一、ftrace架构
Linux ftrace中,trace类型最基础的就是:tracer和event这两类。如下图所示:
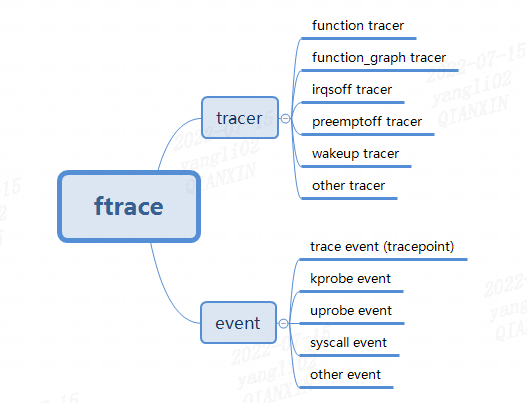
tracer发展出了function、function_graph、irqsoff、preemptoff、wakeup等一系列tracer。
event发展出tracepoint、kprobe、uprobe等一系列的event。
trace采集数据的方法一般分为两种:插桩、采样。
二、Ring Buffer
请参考:https://pwl999.blog.csdn.net/article/details/80349025
三、tracer原理
gcc使用了”-gp ,用_mcount()函数进行插桩,默认的_mcount函数是空操作:
#ifdef CONFIG_FUNCTION_TRACER
#ifdef CC_USING_FENTRY
# define function_hook __fentry__
#else
# define function_hook mcount
#endif
#ifdef CONFIG_DYNAMIC_FTRACE
ENTRY(function_hook)
retq
END(function_hook)
每个函数入口插入对_mcount()函数的调用,就是gcc提供的插桩机制。我们可以重新定义_mcount()函数中的内容,调用想要执行的内容。
确切的mcount符号名称将取决于具体工具链。可能是:
“mcount”、“_mcount”,“__mcount“,“__fentry__”
通过运行以下命令来确定:
[root@localhost ~]# uname -r
3.10.0-957.el7.x86_64
[root@localhost ~]# echo 'main(){}' | gcc -x c -S -o - - -pg | grep mcount
call mcount
其中,“-pg “参数的作用是,给编译出来的函数开头都插入一条指令”call mcount”。通过编译的方式,我们可以给函数加上一个额外的hook点,但是这个额外”mcount”函数调用的开销是较大的,因此ftrace在内核启动的时候做了一件事,就是把内核每个函数里的第一条指令”call mcount”(5个字节),替换成了”nop”指令(五个字节),也就是一条空指令,表示什么都不做。
内核二进制文件vmlinux中附加了一个mcount_loc的段,这个段里记录了所有”call mcount”指令的地址。这样我们很容易就能找到每个函数的这个入口点。
在编译的时候调用recordmcount.pl脚本文件搜集所有mcount()函数的调用点,并且所有的调用点地址保存到section mcount_loc。
CONFIG_FTRACE_MCOUNT_RECORD=y
// /include/asm-generic/vmlinux.lds.h
#ifdef CONFIG_FTRACE_MCOUNT_RECORD
#define MCOUNT_REC() . = ALIGN(8); \
VMLINUX_SYMBOL(__start_mcount_loc) = .; \
*(__mcount_loc) \
VMLINUX_SYMBOL(__stop_mcount_loc) = .;
内核初始化时,遍历section mcount_loc的调用点地址,默认给所有“call mcount”替换成“nop”
start_kernel()
-->ftrace_init()
extern unsigned long __start_mcount_loc[];
extern unsigned long __stop_mcount_loc[];
void __init ftrace_init(void)
{
unsigned long count;
......
count = __stop_mcount_loc - __start_mcount_loc;
ret = ftrace_dyn_table_alloc(count);
if (ret)
goto failed;
last_ftrace_enabled = ftrace_enabled = 1;
//“call mcount”替换成“nop”
ret = ftrace_process_locs(NULL,
__start_mcount_loc,
__stop_mcount_loc);
......
}
虽然是空指令,不过在内核的代码段里,这相当于给每个函数预留了5个字节。这样在需要的时候,内核可以再把这5个字节替换成callq指令,call的函数就可以指定成我们需要的函数了。
同时,内核的mcount_loc段里,虽然已经记录了每个函数”call mcount”的地址,不过对于ftrace来说,除了地址之外,它还需要一些额外的信息。
因此,在内核启动初始化的时候,ftrace又申请了新的内存来存放mcount_loc段中原来的地址信息,外加对每个地址的控制信息,最后释放了原来的mcount_loc段。
申请了新的内存来存放mcount_loc段:
ftrace_init()
-->ftrace_process_locs()
-->ftrace_allocate_pages()
将“call mcount”替换成“nop”:
ftrace_init()
-->ftrace_process_locs()
-->ftrace_update_code()
/*
* Do the initial record conversion from mcount jump
* to the NOP instructions.
*/
-->ftrace_code_disable()
-->ftrace_make_nop()
ftrace_make_nop将call指令替换成nop指令:
int ftrace_make_nop(struct module *mod,
struct dyn_ftrace *rec, unsigned long addr)
{
unsigned const char *new, *old;
unsigned long ip = rec->ip;
old = ftrace_call_replace(ip, addr);
new = ftrace_nop_replace();
/*
* On boot up, and when modules are loaded, the MCOUNT_ADDR
* is converted to a nop, and will never become MCOUNT_ADDR
* again. This code is either running before SMP (on boot up)
* or before the code will ever be executed (module load).
* We do not want to use the breakpoint version in this case,
* just modify the code directly.
*/
if (addr == MCOUNT_ADDR)
return ftrace_modify_code_direct(rec->ip, old, new);
/* Normal cases use add_brk_on_nop */
WARN_ONCE(1, "invalid use of ftrace_make_nop");
return -EINVAL;
}
相对应的函数将nop指令替换成call指令:
int ftrace_make_call(struct dyn_ftrace *rec, unsigned long addr)
{
unsigned const char *new, *old;
unsigned long ip = rec->ip;
old = ftrace_nop_replace();
new = ftrace_call_replace(ip, addr);
/* Should only be called when module is loaded */
return ftrace_modify_code_direct(rec->ip, old, new);
}
所以Linux内核在机器上启动之后,在内存中的代码段和数据结构就会发生变化。可以参考后面这张图,它描述了变化后的情况:
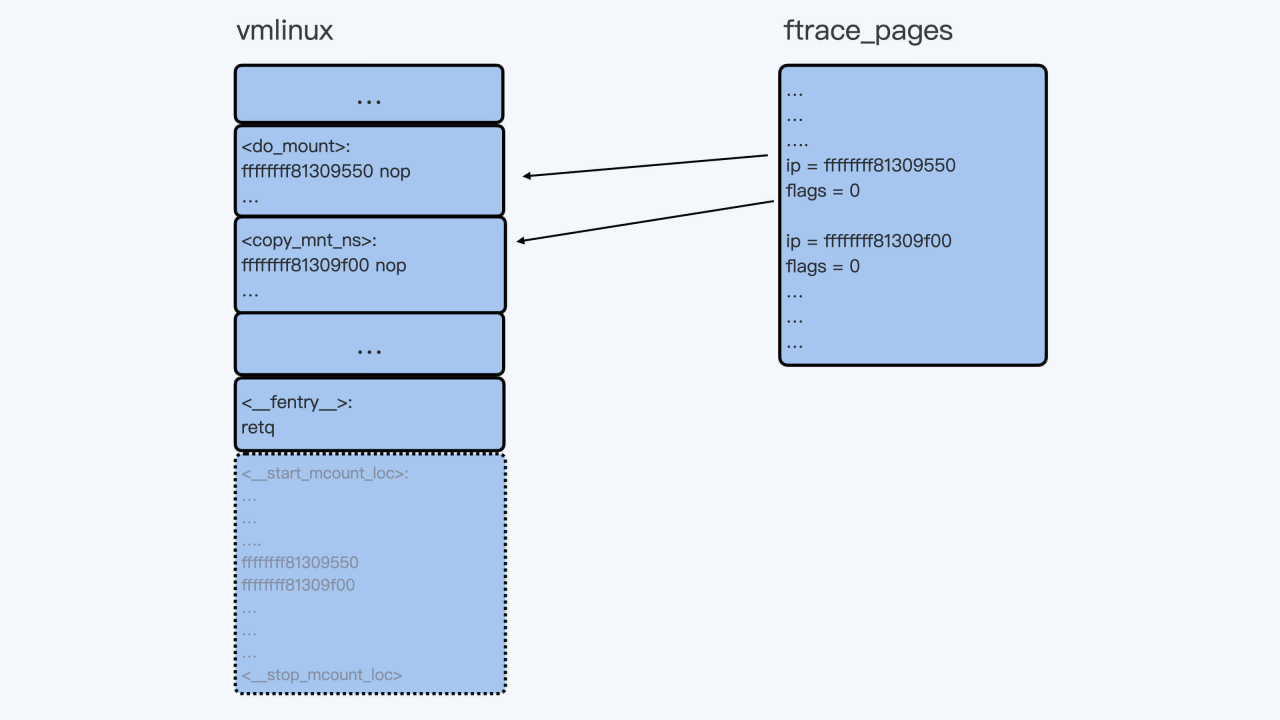
当我们需要用function tracer来trace某一个函数的时候,比如”echo do_mount > set_ftrace_filter”命令执行之后,do_mount()函数的第一条指令就会被替换成调用ftrace_caller的指令。如下所示:
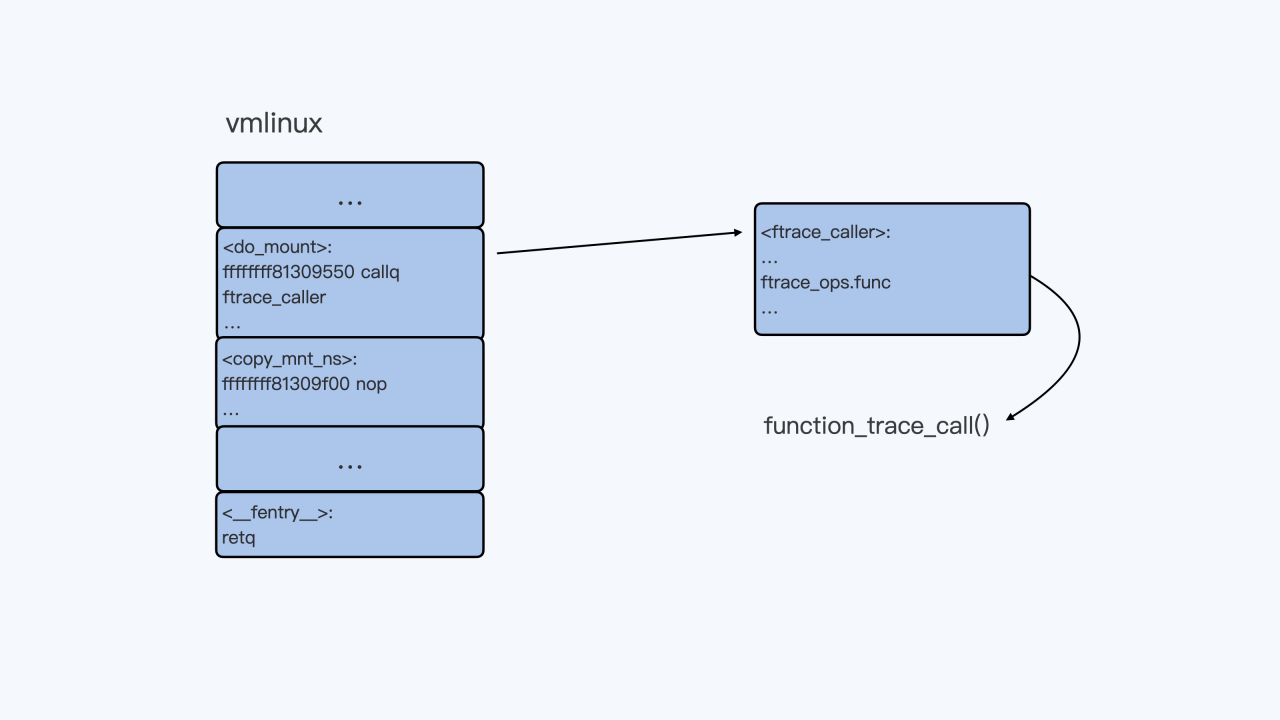
这样,每调用一次do_mount()函数,它都会调用function_trace_call()函数,把ftrace function trace信息放入ring buffer里,再通过tracefs输出给用户。
图片来自于:极客时间容器实战高手课
详细原理请参考:
https://blog.csdn.net/pwl999/article/details/80627095
https://rtoax.blog.csdn.net/article/details/120925737
3.1 静态插桩
重定义_mcount()函数的方法来实现插桩。static ftrace一旦使能,对kernel中所有的函数(除开notrace、online、其他特殊函数)进行插桩,这带来的性能开销非常,一般不会使用。
3.2 动态插桩
调用者一般不需要对所有函数进行追踪,只会对感兴趣的一部分函数进行追踪。dynamic ftrace把不需要追踪的函数入口处指令“bl _mcount”替换成nop,这样基本上对性能无影响,对需要追踪的函数替换入口处”bl _mcount”为需要调用的函数。
如果设置了 CONFIG_DYNAMIC_FTRACE,则在禁用函数跟踪时系统将几乎没有开销运行。 它的工作方式是 mcount 函数调用(放置在每个内核函数的开头,由 gcc 中的 -pg 开关产生),开始指向一个简单的返回。 (启用 FTRACE 将在内核编译中包含 -pg 开关。)
在编译时,每个 C 文件对象都通过 recordmcount 程序(位于脚本目录中)运行。 该程序将解析 C 对象中的 ELF 标头以查找 .text 部分中调用 mcount 的所有位置。 从 gcc 版本 4.6 开始,为 x86 添加了 -mfentry,它调用“fentry”而不是“mcount”。 在创建堆栈帧之前调用它。
请注意,并非所有部分都被跟踪。 它们可能会被 notrace 阻止,或者以其他方式阻止,并且不会跟踪所有内联函数。 检查“available_filter_functions”文件以查看可以跟踪哪些功能。
创建了一个名为“__mcount_loc”的部分,其中包含对 .text 部分中所有 mcount/fentry 调用站点的引用。 recordmcount 程序将此部分重新链接回原始对象。 内核的最后链接阶段会将所有这些引用添加到一个表中。
在启动时,在初始化 SMP 之前,动态 ftrace 代码会扫描此表并将所有位置更新为 nop。 它还记录添加到 available_filter_functions 列表中的位置。 模块在加载时和执行之前进行处理。 当一个模块被卸载时,它也会从 ftrace 函数列表中删除它的函数。 这在模块卸载代码中是自动的,模块作者无需担心。
启用跟踪时,修改功能跟踪点的过程取决于体系结构。 旧的方法是使用 kstop_machine 来防止 CPU 与执行代码的竞争被修改(这可能导致 CPU 做不受欢迎的事情,特别是如果修改的代码跨越缓存(或页面)边界),并且 nop 被修补回调用 . 但是这一次,他们没有调用 mcount(这只是一个函数存根)。 他们现在调用 ftrace 基础设施。
修改函数跟踪点的新方法是在要修改的位置下一个断点,同步所有CPU,修改断点未覆盖的其余指令。 再次同步所有 CPU,然后将带有完成版本的断点移至 ftrace 调用站点。
有些archs甚至不需要进行同步,并且可以将新代码放在旧代码之上,而其他 CPU 同时执行它时不会出现任何问题。
记录被跟踪函数的一个特殊副作用是,我们现在可以有选择地选择希望跟踪哪些函数,以及希望mcount调用保留nops。
使用了两个文件,一个用于启用,一个用于禁用对指定功能的跟踪。 他们是:
set_ftrace_filter
set_ftrace_notrace
可以添加到这些文件中的可用函数列表如下:
available_filter_functions
[root@localhost tracing]# cat available_filter_functions | more
__startup_secondary_64
run_init_process
do_one_initcall
match_dev_by_uuid
name_to_dev_t
rootfs_mount
rootfs_mount
calibrate_delay
x86_pmu_extra_regs
x86_pmu_disable
collect_events
x86_pmu_event_idx
x86_pmu_sched_task
get_segment_base
perf_get_x86_pmu_capability
perf_assign_events
events_sysfs_show
x86_pmu_commit_txn
x86_pmu_add
x86_pmu_start_txn
set_attr_rdpmc
get_attr_rdpmc
x86_pmu_cancel_txn
x86_pmu_notifier
allocate_fake_cpuc
change_rdpmc
x86_perf_event_update
x86_pmu_stop
x86_pmu_del
x86_reserve_hardware
x86_pmu_event_init
x86_release_hardware
hw_perf_event_destroy
x86_add_exclusive
x86_del_exclusive
hw_perf_lbr_event_destroy
......
当我们需要用function tracer来trace某一个函数的时候,比如”echo do_mount > set_ftrace_filter”命令执行之后,do_mount()函数的第一条指令就会被替换成调用ftrace_caller的指令。
四、trace event
trace event的插桩使用的是tracepoint机制,该机制是一种静态的插桩方法,它需要静态的定义桩函数,并且在插桩位置显式调用。这种方法的好处是高效可靠,并且可以处于函数中的任何位置、方便的访问各种变量,坏处是不太灵活。对于kernel在重要的节点固定位置,插入了几百个trace event用于跟踪。
五、kprobe event
从前面几章看:trace event使用静态tracepoint插桩,function tracer使用“call mcount”的插桩点来动态插桩。既然都是插桩,为什么我们不使用功能强大的kprobe机制?
kprobe event就是这样的产物。krpobe event和trace event的功能一样,但是因为它采用的是kprobe插桩机制,所以它不需要预留插桩位置,可以动态的在任何位置进行插桩。开销会大一点,但是非常灵活,是一个非常方便的补充机制。
kprobe的主要原理是使用“断点异常”和“单步异常”两种异常指令来对任意地址进行插桩,在此基础之上实现了三种机制:
(1)kprobe: 可以被插入到内核的任何指令位置,在被插入指令之前调用kp.pre_handler(),在被插入指令之后调用kp.post_handler()
(2)jprobe: 只支持对函数进行插入
(3)kretprobe: 和jprobe类似,机制略有不同,会替换被探测函数的返回地址,让函数先执行插入的钩子函数,再恢复。
参考资料
Linux 3.10.0
极客时间容器实战高手课
https://blog.csdn.net/u012489236/article/details/119494200
https://blog.csdn.net/dog250/article/details/84667690
https://rtoax.blog.csdn.net/article/details/120925737
https://blog.csdn.net/jasonactions/article/details/120940323