ElasticSearch
我们首先简要的介绍一下ES是什么:
ES全称ElasticSearch,是一个基于Lucene的搜索服务器。(其实就是对Lucene进行封装,提供了REST API的操作接口)
- 它是作为一个高度可拓展的开源分布式全文搜索和分析引擎出现在我们的世界中的,可用于快速地 对大数据进行存储,搜索和分析。
- 它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理 PB 级别的数据。
- ElasticSearch是基于Java开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。
- ElasticSearch是和Logstash(数据收集、日志解析引擎)、Kibana(分析和可视化平台)一起开发的。这三个产品被设计成一个集成解决方案,称为“Elastic Stack”(以前被称为ELK技术栈)。
ElasticSearch的使用场景:云计算。能够达到实时搜索、稳定、可靠、快速、安装使用方便。主要用于搜索各种文档。
为什么会出现ES这种全文搜索引擎呢?
Google,百度类的网站搜索,它们都是根据网页中的关键字生成索引,我们在搜索的时候输入关键字,它们会将该关键字即索引匹配到的所有网页返回;还有常见的项目中应用日志的搜索等等。对于这些非结构化的数据文本,关系型数据库搜索不是能很好的支持。
一般传统数据库,全文检索都实现的很鸡肋,因此一般也没人用数据库存文本字段。进行全文检索需要扫描整个表,如果数据量大的话即使对 SQL 的语法优化,也收效甚微。哪怕建立了索引,但是维护起来也很麻烦,对于 insert 和 update 操作都会重新构建索引。
基于以上原因可以分析得出,在如下一些生产环境中,使用常规的搜索方式,性能是非常差的:
-
搜索的数据对象是大量的非结构化的文本数据。
-
文件记录量达到数十万或数百万个甚至更多。
-
支持大量基于交互式文本的查询。
-
需求非常灵活的全文搜索查询。
-
对高度相关的搜索结果的有特殊需求,但是没有可用的关系数据库可以满足。
-
对不同记录类型、非文本数据操作或安全事务处理的需求相对较少的情况。为了解决结构化数据搜索和非结构化数据搜索性能问题,我们就需要专业,健壮,强大的全文搜索引擎 。
由此,ES这种全文搜索引擎就出现了。它的工作原理是计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。
通知:
这里我就不再介绍ES如何使用以及安装了,百度上有很多这种文章,都讲的很详细,所以我就不再花大量篇幅介绍如何安装以及使用ES了。下面会直接开始将ES整合进我们的项目。
SpringBoot整合ElasticSearch
elasticsearch-Rest-Client
Java操作es有两种方式:
第一种是通过9300端口,这个端口遵循的是TCP协议。
- 需要导入spring-data-elasticsearch:transport-api.jar;
- 且springboot版本不同,transport-api.jar也不同,不能适配所有es版本
- 7.x已经不建议使用,8以后就要废弃
第二种是通过9200端口,这个端口遵循的是HTTP协议。
这个的发行版本很多,有很多包。
- jestClient: 非官方,更新慢;
- RestTemplate:模拟HTTP请求,ES很多操作需要自己封装,麻烦;
- HttpClient:同上;
- **Elasticsearch-Rest-Client:**官方RestClient,封装了ES操作,API层次分明,上手简单;
最终我们选择第二种方式中的Elasticsearch-Rest-Client(elasticsearch-rest-high-level-client)。
创建gulimall-search项目
-
创建项目springboot项目gulimall-search,这里我们只选择依赖Spring Web,不要在里面选择ElasticSearch!因为里面的es版本没有更新,与我们的boot依赖并不适配!
-
导入依赖,这里的版本要和我们Linux虚拟机上的ElasticSearchKibana版本匹配
<dependency> <groupId>org.elasticsearch.client</groupId> <artifactId>elasticsearch-rest-high-level-client</artifactId> <version>7.4.2</version>//如果下面做了es的版本仲裁,这里可以不写 </dependency>注意这里我们这里使用的SpringBoot版本是2.1.8.RELEASE,它的elasticsearch版本已经写好了是6.4.3,所以我们这里需要改一下spring-boot-dependencies中所依赖的ES版本。
<properties> <java.version>1.8</java.version> <elasticsearch.version>7.4.2</elasticsearch.version> </properties> -
然后我们需要编写ES的配置信息(在
com.hgw.gulimall.search.config包下创建一个ES的配置类)。- 我们这里需要给容器中注入一个RestHighLevelClient的实例以便我们之后可以直接从容器中取出这个实例。
- 另外ES添加了安全访问规则,访问ES需要添加一个安全头,这里就可以通过requestOptions设置,并且官方建议把requestOptions创建成单实例。
@Configuration public class GuliESConfig { public static final RequestOptions COMMON_OPTIONS; static { RequestOptions.Builder builder = RequestOptions.DEFAULT.toBuilder(); COMMON_OPTIONS = builder.build(); } @Bean public RestHighLevelClient esRestClient() { //下面我们可以指定多个ES,这里只指定了一个 RestClientBuilder builder = RestClient.builder(new HttpHost(host, 9200, "http")); RestHighLevelClient client = new RestHighLevelClient(builder); return client; } }通过这三步我们就已经把SpringBoot和ElasticSearch整合好了,下面我们就来测试一下吧。
ES的API具体使用
下文中所有client实例都是从Spring的IOC容器中获取的,代码如下:
@Autowired
private RestHighLevelClient client;
创建索引
// 测试创建索引
@Test
public void testCreateIndex() throws IOException {
// 1、创建索引请求
CreateIndexRequest request = new CreateIndexRequest("gulimall_index");
// 2、执行IndicesClient的创建索引请求 ,请求后获得响应
CreateIndexResponse createIndexResponse = client.indices().create(request, RequestOptions.DEFAULT);
System.out.println(createIndexResponse);
}
判断索引是否存在
// 测试获取索引
@Test
public void testGetIndex() throws IOException {
GetIndexRequest request = new GetIndexRequest("gulimall_index");
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
System.out.println(exists);
}
删除索引
// 测试删除索引
@Test
public void testDeleteIndex() throws IOException {
DeleteIndexRequest request = new DeleteIndexRequest("gulimall_index");
AcknowledgedResponse delete = client.indices().delete(request, RequestOptions.DEFAULT);
System.out.println(delete.isAcknowledged());
}
创建文档
@Test
public void testAddDocument() throws IOException {
// 创建请求体内容
User user = new User();
user.setName("xjx");
user.setGender("男");
user.setAge(20);
String UserJson = JSON.toJSONString(user);
// 创建请求
IndexRequest request = new IndexRequest("gulimall_index");
// 规则 PUT /gulimall_index/_doc/1
request.id("1");
request.timeout(TimeValue.timeValueSeconds(1));
request.timeout("1s");
// 将我们的数据放入请求JSON, 并且指定泛指的类型
request.source(UserJson, XContentType.JSON);
// 客户端发送请求,获取响应的结果
IndexResponse indexResponse = client.index(request, GulimallElasticSearchConfig.COMMON_OPTIONS);
System.out.println(indexResponse.toString());
System.out.println(indexResponse.status()); // 对应我们命令返回的状态 CREATED
}
测试结果如下:
IndexResponse[index=gulimall_index,type=_doc,id=1,version=1,result=created,seqNo=0,primaryTerm=1,shards={"total":2,"successful":1,"failed":0}]
到这里其实我们就已经发现操作ES的规律了,我们操作什么就创建其对应的Request请求对象,然后把要操作的数据信息放入这个request对象中,然后调用我们之前配置好的RestHighLevelClient实例来发送对应的请求即可。都是属于API调用层面,只要找到规律,调用起来并不难。
批量增加
@Test
public void testBulkRequest() throws IOException {
//创建批处理请求
BulkRequest bulkRequest = new BulkRequest();
bulkRequest.timeout("10s");
//创建请求内容
ArrayList<User> userList = new ArrayList<>();
userList.add(new User("xjx1", "男", 18));
userList.add(new User("xjx2", "男", 19));
userList.add(new User("xjx3", "男", 20));
userList.add(new User("xjx4", "男", 21));
userList.add(new User("xjx5", "女", 22));
// 处理批处理请求
for (int i = 0; i < userList.size(); i++) {
bulkRequest.add(new IndexRequest("xjx_index")
.id(""+(i+1))
.source(JSON.toJSONString(userList.get(i)), XContentType.JSON)
);
}
BulkResponse bulk = client.bulk(bulkRequest, GulimallElasticSearchConfig.COMMON_OPTIONS);
System.out.println(bulk.hasFailures()); // 是否失败,返回false表示成功
}
获取文档信息
//获取文档的信息
@Test
public void testGetDocument() throws IOException {
GetRequest getRequest = new GetRequest("xjx_index","1");
GetResponse getResponse = client.get(getRequest,GulimallElasticSearchConfig.COMMON_OPTIONS);
System.out.println(getResponse.getSourceAsString()); // 打印文档的内容
System.out.println(getResponse); // 返回的全部内容和命令是一样的
}
查询文档是否存在
//判断文档是否存在 比如:get /index/doc/1
@Test
public void testIsExists() throws IOException {
GetRequest getRequest = new GetRequest("xjx_index", "1");
// 不获取返回的_source的上下文了
getRequest.fetchSourceContext(new FetchSourceContext(false));
getRequest.storedFields("_none_");
boolean exists = client.exists(getRequest, GulimallElasticSearchConfig.COMMON_OPTIONS);
System.out.println(exists);
}
更新文档信息
// 更新文档的信息
@Test
public void testUpdateDocument() throws IOException {
UpdateRequest updateRequest = new UpdateRequest("hgw_index","1");
updateRequest.timeout("1s");
User user = new User("黄龚伟", "男",50);
updateRequest.doc(JSON.toJSONString(user),XContentType.JSON);
UpdateResponse updateResponse = client.update(updateRequest, RequestOptions.DEFAULT);
System.out.println(updateResponse.status());
}
删除文档记录
// 删除文档的纪律
@Test
public void testDeleteRequest() throws IOException {
DeleteRequest deleteRequest = new DeleteRequest("hgw_index","1");
deleteRequest.timeout("1s");
DeleteResponse deleteResponse = client.delete(deleteRequest, RequestOptions.DEFAULT);
System.out.println(deleteResponse.status());
}
普通检索
/**
* SearchRequest 搜索请求
* SearchSourceBuilder 封装检索条件的对象
* HighlightBuilder 构建高亮
* QueryBuilder 查询条件的构建
* MatchAllQueryBuilder 匹配所有
* XXXQueryBuilder 对应所有命令
*/
@Test
public void testSearch() throws IOException {
// 1、创建检索的请求
SearchRequest searchRequest = new SearchRequest("bank");
// 2、封装检索条件的对象的构建
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
// 2.1)构建检索条件
sourceBuilder.query(QueryBuilders.matchQuery("address","mill"));
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
// 3、构建放到请求里面
searchRequest.source(sourceBuilder);
// 4、执行请求
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
System.out.println(JSON.toJSON(searchResponse.getHits()));
System.out.println("=====================");
//遍历检索出的对象中集中的文档
for (SearchHit hit : searchResponse.getHits().getHits()) {
System.out.println(hit.getSourceAsMap());
}
}
复杂检索
搜索address中包含mill的所有人的年龄分布,平均薪资
@Test
public void searchData() throws IOException {
// 1、创建检索请求
SearchRequest searchRequest = new SearchRequest();
// 指定索引
searchRequest.indices("bank");
// 指定DSL语句即索引条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 1.1)构建检索条件
searchSourceBuilder.query(QueryBuilders.matchQuery("address", "mill"));
// 按照年龄的值分布进行聚合
TermsAggregationBuilder ageAgg = AggregationBuilders.terms("ageAgg").field("age").size(10);
//添加进检索条件
searchSourceBuilder.aggregation(ageAgg);
// 计算平均薪资进行聚合
AvgAggregationBuilder balanceAvg = AggregationBuilders.avg("balanceAvg").field("balance");
//添加进检索条件
searchSourceBuilder.aggregation(balanceAvg);
//把检索条件加入请求中
searchRequest.source(searchSourceBuilder);
// 2、执行检索
SearchResponse searchResponse = client.search(searchRequest,GulimallElasticSearchConfig.COMMON_OPTIONS);
// 3、分析结果
System.out.println(searchResponse.toString());
//转换成Bean
//3.1)、获取所有查找的数据
SearchHits hits = searchResponse.getHits();
SearchHit[] searchHits = hits.getHits();
for (SearchHit searchHit : searchHits) {
String string = searchHit.getSourceAsString();
Accout accout = JSON.parseObject(string, Accout.class);
System.out.println("accout: " + accout);
}
//Buckets分析信息
//3.2)、获取这次检索到的分析信息
Aggregations aggregations = searchResponse.getAggregations();
Terms ageAgg1 = aggregations.get("ageAgg");
for (Terms.Bucket bucket : ageAgg1.getBuckets()) {
System.out.println("年龄:"+ bucket.getKeyAsString());
}
Avg balanceAvg1 = aggregations.get("balanceAvg");
System.out.println("平均薪资:" + balanceAvg1.value());
}
ES的操作总结:
总的来说如果我们要进行什么操作就先创建对应操作的请求对象,比如删除文档就是DeleteRequest但是删除索引就需要加一个Index如DeleteIndexRequest。然后把这个请求需要的参数加入这个请求,简单的操作可以直接把参数通过请求对象的有参构造传给请求对象,复杂的如检索就需要额外创建一个对象来封装这些条件了(SearchSourceBuilder)。最后我们只要把这个请求对象传给我们之前添加在容器中的RestHighLevelClient对象就可以了。
ES与Product服务的整合
我们的项目为什么选择ES
这其实是属于项目经理需要考虑的问题,因为这涉及到了技术选型。这里简要介绍一下,我们既然使用了这门技术,就要知道为什么使用这门技术,正所谓知其然知其所以然。
由于我们做的是电商项目,后面就要根据一些商品的关键字进行搜索商品了。而传统的数据库比如我们项目中使用的mysql数据库对于这种全文检索的实现是很差的,因为mysql是关系型数据库,我们需要检索整个表,甚至检索关联的多个表的全部数据。哪怕我们使用了索引,后面还要维护索引。因此我们这里只是用mysql数据库用作持久化存储使用。而选用擅长这种全文检索的ES全文搜索引擎来进行我们的商品全文检索。
如何使用ES检索我们的商品数据?
我们既然选用了ES进行我们项目的商品全文检索,那么就需要把我们所有的商品信息存入我们的ES中,这里需要记住一点ES中的所有数据都是存在内存中的,这也是其检索效率高的重要原因。那么为什么ES可以把数据全部存入内存呢?
最一开始我们就提到了ES是一个高拓展的分布式的全文搜索引擎。因此如果我们的ES服务器存不下我们要检索的数据的话,我们就可以建立一个ES集群(因为ES是天然支持分布式的),然后ES可以将所有数据分片存储,这样就能保证所有数据都存储在内存中了。
因此,现在我们就需要把我们所有的商品信息存入ES。但不是所有的商品信息都是需要存入到ES中的,我们只把需要全文检索的数据上传到ES中。只有我们上架的商品才会在网站中被检索展示出来。商品上架按钮在spu管理中,我们对想要在网站中展示的商品点击上架即可
分析存储的商品数据
但我们的商品信息那么多,该存哪些信息在ES中呢?下面就需要分析一下:
通过分析jd商城页面我们知道,我们不仅需要在ES中存储SKU销售属性的信息(比如标题),还有其分类信息(所属品牌)及其SPU规格参数信息。那么这么多信息,到底该以什么形式存储在ES中呢?
分析:商品上架在es中是存sku还是spu?
- 检索的时候输入名字,是需要按照sku的title进行全文检索的
- 使用商品规格进行检索,规格参数信息是spu的公共属性,所以每个spu对应的很多sku中规格参数都是一样的
- 按照分类id进去的都是直接列出spu的,还可以切换。
- 我们如果将sku的全量信息保存到es中(包括spu属性〕就太多字段了
下面我们有两个方案:
方案1
{
skuId:1
spuId:11
skyTitile:华为xx
price:999
saleCount:99
attr:[
{尺寸:5},
{CPU:高通945},
{分辨率:全高清}
]
缺点:如果每个sku都存储规格参数(如尺寸),会有冗余存储,因为每个spu对应的sku的规格参数都一样
方案2
sku索引
{
spuId:1
skuId:11
}
attr索引
{
spuId:11
attr:[
{尺寸:5},
{CPU:高通945},
{分辨率:全高清}
]
}
这种方案可以不存那么多冗余数据,因为可以根据skuid查出其对应的规格参数。
缺点是太耗费时间了,比如我们需要找到4000个符合要求的spu,再根据4000个spu查询对应的属性,封装了4000个id,long 8B*4000=32000B=32KB
1K个人检索,就是32MB
结论:如果将规格参数单独建立索引,会出现检索时出现大量数据传输的问题,会引起网络阻塞
因此最终我们选用方案1,以空间换时间。
分析好了需要上传到ES的商品数据信息,我们接下来就可以在ES中建立商品数据模型的索引了。
建立ES中商品索引
最终选用的数据模型如下:
PUT product
{
"mappings":{
"properties": {
"skuId": { "type": "long" },
"spuId": { "type": "keyword" }, #保持数据精度问题,可以检索,但不分词
"skuTitle": {
"type": "text",
"analyzer": "ik_smart" # 中文分词器
},
"skuPrice": { "type": "keyword" }, # 保证精度问题
"skuImg" : { "type": "keyword" }, # 视频中有false
"saleCount": { "type":"long" },
"hasStock": { "type": "boolean" },
"hotScore": { "type": "long" },
"brandId": { "type": "long" },
"catalogId": { "type": "long" },
"brandName": {"type": "keyword"}, # 视频中有false
"brandImg":{
"type": "keyword",
"index": false, # 不可被检索,不生成index,只用做页面展示使用
"doc_values": false # 不可被聚合,默认为true,设置为false后es就不会维护一些聚合的信息
},
"catalogName": {"type": "keyword" }, # 视频里有false
"attrs": {
"type": "nested",
"properties": {
"attrId": {"type": "long" },
"attrName": {
"type": "keyword",
"index": false,
"doc_values": false
},
"attrValue": {"type": "keyword" }
}
}
}
}
}
-
冗余存储的字段:不用来检索,也不用来分析,节省空间
-
库存是bool。
-
检索品牌id,但是不检索品牌名字、图片
-
用skuTitle检索
nested嵌入式对象
使用方式是”type”: “nested”,因为是内部的属性进行检索
为什么这么设置呢?
因为ES中会将对象扁平化处理进一个数组中(对象的每个属性会分别存储到一起),比如存储如下数据时
{
"user":[
{
"name":"xjx",
"addr":"ly"
},
{
"name":"lxn",
"addr":"py"
}
]
}
ES实际会存储为如下结果
user.name=["xjx","lxn"]
user.addr=["ly","py"]
这种对象扁平化处理就会使我们检索数据时,错误的检索到如{xjx,py}这种并不存在的数据。
由于ES对象的扁平化处理会使检索能检索到本身不存在的数据,为了解决这个问题,就采用了嵌入式属性,如果存储数据是数组且里面是对象时需要用嵌入式属性(不是对象无需用嵌入式属性)。
到此我们就分析完ES如何存储我们的商品数据了,下面就开始我们的后端代码实现上传我们的商品数据进ES了
商品上架
这一步的逻辑比较复杂,最好还是对比源码进行观看,我将每一行代码具体做什么的都有写注释。
-
首先我们我们需要查出前台给我们传回来的spuid对应的所有sku信息,包括其品牌以及三级分类名。sku的规格参数信息我们可以直接通过spuid进行查询,因为规格参数本来也就是绑定的spu而不是sku,这里我们需要过滤,只需要查出可以检索的规格参数即可。然后把这些可以检索的规格参数数据添加到我们的数据模型中。
-
然后就是我们的查询库存,这里就涉及到了远程调用仓库服务。我们先需要在我们的远程调用包(feign)中创建我们的远程调用接口,然后去仓库服务中创建处理请求的方法。这里需要创建一个新的VO,因为我们只需要判断产品服务传过来的skuid对应的商品有没有库存,不需要返回其他数据。然后去数据库查是否有库存,只要有库存就返回true表示有库存。注意这里我们返回的是一个list集合,因为请求中skuid也是一个list。我们仍然需要返回R,但是从R中取出数据还需要类型转换,之前我们是把R返回前端,不需要进行类型转换(js不需要手动指定类型),但我们这里是服务之间的相互调用,所以想取出数据就需要转换。这里为了方便,我们把R设计成泛型类,之后的所有数据都存在泛型类型的data变量中。之后就可以对前端返回的所有sku进行库存判断了,因为之后我们会总的对这个skuids集合进行处理,所以这里我们可以把R返回的库存数据处理为map(key为skuid,value就是是否有库存)。
-
品牌和分类信息,我们可以一起在对skuid进行数据封装时一起处理了,比较简单。
-
完成以上功能后,我们就把需要上架的商品信息处理完了,接下来调用我们ES服务进行上架就可以了(把商品数据存储到ES中)。
因为涉及到了远程调用,所以我们仍然需要先创建远程调用接口。然后去ES服务中创建请求处理的方法。这里主要是将数据存储到ES中,然后把商品的状态修改一下。存储数据到ES直接利用我们之前学过的存储文档方法调用其API就可以了。这里因为保存的商品信息比较多,所以使用批处理请求。
完成这些功能后,可能还有一小部分需要优化,这里太碎了就不细说了可以看下我的源码,都有注释的。
这里记录一下关于alibaba的fastjson中TypeReference的使用:
这里因为我们的R实际上是一个HashMap,所以无法为我们单一的数据指定泛型,所以这里我们将数据使用反序列化的方式进行取出。创建一个泛型方法然后传入一个泛型类TypeReference。那么我们之后取数据时只要给TypeReference指定对应的泛型,那么之后取出的数据就是我们泛型指定的类型了(利用了json的两次转换)。
feign调用流程:
-
构造请求数据,将对象转为json:
RequestTemplate template = buileTemplateFromArgs.create(argv);
也就是说我们调用远程接口之后,它会先构造我们的请求,并且将对象转为json
-
发送请求进行执行(执行成功之后会解码相应数据):
也就是把我们构造好的请求发送给真正处理请求的处理器
executeAndDecode(template);
-
执行请求会有重试机制
默认是重试5次,即哪怕远程调用失败了,我们的feign还是会再重复请求4次。
while(true){
try{
executeAndDecode(template);
}
retryer.continueOrPropagate(e);
}
下面是Feign的源码:
// ReflectiveFeign
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
if (!"equals".equals(method.getName())) {
if ("hashCode".equals(method.getName())) {
return this.hashCode();
} else {
return "toString".equals(method.getName()) ? this.toString() : ((MethodHandler)this.dispatch.get(method)).invoke(args);
}
} else { // 处理equals方法
try {
Object otherHandler = args.length > 0 && args[0] != null ? Proxy.getInvocationHandler(args[0]) : null;
return this.equals(otherHandler);
} catch (IllegalArgumentException var5) {
return false;
}
}
}
// SynchronousMethodHandler
public Object invoke(Object[] argv) throws Throwable {
// 传过来的数据,构造 RequestTemplate,里面body有数据
RequestTemplate template = this.buildTemplateFromArgs.create(argv);
Options options = this.findOptions(argv);
// 重试器,要注意重复调用、接口幂等性。可以写重试器自己的实现
Retryer retryer = this.retryer.clone();
while(true) {
try {
// 执行后得到响应,解码得到bean
return this.executeAndDecode(template, options);
} catch (RetryableException var9) {
RetryableException e = var9;
try {
retryer.continueOrPropagate(e);
} catch (RetryableException var8) {
Throwable cause = var8.getCause();
if (this.propagationPolicy == ExceptionPropagationPolicy.UNWRAP && cause != null) {
throw cause;
}
throw var8;
}
}
}
}
Object executeAndDecode(RequestTemplate template, Options options) throws Throwable {
// 构造出请求
Request request = this.targetRequest(template);
if (this.logLevel != Level.NONE) {
// 打印日志
this.logger.logRequest(this.metadata.configKey(), this.logLevel, request);
}
long start = System.nanoTime();
Response response;
try {
// 执行。client是LoadBalancerFeignClient。跳转到远程
response = this.client.execute(request, options);
response = response.toBuilder().request(request).requestTemplate(template).build();
} catch (IOException var16) {
if (this.logLevel != Level.NONE) {
this.logger.logIOException(this.metadata.configKey(), this.logLevel, var16, this.elapsedTime(start));
}
throw FeignException.errorExecuting(request, var16);
}
Nginx整合商城系统静态资源
我们的项目毕竟是用来学习练手的,所以并不采用真正的前后端分离进行开发。所以前端的静态资源我们也要进行处理。
静态资源处理流程如下:
-
请求需要过nginx发给网关,网关再路由到微服务
-
静态资源放到nginx中(后面的很多服务都需要放到nginx中):html\首页资源\index放到gulimall-product下的static文件夹,把index.html放到templates中
具体流程如下图:
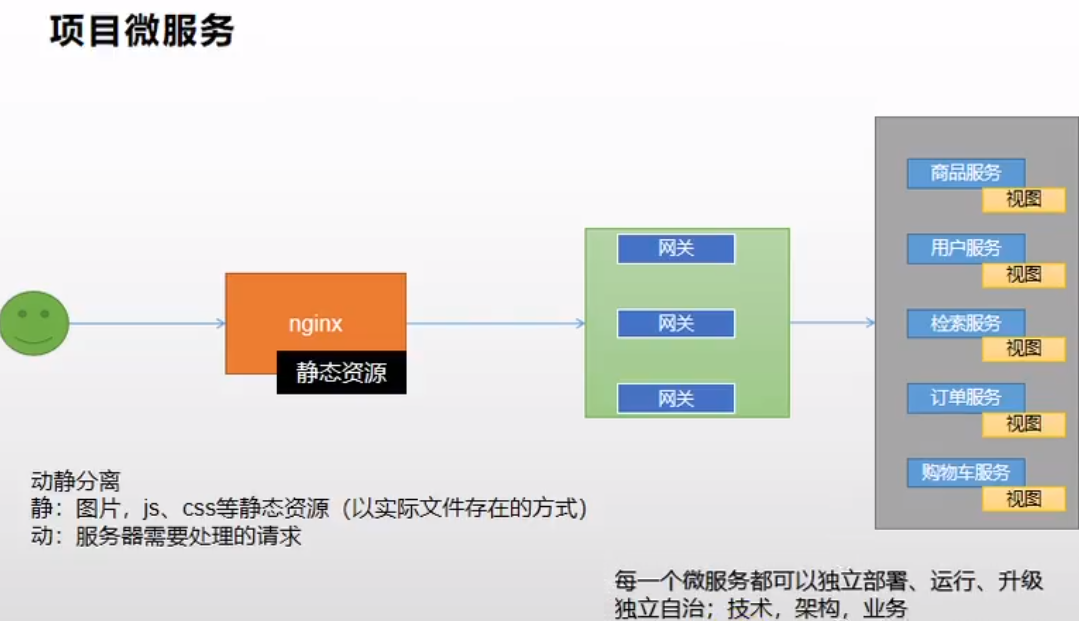
动静分离的意思就是说我们请求中所有静态资源都是从nginx中取,而不是到我们真正的微服务中取,这样可以节省大量服务器资源用于处理真正的业务请求。
微服务:我们的每一个服务都是可以单独部署运行的,因为我们每一个微服务的前后端资源都只会放到自己的服务中,如本节的商城静态资源就只会放到我们的商品服务中,然后其中的请求也都会由我们的商品服务自己进行处理。相当于每一个微服务都是完全自治的,甚至不限定于java语言进行开发。
整合thymyleaf
我们前端资源的渲染都是用thymeleaf模板引擎处理。下面是项目整合thymeleaf步骤:
- 首先把thymeleaf的包导入进来,这里springboot已经整合好了thymeleaf,所以我们导入其starter即可。
- 然后配置thymeleaf,设置缓存为false这样我们才能实时的在前端页面看到我们的代码修改效果;再设置前缀视图解析器,这样我们的controller以后返回的数据不是json数据,而是一个字符串,那么我们springmvc的视图解析器就会对其进行拼接前后缀处理。
- 然后我们可以改一下我们的包名,因为我们原来的controller其实处理的都是rest请求,所以也可以叫做rest接口,所以改名为app。然后创建一个新包(web)所有的controller都创建在这个包下。
Springboot-加载静态资源
之后我们就可以将我们每个服务的静态资源放入到static文件夹下,而将index.html放入到templates文件夹下。为什么这么存放呢?
因为springboot的静态资源分别存放在两个目录下:
- static目录:css、js、图片等
- templates目录:html页面
而spring boot又默认将静态资源访问映射到以下目录:
classpath:/static
classpath:/public
classpath:/resources
classpath:/META-INF/resources
这四个目录的访问优先级:META-INF/resources > resources > static > public
即:这四个路径下如果有同名文件,则会以优先级高的文件为准。
其对应的配置方法为:application.yml。默认配置如下:
spring:
web:
resources:
static-locations: classpath:/META-INF/resources/, classpath:/resources/, classpath:/static/, classpath:/public/
//这个配置的意思是静态资源存放路径。我们可以自定义Springboot前端静态资源的位置。默认Springboot已经配置好了。就是上面那四个
其实,它还与application.yml的下边这个配置有关,两者联合起来控制路径
spring:
mvc:
static-path-pattern: /static/**
//这个配置的意思是静态资源匹配路径、只有静态资源的访问路径为/static/**时,才会处理请求。比如访问http://localhost:8080/static/a.css,处理方式是据模式匹配后的文件名查找本地文件。按spring.resources.static-locations指定查找的本地文件的位置。
这里笔者的静态资源刚开始就没有加载出来,加了mvc的配置才加载出来,因此这里记录一下。
而推荐将html页面放置在templates目录的原因如下:
templates目录下的html页面不能直接访问,需要通过服务器内部进行访问,可以避免无权限的用户直接访问到隐私页面,造成信息泄露。
如果HTML文件放到static目录下,那么用户可以通过两种方法获得到html页面:
- 直接访问.html资源
- 通过controller跳转
就像上边说的一样,当直接访问.html资源时,用户可以访问到无权访问的页面。
所以我们一般都会将html文件存放在templates目录下,通过我们的请求处理才可以访问到(一般templates前缀会使用视图解析器),而一些静态文件才会放到static目录下。
渲染前端页面
渲染一级分类数据
现在我们不只是想要访问localhost:10000/能成功访问到页面,还想要实现访问localhost:10000/index.html也能访问,另外当thymeleaf中,默认的访问的前缀和后缀
//前缀
public static final String DEFAULT_PREFIX = "classpath:/templates/";
//后缀
public static final String DEFAULT_SUFFIX = ".html";
而controller中如果返回的是一个视图地址字符串,视图解析器就会对它进行拼串。这里切记controller用@controller注解而不要用@RestController注解,因为我们要返回的是一个地址字符串,这样视图解析器才能对其进行处理。
那么我们就可以把我们想要访问的路径名作为这个controller可以处理的请求地址配置上即可
@GetMapping({"/", "/index.html"})
查询出所有的一级分类:
由于访问首页时就要加载一级目录,所以我们需要在加载首页时获取该数据
这里就是一个简单的查询数据库中一级分类的请求。注意controller的返回值类型为String,返回值要写”index”,这样视图解析器就可以解析我们的返回值地址字符串,然后定位到我们的templates下的index.html,然后把这个页面返回给前端进行展示。
然后我们需要在前端页面把后端传回来的数据加以处理,渲染到我们的页面上。这里使用的就是thymeleaf:只需要引入thtmeleaf头文件就可以了。
<html lang="en" xmlns:th="http://www.thymeleaf.org">
然后我们就可以使用thymeleaf的语法进行数据处理了。
渲染二级三级分类数据
本来的二级三级数据来自于一个写死的文件,现在我们要根据一级菜单动态获取这些数据,所以把catalogLoad.js这个请求改一下,然后我们处理这个请求。我们首先分析一下前台需要的json数据格式,然后创建出其对应的实体类,然后就可以取数据库中查数据,然后封装到刚刚创建的实体类当中,然后返回就可以了。前端要的是json数据,所以需要用@ResponseBody注解,不加这个则默认是地址字符串,会被视图解析器解析。
搭建域名访问环境
项目真正上线时肯定不是用ip地址加端口号来访问的,所以我们接下来给我们的服务器配置一个域名。这里我们不需要买服务器,我们把所有请求都让nginx进行反向代理,然后把nginx的ip地址配置到本地host文件中,然后给nginx服务器起一个域名就可以了,这样我们以后就可以直接访问nginx服务器的域名,然后让nginx帮我们转发请求到具体的服务上。具体过程如下图:

操作好之后我们把nginx配置文件配置一下,这里直接配置我们的网关了。
nginx负载均衡到网关
-
修改“/mydata/nginx/conf/nginx.conf”,添加如下内容
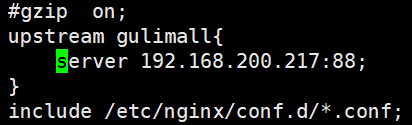
注意:这里的88端口为“gulimall-gateway”服务的监听端口,也即访问“gulimall-product”服务通过该网关进行路由。
-
修改“/mydata/nginx/conf/conf.d/gulimall.conf”文件
proxy_set_header Host $host的作用是给我们的请求头加上host信息。因为Nginx代理给网关的时候,会丢失请求头的很多信息,如HOST信息,Cookie等。
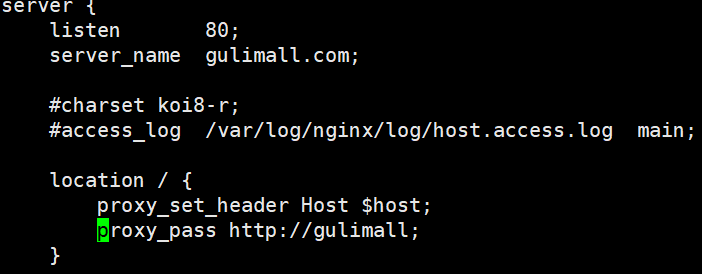
配置完后重启nginx服务
- 在“gulimall-gateway”添加路由规则:
- id: gulimall_host_route
uri: lb://gulimall-product
predicates:
- Host=**.gulimall.com
注意:这个路由规则,一定要放置到最后,否则会优先进行Host匹配,导致其他路由规则失效。
完成这三步,我们就可以通过域名访问到我们商城的主页了。
**整个的数据流是这样的:**浏览器请求gulimall.com,在本机被解析为192.168.10.10(虚拟机ip),192.168.10.10的80端口接收到请求后,解析请求头得到host,然后使用在“gulimall.conf”中配置的规则,将请求转到“http://192.168.10.1:88”(主机ip),然后网关服务响应请求后转发到我们的商品服务,最后返回响应结果。
性能压力测试与优化
通过对我们程序的压力测试我们可以考察在当前软硬件环境下我们的商城系统所能承受的最大负荷并且帮助我们找出系统瓶颈所在(比如看看业务是CPU密集型还是IO密集型)。所以必要的压力测试是很有必要的。下面我们就对我们的程序进行压力测试:
我们的压力测试工具用的是JMeter,性能监控工具用的是jvisualvm。关于这两个工具的使用老师课中讲的十分清晰,这里就不贴图教大家使用了,因为贴上会使整个版面看起来都会很乱,所以还是建议大家跟着视频课学习一下使用,都比较简单。下面这个表格就是对我的商城系统的压力测试结果。
| 压测内容 | 压测线程数 | 吞吐量/s | 90%响应时间 | 99%响应时间 |
|---|---|---|---|---|
| Nginx(浪费CPU) | 50 | 2120 | 10 | 1189 |
| Gateway(浪费CPU) | 50 | 9157 | 9 | 20 |
| 简单服务(返回字符串) | 50 | 9789 | 8 | 48 |
| 首页一级菜单渲染 | 50 | 350 | 260 | 498 |
| 首页菜单渲染(开缓存) | 50 | 423 | 139 | 306 |
| 首页菜单渲染(开缓存、优化数据库、关日志) | 50 | 644 | 101 | 288 |
| 三级分类数据获取 | 50 | 4 | 13218 | 13453 |
| 三级分类(优化业务) | 50 | 15 | 4092 | 5891 |
| 首页全量数据获取 | 50 | 2.7 | 24213 | 25978 |
| 首页全量数据获取(动静分离) | 50 | 4.9 | 14849 | 16134 |
| Nginx+GateWay | 50 | |||
| Gateway+简单服务 | 50 | 3124 | 27 | 61 |
| 全链路(Nginx+GateWay+简单服务) | 50 | 636 | 81 | 589 |
关于我们项目优化有以下几点:
-
开启thymeleaf的缓存(这是因为如果不开缓存,每次加载页面时都需要重新加载进静态资源进行渲染)
-
给常查询的数据库字段添加索引
-
把日志级别修改成更高级即少打印日志信息(比如上线时改为error级别,只有在开发阶段才调到比较细的粒度级别)
-
动静分离
-
修改JVM参数(-Xmx1024m -Xms1024m -Xmn512m)
因为我们之前设置的堆内存过小,会有大量的GC停顿时间,并且可能会因为内存不够而爆OOM异常导致把服务挤掉线,所以需要把内存调大,以免出现内存溢出错误和频繁的进行GC(尤其是fullGC)
-
优化业务代码(主要是我们操作数据库的代码)
测试之后我们发现其实对于我们的项目来说增加中间件并不是业务响应慢的根本原因,根本原因出在我们编写的业务逻辑上(比如循环嵌套查询数据库)
这里其他优化都不难,下面我们重点介绍一下动静分离的操作和优化业务代码。
nginx配置动静分离
由于动态资源和静态资源目前都处于服务端,所以为了减轻服务器压力,我们将js、css、img等静态资源放置在Nginx端,以减轻服务器压力
我们只需要把原本商品服务中static文件夹下的所有资源都转移到我们nginx服务当中,然后修改我们项目的配置文件(gulimall.conf)然后配置一下nginx服务对于请求静态资源的请求配置静态资源查找路径(就是我们nginx服务中存放static文件夹下静态资源的位置)就可以了。具体配置如下图:
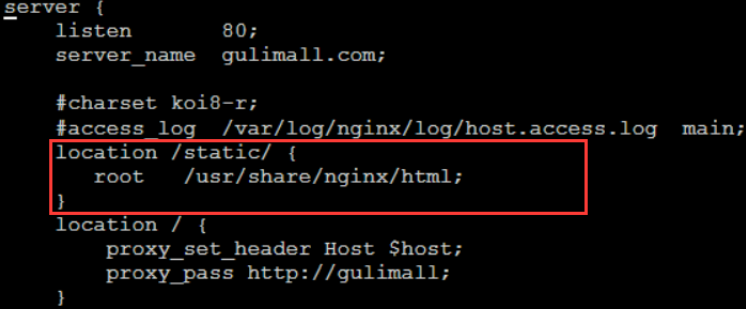
表示80端口下的有关gulumall.com域名下/static的请求去root目录下找,不是/static的请求才会进入/路径对应的配置地址进行请求。
配置完后记得重启nginx
最后需要修改一下我们前端页面请求静态资源的url,在前面全部加上/static前缀,这样才能被nginx转发静态请求之后正确解析出静态资源。
业务代码优化
这里我们三级分类数据获取的代码比较耗费性能,因为其每一次查询都需要查询数据库
首先来看一下我们之前编写的获取三级分类数据的业务逻辑代码:
@Override
public Map<String, List<Catelog2Vo>> getCatelogJson() {
//1查出所有一级分类
List<CategoryEntity> level1Categories = getLevel1Categories();
Map<String, List<Catelog2Vo>> parent_cid = level1Categories.stream().collect(Collectors.toMap(k -> k.getCatId().toString(), level1 -> {
//2 根据一级分类的id查找到对应的二级分类
List<CategoryEntity> level2Categories = this.baseMapper.selectList(new QueryWrapper<CategoryEntity> ().eq("parent_cid", level1.getCatId()));
//3 根据二级分类,查找到对应的三级分类
List<Catelog2Vo> catelog2Vos =null;
if(null != level2Categories || level2Categories.size() > 0){
catelog2Vos = level2Categories.stream().map(level2 -> {
//得对应的三级分类
List<CategoryEntity> level3Categories = this.baseMapper.selectList(new QueryWrapper<CategoryEntity>().eq("parent_cid", level2.getCatId()));
//封到Catalog3List
List<Catalog3List> catalog3Lists = null;
if (null != level3Categories) {
catalog3Lists = level3Categories.stream().map(level3 -> {
Catalog3List catalog3List = new Catalog3List(level2.getCatId().toString(), level3.getCatId().toString(), level3.getName());
return catalog3List;
}).collect(Collectors.toList());
}
return new Catelog2Vo(level1.getCatId().toString(), catalog3Lists, level2.getCatId().toString(), level2.getName());
}).collect(Collectors.toList());
}
return catelog2Vos;
}));
return parent_cid;
}
具体逻辑如下:
- 首先从数据库中查询所有的一级分类
- 根据一级分类的ID到数据库中找到对应的二级分类
- 根据二级分类的ID,到数据库中寻找到对应的三级分类
在这个逻辑实现中,每一个一级分类的ID,至少要经过3次数据库查询才能得到对应的三级分类,所以在大数据量的情况下,频繁的操作数据库,会导致我们服务的性能比较低。
这时我们就可以对其进行优化,我们可以考虑将这些分类数据一次性的加载到内存中,然后在内存中来操作这些数据而不是频繁的进行数据库交互操作(简单来说就是使用空间换时间),下面是优化后的查询代码:
@Override
public Map<String, List<Catelog2Vo>> getCatelogJson() {
//一性查询出所有的分类数据,减少对于数据库的访问次数,后面的数据操作并不是到数据库中查询,而是直接从这个集合中获取
List<CategoryEntity> categoryEntities = this.baseMapper.selectList(null);
//1查出所有一级分类
List<CategoryEntity> level1Categories = getParentCid(categoryEntities,0L);
Map<String, List<Catelog2Vo>> parent_cid = level1Categories.stream().collect(Collectors.toMap(k -> k.getCatId().toString(), level1 -> {
//2 根据一级分类的id查找到对应的二级分类
List<CategoryEntity> level2Categories = getParentCid(categoryEntities,level1.getCatId());
//3 根据二级分类,查找到对应的三级分类
List<Catelog2Vo> catelog2Vos =null;
if(null != level2Categories || level2Categories.size() > 0){
catelog2Vos = level2Categories.stream().map(level2 -> {
//得对应的三级分类
List<CategoryEntity> level3Categories = getParentCid(categoryEntities,level2.getCatId());
//封到Catalog3List
List<Catalog3List> catalog3Lists = null;
if (null != level3Categories) {
catalog3Lists = level3Categories.stream().map(level3 -> {
Catalog3List catalog3List = new Catalog3List(level2.getCatId().toString(), level3.getCatId().toString(), level3.getName());
return catalog3List;
}).collect(Collectors.toList());
}
return new Catelog2Vo(level1.getCatId().toString(), catalog3Lists, level2.getCatId().toString(), level2.getName());
}).collect(Collectors.toList());
}
return catelog2Vos;
}));
return parent_cid;
}
/**
* 在selectList中找到parentId等于传入的parentCid的所有分类数据
* @param selectList
* @param parentCid
* @return
*/
private List<CategoryEntity> getParentCid(List<CategoryEntity> selectList,Long parentCid) {
List<CategoryEntity> collect = selectList.stream().filter(item -> item.getParentCid() == parentCid).collect(Collectors.toList());
return collect;
}
整体的逻辑就是每次根据分类ID,找到所有子分类数据的时候,不再从数据库中查找,而是在内存中查询。因为我们已经一次性将所有的分类数据(包括123级分类,而原来只是查1级分类)全部加载到内存当中了,之后就不需要去数据库查数据了(相当于内存就是一个缓存分类数据的数据库),在我们的业务代码中就是只调用了一次selectList方法查所有分类数据。