导读
在入道数据岗位之初,曾系列写过多个数据科学工具包的入门教程,包括Numpy、Pandas、Matplotlib、Seaborn、Sklearn等,这些也构成了自己当初的核心工具栈。在这5个工具包中,用于数据绘图的有2.5个(Pandas可以算0.5个),占比之高定与当时一度”沉迷”于简单而有效的可视化有关,可谓乐此不疲。时隔一年有余,在不断接触了Plotly这个可视化新贵之后,近期终于正式学习了一下这个包的使用、特性及优劣,并稍作整理、以资后鉴,遂成此文!

plotly绘图简洁高效可交互,值得一试!
01 为什么学习plotly
plotly,这个包名不可谓不直观,一看便知其一定是一个用来画图的工具;但同时,它仍然有失直观,因为plotly实际上是一个多语言绘图库,而当提及plotly时更可能的指代是JavaScript中的plotly。实际上,plotly本就是一个基于JavaScript的绘图库,然后引入到了Python中来,所以为了更具体的指代Python中的plotly,一般可称之为plotly.py。
plotly支持多语言平台
所以但是,为啥plotly不效仿Python中众多第三方库的做法,直接命名为pyplotly呢?毕竟这样的先例不在少数,例如pyecharts,pymysql,pytorch等。
进一步地,为什么在掌握了matplotlib和seaborn这两个近乎可以完成所有绘图需求之后,还要另外花费学习成本来上手plotly呢?或者说,plotly有哪些核心优势或者不可替代的地方?简言之:可交互性!是的,plotly的绘图是支持交互的,而这是matplotlib和seaborn所不具备的(更严谨地说,只是默认情况下不可交互)。
当然,可交互的绘图库也不止它一个,比如之前也尝试过pyecharts!但于我而言只是pyecharts的绘图结果需另开网页而略显繁琐,同时plotly的绘图语法与matplotlib和seaborn更为接近,学习门槛更加丝滑。基于上述丰富的内心活动之后,我选择了plotly,并最终决定系统学习和试手一下。
02 plotly能干什么
plotly作为一个可视化库,当然是能用来画图了,而且是多种丰富样式的图。所幸,这里不妨直接引用plotly官网的介绍:
The plotly Python library is an interactive, open-source plotting library that supports over 40 unique chart types covering a wide range of statistical, financial, geographic, scientific, and 3-dimensional use-cases.
几个关键字是:开源、可交互、支持40余种图表类型,涵盖统计、金融、地理、科学和3D图表。
看下官网直接给出的图表demo吧:
统计和科学图表系列

金融和地理图表系列

AI科学系列
更多的图表类型可以查看官网,简而言之,plotly功能还是齐全且强大的。
03 plotly如何绘图
既然本文定位为入门介绍系列,那么肯定是要介绍一下如何使用和上手的。
首先,python中安装plotly库的流程非常简单,且依赖很少(通过pip show plotly发现,其只有2个依赖包),无论是pip还是conda都可通过常规的install方式快速完成安装。
其次,给出plotly中各组成模块的整体介绍,以期从宏观上了解plotly的宏观架构和各模块定位。打开plotly源码文件夹,可以看到主要包含了以下几个subfolder,这也基本对应了plotly中的几个子模块:
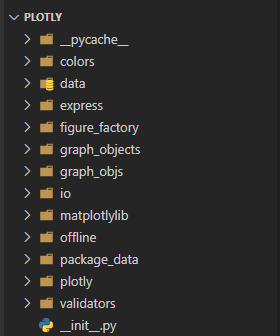
除上述subfolder,plotly另有若干独立.py文件
具体而言,应用plotly进行可视化时一般会涉及以下子模块:
-
express: plotly中用于可视化的高级API
-
graph_objects: 底层绘图接口,包含了所有图表对象和布局(graph_objs与其是同名包)
-
io: 底层接口,用于展示和读写图表
-
colors: 用于配置图表颜色相关
-
data: 提供了一些内置的数据集加载功能,例如iris、tips数据集
实际上,为了极简入门plotly并快速上手使用,或许只需重点了解plotly.express和plotly.graph_objects两个子模块即可!在具体使用之前,先介绍下二者的区别和定位:
-
plotly.graph_objects是底层API,是一种面向对象的绘图风格,定义了plotly中的所有图表对象(graph_objects翻译过来,不就是图表对象的意思吗,真·简单粗暴!),并提供了相近的布局设置功能(layout),类似于matplotlib的角色;
-
plotly.express是高层API,是一种函数式的绘图风格,绘图的过程就是指定函数各个参数的过程,提供了更为简洁和方便的绘图功能。如果说前者类似于matplotlib,那么plotly.express就妥妥的相当于seaborn的角色!
好家伙,plotly自己还要定义两套绘图风格,真的是要替代matplotlib+seaborn的江湖地位吗?但对于使用者来说,或许是喜闻乐见的——需要快速简洁,就用plotly.express;需要个性化定制,则用plotly.graph_objects。
下面,基于plotly给出两段简单的代码实例
1)使用底层API——graph_objects
graph_objects之所以叫底层API,是因为暴露了更多的绘图细节和参数,但这利弊各半。一般来说,基于graph_objects子模块绘图主要分三步:
-
选定一个图表对象(graph_object),并配置要绘图的数据,例如x和y数据;图表的属性,例如标题、线型等
-
设定一些布局(layout),并配置布局参数,例如图片尺寸、标题等
-
创建一个Figure对象,并接收前两步得到的图表对象和布局对象,而后show出来
举个例子:
import plotly.graph_objects as go # 标准引用格式,一般简写为:go
import plotly.express as px # 标准引用格式,一般简写为:px
tips = px.data.tips() # plotly内置数据集:tips
# 使用graph_objects绘图流程需要三步
line = go.Scatter(x=tips['total_bill'], y=tips['tip'], mode='markers') # ① 创建图表对象
layout = go.Layout(autosize=False, width=900, height=600, title='tips') # ② 创建布局对象
go.Figure(data=line ,layout=layout).show() # 创建Figure,接收图表和布局,并加以显示2)使用高级API——express
express之所以叫高级API,是因为具有更为顶层的抽象,或者说使用更少的代码即可得到更为丰富的绘图结果,更重要的express的绘图接口似乎天然就是为了适配pd.DataFrame而存在的,因为其各类绘图函数中的第一个参数都是data_frame!在设置这一参数之后,x和y的数据只需提供相应的列名即可,例如对于上述同样的绘图需求只需要调用一个函数:
import plotly.graph_objects as go # 标准引用格式,一般简写为:go
import plotly.express as px # 标准引用格式,一般简写为:px
tips = px.data.tips() # plotly内置数据集:tips
# 使用express绘图只需要调用一个函数
px.scatter(tips, x='total_bill', y='tip', width=900, height=600, title='tips').show()当然,上述两种方法得到的绘图结果是一样的,而且这幅图提供了常用的交互功能,例如区域选中(包括矩形区域和自定义区域)、缩放、移动和存储等常用交互按钮,简单演示如下:
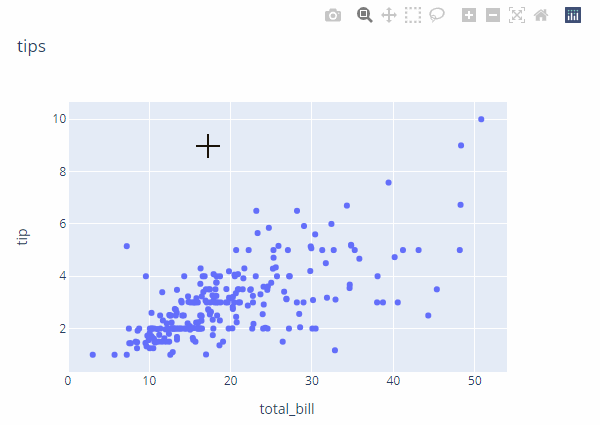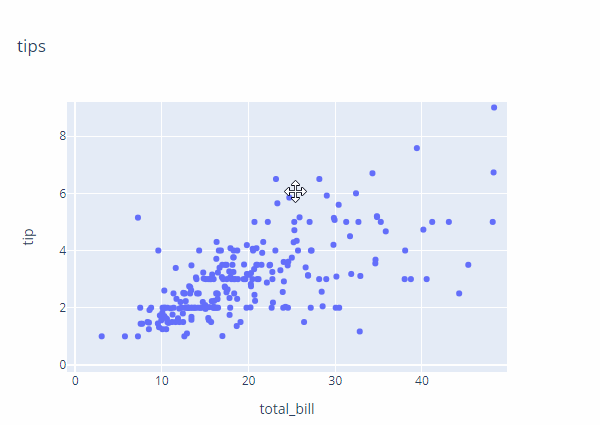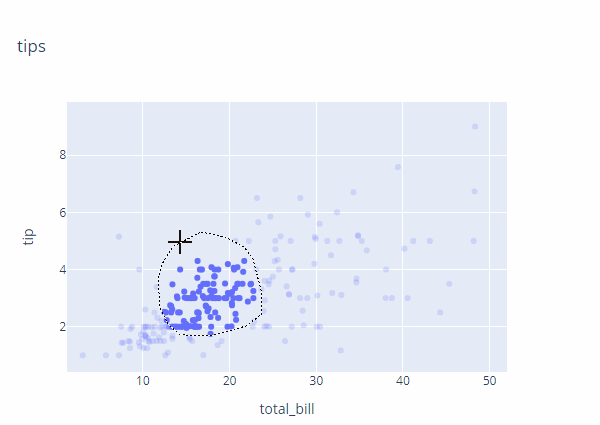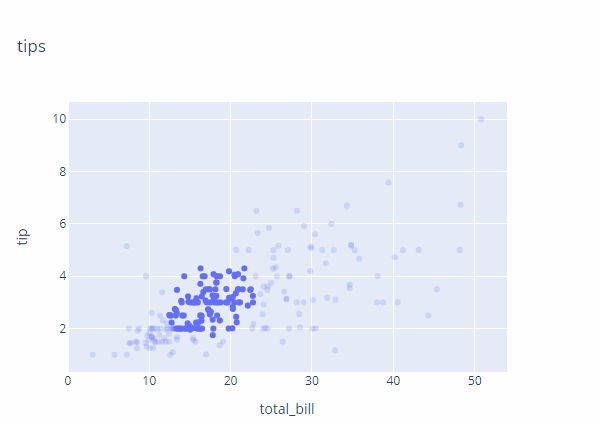
再演示一张个人比较喜欢的小提琴图,用于展示类别间的分布关系:
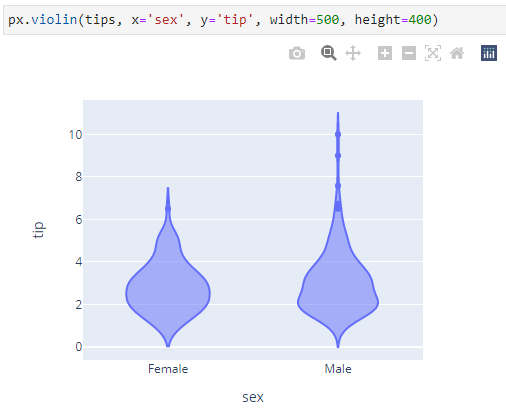
是不是有seaborn那个味道了。。?
另外值得补充的两点:
1)plotly提供了将一个matplotlib绘图转化为plotly绘图的接口,一定程度上使得混合使用两个可视化库更为顺滑,但具体使用体验有待尝试;
2)plotly早期版本还区分online和offline,其中offline就是上述的常规绘图方式,而online方式大概是需要连接plotly的web服务器,不过个人觉得可能并没什么鸟用,所以在V4.0版本移除了。具体参考plotly官网给出的Note:

相关阅读: