1、Cassandra特点
因Cassandra采用了许多容错机制。由于Cassandra是无主的,类似区块链去中心化设计,所以不存在单点故障。可以做到在不停机情况下滚动升级。这是因为Cassandra可以支持多个节点的临时失效(取决于群集大小),对整个群集的性能影响可以忽略不计。
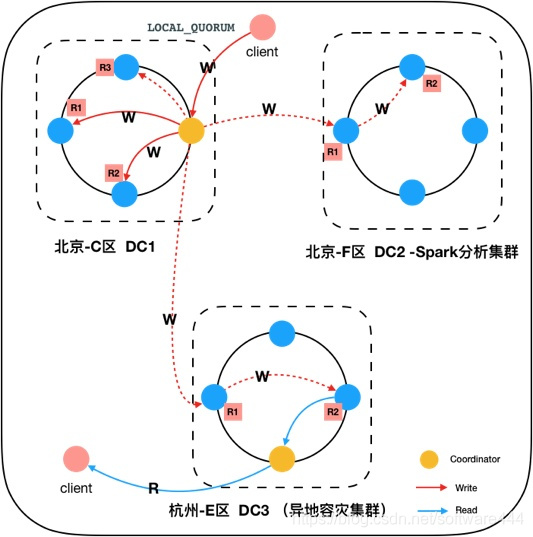
Cassandra提供LOCAL和REMOTE模式,支持多地域容灾。Cassandra允许您将数据复制到其他数据中心,并在多个地域保留多副本。除了作为强大的灾难恢复和业务连续性保障之外,这有助于满足许多监管,离线分析等要求,参考在线文档。
Cassandra提供强大QPS能力,多个节点可以轻松达到10W/TPS。
2、Cassandra部署
以cassandra 3.3.x安装为例,描述cassandra集群搭建过程,先将cassandra 3.3.x解压到Linux服务器目录/appuser/cassandra 3.3.x
以三节点集群为例:192.168.0.1,192.168.0.2,192.168.0.3,并选192.168.0.1为种子节点。
2.1、前置条件
2.1.1、配置jdk
需要SUN提供的JDK1.8,java -version查看JDK版本,注意不是OpenJDK
2.1.2、配置Cassandra环境变量
vi ~/.bash_profile
CASSANDRA_HOME=/appuser/cassandra 3.3.x
并在path后面加上
:$CASSANDRA_HOME/bin
执行:source ~/.bash_profile 让其配置生效
验证生效:echo $CASSANDRA_HOME
2.1.3、配置系统调优参数
(1)vi /etc/sysctl.conf 配置网络缓冲区和虚拟内存
net.ipv4.tcp_syncookies=1
net.ipv4.tcp_tw_reuse=1
net.ipv4.tcp_tw_recycle=1
net.ipv4.tcp_synack_retries=2
net.ipv4.tcp_syn_retries=2
net.ipv4.tcp_wmem=8192436600873200
net.ipv4.tcp_rmem=32768436600873200
net.ipv4.tcp_mem=94500000 91500000 92700000
net.ipv4.tcp_max_orphans=3276800
net.ipv4.tcp_fin_timeout=30
vm.swappiness=5
vm.max_map_count=1048575
(2)vi /etc/security/limits.conf 配置资源限制
*-memlock unlimited
*- nofile 65535
*-nproc 32768
*-as unlimited
(3)vi /etc/security/limits.d/90-nproc.conf 配置文件打开数
*-nproc 32768
让配置生效:执行sysctl -p
2.2、配置cassandra.yaml
2.2.1、配置yaml,详细参考官方文档…
cd $CASSANDRA_HOME
cd conf
注意:后面加空格然后在添加参数
vi cassandra.yaml
cluster_name: 'xx-cluster' #集群名称,每个节点相同
seeds: "192.168.0.1" #种子节点--注:集群启动时每个节点需配置相同的种子IP地址
listen_address: "192.168.0.1" #本机实际IP地址
rpc_address: "192.168.0.1" #RPC服务,本机实际IP地址
data_file_directories: /appuser/data #元数据路径
commitlog_directory: /appuser/logs #日志存放目录
saved_caches_directory: /appuser/caches #缓存存放目录
concurrent_compactors: 8
concurrent_reads: 32
concurrent_writes: 32
concurrent_counter_writes: 32
file_cache_size_in_mb: 2048 #注意tombstone会撑爆缓存,应根据数据量适当调整,或避免大表出现tombstone
2.2.2、配置jvm.options
#CMS Setting禁用CMS垃圾回收器,使用G1垃圾回收器,以下以主机内存为16G的参数调优为例:
-Xms10G
-Xmx10G
-XX:+UseG1GC
-XX:G1RSetUpdatingPauseTimePercent=5
-XX:MAXGCPauseMillis=500
-XX:InitiatingHeapOccupancyPercent=75
-XX:ParallelGCThreads=16
-XX:ConcGCThreads=16 #默认为Parallel的1/4,设置相同减少STW
-XX:+AlwaysPreTouch
-XX:-UseBiasedLocking #禁用偏向锁
#其他Print参数保持不变
-Xloggc: /appuser/cassandra/gc.log #以实际地址为准
2.3、启动cassandra
启动时,先启动种子节点,然后再启动其他节点。
cd ${CASSANDRA_HOME}/bin
./cassandra &
(1)、创建用户
- ./cqlsh IP 9042 -ucassandra -pcassandra;
-. /cqlsh IP 9042 -u cassuser -pcass123! create usercassuserwith password‘cass123!’superuser; #创建用户cassusergrand all on keyspacecasskeyspacetocassuser; #授权casskeyspace给cassuser用户alter usercassandrawith password‘cass123!’; #更改用户cassandra的密码create keyspace if not existscasskeyspace with durable writes =true and replication {‘class’: ‘org.apache.cassandra.locator.SimpleStrategy’, ‘replication_factor’: ‘3’}
2.4、sstable压缩方式选择
如何选择创建表,往往需要对读写场景进行分析,针对不同场景,压缩选择方式不仅相同,具体参考官方文档说明。
(1)SizeTieredCompactionStrategy(默认)
数据量达到阈值才进行压缩,Cassandra在内存数据达到一定大小时,会将数据排序写入磁盘生成一个sstable文件块,所以会提高写速度。
- 推荐用于写入密集型工作负载。
优点:非常好地压缩写入密集型工作负载。
缺点:可以保留陈旧数据的时间过长。所需的内存会随着时间的推移而增加。
(2)LeveledCompactionStrategy
各层无重复数据,检索速度快:同一层的各个sstable之间不会有重复的数据。所以在某一层和它上一层的数据块进行合并时,可以明确的知道某个key值处在哪个数据块中,可以一个数据块一个数据块的合并,合并后生成新块就丢掉老块。
- 推荐用于
读取密集型工作负载。
优点:磁盘需求更容易预测。读取操作延迟更可预测。陈旧数据被更频繁地逐出。
缺点:更高的 I/O 利用率影响操作延迟
(3)DateTieredCompactionStrategy
- 推荐用于时间序列和即将到期的生存时间 (TTL)工作负载。
优点:非常适合时间序列数据,存储在对所有数据使用默认 TTL 的表中。比 DateTieredCompactionStrategy (DTCS) 更简单的配置,后者已被弃用而支持 TWCS。
缺点:如果需要乱序时间数据,则不合适,因为 SSTable 不会很好地压缩。此外,不适用于没有 TTL 工作负载的数据,因为存储将无限制地增长。与 DTCS 相比,可以进行更少的微调配置。
3、常用命令
3.1、集群状态查看
./nodetool status #查看集群总体状态
./nodetool tpsstats #查看集群总体各个阶段的性能
./nodetool cfsstats tbs.mkt_info |head -7 #查看集群读写延迟,超过1s重点关注
#tbs.mkt_info表示:
k
e
y
s
p
a
c
e
.
{keyspace}.
keyspace.{table}
- 查看集群读写延迟统计信息,识别性能瓶颈问题,一般使用此命令,关注ReadLatency和WriteLatency的数值,超过1s重点关注
./nodetool proxyhistograms - 查看对应表读写延迟统计信息,分析具体涉及表结构时,一般使用此命令,关注ReadLatency和WriteLatency的数值,超过1s重点关注
./nodetool tablehistograms tbs.mkt_info - 查看集群KeyCache命中率,重点关注hists,命中率越高,说明缓存越有效
./nodetool info |grep ‘Key Cache’ - 查看集群RowCache命中率,重点关注hists,命中率越高,说明缓存越有效
./nodetool info |grep ‘Row Cache’ - 监控磁盘读写浏览,间隔2s刷新一次
iostat -dx 2
3.2、cql使用
./bin/cqlsh 进入cqlsh控制台
1、describe keyspaces;
2、describe types;
#可以查询SELECT * FROM tb;
3、describe tables
#进入keyspace
4、user keyspace
#进行数据查询,并将结果导出到日志
5、bin/cqlsh -e `SELECT id,title FROM t_videos;` >output.txt
#从文件导入,指定分隔符或表头
6、copy myspace.mytable(col1,col2,col3) from '/path/to/import.dat' with delimiter=','
copy myspace.mytable(col1,col2,col3) from '/path/to/import.dat' with delimiter=',' and header=true
#导出表到文件
7、copy myspace.mytable(col1,col2,col3) to'/path/to/export.dat' with delimiter=','
copy myspace.mytable(col1,col2,col3) to'/path/to/export.dat' with delimiter=',' and header=true
#清空表,类似mysql delete from tableName;
8、truncate tableName
#执行文件内脚本,针对一些权限限制严的场景(比如:银行)
9、./cqlsh IP 9042 -ucass -pcass123! -f ddl.sql
3.3、使用sstableloader
./bin/sstableloader -d 192.168.0.1,192.168.0.2,192.168.0.3 -u cassuser -pw cass123! -t 10 -cph 100 casskeyspace/test_dt_sstable
其中集群地址:192.168.0.1,192.168.0.2,192.168.0.3
生成的文件目录:casskeyspace/test_dt_sstable
限制流量-t:M/bps
每个节点建立连接数:-cph
3.4、官方压测工具
进入cassandra/tools工具目录
- 写压测:./bincassandra-stress write n=1000000 -rate threads=50 -node 192.168.0.1,192.168.0.2,192.168.0.3
- #写压测(写100万行,写3个副本)
./bincassandra-stress write n=1000000 cl=LOCAL_QUORUM -rate threads=50 -schema “replication(factor=3)” -node 192.168.0.1,192.168.0.2,192.168.0.3 - #读压测(读20万行,等待2个副本响应)
./bincassandra-stress read n=200000 cl=LOCAL_QUORUM -rate threads=50 -schema “replication(factor=2)” -node 192.168.0.1,192.168.0.2,192.168.0.3 - 插入100万条数据,读写比例3:1,一致性为QUORUM
./bincassandra-stress user profile=stress-leveled.yaml n=1000000 ops(insert=3,read=1) no-warmup cl=LOCAL_QUORUM – node 192.168.0.1,192.168.0.2,192.168.0.3 -port native=9042
3.5、创建表
详细请参考官方文档详细说明,这里只对如下参数做一点说明:
gc_grace_seconds :数据被标记为墓碑(删除标记)后几秒钟,然后才有资格进行垃圾收集。默认值:864000(10 天)。默认值允许 Cassandra 在删除之前最大化一致性。建议对创建表都进行设定,以防墓碑不断增长导致预警。