文章目录
写在前面
fastp是用于处理fastq文件,基于C++,支持多线程,包含fastQC和Trimmomatic的一些功能。这里主要给出常用参数的一些说明。
参数说明主要参考github上的使用说明,请以github上的说明为准。
参考文献
fastp工具参考文献
fastp软件github下载
fastp功能
- 去接头
- 碱基矫正
- 滑动窗口质量值剪切
- 切ployG/ployX尾巴
- 处理分子标签(UMI)
- 分割输出结果
- duplicate率的评估
- 过表达序列分析
- 质控结果报告
类似软件比较
fastp的文献中指出其运行速度比Trimmomatic快近5倍。
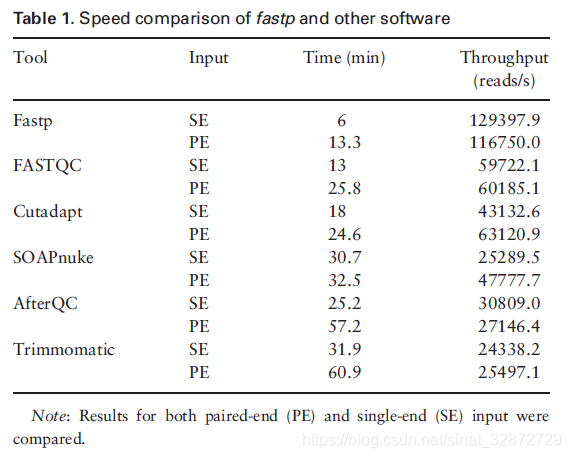
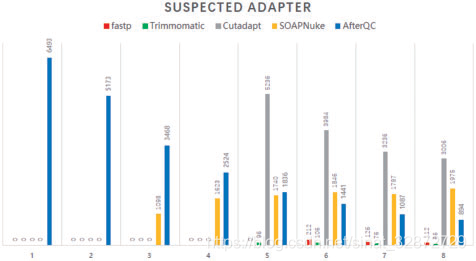
fastp参考文献也对于去除adapter的性能作了比较,X轴是搜索adapter时允许碱基错配数,Y轴是adapter序列数。

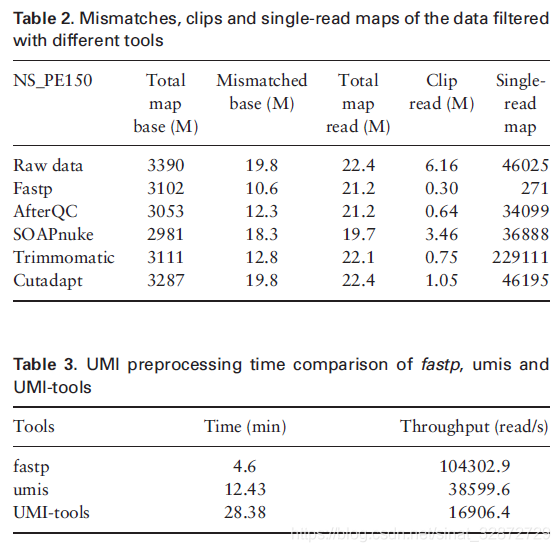
下面是各软件比对情况的比较结果:
简单示例
## 双端数据
$ fastp -i in.R1.fq.gz -I in.R2.fq.gz -o out.R1.fq.gz -O out.R2.fq.gz
## 去UMI简单示例
$ cat R1.fq
@NS500713:64:HFKJJBGXY:1:11101:1675:1101 1:N:0:TATAGCCT+GACCCCCA
AAAAAAAAGCTACTTGGAGTACCAATAATAAAGTGAGCCCACCTTCCTGGTACCCAGACATTTCAGGAGGTCGGGAAA
+
6AAAAAEEEEE/E/EA/E/AEA6EE//AEE66/AAE//EEE/E//E/AA/EEE/A/AEE/EEA//EEEEEEEE6EEAA
$ fastp -i R1.fq -o out.R1.fq -U --umi_loc=read1 --umi_len=8
$ cat out.R1.fq
@NS500713:64:HFKJJBGXY:1:11101:1675:1101:AAAAAAAA 1:N:0:TATAGCCT+GACCCCCA
GCTACTTGGAGTACCAATAATAAAGTGAGCCCACCTTCCTGGTACCCAGACATTTCAGGAGGTCGGGAAA
+
EEE/E/EA/E/AEA6EE//AEE66/AAE//EEE/E//E/AA/EEE/A/AEE/EEA//EEEEEEEE6EEAA
常用参数说明
-i, --in1 R1文件输入;
-I, --in2 R2文件输入;
-o, --out1 R1文件处理后的输出;
-O, --out2 R2文件处理后的输出;
-h, --html 设置输出html格式的质控结果文件名,不设置则默认html文件名为fastp.html
-j, --json 设置输出html格式的质控结果文件名,不设置则默认json文件名为fastp.json
UMI去除
分子标签(UMI),来自于相同的分子的标记,用于去重,错误校正。常用在ctDNA测序,illumina测序的UMI位于两个不同位置:index和read开头。
--umi 启用UMI处理参数;
--umi_loc 指定UMI的位置,可设置下面几种:
"index1": 第一个index作为UMI, 对双端数据,则作用于R1/R2;
"index2": 第二个index作为UMI, 对双端数据,则作用于R1/R2;
"read1": read1的头部作为UMI, 对双端数据,则作用于R1/R2;
"read2": read2的头部作为UMI, 对双端数据,则作用于R1/R2;
"pre_index", "index1_index2":
"pre_read": read1的头部定义'umi1', read2的头部定义'umi2', 'umi1_umi2'作为UMI, 作用于R1/R2
--umi_len UMI的长度,当指定UMI的位置为read1, read2,per_read时,应指定UMI长度;
--umi_prefix UMI设置前缀,例: UMI=AATTCCGG,prefix=ATC,即设置--umi_prefix=ATC,则被加在read_name行的UMI序列将会是ATC_AATTCCGG ;
--umi_skip UMI去除并加到read_name后,再去除(跳过)的碱基数;例:--umi_skip=4 表示去除UMI后再去除4bp。
fastp是将UMI提取后加在对应read的name行,如果UMI在read中,那么UMI会从read中移除,如果UMI在index中,会被保留。
质量过滤
-q, --qualified_quality_phred 设置碱基质量值不小于多少时,该碱基为合格碱基,默认碱基质量值是15,即默认碱基质量>=15是合格碱基,<15为不合格碱基;
-u, --unqualified_percent_limit 设置允许不合格碱基的占比为多少时,去掉这条read,默认是40,即默认不合格碱基占比>40%时,去掉该read;
-Q, --disable_quality_filtering 设置该参数则禁用默认质量过滤参数(-q, -u)。
长度过滤
-l, --length_required 设置read的最小长度,默认是15,即长度<15的read被去掉;
--length_limit 设置read的最大长度, 默认为0是没有最大长度限制;
低复杂度过滤
-Y, --complexity_threshold 设置read的复杂度过滤阈值,默认为30,即当read复杂度<30时,去掉该read。复杂度:
- 复杂度的定义为 一个碱基与其下一个相邻碱基不同的碱基个数占比;
- 例:一条长为51bp的read,有3个碱基与其下一个碱基不同
seq = 'AAAATTTTTTTTTTTTTTTTTTTTTGGGGGGGGGGGGGGGGGGGGGGCCCC'
其复杂度为:complexity = 3/(51-1) = 6%
-y, --low_complexity_filter 设置该参数则禁用默认复杂度过滤参数(-Y)
adapter过滤
-A, --disable_adapter_trimming 设置该参数则禁用默认adapter过滤参数;
-a, --adapter_sequence 指定引物序列(对应SE数据的引物序列 或 对应PE数据的R1的引物序列)。对单端(SE)数据,可通过自动检测前~1Mreads的尾巴,去识别adapter,若设置该参数,则表示禁用自动识别adapter;
--adapter_sequence_r2 指定R2引物序列(对PE数据的R2)。对双端(PE)数据,是通过两条reads的overlap去adapter(由于该方法比较稳定,通常不必设置引物序列)。如果为找到overlap,用使用这些序列去adapter(是否设置都先通过overlap去adapter?);
--detect_adapter_for_pe 默认对双端数据则默认不使用自动检测adapter(SE可自动检测),设置该参数,表示对双端数据也启用自动检测方法;
--adapter_fasta 接头序列文件(fasta格式),注意该fasta文件中的fasta序列长度至少6bp,否则会被跳过。
注:fastp首先去除自动化检测到的接头序列,或者使用--adapter_sequence |--adapter_sequence_r2指定的接头序列,然后去除由--adapter_fasta设置的接头序列。去除的接头序列分布可以在html/json文件中查看。
通过质量值过滤每条read
下面参数是通过滑动窗的平均质量值切除reads
-W, --cut_window_size 设置滑动窗口大小;
-M, --cut_mean_quality 设置滑动窗口的平均质量值阈值,低于这个阈值则被切除;
可对两端分别进行切除:
- 对
5'端的参数,与Trimmomatic中的LEADING参数方法相似:-5, --cut_front是去除5'端低质量碱基,具体是指滑动窗从5'向末尾3’滑动,如果窗口内的碱基平均质量值低于阈值,则切除这些碱基,然后窗口继续滑动,直到达到阈值则不再去除;--cut_front_window_size是设置从5'端开始的滑动窗的大小,即每个滑动窗包含几个碱基;--cut_front_mean_quality设置从5'端开始的滑动窗平均质量值阈值,低于该阈值则切除这些碱基;
- 对
3'端开始切除的参数与5'端类似,也与Trimmomatic中的TRAILING参数的方法类似:-3, --cut_tail是去除3'端低质量碱基,具体是指滑动窗从3'向起始5’滑动,如果窗口内的碱基平均质量值低于阈值,则切除这些碱基,然后窗口继续滑动,直到达到阈值则不再去除;--cut_tail_window_size是设置从3'端开始的滑动窗的大小;--cut_tail_mean_quality设置从3'端开始的滑动窗平均质量值阈值,低于该阈值则切除这些碱基;
还有切除序列的其他参数:
-r, --cut_right 是切除右侧序列,-3与-r参数的差别是,前者是先进行碱基去除,达到阈值则不再去除碱基,然后继续滑动窗口;后者是前者进行后,继续滑动滑动窗,直到发现窗口内碱基的平均质量值低于阈值,则切除该窗口及右侧所有碱基。也就是使用该参数,就没必要设置--cut_tail参数 。
ployG/ployX
对Illumina的NextSeq/NovaSeq测序数据,常会用ployG发生(是因为这两个平台使用两个荧光信号,而没有信号时表示G)。fastp能够检测到ployG并去除(默认是NextSeq/NovaSeq平台,通过测序仪ID和fastq识别)
-g, --trim_poly_g 启用去除尾巴ployG;
--poly_g_min_len 设置去除尾巴’G’的最小长度,默认为10即尾巴ployG长度>10时,会被去除;
-G, --disable_trim_poly_g 禁用去除尾巴ployG;
-x, --polyX 启用去除polyX(polyA, polyT, polyC, polyG),若同时设置--trim_poly_g和--ployX,则先进行ployG尾巴去重,再进行ployX(这样设置有助于ployA尾巴在G尾巴之前时,去重ployA尾巴[常见于mRNA-Seq])。
PE数据的碱基校正
fastp通过overlap进行分析,如果找到合适的overlap,当overlap区域的两个错配碱基中,一个碱基质量值较高,一个碱基质量值极低,该软件会将错配的两个碱基进行校正(?将低质量碱基校正为与高质量碱基互补的碱基)。对应的碱基质量值也校正为相同的值。
-c, --correction 对碱基校正,默认不启用该参数;使用该参数是基于检测overlap,overlap的可调参数有:
-
--overlap_len_requireoverlap的长度要求,默认是30,即默认overlap区域的长度不低于30bp;否则认为无overlap; -
--overlap_diff_limitoverlap中最大错配数,默认是5,即默认overlap时最多有5个错配;否则认为无overlap; -
--overlap_diff_percent_limitoverlap中最大错配数在重叠区的占比,默认是20,即默认最大错配数的碱基占比不高于20%;否则认为无overlap。
整体切除 【global trimming】
整体切除一般是考虑到,illumina测序最后1个cycle或最后n个cycle测序质量较低,使用-t 1, --trim_tai1l=1参数将所有reads的末尾1bp去除;
-f, --trim_front1 对R1起始几bp进行去除,例如:-f 1或--trim_front1=1表示去除R1起始位置1bp碱基;
-t, --trim_tail1 对R1末尾几bp进行去除,例如:-t 2或--trim_tail1=2表示去除R1末尾位置1bp碱基;
-b, --max_len1 设置R1最大长度阈值,即R1的长度大于阈值,则在尾巴开始切除read直到与阈值相等,默认不切除。注意最大长度在最后一步处理;
-F, --trim_front2 与R1相似;不设置默认则与R1指定的参数相同;
-T, --trim_tail2 与R1相似;不设置默认则与R1指定的参数相同;
-B, --max_len2 设置R2最大长度,同-b参数。[注意最大长度在最后一步处理]
## 过滤reads顺序:
1. 对UMI进行处理("--umi")
2. 整体切除的起始位置切除("-f", "-F")
3. 整体切除的尾巴位置切除("-t", "-T")
4. 5'端质量值切除("-cut_front")
5. 滑动窗切除("--cut_right")
6. 3'端质量值切除("--cut_tail")
7. ployG切除("--trim_ploy_g", 默认作用于'NovaSeq/NextSeq'的数据)
8. 根据overlap分析去adapter(PE数据)
9. 根据adapter序列去apapter("--adapter_sequence", "--adapter_sequence_r2", 对PE数据则跳过该步骤)
10. 去除polyX("--trim_poly_x")
11. 去除最大长度("--max_len")
输出文件切分
可通过设置分割成几个文件或者设置每个文件的行数 ,两者不可同时设置。
-s, --split 指定最多分割成几个文件;
-S, --split_by_lines 指定分割后的每个文件最多几行;
-d, --split_prefix_digits 设置输出文件的前缀数字位数,例如:--split_prefix_digits=4 --split=3 --out1=out.fq , 则输出文件为0001.out.fq, 0002.out.fq, 0002.out.fq
过表达序列分析
【overrepresented sequence analysis】
-p,--overrepresentation_analysis 启用该分析,默认仅统计序列长度为10bp, 20bp, 40bp, 100bp或 cycle -2 ;
-P, --overrepresentation_sampling 指定用于统计的reads数比例,默认20,即默认1/20的reads用于序列统计。例:设置-P 100 表示将1/100的reads用序列统计,设置-P 1 表示将所有reads用于统计(运行会很慢,默认20是平衡了速度和精确度)
不仅有过表达序统计结果,还有循环中(cycles)的分布情况,并用图展示检测到的过表达序列,以便找到最多的序列。