以下文章摘录自:
《机器学习观止——核心原理与实践》
京东: https://item.jd.com/13166960.html
当当:http://product.dangdang.com/29218274.html
(由于博客系统问题,部分公式、图片和格式有可能存在显示问题,请参阅原书了解详情)
————————————————
版权声明:本文为CSDN博主「林学森」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/xuesen_lin/
1.1 Tensorflow分布式训练
1.1.1.1 Google DisBelief
我们分析tensorflow的分布式原理,不得不先提到Google的另一个系统DisBelief——因为tensorflow的一些分布式核心理念都来源于后者。简单来讲,DisBelief是Google内部开发的第一代面向深度学习的分布式系统。虽然DisBelief具备较好的扩展性,但它对一些研究场景的支持却不够灵活,所以Google才又设计出了第二代深度学习分布式系统——也就是大家所熟知的TensorFlow。它相比第一代系统不仅速度更快,更为灵活,而且更能满足新的研究场景需求。据悉这两套系统都被广泛应用于Google的技术产品中,例如语音识别,图像识别及翻译等。
在DisBelief的设计框架中,主要包含了如下两个核心元素:
l Parameter servers
Parameter servers负责保存和更新模型状态(例如参数),同时可以根据worker计算出的梯度下降数值来更新参数
l Worker replicas
Worker replicas的主要任务是执行具体的计算工作,它会计算神经网络的loss函数以及梯度下降值
Tensorflow作为Google的第二代深度学习分布式系统,不但很好地继承了DisBelief的上述设计,而且做了不少功能上的扩展改进和性能上的优化。例如在灵活性方面,Tensorflow与DisBelief最大的区别在于:后者的ps和worker是两个不同的程序,而在tensorflow中ps和worker的运行代码几乎完全相同。
DisBelief的核心实现可以参考下图的描述。
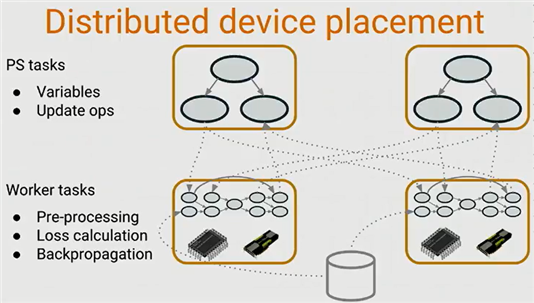
图 ‑ Google DisBelief系统
引用自Tensorflow dev summit
下图是Tensorflow的分布式示意图:
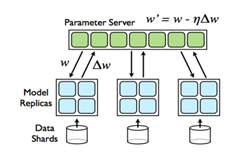
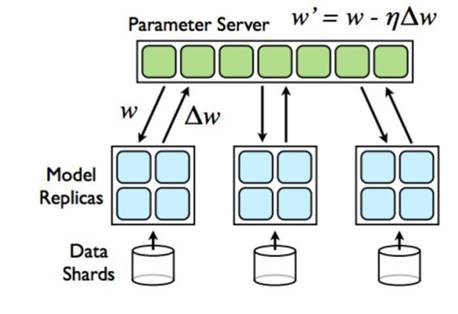
图 ‑ Tensorflow分布式示意图
1.1.1.2 分布式TF的基本概念
我们先针对tensorflow分布式实现中的几个重要概念进行讲解,这样大家后续再遇到它们时就不会“一头雾水”了。
(1) Tensorflow Cluster
Tensorflow cluster指的是一系列针对graph进行分布式计算的task任务,其中每一个task又和server相关联——而server则包含了一个用于创建session的master节点和一个用于graph计算的worker节点。
(2) Task
前面我们提到了Cluster是task的集合,大家肯定会有疑问——那么task又是什么呢?简单来讲,task就是主机上的一个进程。而且大多数情况下,一台机器只运行一个task。
(3) Job
Tensorflow的一个cluster也可以被划分为1个或者多个jobs,然后每个job则包含了1个或者多个tasks,所以job是task的集合。那么为什么会有job这个概念,它想解决什么样的问题呢?
这是因为在分布式深度学习框架中,存在两种job——即Parameter Job和Worker Job。根据之前的讲解,我们应该知道前者用于执行参数的存储和更新工作,而后者则负责实际的图计算。当参数数量太大时,就需要多个tasks来协同了。
(4) Parameter server和Worker replicas
Parameter server和worker replicas的概念我们在前面DisBelief小节已经做过解释,这里就不再赘述了。
(5) Client
Client一般由Python或者C++编写,它通过构建Tensorflow graph和Session来与cluster交互。
(6) Master service
Master service实现了tensorflow::Session接口,同时负责协调1或3个worker services。
(7) Worker service
Worker service实现了worker_service.proto,它利用本地设备来执行Tensorflow graph中的一部分。Tensorflow中的所有server都会实现Master service和Worker service。
如下示意图所示:
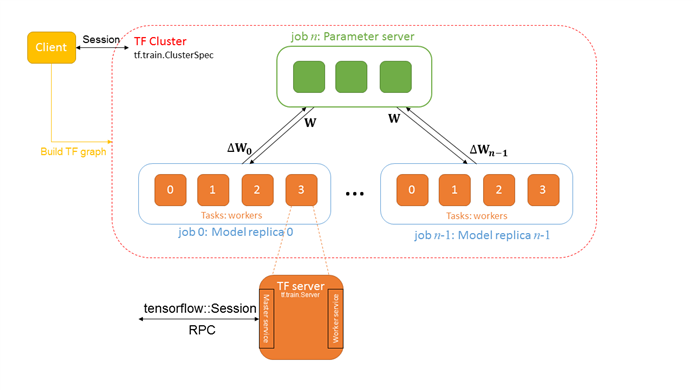
图 ‑ Tensorflow分布式核心元素示意图
Tensorflow相比于其它机器学习平台的一个明显优势还在于其强大的并行计算能力。那么应该怎么理解这个“并行”的概念呢?通俗来讲,“并行”就是指任务可以被拆分成多份,同步执行计算过程,从而有效降低任务耗时。
不过在机器学习这个场景下,我们认为“并行”还可以被进一步细分。下面我们为大家逐一分析各种可能的Tensorflow程序的运行情况。
(1) 一对一的情况(任务不拆分)
也就是1个任务(不拆分)在1个CPU/GPU上运行的情况,此时并不涉及并行计算。如下示例图所示:
图 ‑ 一对一的情况(任务不拆分)
那么我们怎么指定一个Task是在CPU上或者GPU上运行呢?事实上Tensorflow已经帮大家充分考虑到了这一点,并提供了tf.device接口来满足开发者的需求。而且Tensorflow还提供了log_device_placement选项来打印出每步运算操作的硬件承载体。
下面我们结合范例来做详细讲解。如下代码段所示:
import tensorflow as tf
var_a = tf.constant([2], name=’var_a’)
var_b = tf.constant([3], name=’var_b’)
var_c = var_a + var_b
sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))
print (sess.run(var_c))
如果你的tensorflow程序是在CPU上执行了的话,那么会有类似如下的输出:
Device mapping: no known devices.
add: (Add): /job:localhost/replica:0/task:0/device:CPU:0
var_b: (Const): /job:localhost/replica:0/task:0/device:CPU:0
var_a: (Const): /job:localhost/replica:0/task:0/device:CPU:0
…
而如果是在GPU上执行了的话,输出就变成了:
Device mapping:
/job:localhost/replica:0/task:0/device:GPU:0 -> device: 0, name: GeForce GT 650M, pci bus id: 0000:01:00.0, compute capability: 3.0
add: (Add): /job:localhost/replica:0/task:0/device:GPU:0
var_b: (Const): /job:localhost/replica:0/task:0/device:GPU:0
var_a: (Const): /job:localhost/replica:0/task:0/device:GPU:0
…
其中cpu:0是tensorflow对cpu的编号——不过不管设备上有几个CPU,都只会显示cpu:0。而gpu的情况则不同,tensorflow会给设备上的所有GPU分配不同的名称,如gpu:0、gpu:1等等。
如果设备属于如下几种情况,那么tensorflow会默认选择CPU来执行程序:
l 没有GPU
l 有GPU,但不在tensorflow的支持范围内
l 有GPU且在支持范围内,但没有安装配套的驱动软件
l 有GPU,但安装的是tensorflow的CPU版本
相对应的,如果设备满足以下条件,那么tensorflow则默认选择GPU来执行程序:
l 安装了GPU版本的tensorflow
l 设备有GPU,而且在tensorflow的支持范围内
l 正确安装了GPU的辅助配套软件
当然,开发者也可以人为地指定需要在CPU或者GPU上执行程序。范例代码如下:
import tensorflow as tf
with tf.device(‘/cpu:0’):
var_a = tf.constant([2], name=’var_a’)
var_b = tf.constant([3], name=’var_b’)
var_c = var_a + var_b
sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))
print (sess.run(var_c))
上述代码在符合条件的GPU设备上运行时,会有如下输出:
Device mapping:
/job:localhost/replica:0/task:0/device:GPU:0 -> device: 0, name: GeForce GT 650M, pci bus id: 0000:01:00.0, compute capability: 3.0
add: (Add): /job:localhost/replica:0/task:0/device:CPU:0
var_b: (Const): /job:localhost/replica:0/task:0/device:CPU:0
var_a: (Const): /job:localhost/replica:0/task:0/device:CPU:0
…
这就说明利用tf.device来有目的性的选择处理器产生效果了。
(2) 一对一的情况 (任务拆分)
图 ‑ 一对一的情况(任务拆分)
一个任务就只能选择在同一种处理器上端到端地执行吗?
答案是否定的。我们针对前面的代码再做一下改造,如下所示:
import tensorflow as tf
with tf.device(‘/cpu:0’):
var_a = tf.constant([2], name=’var_a’)
var_b = tf.constant([3], name=’var_b’)
with tf.device(‘/gpu:0’):
var_c = var_a + var_b
sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))
print (sess.run(var_c))
上面代码段就把一个任务成功地拆分成两份了,它们将分别在cpu和gpu上执行。程序执行过程中的log输出也可以证明这一点:
Device mapping:
/job:localhost/replica:0/task:0/device:GPU:0 -> device: 0, name: GeForce GT 650M, pci bus id: 0000:01:00.0, compute capability: 3.0
add: (Add): /job:localhost/replica:0/task:0/device:GPU:0
var_b: (Const): /job:localhost/replica:0/task:0/device:CPU:0
var_a: (Const): /job:localhost/replica:0/task:0/device:CPU:0
…
需要特别注意的是,并不是所有的tensorflow运算都可以在GPU上执行。如果强制指定不适当的处理器的话,有可能导致类似下面的错误:
…\Local\Programs\Python\Python36\lib\site-packages\tensorflow\python\framework\ops.py”, line 3160, in create_op op_def=op_def)
File “C:\Users\Administrator\AppData\Local\Programs\Python\Python36\lib\site-packages\tensorflow\python\framework\ops.py”, line 1625, in __init__
self._traceback = self._graph._extract_stack() # pylint: disable=protected-access
InvalidArgumentError (see above for traceback): Cannot assign a device for operation ‘var_a’: Could not satisfy explicit device specification ‘/device
:GPU:0′ because no supported kernel for GPU devices is available.
Colocation Debug Info:
Colocation group had the following types and devices:
VariableV2: CPU
Identity: CPU
Assign: CPU
[[Node: var_a = VariableV2[container=””, dtype=DT_INT32, shape=[1], shared_name=””, _device=”/device:GPU:0″]()]]
…
(3) 一对多GPU的情况 (任务拆分)
前面我们讲解的是一种任务拆分后分别在CPU和GPU上运行的情况。不难理解,同一任务也可以在多个GPU上分别执行。

图 ‑ 一对多GPU的情况
在这种情况下,我们也可以通过tf.device来指定哪些操作具体需要在哪个GPU上执行,这和前面所述是基本一致的。不过之前的范例比较简单,并不涉及多个GPU之间的复杂协同关系——竞争与协同在计算机领域几乎无处不在,同时也是一个让开发者比较头疼的问题,因为如果处理不当就很容易导致各种异常情况。
接下来我们结合tensorflow的一个官方范例来为大家实际讲解如何利用多GPU来协同完成模型的训练工作。这个范例是基于CIFAR-10数据集(https://www.cs.toronto.edu/~kriz/cifar.html)开展的,大家如果对此不熟悉的话可以参考一下本书其它章节的介绍。
不论是什么类型的深度神经网络,我们基本上可以把它们抽象成如下几个步骤:
l Step1. 初始化神经网络参数
l Step2. 一轮迭代开始,根据既定策略选择(部分)数据集
l Step3. 通过前向传播来计算出结果值
l Step4. 利用反向传播算法来更新原有参数
l Step5. 回到Step2开始下一轮迭代
由此可见,神经网络的训练时间主要就耗费在N轮的迭代过程中——而且这种迭代理论上是可以并行进行的。具体来讲,在多个GPU上同步训练一个神经网络至少有两种可选方式,即同步协同和异步协同。
在异步协同模式下,各GPU之间是相对独立的。大致的过程就是:每个GPU都读取同一份参数值,然后独立开展迭代,最后再用反向传播算法得到的结果来更新参数值。异步模式虽然在多GPU协同上不需要做太多工作,但一方面容易引发参数更新冲突,另一方面也有可能导致迭代过程无法达到最优点的问题,因而我们并不推荐采用这种方式。
同步协同方式的其中一个关键点在于如何有效地管理每个GPU各自迭代后产生的参数值更新。换句话说,每个GPU虽然还是独立进行迭代,但它们必须等待所有设备都完成反向传播,得到统一的参数更新(通常采用取平均值的方式)后才能进行到下一轮的工作中。
异步协同的示意图如下所示:
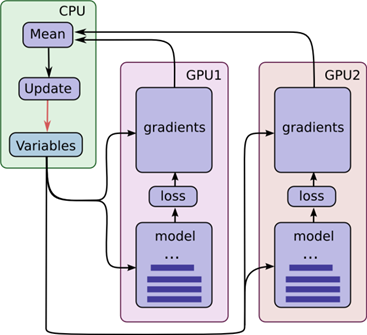
图 ‑ GPU异步协同模式
在上图所示的设计中有一个细节,即CPU会负责收集所有GPU设备的输出结果,统一计算更新值后再让它们共享。
下面的代码用于完成在多个GPU上并行执行AlexNet深度神经网络的训练过程,我们将逐一注释其中的一些关键代码行。因为代码比较长,下面进行分段阅读。
def train():
with tf.Graph().as_default(), tf.device(‘/cpu:0’):
global_step = tf.get_variable( ‘global_step’, [], initializer=tf.constant_initializer(0), trainable=False)
# Calculate the learning rate schedule.
num_batches_per_epoch = (cifar10.NUM_EXAMPLES_PER_EPOCH_FOR_TRAIN
FLAGS.batch_size)
decay_steps = int(num_batches_per_epoch * cifar10.NUM_EPOCHS_PER_DECAY)
前面我们介绍过,并不是所有操作都可以在GPU上执行;另外,兼顾到CPU与GPU之间的数据传输耗时等因素,因而上述代码段被指定在CPU上完成。其中global_step是一个全局的参数,可以用于训练过程中的计数。紧接着我们计算每轮迭代所需的训练数据batch,以及learning rate的更新周期(即decay_steps变量)。这两个变量是为了接下来进一步推算出学习率而准备的。
# Decay the learning rate exponentially based on the number of steps.
lr = tf.train.exponential_decay(cifar10.INITIAL_LEARNING_RATE, global_step, decay_steps,
cifar10.LEARNING_RATE_DECAY_FACTOR,
staircase=True)
# Create an optimizer that performs gradient descent.
opt = tf.train.GradientDescentOptimizer(lr)
# Get images and labels for CIFAR-10.
images, labels = cifar10.distorted_inputs()
batch_queue = tf.contrib.slim.prefetch_queue.prefetch_queue(
[images, labels], capacity=2 * FLAGS.num_gpus)
# Calculate the gradients for each model tower.
tower_grads = []
在神经网络的训练过程中,learning rate既可以是固定值也可以是动态变化的值——采用固定值的优点在于简单,而采用动态值则被很多实验证明确实可以对收敛产生有益的影响。Learning rate的调整可以有很多种具体方式,比如tensorflow中就提供了指数衰减、多项式衰减等API。上述的exponential_decay就是指数衰减函数,它的原型如下所示:
exponential_decay(learning_rate, global_step, decay_steps,
decay_rate, staircase=False, name=None)
第一个参数代表的是初始的学习速率;第二个参数为全局计数值;第三个参数是学习率的更新周期;第四个参数为衰减率;第五个参数代表是否采用非连续性的衰减方式。
学习速率的计算方式确定后,接下来还要为训练过程设置优化器。这里采用的是GradientDescentOptimizer,即常用的梯度下降算法。最后的tower_grads数组用于存储各GPU设备的输出结果,以便在每轮结束后执行参数的统一计算。
程序执行到现有为止基本可以说是“万事具备,只欠东风”了,接下来就可以请主角登场了:
with tf.variable_scope(tf.get_variable_scope()):
for i in xrange(FLAGS.num_gpus):
with tf.device(‘/gpu:%d’ % i):
with tf.name_scope(‘%s_%d’ % (cifar10.TOWER_NAME, i)) as scope:
# Dequeues one batch for the GPU
image_batch, label_batch = batch_queue.dequeue()
# Calculate the loss for one tower of the CIFAR model. This function
# constructs the entire CIFAR model but shares the variables across
# all towers.
loss = tower_loss(scope, image_batch, label_batch)
# Reuse variables for the next tower.
tf.get_variable_scope().reuse_variables()
# Retain the summaries from the final tower.
summaries = tf.get_collection(tf.GraphKeys.SUMMARIES, scope)
# Calculate the gradients for the batch of data on this CIFAR tower.
grads = opt.compute_gradients(loss)
# Keep track of the gradients across all towers.
tower_grads.append(grads)
不难看出,上述代码段的主循环逻辑在于将任务分发到多个GPU(由FLAGS.num_gpus决定)进行同步训练。每个GPU的工作都是相对平等的,它们从batch queue中获取到image和label,然后调用tower_loss来执行前向传播算法。所获取到的loss再借助compute_gradients的后向传播过程进一步计算出梯度值。最后再将该GPU的梯度计算结果保存到tower_grads数组中。这个代码段中体现神经网络训练过程的主要是两个函数:tower_loss和compute_gradients。它们的实现原理在本书其它章节也已经做过详细的讲解了,因而限于篇幅我们就只聚焦于多GPU协同方式上,而不再赘述这些细枝末节了。
…
grads = average_gradients(tower_grads)
…
# Apply the gradients to adjust the shared variables.
apply_gradient_op = opt.apply_gradients(grads, global_step=global_step)
各GPU完成自己的一轮迭代后,接下来就该做参数的统一更新了——首先是通过average_gradients来计算“平均梯度”值,然后再调用apply_gradients来更新优化器中的训练参数。
当然,到目前为止我们只是配置了很多变量,但还未实际执行它们。这是由下面代码段完成的:
train_op = tf.group(apply_gradient_op, variables_averages_op)
# Create a saver.
saver = tf.train.Saver(tf.global_variables())
# Build the summary operation from the last tower summaries.
summary_op = tf.summary.merge(summaries)
# Build an initialization operation to run below.
init = tf.global_variables_initializer()
sess = tf.Session(config=tf.ConfigProto( allow_soft_placement=True,
log_device_placement=FLAGS.log_device_placement))
sess.run(init)
# Start the queue runners.
tf.train.start_queue_runners(sess=sess)
summary_writer = tf.summary.FileWriter(FLAGS.train_dir, sess.graph)
for step in xrange(FLAGS.max_steps):
start_time = time.time()
_, loss_value = sess.run([train_op, loss])
duration = time.time() – start_time
assert not np.isnan(loss_value), ‘Model diverged with loss = NaN’
if step % 10 == 0:
num_examples_per_step = FLAGS.batch_size * FLAGS.num_gpus
examples_per_sec = num_examples_per_step / duration
sec_per_batch = duration / FLAGS.num_gpus
format_str = (‘%s: step %d, loss = %.2f (%.1f examples/sec; %.3f’sec/batch)’)
print (format_str % (datetime.now(), step, loss_value,
examples_per_sec, sec_per_batch))
if step % 100 == 0:
summary_str = sess.run(summary_op)
summary_writer.add_summary(summary_str, step)
…
这样一来基于CIFAR10数据集的多GPU协同训练过程就完成了。总的来说,整个程序的执行逻辑基本上就是按照我们前面给出的同步协同结构进行的。其中的主要难点在于:
l 如何合理的分工,即哪些属于CPU的工作范畴,而哪些则是GPU更擅长的内容
l 同步模式下,所有GPU设备在每轮训练结束后都需要做统一的“调度”
l 各GPU的迭代结果首先保存到一个数组中,计算出最终参数值后再做统一更新,并保证所有设备共享同一份参数
随着深度学习的持续火热,模型的复杂度越来越高。比如有的深度神经网络模型的参数个数可以达到百亿以上级别,需要训练的数据则以TB为单位来衡量。此时即便是一台机器中配置多个GPU也已经“力不从心”了,所以就引出了多机多GPU的诉求。
1.1.3.1 Tensorflow服务器集群
本小节我们先来讲解如何创建一个tensorflow的集群。
Tensorflow官方版本就支持服务器集群搭建,而且实现过程并不复杂,不过需要大家熟悉几个核心的API函数。例如tf.train.ClusterSpec就是专门用于描述tensorflow分布式集群的一个class实现。

举个例子来说,如果我们希望创建一个包含了2个jobs和5个tasks的cluster,可以采用下面的代码行:
cluster = tf.train.ClusterSpec({“worker”: [“worker0.example.com:2222”,
“worker1.example.com:2222”,
“worker2.example.com:2222”],
“ps”: [“ps0.example.com:2222”,
“ps1.example.com:2222”]})
这样一来就产生了我们所需的Cluster了。它包含两个Job(worker和ps),其中worker中有三个Task(即有三个Task执行Tensorflow op操作), ps有2个Task。
当然,我们也可以在本地机器上创建cluster。下面就是一个single-process cluster的范例,可以看到实现过程同样很简单:
import tensorflow as tf
c = tf.constant(“Hello, distributed TensorFlow!”)
server = tf.train.Server.create_local_server()
sess = tf.Session(server.target) # Create a session on the server.
sess.run(c)
其中create_local_server就用于创建一个运行于本地host机器的single-process cluster。其原型如下:

紧接着,我们需要在每个task中创建一个tf.train.Server实例。Server用于管理如下一些元素:
l 一系列本地的设备
l 与其它tasks的连接操作
l 可以用于执行分布式计算的一个tf.Session实例
例如,下述代码描述了运行于localhost上的两个server:
# In task 0:
cluster = tf.train.ClusterSpec({“local”: [“localhost:2222”, “localhost:2223”]})
server = tf.train.Server(cluster, job_name=”local”, task_index=0)
# In task 1:
cluster = tf.train.ClusterSpec({“local”: [“localhost:2222”, “localhost:2223”]})
server = tf.train.Server(cluster, job_name=”local”, task_index=1)
完成了cluster的创建后,我们就可以进一步在模型中使用它来实现分布式操作了。
with tf.device(“/job:ps/task:0”):
weights_1 = tf.Variable(…)
biases_1 = tf.Variable(…)
with tf.device(“/job:ps/task:1”):
weights_2 = tf.Variable(…)
biases_2 = tf.Variable(…)
with tf.device(“/job:worker/task:7”):
input, labels = …
layer_1 = tf.nn.relu(tf.matmul(input, weights_1) + biases_1)
logits = tf.nn.relu(tf.matmul(layer_1, weights_2) + biases_2)
# …
train_op = …
with tf.Session(“grpc://worker7.example.com:2222”) as sess:
for _ in range(10000):
sess.run(train_op)
上述这个范例中包含两个job,其中ps job里的2个task用于创建变量,而worker job里的task用于执行计算操作。另外,Ps job和worker job包含的众多task之间的交互显然是双向的:
l ps -> worker
深度网络的前向传播
l worker -> ps
参数更新
那么这些ps job和worker job具体是如何进行交互的,有几种可选的模式呢?我们将在接下来的几个小节中逐一为大家“揭开面纱”。
1.1.3.2 分布式交互模式
1.1.3.2.1 In-graph replication
In-graph replication,一般被称为“图内复制”,是tensorflow提供的分布式模式中较为简单的一种。它的特点在于数据集中在一个节点上进行分发,然后结合其它计算节点来完成训练。如下范例图所示:
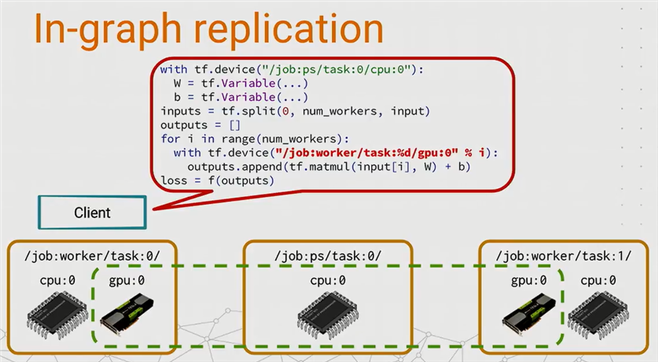
图 ‑ In-graph replication示意图
显然这种方式配置简单,也很好实现,所以在某些场景下具备一定的优势。但对于很大的模型,in-graph replication的单点分发会严重影响并发训练速度。
1.1.3.2.2 Between-graph replication
在between-graph replication的设计中,每一个/job:worker task都有独立的client(典型情况下,task和client在一个进程中)。换句话说,每个worker都会创建一个图来跑计算,并把数据保存在本地。同时,ps task会协同不同client之间的数据变化。
那么ps task是如何做到的呢?实现原理也并不复杂,说得直白些就是“共享内存”——为worker tasks创建同样名字的变量,并存放在ps的内存中进行共享。这样当一个worker task更新了变量,其它task也是可见的。
如下示意图所示:
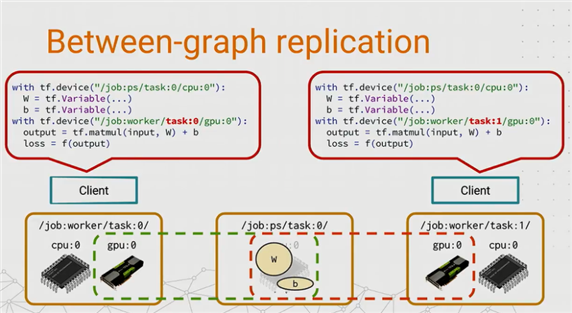
图 ‑ Between-graph replication
1.1.3.2.3 同步和异步训练
在同步训练模式下(Synchronous training),每次迭代都需要等待所有分发出去的数据计算完成并返回了结果以后,才可以执行梯度更新。优点在于我们在寻找最优解的过程中较为稳定,不容易出异常状况;缺点也是很明显的,就是会造成不必要的等待耗时(因为不同worker计算所需时间有长有短,这样一来“快的”就必然要等待“慢的”)。
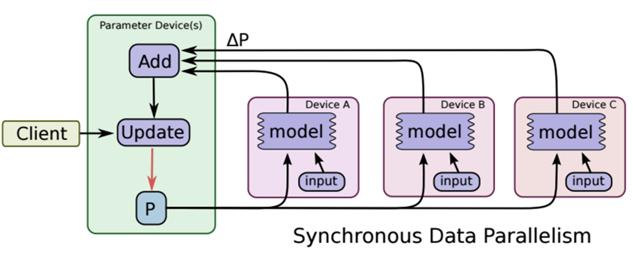
图 ‑ 同步训练模式
和上述同步训练模式相对应的是异步训练模式(Asynchronous training),此时大家各自更新计算结果,因而可以充分利用计算资源。缺点就在于有可能造成寻优过程的不稳定和抖动的情况。
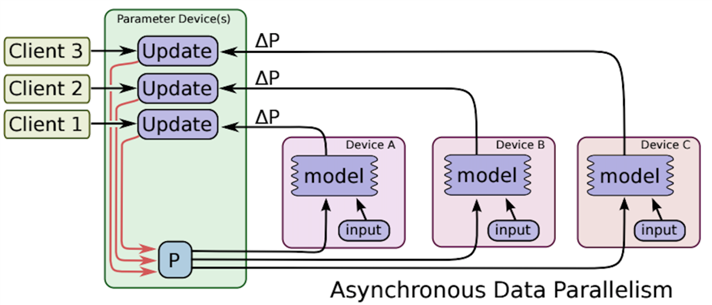
图 ‑ 异步协同训练模式
1.1.3.3 代码范例
我们以一个简单的代码范例来演示between graph的分布式训练。
这个范例需要拟合的是一个函数y=5x + 8,核心代码如下所示:
#distributed_between_graph.py
if FLAGS.job_name == “ps”:
server.join() ##如果是ps,则只要等待别人即可
elif FLAGS.job_name == “worker”:
with tf.device(tf.train.replica_device_setter(
worker_device=”/job:worker/task:%d” % FLAGS.task_index,
cluster=cluster)):
global_step = tf.Variable(0, name=’global_step’, trainable=False)
input = tf.placeholder(“float”)
label = tf.placeholder(“float”)
weight = tf.get_variable(“weight”, [1], tf.float32, initializer=tf.random_normal_initializer())
bias = tf.get_variable(“bias”, [1], tf.float32, initializer=tf.random_normal_initializer())
pred = tf.multiply(input, weight) + bias
loss_value = loss(label, pred)
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
grads_and_vars = optimizer.compute_gradients(loss_value)
以上代码段用于定义变量,优化器以及梯度计算等操作,这和单机的训练情况没有本质区别。需要特别注意的是replica_device_setter这个函数,简单来讲它是把各个variables按照round-robin的方式依次分配到ps节点上。引用dev summit上的一张图例就是:
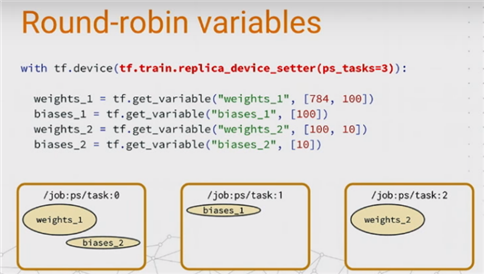
可以看到上述4个变量(weights_1、biases_1等)被按照顺序依次分配到3个ps节点上了(其中task:0分配了两个变量)。当然,还有很多其它的分配算法,例如Load balancing等等。
if issync == 1:
rep_op = tf.train.SyncReplicasOptimizer(optimizer,
replicas_to_aggregate=len(worker_hosts),
replica_id=FLAGS.task_index,
total_num_replicas=len(worker_hosts),
use_locking=True)
train_op = rep_op.apply_gradients(grads_and_vars, global_step=global_step)
init_token_op = rep_op.get_init_tokens_op()
chief_queue_runner = rep_op.get_chief_queue_runner()
由前面的学习我们知道——在同步模式下,需要各个worker将计算结果协同后才能更新参数。这种情况下可以通过调用SyncReplicasOptimizer来实现。
else:
train_op = optimizer.apply_gradients(grads_and_vars,
global_step=global_step)
异步模式下则要简单一些,因为各个worker只需要“各自为政”就可以了。
init_op = tf.initialize_all_variables()
saver = tf.train.Saver()
tf.summary.scalar(‘cost’, loss_value)
summary_op = tf.summary.merge_all()
sv = tf.train.Supervisor(is_chief=(FLAGS.task_index == 0),
logdir=”./checkpoint/”,
init_op=init_op,
summary_op=None,
saver=saver,
global_step=global_step,
save_model_secs=60)
Supervisor英文直译是“管理者”,顾名思义就是统领全局的人——具体而言,类似于参数初始化、模型保存等公共事务它都可以一并代劳,同时还能兼领“居中协调”的职责,保证分布式任务“有条不紊”的开展。
with sv.prepare_or_wait_for_session(server.target) as sess:
if FLAGS.task_index == 0 and issync == 1:
sv.start_queue_runners(sess, [chief_queue_runner])
sess.run(init_token_op)
step = 0
while step < 200000:
train_x = np.random.randn(1)
train_y = 5 * train_x + np.random.randn(1) * 0.22 + 8
_, loss_v, step = sess.run([train_op, loss_value,global_step], feed_dict={input:train_x, label:train_y})
if step % steps_to_validate == 0:
w,b = sess.run([weight,bias])
print(“step: %d, weight: %f, bias: %f, loss: %f” %(step, w, b, loss_v))
sv.stop()
为了可以快速得到最终结果,我们设置的step步数不会太大(200000),并且每隔1000步打印出当前的最新状态。接下来我们可以在本地机器上启动3个进程来模拟运行上述代码,请大家参考下面的命令行:
##ps节点:
python distribute.py –ps_hosts=192.168.1.101:2222 –worker_hosts=192.168.1.101:2224,192.168.1.101:2225 –job_name=ps –task_index=0
##worker1节点:
python distribute.py –ps_hosts=192.168.1.101:2222 –worker_hosts=192.168.1.101:2224,192.168.1.101:2225 –job_name=worker –task_index=0
##worker2节点:
python distribute.py –ps_hosts=192.168.1.101:2222 –worker_hosts=192.168.1.101:2224,192.168.1.101:2225 –job_name=worker –task_index=1
当ps和2个worker运行起来后,它们各自就会互相协同来完成分布式训练任务了。
其中ps节点的状态如下:

第1个worker的状态如下:
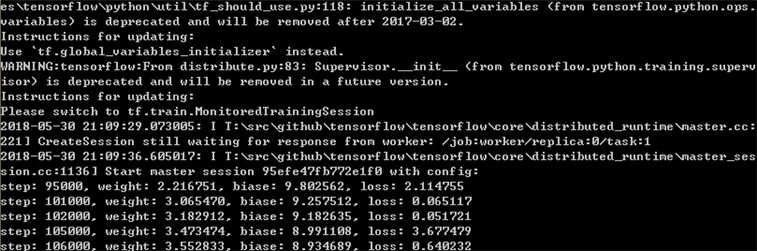
第2个worker的状态如下:
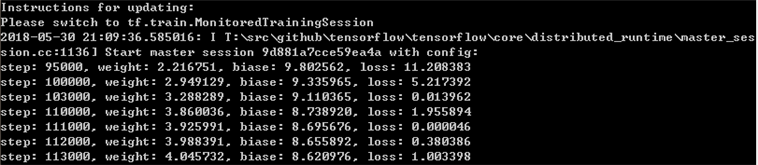
可以看到,最终得到的分布式训练结果和y=5x +8基本相近。