概率图模型对序列建模,区分概率图模型的关键是理解模型是联合概率分布还是条件概率分布,在nlp任务中,往往是要求条件概率P(y|x),联合概率分布模型通过贝叶斯公式将条件概率转换为求联合概率,再通过联合概率分布模型求解计算。
1. 隐马尔可夫模型(HMM)
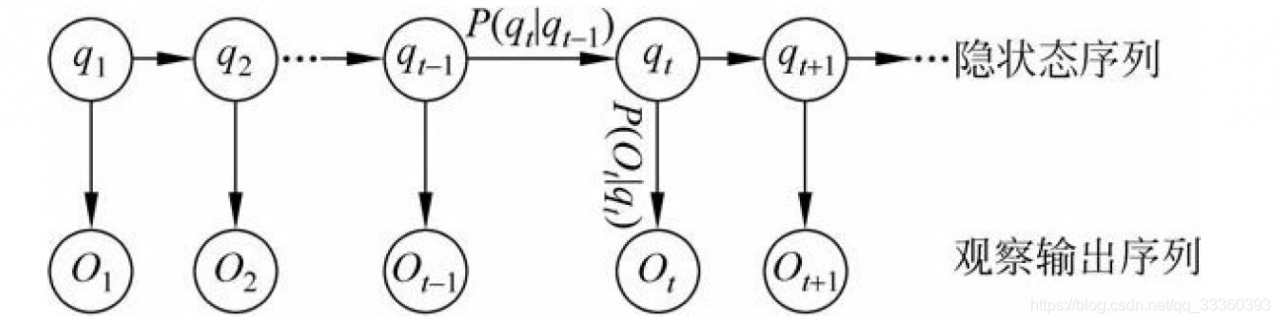
建模方法
模型是一个联合概率分布P(Q,O),其中Q为隐变量(对应预测结果Y),O为可观测变量(对应训练数据X)。
在求解问题时,通过贝叶斯公式转化为通过模型
求解结果。
模型参数为,其中,A为状态转移概率矩阵,即qi转移到qj的概率矩阵;B为表现矩阵,即从qy表现为Ox的概率矩阵;π为初始状态概率分布,即q1的概率分布。
在模型预测阶段,预测问题即找到使得条件概率最大的Q
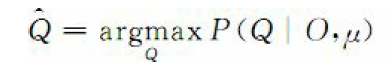
通过定义维比特变量,求Q、O的联合概率分布

则:
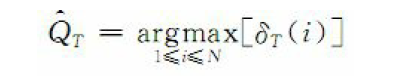
维比特算法将时间复杂度降低到了O(N2T)
HMM的参数估计采用了EM算法,通过前向、后向算法优化了求解计算过程。
2. 最大熵模型(ME)
最大熵模型在形式上是最漂亮的统计模型,而在实现上是最复杂的模型之一。
假设分类模型是一个条件概率分布P(Y | X )
通过特征函数约束分布,即:

在约束条件下求条件概率分布P(Y | X )的最大熵:

定义拉格朗日函数L(P,w):

最优化的原始问题是:
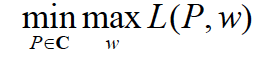
转化为对偶问题:

内部的极小化问题求解得:

外部极大化问题求解通过求参数w的极大似然估计,优化方法可以通过梯度下降法、牛顿法、拟牛顿法。
3. 最大熵马尔可夫模型(MEMM)
最大熵马尔科夫模型把HMM模型和maximum-entropy模型的优点集合成一个产生式模型,这个模型允许状态转移概率依赖于序列中彼此之间非独立的特征上,从而将上下文信息引入到模型的学习和识别过程中,提高了识别的精确度,召回率也大大的提高。
MEMM假设分类模型是一个条件概率分布,其中
是
的前一个状态。(
依赖前一个状态
,由此引入马尔科夫性)
通过特征函数约束分布,求
的最大熵并求解,内部的极小化问题求解得:

其中为归一化因子。
外部极大化问题求解,通过求解参数的极大似然估计。
在预测阶段,可通过公式:

4. 条件随机场(CRF)
假设分类模型是一个条件概率分布P(Y | X )
通过特征函数和
约束分布,
在约束条件下求条件概率分布P(Y | X )的最大熵,内部的极小化问题求解得:

外部极大化问题求解,通过求解参数和
的极大似然估计。
区别与联系
1. HMM的优缺点
HMM模型将标注看作马尔可夫链,一阶马尔可夫链式针对相邻标注的关系进行建模,其中每个标记对应一个概率函数。HMM是一种产生式模型,定义了联合概率分布 ,其中x和y分别表示观察序列和相对应的标注序列的随机变量。为了能够定义这种联合概率分布,产生式模型需要枚举出所有可能的观察序列,这在实际运算过程中很困难,因为我们需要将观察序列的元素看做是彼此孤立的个体即假设每个元素彼此独立,任何时刻的观察结果只依赖于该时刻的状态。
HMM模型的这个假设前提在比较小的数据集上是合适的,但实际上在大量真实语料中观察序列更多的是以一种多重的交互特征形式表现,观察元素之间广泛存在长程相关性。在命名实体识别的任务中,由于实体本身结构所具有的复杂性,利用简单的特征函数往往无法涵盖所有的特性,这时HMM的假设前提使得它无法使用复杂特征(它无法使用多于一个标记的特征。
HMM的优点是计算相对较快。
2. ME的优缺点
最大熵模型可以使用任意的复杂相关特征,在性能上最大熵分类器超过了Byaes分类器。但是,作为一种分类器模型,这两种方法有一个共同的缺点:每个词都是单独进行分类的,标记之间的关系无法得到充分利用,具有马尔可夫链的HMM模型可以建立标记之间的马尔可夫关联性,这是最大熵模型所没有的。
最大熵模型的优点:(1)最大熵统计模型获得的是所有满足约束条件的模型中信息熵极大的模型;(2)最大熵统计模型可以灵活地设置约束条件,通过约束条件的多少可以调节模型对未知数据的适应度和对已知数据的拟合程度;(3)它还能自然地解决了统计模型中参数平滑的问题。
最大熵模型的不足:(1)最大熵统计模型中二值化特征只是记录特征的出现是否,而文本分类需要知道特征的强度,因此,它在分类方法中不是最优的;(2)由于算法收敛的速度较慢,所以导致最大熵统计模型它的计算代价较大,时空开销大;(3)数据稀疏问题比较严重。
3. MEMM的优缺点
最大熵马尔科夫模型把HMM模型和maximum-entropy模型的优点集合成一个产生式模型,这个模型允许状态转移概率依赖于序列中彼此之间非独立的特征上,从而将上下文信息引入到模型的学习和识别过程中,提高了识别的精确度,召回率也大大的提高,有实验证明,这个新的模型在序列标注任务上表现的比HMM和无状态的最大熵模型要好得多。
4. CRF的优缺点
HMM模型中存在两个假设:一是输出观察值之间严格独立,二是状态的转移过程中当前状态只与前一状态有关(一阶马尔可夫模型)。
MEMM模型克服了观察值之间严格独立产生的问题,但是由于状态之间的假设理论,使得该模型存在标注偏置问题。
CRF模型解决了标注偏置问题,去除了HMM中两个不合理的假设。当然,模型相应得也变复杂了。
CRF模型的特点:
(1)CRF在给定了观察序列的情况下,对整个的序列的联合概率有一个统一的指数模型。一个比较吸引人的特性是其 损失函数 的凸面性。
(2)CRF相比较MEMM,定义了多种特征模板,可以更好更多的利用待识别文本中所提供的上下文信息以得更好的实验结果。并避免了严格的独立性假设和数据归纳偏置问题。有测试结果表明:在采用相同特征集合的条件下,条件随机域模型较其他概率模型有更好的性能表现。
CRFs与最大熵模型的本质区别是:最大熵模型在每个状态都有一个概率模型,在每个状态转移时都要进行归一化。如果某个状态只有一个后续状态,那么该状态到后续状态的跳转概率即为1。这样,不管输入为任何内容,它都向该后续状态跳转。而CRFs是在所有的状态上建立一个统一的概率模型,这样在进行归一化时,即使某个状态只有一个后续状态,它到该后续状态的跳转概率也不会为1,从而解决了“label bias”问题。因此,从理论上讲,CRFs非常适用于中文的词性标注。
CRF模型的优点:
(1)CRF模型由于其自身在结合多种特征方面的优势和避免了标记偏置问题。其次,CRF的性能更好,CRF对特征的融合能力比较强,
(2)对于实例较小的时间类ME来说,CRF的识别效果明显高于ME的识别结果。
CRF模型的不足:
(1)通过对基于CRF的结合多种特征的方法识别英语命名实体的分析,发现在使用CRF方法的过程中,特征的选择和优化是影响结果的关键因素,
(2)特征选择问题的好与坏,直接决定了系统性能的高低。其次,训练模型的时间比ME更长,且获得的模型很大,在一般的PC机上无法运行。