一、官网下载文件:
当前最新版本为1.0.0rc2
https://github.com/open-mmlab/mmsegmentation/releases/tag/v1.0.0rc2
下载源码解压文件可得到最新版的代码
二、配置环境:
这部分省略:按照给的README文件很快就配置好了
https://github.com/open-mmlab/mmsegmentation/blob/master/docs/en/get_started.md#installation
三、配置自己的dataset文件
1.首先进入到:mmseg/datasets文件夹下,在这里复制一份voc.py 命名为mydata.py
a.更改类名为MyDataset:
b.更改classes和palette为自己的类别和像素值
c.在__init__更改自己的图片和label后缀名
@DATASETS.register_module()
class MyDataset(BaseSegDataset):
"""Pascal VOC dataset.
Args:
split (str): Split txt file for Pascal VOC.
"""
METAINFO = dict(
# classes=('background', 'aeroplane', 'bicycle', 'bird', 'boat',
# 'bottle', 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable',
# 'dog', 'horse', 'motorbike', 'person', 'pottedplant', 'sheep',
# 'sofa', 'train', 'tvmonitor'),
# palette=[[0, 0, 0], [128, 0, 0], [0, 128, 0], [128, 128, 0],
# [0, 0, 128], [128, 0, 128], [0, 128, 128], [128, 128, 128],
# [64, 0, 0], [192, 0, 0], [64, 128, 0], [192, 128, 0],
# [64, 0, 128], [192, 0, 128], [64, 128, 128], [192, 128, 128],
# [0, 64, 0], [128, 64, 0], [0, 192, 0], [128, 192, 0],
# [0, 64, 128]]
classes=('wall', 'ceiling', '改为自己的类别'),
palette=[[157, 25, 239], [172, 57, 105], '改为自己的类别',]
)
def __init__(self,
ann_file,
img_suffix='.png',
seg_map_suffix='.png',
**kwargs) -> None:
super().__init__(
img_suffix=img_suffix,
seg_map_suffix=seg_map_suffix,
ann_file=ann_file,
**kwargs)
assert self.file_client.exists(
self.data_prefix['img_path']) and osp.isfile(self.ann_file)d.在mmseg/datasets/__init__.py中加入自己的数据名称

四、配置configs文件:
1.更改__base__
进入到configs/_base_/datasets
复制pascal_voc12.py一份命名为my_data.py
更改my_data.py中的
data_type : 为自己的数据类型,也就是”MyDataset”
data_root : 为自己的数据集的父文件夹路径
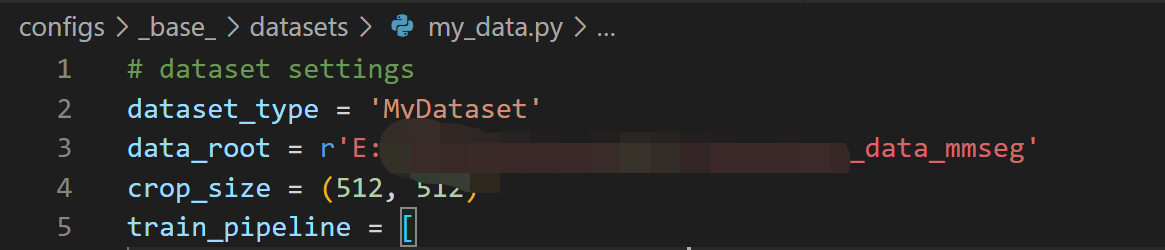
train_loader:
更改train_dataloader、val_dataloader、test_dataloader中的dataset[‘data_prefix’]
由于我的目录结构如下,所以更改项目路径如下
(其他参数根据需要自己更改即可)
train_dataloader = dict(
batch_size=4,
num_workers=4,
persistent_workers=True,
sampler=dict(type='InfiniteSampler', shuffle=True),
dataset=dict(
type=dataset_type,
data_root=data_root,
data_prefix=dict(
img_path='img', seg_map_path='mask'),
ann_file='train.txt',
pipeline=train_pipeline))
val_dataloader = dict(
batch_size=1,
num_workers=4,
persistent_workers=True,
sampler=dict(type='DefaultSampler', shuffle=False),
dataset=dict(
type=dataset_type,
data_root=data_root,
data_prefix=dict(
img_path='img', seg_map_path='mask'),
ann_file='val.txt',
pipeline=test_pipeline))
test_dataloader = val_dataloader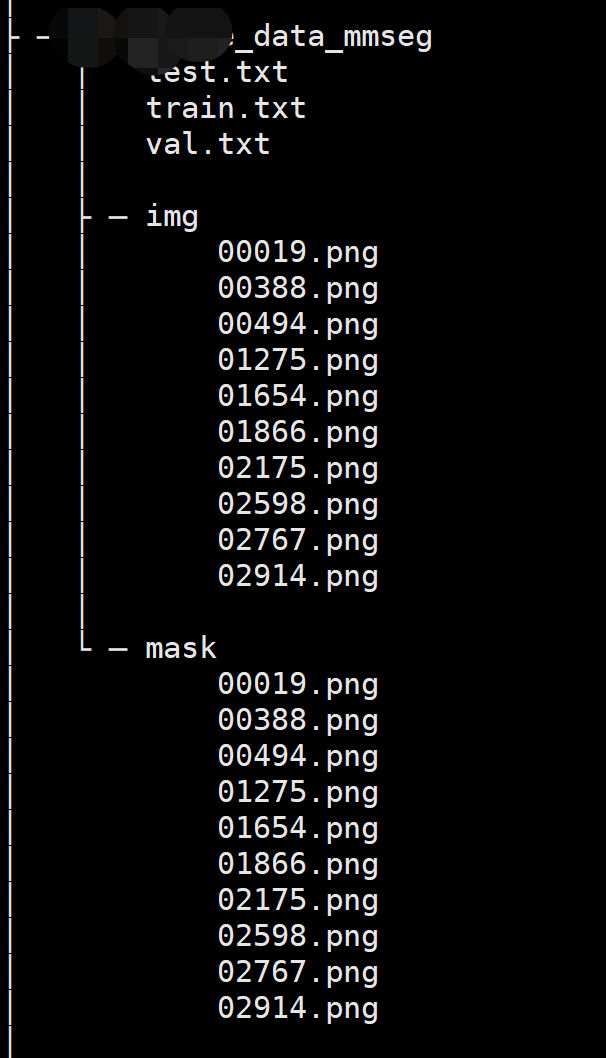
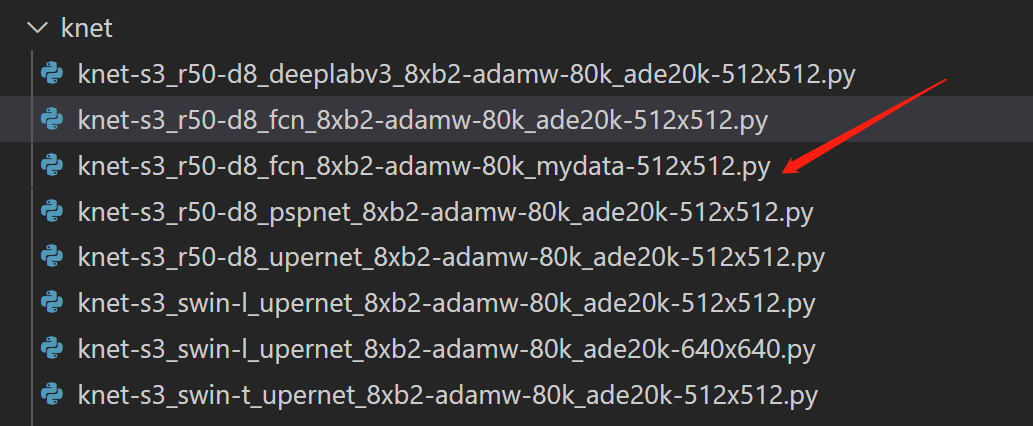
2.建立configs
复制configs/knet/knet-s3_r50-d8_fcn_8xb2-adamw-80k_ade20k-512×512.py
到configs/knet/knet-s3_r50-d8_fcn_8xb2-adamw-80k_mydata-512×512.py
更改自己的配置文件:
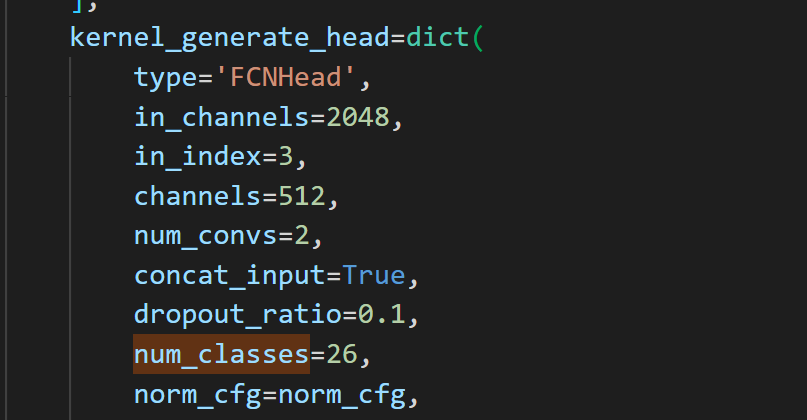
a.修改__base__继承的文件,删除原本的ade20k,改为刚刚添加的my_data.py

b.将model中所有的num_classes=150替换为自己的数据类别,当前版本有3处

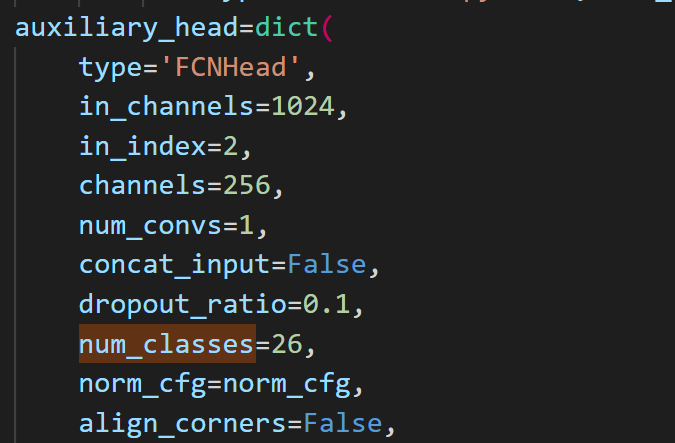
c.以下可选:
如果需要更改其他的默认设置,可参考 官网说明:
五、执行训练:
在完成上面的配置之后就可以进行模型的训练了
训练脚本:python + train.py+ configs文件地址
如下:
python .\tools\train.py configs\knet\knet-s3_r50-d8_fcn_8xb2-adamw-80k_mydata-512x512.py六、执行预测:
训练完成之后,如果没有设置自己的work_dir参数,默认所有的文件会保存在work_dirs文件夹下,
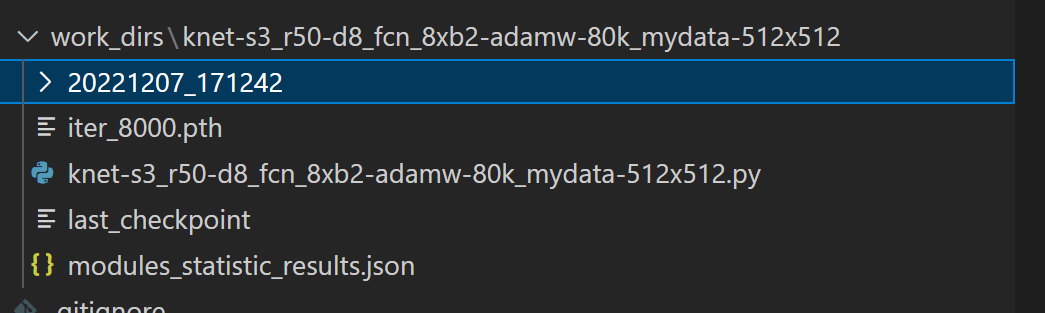
新建测试脚本infer.py如下:
from mmseg.apis import inference_model, init_model, show_result_pyplot
from mmseg.utils import register_all_modules
register_all_modules()
# 配置文件和权重的路径
config_file = r'configs\knet\knet-s3_r50-d8_fcn_8xb2-adamw-80k_mydata-512x512.py'
checkpoint_file = r'work_dirs\knet-s3_r50-d8_fcn_8xb2-adamw-80k_mydata-512x512\iter_8000.pth'
model = init_model(config_file, checkpoint_file, device='cuda:0')
# 需要进行预测的图片地址
img = r'.\img\00019.png'
result = inference_model(model, img)
# out_file为预测结果的保存路径
show_result_pyplot(model, img, result, out_file='result.jpg', opacity=0.5)

如果训练集没有问题的话可以进行正常的预测,本人在这里遇到了一个问题,预测的色卡和训练集的色卡无法形成对应,比如在训练集中:物体A对应的颜色为a,物体B对应的颜色为b,在预测的时候会发现物体A的颜色为b,物体B的颜色为c。最后查找原因是:训练集Mask的调色板每一张都不相同,在这里需要注意的是,按照上述方式进行,训练集的mask必须是8bit的格式,调色板必须根据自己的类别进行添加到图片中。下边提供函数可以帮助有此问题的朋友:
检查数据集调色板是否一致(脚本):
def read_palatte(img_path=None):
img = Image.open(img_path)
# print(type(img.getpalette()))
print(img.getpalette())
print(len(img.getpalette()))用这个函数去读取每个mask,如果打印的值每次都不一样或者其中的颜色值和自己的类别相差较大的话说明数据集是有问题的。下边会介绍调整数据集
七、深度学习图像分割Mask制作(不是从零):
制作的工具和方式有很多,可以进行分割的mask种类也很多,这里仅介绍8位伪彩图的核心的几个步骤,以下提到的mask均为8位伪彩图:
1.获取看起来正常的mask
a.不管使用任何工具:尽可能先得到从表面看起来比较正常的mask(各个物体颜色正常,放大之后没有斑点,),分割用的mask一般是png且mode为P格式的,如果得到的是jpg的或者mode非P,通常是需要进行转化的。
查看图片的mode:
msk = Image.open(msk_path)
assert msk.mode == 'P', "mode error"2.将mask转为数字类别图
这里采用中间格式的形式,先将原始的mask转为小数字类别灰度图,再将小数字的单通道图转为训练用8位伪彩图(我对灰度图有需求所以分为两步,但是这里可以合并成一步,有需要请自行合并)
def src_2_gray(src_mask_path, sv_gray_path):
# 注意将palette改为自己的调色板
palette = { 0: (157, 25, 239),
1: (172, 57, 105),
2: (166, 232, 11),
3: (86, 203, 240)}
src_mask = mmcv.imread(src_mask_path, channel_order='rgb')
gray_mask = np.zeros((src_mask.shape[0], src_mask.shape[1]), dtype=np.uint8)
for c, i in palette.items():
m = np.all(src_mask == np.array(c).reshape(1, 1, 3), axis=2)
gray_mask[m] = i
mmcv.imwrite(gray_mask, sv_gray_path)3.将数字类别图转为训练用的8位伪彩图:
def gray2color(img_path, save_path):
# '''
# img+path:类别灰度图
# save_path:存储路径
# '''
# 注意将PALETTE改为自己的调色板
PALETTE=[[157, 25, 239], [172, 57, 105], [166, 232, 11], [86, 203, 240]]
img = cv2.imread(img_path, cv2.IMREAD_GRAYSCALE)
img = Image.fromarray(img)
palette = []
for i in range(256):
palette.extend((i, i, i))
palette[:3*len(PALETTE)] = np.array(
lette, dtype='uint8').flatten()
img.putpalette(palette)
img.save(save_path)
经过上边两步得到的就是正常可训练的mask了
八、提取预测Mask
使用官方提供的预测脚本将将opacity设置为1.0 最终输出的是在原始rgb图上进行涂色之后的图像,因此生成的颜色值是不纯的,如果想提取比较纯净的mask,需要额外进行处理:
这里定义一个函数:
def gray2color(img, save_path='out_color_mask.png'):
PALETTE=[[157, 25, 239], [172, 57, 105], [166, 232, 11], [86, 203, 240]]
lette = PALETTE
img = Image.fromarray(img)
palette = []
for i in range(256):
palette.extend((i, i, i))
# 此处乘的是种类数量
palette[:3*len(lette)] = np.array(
lette, dtype='uint8').flatten()
img.putpalette(palette)
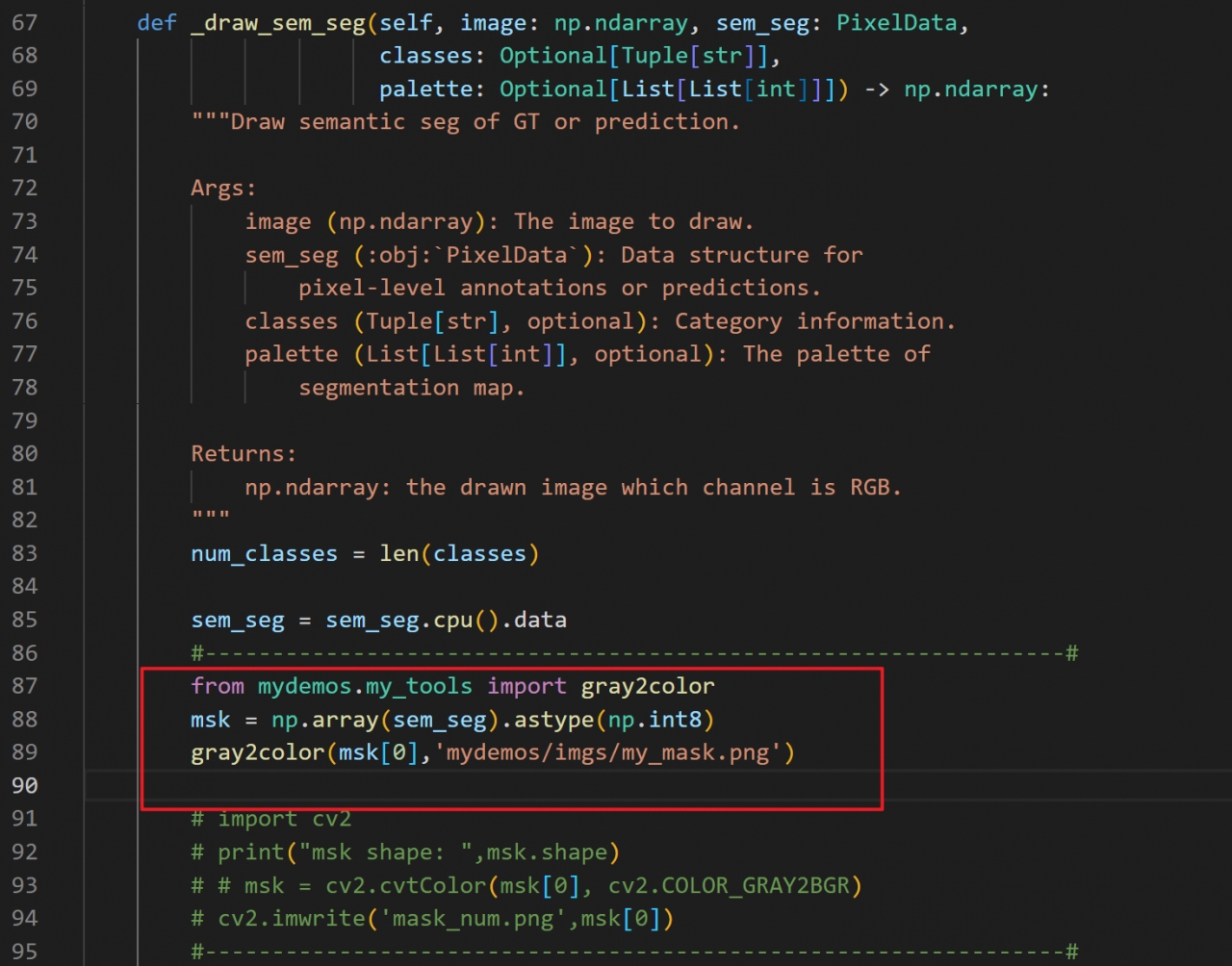
img.save(save_path)更改:mmseg/visualizatio/local_visualizer.py 中的SegLocalVisualizer类的_draw_sem_seg方法:引用这个函数即可生成纯净的mask图了
最终生成效果如下(只用了几张图训练,效果就一般般了):

(mmlab系列的工具大体上步骤都差不多,后边有空再更下其他几个的,希望能够帮助到需要的伙伴😊)