代码编译过程分为四个阶段:
- 预处理阶段
- 编译阶段
- 汇编阶段
- 链接阶段
接下来我们写一段简单的代码 demo.c 看一下编译器的工作过程,这里用的是ubuntu里面的vim编辑器以及gcc编译器。
#include <stdio.h>
#define MAX_NUM 100
int main()
{
//打印MAX_NUM
printf("MAX_NUM=%d\n",MAX_NUM);
int a=1,b=2;
int c=a+b;
printf("c=%d\n",c);
return 0;
}
以上就是demo.c的代码。
下面,我们将通过控制gcc编译器的参数,让gcc编译器一步一步的编译,而不是一次性完成编译。首先,简单看一下gcc的参数:
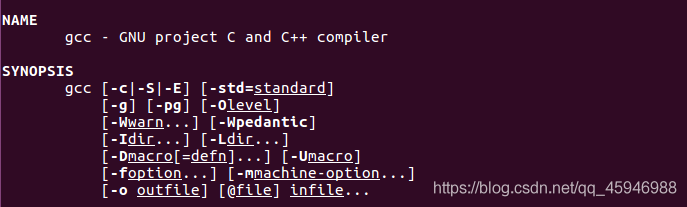 在ubuntu里面输入指令
在ubuntu里面输入指令 man gcc即可找到gcc编译器的参数。我们将使用的是最前面的-C,-S,-E指令。下面我们开始用指令来控制。
1.预处理阶段
输入指令:gcc -E demo.c -o demo.i,得到的demo.i文件就是预处理之后的文件。我们可以进入这个文件。
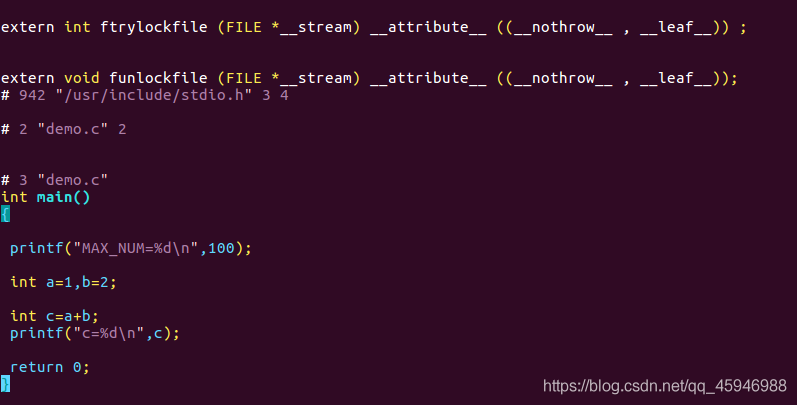
进入demo.i,我们可以看到,预处理阶段将头文件、宏定义展开,并且删除了注释部分,而main()函数部分还是c语言代码。因此,预处理阶段的任务的就是:
- 展开头文件
- 展开宏定义
- 删除所有注释
2.编译阶段
输入指令:gcc -S demo.i -o demo.S,得到的demo.S文件就是编译阶段的文件,.S后缀名表示的就是汇编代码。同样我们可以进入demo.S:
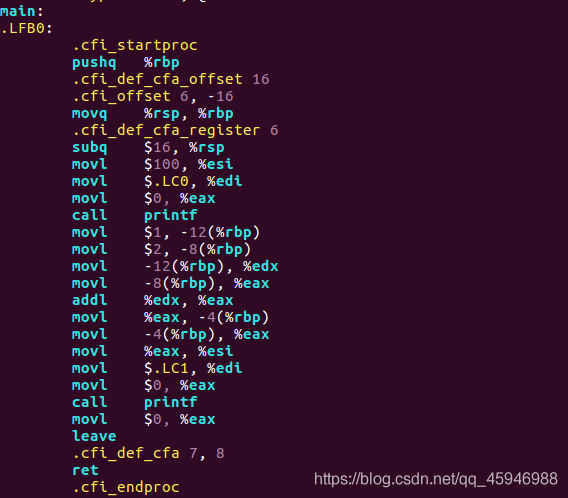
进入之后可以发现,代码都已经变成了汇编代码。这一阶段的主要任务就是:
- 检查语法错误
- 翻译成汇编语言
3.汇编阶段
输入指令:gcc -C demo.S -o demo.o,得到的demo.o就是汇编阶段后的代码:
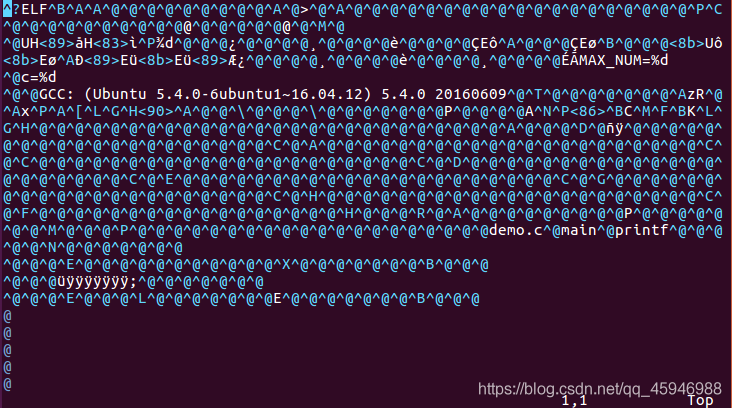
我们可以看到,这个时候已经是机器码了。但是这个文件能不能直接运行呢?我们输入指令:./demo.o试一下:

这里会报错。报错就说明.o不是最终能跑起来的文件。但是为什么会报错呢?这已经是机器码了,为什么还是不能直接运行呢?
因为我们看不懂机器码,所以我们先用反汇编来看看这个时候demo.o里面的内容。输入反汇编指令:objdump -d demo.o
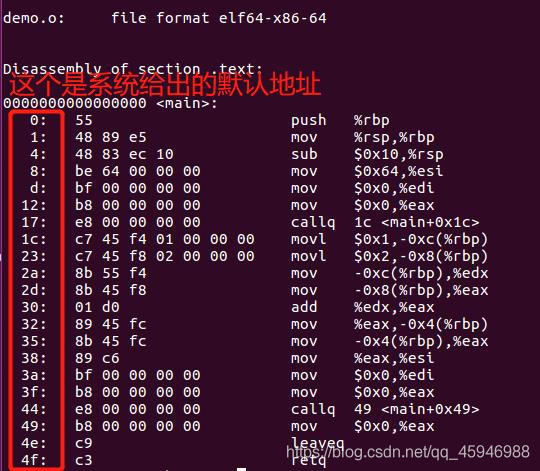
系统里面会有两套地址,一套是系统自己用的的默认地址,一套是用户代码运行时用的内存地址。cpu是跳到内存里拿地址的,代码运行时,操作系统会把他放到用户代码运行的内存空间里,所以,编译器编译后的最终能运行的那个文件里面的地址不能是系统默认地址,而应该是内存地址。
demo.o里面分配的是默认地址,操作系统把demo.o拿到内存时,不知道放在哪里(因为demo.o里面不是内存地址),因此无法运行。
为了把代码放到内存里,要给代码的每一条指令链接一个内存地址,链接后的地址就是其在内存中存放的地址。这就是编译的第4个阶段。
汇编阶段系统主要做的是
- 将汇编语言生成机器指令
4.链接阶段
输入指令gcc demo.o -o demo.elf,这时候的.elf文件就是最终能运行的文件。我们可以反汇编一下这个文件,输入反汇编指令:objdump -d demo.elf,可以看到:
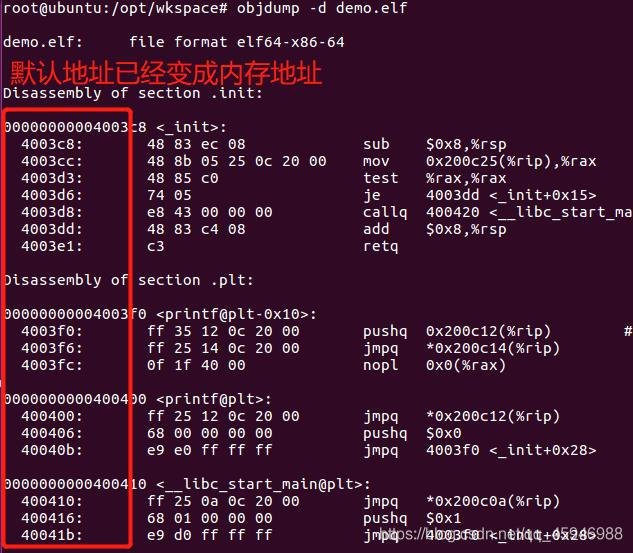 链接阶段主要做了三件事
链接阶段主要做了三件事
- 添加地址:把各种地址信息添加到headinfo中
- 补代码:补充的是固定的进程的启动代码和初始化代码
- 分段:一种技术,将机器码链接成段
总结
- 上述是用代码控制了编译过程。如果想要一步到位,我们可以直接输入指令
gcc demo.c -o demo.elf,后面的demo.elf,就算不加后缀名,默认也是elf的文件。 - 学习c语言不能单单学习语法,还要学习其他相关的基础知识。编译器是学习任何一门都需要接触的,所以了解编译器的工作原理也是很有必要的。
以上就是文章的主要内容,如有错误,请各位朋友给我留言嗷。谢谢你们~