babel之路的起点
开始的起点
因为最近开始学习babel,我想简单了解一下一个编译工具工作原理。又因为编译功能这一块来说还是相对抽象了一点。所以我找到了一个学习的项目。
学习项目:https://github.com/jamiebuilds/the-super-tiny-compiler
说是一个超小的编译器不如说是一个简单编译器工作原理的教学,毕竟官网就有这么一句话:This is an ultra-simplified example of all the major pieces of a modern compiler written in easy to read JavaScript.,同时我们通过这些简短的源码我们可以发现作者在其中写了很多的注释,非常易于理解。
项目作者通过lisp代码到js代码的转换简洁明了地让我们知道编译器的核心部份。
核心功能
在编译的过程中有两项非常重要的操作:Lexical Analysis(词法分析)与Syntactic Analysis(语法分析)
tokenizer,parser, transformer,generator
tokenizer
可以说是非常简单的词法分析
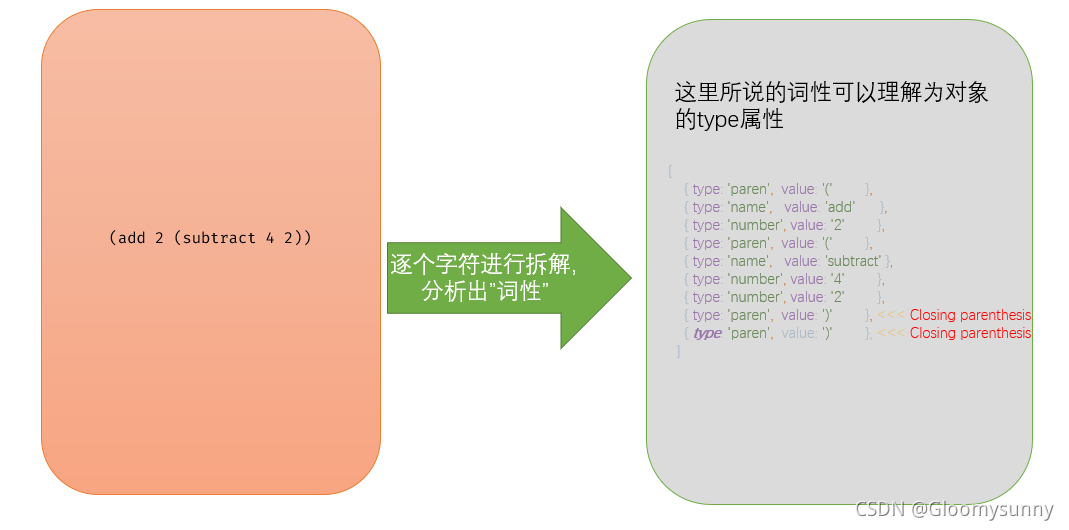
parser
语法分析,这个项目中的语法分析相对较为简单,没有多个操作符表达式的分析,主要针对以上的closing parenthesis(闭合括号进行不同的分析)。
这里主要是吧上面单个的字符对象进行关联性的组合,生成AST。
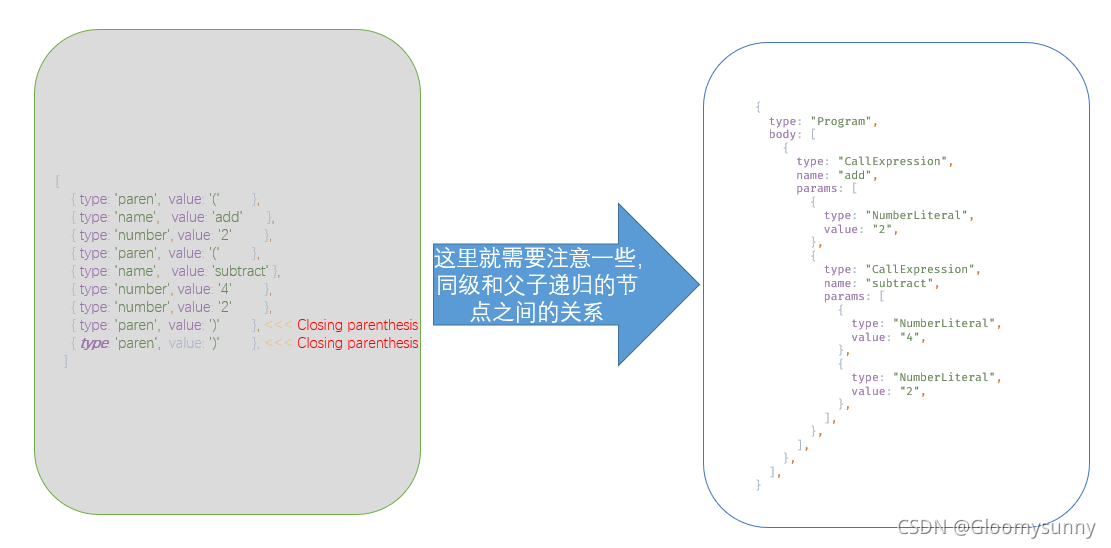
transformer
转换器,将语法树进行修改后再放给generator。其中主要的转换控制由vistor提供条件(可以是节点的约束,或者节点访问前后的钩子函数),具体会在后面的babel基本知识中讲到。
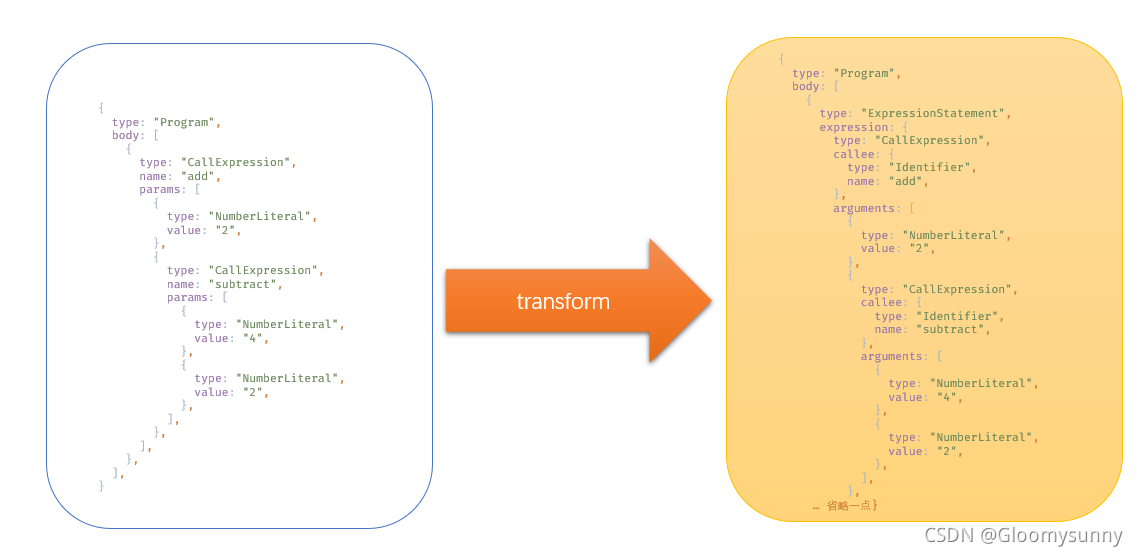
这里为什么要在CallExpression对象外包一个ExpressionStatement,注释中说法是对标js通常语法块的形式。
在源码中核心功能函数为traverseNode
generator
生成器:依据最终文件的代码语法以及AST的节点关系来进行code生成
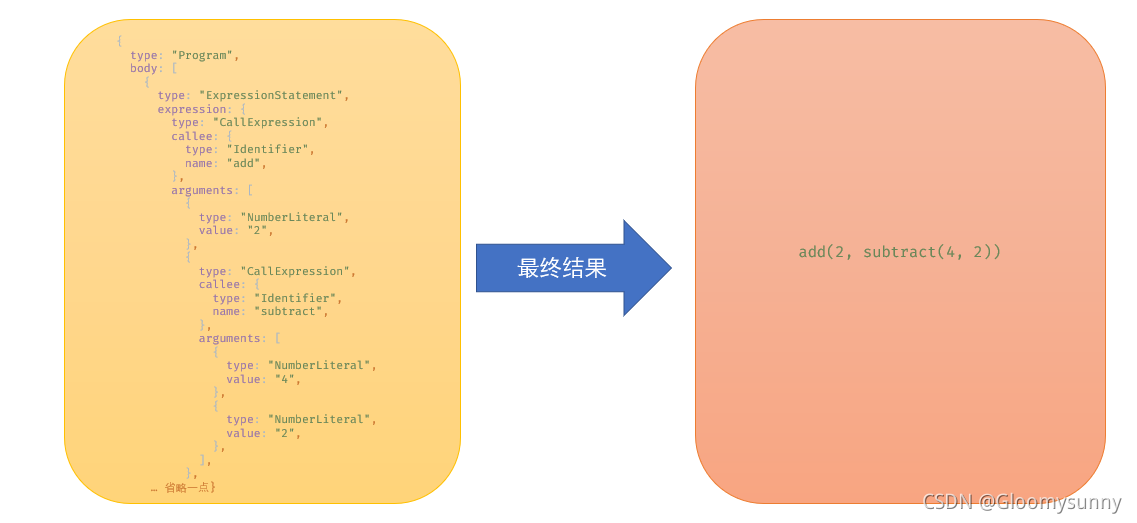
以上就是从Lisp语法到js语法的简答编译。
这里没有贴出什么重要代码的理解是因为作者将代码写得非常易懂,只需要花费很少的时间你就能通过js理解编译器核心的工作内容。
babel入门知识
babel是什么?
Babel 是一个通用的 JavaScript 多用途编译器,再简单一点babel是个编译器。
babel是怎么样实现各式各样的需求的呢?
通过插件,babel有一个庞大的插件库,同时babel提供了我们自定义插件的能力。
更多的如何配置.babelrc或者如何使用babel-cli可以在babel的官网或者https://github.com/jamiebuilds/babel-handbook/blob/master/translations/en/user-handbook.md 进行了解。
怎么去写一个自己的插件?
这里是esTree概况:https://github.com/babel/babel/blob/master/packages/babel-parser/ast/spec.md#node-objects,其中最上面的目录以层级关系展示了各个节点类型之间的关系。
下面说说写一个插件的基本知识
插件基本知识
babel在做文件transfer时存在三个阶段:解析,转换,生成文件
Visitors(访问者)
这是babel中使用的访问节点的一个设计模式。
访问者模式的使用场景:
- 对象结构比较稳定,但经常需要在此对象结构上定义新的操作。
- 需要对一个对象结构中的对象进行很多不同的并且不相关的操作,而需要避免这些操作“污染”这些对象的类,也不希望在增加新操作时修改这些类。
在访问node时,babel提供给我们两个时机。
Paths
一个Path对象代表了两个Node对象之间的关系。同时Paths对象是响应式的当节点发生改变可能会引起他的改变。
当我们使用我们的babel中访问者对象的Identifier方法时,我们实际上是在访问Path对象而不是Node(Node不存在与其他同级父级节点的关系),与同级父级节点的关系通过path表达。
const MyVisitor = {
Identifier(path) {
console.log("Visiting: " + path.node.name);
}
};
a + b + c;
path.traverse(MyVisitor);
//result
Visiting: a
Visiting: b
Visiting: c
scope
作用域之间的关系
Babel API
Babel is actually a collection of modules. In this section we’ll walk through the major ones, explaining what they do and how to use them.(这句话讲述了babel的本质就是一堆模块)
更加详细的文档位置:https://babeljs.io/docs/en/babel-core/
@babel-parser
sourceType 默认是 "script" ,如果解析过程中遇到 import or export会报错,所以当需要import或者export时,将sourceType进行修改为”module”
parser.parse(code, {
sourceType: "module", // default: "script"
plugins: ["jsx"] // default: []
});
@babel-traverse
主要维护修改esTree的功能
@babel-types
babel提供的高效操作库,提供了一些功能函数
import traverse from "@babel/traverse";
import * as t from "@babel/types";
traverse(ast, {
enter(path) {
if (t.isIdentifier(path.node, { name: "n" })) {//isIdentifier就是我们path.node.type == "Identifier"
path.node.name = "x";
}
}
});
@babel-generator
将AST语法树转换成我们书写的源码形式。
import t from "@babel/types";
import generate from "@babel/generator";
console.log(
generate.default(
t.binaryExpression("*", t.identifier("a"), t.identifier("b"))
)
);
@babel-template
一个方便我们编写语法树的功能
import t from "@babel/types";
import generate from "@babel/generator";
import template from "@babel/template";
import fs from "fs";
const buildRequire = template.default(`
var IMPORT_NAME = require(SOURCE);
`);
const ast = buildRequire({
IMPORT_NAME: t.identifier("myModule"),
SOURCE: t.stringLiteral("my-module"),
});
const pathname = "./output.js";
if (!fs.existsSync(pathname)) {
fs.writeFile(pathname, generate.default(ast).code, (err) => {
if (err) console.warn(err);
});
}
执行上面的程序,我们会在output.js文件中看到
var myModule = require("my-module");
@babel-core
const babel = require("@babel/core");
const t = babel.types;
const code = `foo === bar;`;
const result = babel.transformSync(code, {
plugins: [
{
visitor: {
BinaryExpression(path) {
if (path.node.operator !== "===") {
return;
}
path.node.left = t.identifier("sebmck");
path.node.right = t.identifier("dork");
},
},
},
],
});
console.log(result.code); //sebmck === dork;
这里我们的@babel/core实际上是我们上面介绍的的许多微小插件的集合,这里体现的就是的babel微内核的特点,其功能均由插件拓展而来,内核仅提供核心功能。
import { GeneratorOptions } from '@babel/generator';
import { ParserOptions } from '@babel/parser';
import template from '@babel/template';
import traverse, { Hub, NodePath, Scope, Visitor } from '@babel/traverse';
import * as t from '@babel/types';
export { ParserOptions, GeneratorOptions, t as types, template, traverse, NodePath, Visitor };
这段可以看出@babel/core导出对象的功能
transform时的操作
访问
path.node.property:访问到节点
path.get(dotpath):访问节点的path对象
BinaryExpression(path) {
path.node.left;
path.node.right;
path.node.operator;
}
path.get('body.0');
检查节点的类型
做transform时我们通常会有一个或者说是一些我们希望更改的节点,这个时候可以用下面的方式进行检查
BinaryExpression(path) {
if (t.isIdentifier(path.node.left, { name: "n" })) {
// ...
}
}
功能上等价于:
BinaryExpression(path) {
if (
path.node.left != null &&
path.node.left.type === "Identifier" &&
path.node.left.name === "n"
) {
// ...
}
}
检查路径(Path)类型
检查标识符(Identifier)是否被引用
这里两个并没有粘上示例代码主要的原因是:这两个操作与检查节点类型十分相似,同时我们又已经了解了访问的操作。而这些检查实际上都是@babel/types包下的操作。所以只需要在实际应用中想到有这么一个操作然后查查上面发的handle-book或者babel文档就好(后者更优)
找到特定的父路径
有时我们需要从当前path找一个合适的父级path。
path.findParent((path) => path.isObjectExpression());
这个findParent()就是提供一个参数为父级path的callback,然后不断向上遍历直到父级path满足return 条件
获取同级路径
在一个代码块或文件中,我们经常写一些同级的节点。所以针对一个path寻找他的同级操作也是需要的。与之相关的有以下操作。
path.inList:检查一个path是否在一个同级列表中,相当于检查是否有同级元素path.key:检查一个path在Container中的index(打印过的path对象的我们应该知道,container也是其中的一项信息)path.getSibling(index):我们可以找到index代表的同级的path对象,index与path.key有关`path.container:容纳同级path的数组path.listKey:获取容器的key
停止path遍历
-
写一个停止的return条件
const visitor = { xxxExpression(path) { return } } -
调用
path.skip()、path.stop(),我暂时还不知道怎么用。- ok,
path.stop()的情形碰到了,比如说我的访问者对象是访问一个StringLiteral但是我在对这个p作时又生成了StringLiteral,这种情况因为我们的StringLiteral会被马上加到AST中,然后就又会被访问者对象访问到,会一直循环,我们只需要在最后调用path.stop()即可,下面这段代码已经可以充分说明问题了,虽然这是我写错的时候写出来的 - 一个demo把两个方法调用都搞明白了,如果调用
path.stop(),针对当前访问方法不再继续,会停止访问者当前层级树节点遍历,然后就会像树遍历一样一层一层退出,所以调用path.stop(),'Hello ' + name中的name不会被反转。而如果调用path.skip(),就会跳过接下来对于StringLiteral的遍历,所以程序能够访问到name并根据代码把name更换成eman
const babel = require("@babel/core"); const t = babel.types; const fs = require("fs"); const code = ` function greet(name) { return 'Hello ' + name; } console.log(greet('abao')); `; const output = babel.transformSync(code, { plugins: [ function myCustomPlugin() { return { visitor: { StringLiteral(path) { const concat = path.node.value .split("") .map((c) => babel.types.stringLiteral(c)) .reduce((prev, curr) => { return babel.types.binaryExpression("+", prev, curr); }); path.replaceWith(concat); path.skip(); }, Identifier(path) { if ( t.isFunctionDeclaration(path.parent) || t.isCallExpression(path.parent) || t.isBinaryExpression(path.parent) ) { path.node.name = path.node.name.split("").reverse().join(""); } }, }, }; }, ], }); /** * output.code的输出结果: * function teerg(eman) { * return "H" + "e" + "l" + "l" + "o" + " " + eman; * } * * console.log(teerg("a" + "b" + "a" + "o")); */ const pathname = "./out-reverse.js"; fs.writeFile(pathname, output.code, (err) => { if (err) console.warn(err); }); - ok,
增、删、改节点StringLiteral
看一下代码就知道怎么回事了,还有一些其他的更换方式大同小异都在这个链接里:https://github.com/jamiebuilds/babel-handbook/blob/master/translations/en/plugin-handbook.md#manipulation
BinaryExpression(path) {
path.replaceWith(
t.binaryExpression("**", path.node.left, t.numberLiteral(2))
);
}
scope(作用域)
检查作用域与变量的关系
path.scope.hasBinding("n")
// 检查作用域中(会沿作用域链查找)是否有n变量
path.scope.hasOwnBinding("n")
// 只在自己的作用域中查找是否有n变量
这里主要handle-book说的有点含糊,我也没有去看官文。我通过下面的例子证实了我的猜想。
const code = `
function qq() {
let a = 1;
function cb() {
}
}
`;
const result = babel.transformSync(code, {
plugins: [
{
visitor: {
FunctionDeclaration(path) {
console.log(path.scope.hasOwnBinding("a")); //改成path.scope.hasBinding后再次证实一次
},
},
},
],
});
提升变量声明至父级作用域
有时你可能想要推送一个` VariableDeclaration </>,这样你就可以分配给它。
FunctionDeclaration(path) {
const id = path.scope.generateUidIdentifierBasedOnNode(path.node.id);
path.remove();
path.scope.parent.push({ id, init: path.node });
}
- function square(n) {
- return n * n;
+ function square(x) {
+ return x * x;
}
最佳实践
我认为最佳的实践肯定是一些小项目,handle-book的应该被称为项目中比较实用的技巧。
1.创建帮助函数
function isAssignment(node) {//判断是否为赋值操作
return node && node.operator === opts.operator + "=";
}
function buildAssignment(left, right) {//写了一个helper函数方便之后调用只需要传两个参数
return t.assignmentExpression("=", left, right);
}
2.尽可能合并访问者对象
因为一个traverse操作的成本比较高,将多个表达式的匹配放在一个visitor中可以减少调用traverse的次数
-path.traverse({
- Identifier(path) {
- // ...
- }
-});
-path.traverse({
- BinaryExpression(path) {
- // ...
- }
-});
+path.traverse({
+ Identifier(path) {
+ // ...
+ },
+ BinaryExpression(path) {
+ // ...
+ }
+});
3.在可以不用traverse的时候尽可能不用
-const nestedVisitor = {
- Identifier(path) {
- // ...
- }
-};
const MyVisitor = {
FunctionDeclaration(path) {
- path.get('params').traverse(nestedVisitor); //这个traverse是可以不用调用的
+ path.node.params.forEach(function() {...});
}
};
4.优化嵌套的vistors
其实就是尽可能减少同一种功能的visitor的重复创建。
比如在函数局部作用域的声明,我们可以将其声明放在功能函数体之外。
const MyVisitor = {
FunctionDeclaration(path) {
path.traverse({ //path.traverse中传入的就是一个每次访问MyVisitor就会重复创建的一个visitor对象
Identifier(path) {
// ...
}
});
}
};
到这里第一阶段算是结束了,之后就要真正进入实战提升自己了。
更多入门级的操作也可以在这个链接中找到:https://github.com/jamiebuilds/babel-handbook/blob/master/translations/en/plugin-handbook.md