处理器解决MESI协议带来写请求阻塞问题的方案:
(1)引入store buffer
将同步等待变成异步的,单独为写操作划分一个store buffer,这样读的数据完全由cache 获取。而store buffer只负责写数据。 CPU可以先将要写入的数据写到Store Buffer,然后继续做其它事情。等到收到其它CPU发过来的Cache Line(Read Response),再将数据从Store Buffer移到Cache Line。结构如下所示:
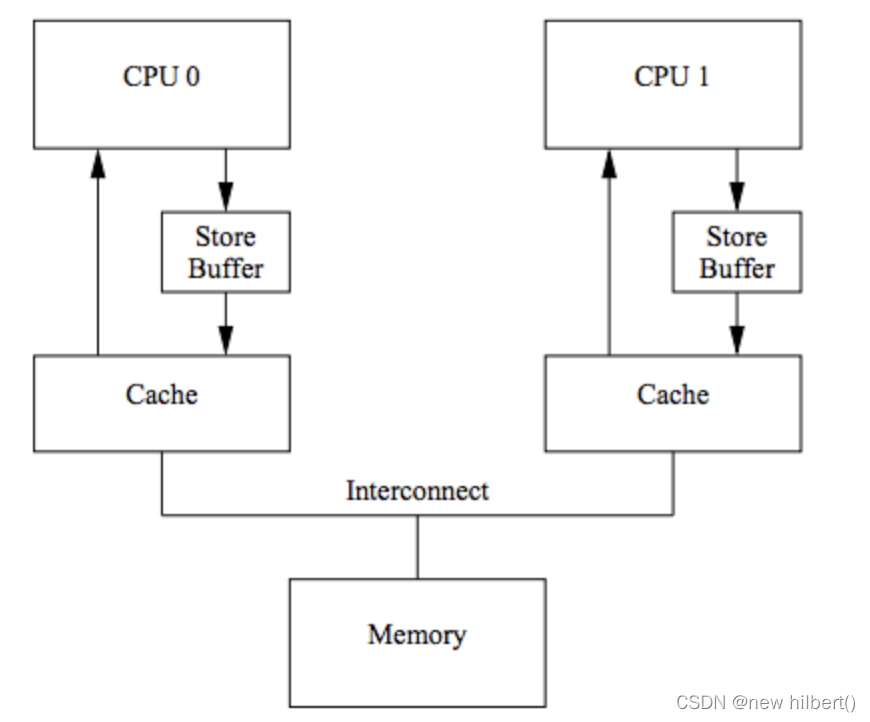
然后加了Store Buffer之后,会引入另一个问题:cache 的数据是不准的,因为store buffer数据还没同步到cache,store buffer 只负责写,取数从cache 里面取出来
a = 2;
b = a + 1 ;
初始状态下,假设a,b值都为0,并且a存在CPU1的Cache Line中(Shared状态),可能出现如下操作序列:
- CPU0 要写入A,发出Read Invalidate消息,并将a=1写入Store Buffer
- CPU1 收到Read Invalid,返回Read Response(包含a=0的Cache Line)和Invalid Ack
- CPU0 收到Read Response,更新Cache Line(a=0)
- CPU0 开始执行 b = a + 1,从Cache Line中加载a,得到a=0 ,然后此时 b的值是1,跟我们预测的 b =2+1 是违背。
- CPU0 收到所有的invalid ack,将Store Buffer中的a=1应用到Cache Line
造成原因: 同一个CPU存在对a的两份拷贝,一份在Cache,一份在Store Buffer,前者用于读,后者用于写,因而出现单线程情况下CPU执行顺序与程序顺序(Program Order)不一致(看起来是先执行了b=a+1,再执行a=1)。
科普一下:
as-if-serial语义:不管怎么重排(编译器和处理器为了提高并行度),(单线程)程序的执行结果不能被改变,不会对存在数据依赖关系的操作进行重排序,编译器,runtime和处理器必须遵守as-if-serial 语义。
- 真·重排序:编译器,底层硬件cpu等(指令级别),出于“优化”的目的,按照某种规则将指令重新排序。
- 假·重排序:由于store buffer 缓存同步cache
的顺序问题,看起来指令被重排序了。但是在语义上面是不允许被重排序的,因为存在关联关系。
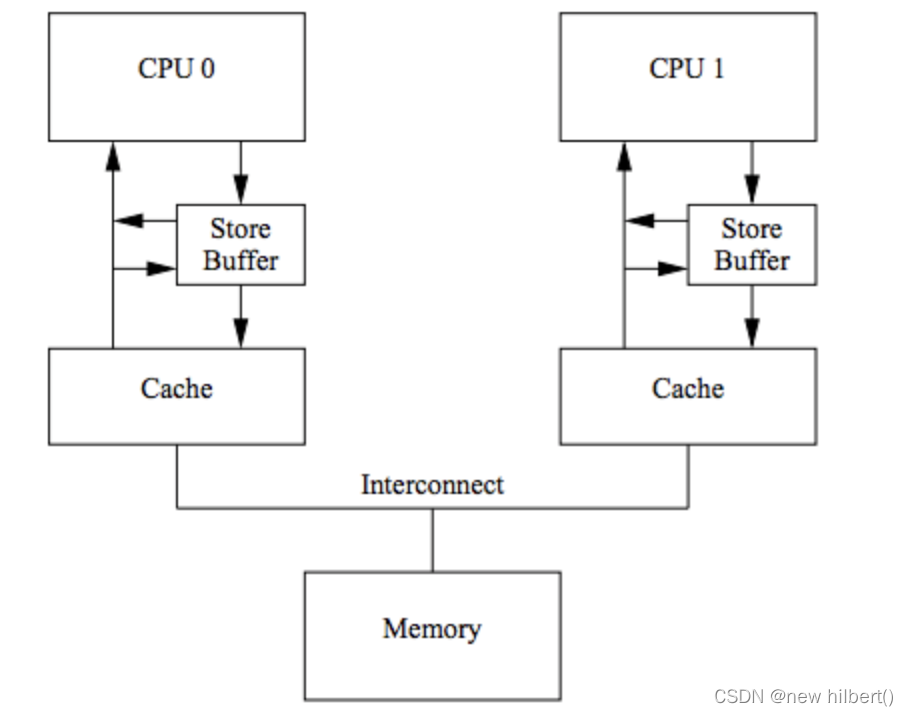
Store Forwarding 技术:
CPU可以直接从Store Buffer中加载数据,即支持将CPU存入Store Buffer的数据传递(forwarding)给后续的加载操作,而不经由Cache。(为了解决同一cpu里面cache 和store buffer 数值不一致)
(2)Invalid Queue:将同步响应Invalid ack 变成异步
Invalid Ack耗时的主要原因是CPU要先将对应的Cache Line置为Invalid后再返回Invalid Ack,一个很忙的CPU可能会导致其它CPU都在等它回Invalid Ack。
解决思路还是化同步为异步 : CPU不必要处理了Cache Line之后才回Invalid Ack,而是可以先将Invalid消息放到某个请求队列Invalid Queue,然后就返回Invalid Ack。CPU可以后续再处理Invalid Queue中的消息,大幅度降低Invalid Ack响应时间。
此时的CPU Cache结构图如下:
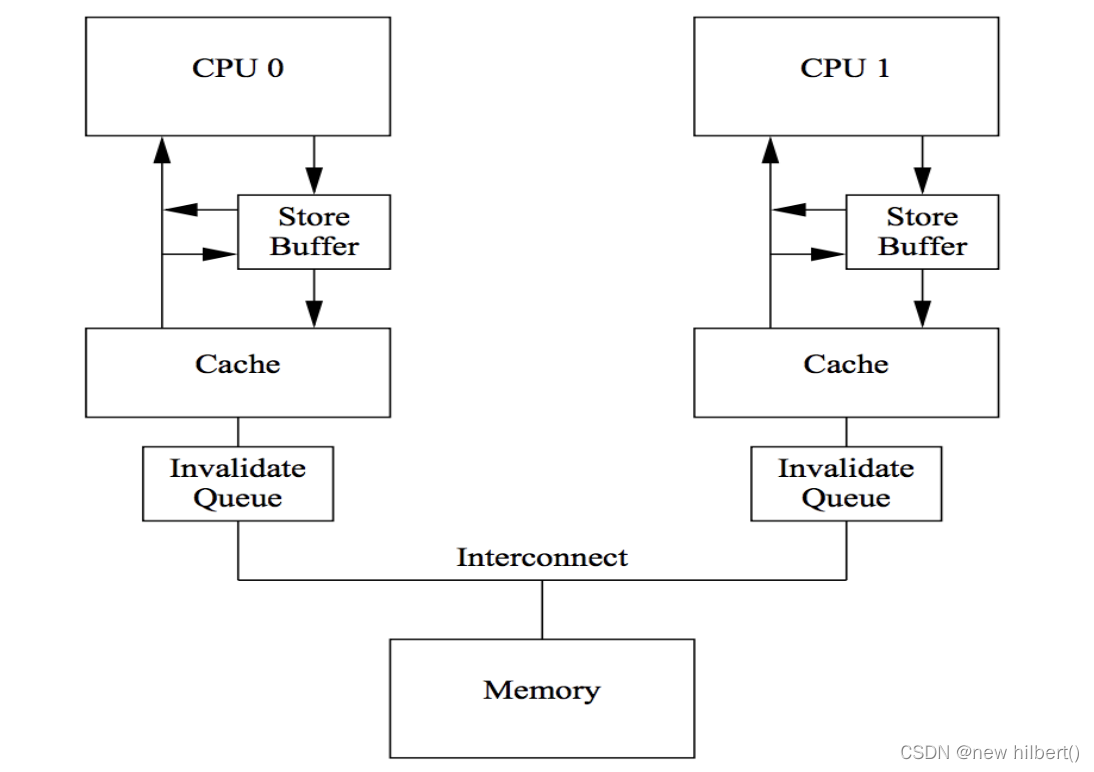
- 对于所有的收到的 Invalidate 请求,Invalidate Acknowlege 消息必须立刻发送 Invalidate
- 并不真正执行,而是被放在一个特殊的队列中,在方便的时候才会去执行。
加了lnvalid queue之后,会引入另一个问题:cache 的数据是不准的,因为lnvalid queue数据还没同步到cache,从cache 读出来还是不准的数据。
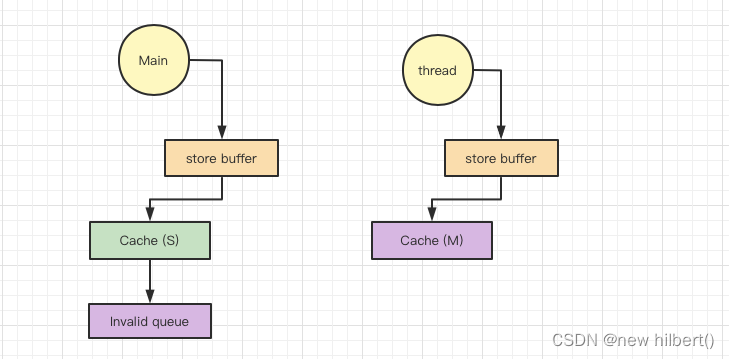
回到我们一开始的问题,在改良后的cpu 缓存模型下,为什么thread还看不到flag 变量的修改?
是因为有延迟,store buffer 异步等待 其他cpu 的valid ack,才能将cache变成exclusive 并且修改变成modify。
- main 线程发出invalid 信号,等待 thread 信号响应 invalid ack 信号,thread 收到invalid
信号,把cache设置为Invalid。 然后返回Invalid ack 信号
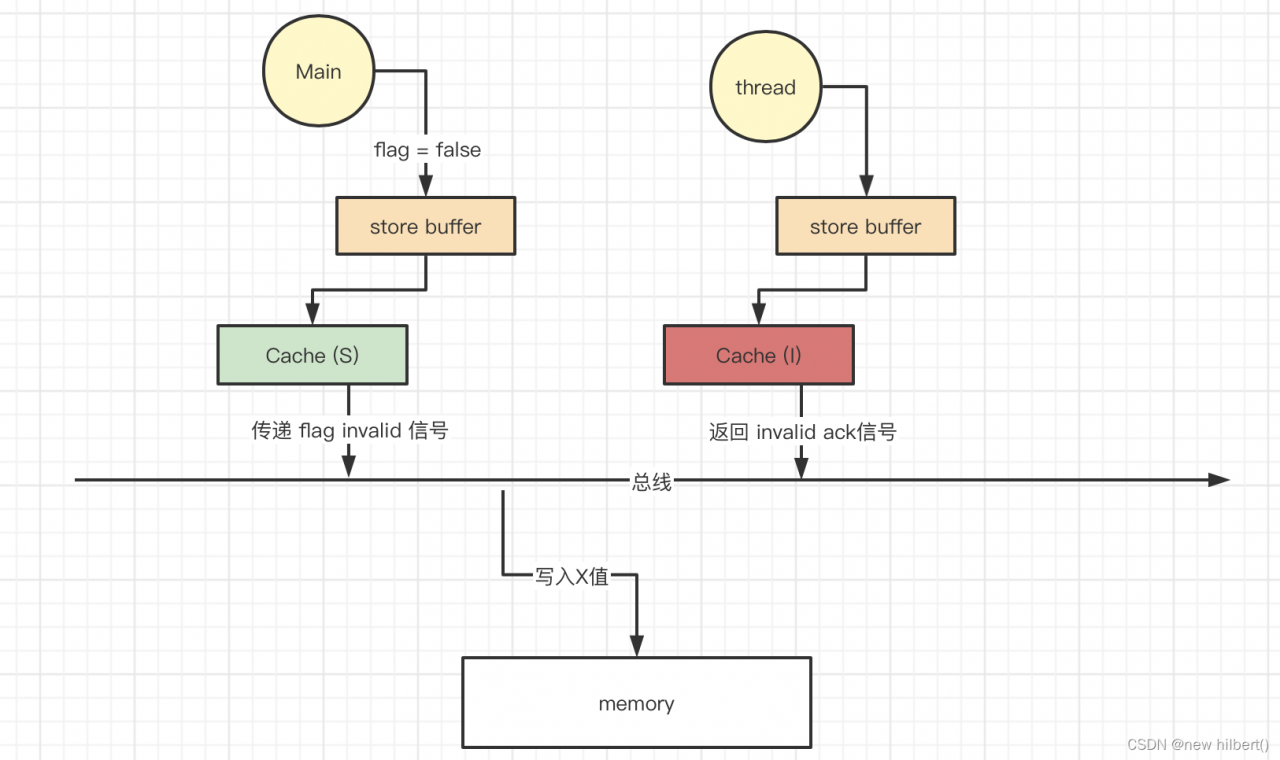
- 但其实我们main程序还没等到invalid ack 就结束了,根本就没有修改到memory 的值,thread 因为cache Invalid 只能从memory 获取到旧的值

public class NoVolatile {
private boolean flag = true;
public void test() {
System.out.println("start");
while (flag) {
}
System.out.println("end");
}
public static void main(String[] args) {
NoVolatile noVolatile = new NoVolatile();
new Thread(noVolatile::test).start();
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
}
noVolatile.flag = false;
}
}
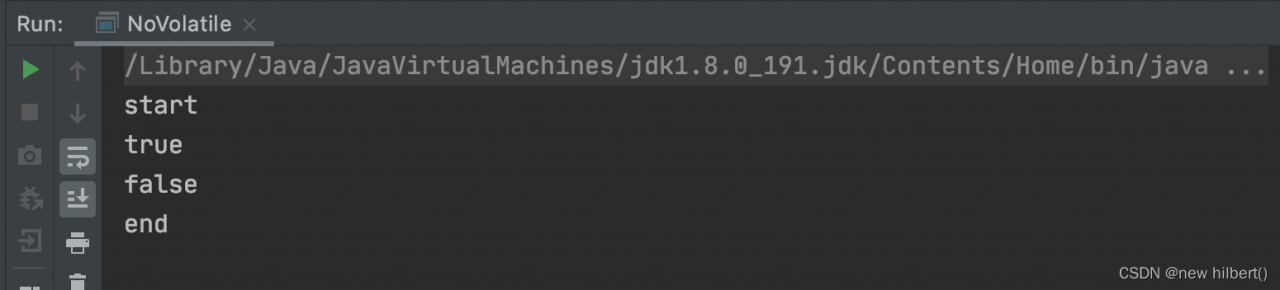
//执行结果:
start
那么怎样才能看到thread 线程在不通过validate的情况下能获取到值呢? 将 main 放久一些,就能得到这个效果。
public class NoVolatile {
private boolean flag = true;
public void test() {
System.out.println("start");
System.out.println(flag);
try {
Thread.sleep(10000);
} catch (InterruptedException e) {
}
System.out.println(flag);
System.out.println("end");
}
public static void main(String[] args) {
NoVolatile noVolatile = new NoVolatile();
new Thread(noVolatile::test).start();
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
}
noVolatile.flag = false;
try {
Thread.sleep(10000);
} catch (InterruptedException e) {
}
}
}
为了解决处理器等待(写请求阻塞)问题,引入了写缓冲区和无效队列,又导致了重排序和可见性问题
存在问题:
a、可见性:
- 比如处理器1写入到自己的写缓冲器中,处理器2通过总线去read数据读取到的还是旧数据;
- 比如处理器1接受到了 a的invalid 消息,将消息写入了Invalid queue ,但是没有处理。会导致处理器1读取a的消息,会读到本该无效的值
b、有序性:
- store load重排:处理器1的写操作写入到了写缓存区对处理器2不可见,处理器2读了一份数据则觉得load在前store在后;
- store store重排:处理器1的第一个写操作发现数据是s状态,写入到写缓冲区;第二个写操作为m状态直接修改,即两个写操作顺序反过来;
本质问题:cp1 store buffer 到 cp2 cache 存在比较大的延迟问题,Invalid queue 不及时同步数据存在延迟问题,跨线程依赖的情况下无法容忍延迟问题。
解决方案:对于上面的内存不一致,很难从硬件层面优化,因为CPU不可能知道哪些值是相关联的,因此硬件工程师提供了一个叫内存屏障的东西。设置屏障方法是禁止重排续,变成同步效果,这样的就解决了,可见性和重排续问题。
写屏障:
写屏障 Store Memory Barrier(a.k.a. ST, SMB, smp_wmb)是一条告诉处理器在执行这之后的指令之前,应用所有已经在存储缓存(store buffer)中的保存的指令。
cpu提供了写屏障(write memory barrier)指令,Linux操作系统将写屏障指令封装成了smp_wmb()函数,cpu执行smp_mb()的思路是,会先把当前store buffer中的数据刷到cache之后,再执行屏障后的“写入操作”,该思路有两种实现方式: 一是简单地刷store buffer,但如果此时远程cache line没有返回,则需要等待,二是将当前store buffer中的条目打标,然后将屏障后的“写入操作”也写到store buffer中,cpu继续干其他的事,当被打标的条目全部刷到cache line,之后再刷后面的条目。
读屏障:
读屏障 Load Memory Barrier (a.k.a. LD, RMB, smp_rmb) 是一条告诉处理器在执行任何的加载前,先应用所有已经在失效队列 Invalid queue 中的失效操作的指令。
可以通过读屏障让CPU标记当前Invalid Queue中所有的条目,所有的后续加载操作必须先等Invalid Queue中标记的条目处理完成再执行
因为cpu可能只关注,写情况或者读情况。大多数CPU架构将内存屏障分为了读屏障(Read Memory Barrier)和写屏障(WriteMemory Barrier)
- 读屏障 lfence : 任何读屏障前的读操作都会先于读屏障后的读操作完成
- 写屏障 sfence : 任何写屏障前的写操作都会先于写屏障后的写操作完成
- 全屏障 mfence : 同时包含读屏障和写屏障的作用
内存屏障能够解决重排续和可见性问题。那么volatile是怎么解决的?在哪里实现内存屏障的?
volatile static int a = 0;
//javap 反编译后得到 ACC_VOLATILE 关键字
static volatile int a;
descriptor: I
flags: ACC_STATIC, ACC_VOLATILE
在accessFlags.hpp 文件中
//ACC_VOLATILE 关键字
bool is_volatile () const { return (_flags & JVM_ACC_VOLATILE ) != 0; }
在bytecodeInterpreter.cpp 文件中
- Volatile 写操作的源码
if (cache->is_volatile()) {
if (tos_type == itos) {
obj->release_int_field_put(field_offset, STACK_INT(-1));
} else if (tos_type == atos) {
VERIFY_OOP(STACK_OBJECT(-1));
obj->release_obj_field_put(field_offset, STACK_OBJECT(-1));
OrderAccess::release_store(&BYTE_MAP_BASE[(uintptr_t)obj >> CardTableModRefBS::card_shift], 0);
} else if (tos_type == btos) {
obj->release_byte_field_put(field_offset, STACK_INT(-1));
} else if (tos_type == ltos) {
obj->release_long_field_put(field_offset, STACK_LONG(-1));
} else if (tos_type == ctos) {
obj->release_char_field_put(field_offset, STACK_INT(-1));
} else if (tos_type == stos) {
obj->release_short_field_put(field_offset, STACK_INT(-1));
} else if (tos_type == ftos) {
obj->release_float_field_put(field_offset, STACK_FLOAT(-1));
} else {
obj->release_double_field_put(field_offset, STACK_DOUBLE(-1));
}
OrderAccess::storeload();
}
两个关键动作:
- 调用release_int_field_put 函数,执行赋值动作
- 执行OrderAccess::storeload()
inline void oopDesc::release_int_field_put(int offset, jint contents) { OrderAccess::release_store(int_field_addr(offset), contents);
}
inline void OrderAccess::release_store(volatile jint* p, jint v) {
*p = v;
}
- Volatile 读操作
if (cache->is_volatile()) {
if (tos_type == atos) {
VERIFY_OOP(obj->obj_field_acquire(field_offset));
SET_STACK_OBJECT(obj->obj_field_acquire(field_offset), -1);
} else if (tos_type == itos) {
SET_STACK_INT(obj->int_field_acquire(field_offset), -1);
} else if (tos_type == ltos) {
SET_STACK_LONG(obj->long_field_acquire(field_offset), 0);
MORE_STACK(1);
} else if (tos_type == btos) {
SET_STACK_INT(obj->byte_field_acquire(field_offset), -1);
} else if (tos_type == ctos) {
SET_STACK_INT(obj->char_field_acquire(field_offset), -1);
} else if (tos_type == stos) {
SET_STACK_INT(obj->short_field_acquire(field_offset), -1);
} else if (tos_type == ftos) {
SET_STACK_FLOAT(obj->float_field_acquire(field_offset), -1);
} else {
SET_STACK_DOUBLE(obj->double_field_acquire(field_offset), 0);
MORE_STACK(1);
}
}
关键动作:
JVM定义的内存屏障有这些:

inline void OrderAccess::loadload() { acquire(); }
inline void OrderAccess::storestore() { release(); }
inline void OrderAccess::loadstore() { acquire(); }
inline void OrderAccess::storeload() { fence(); }
inline void OrderAccess::acquire() {
volatile intptr_t local_dummy;
#ifdef AMD64
__asm__ volatile ("movq 0(%%rsp), %0" : "=r" (local_dummy) : : "memory");
#else
__asm__ volatile ("movl 0(%%esp),%0" : "=r" (local_dummy) : : "memory");
#endif // AMD64
}
inline void OrderAccess::release() {
// Avoid hitting the same cache-line from
// different threads.
volatile jint local_dummy = 0;
}
inline void OrderAccess::fence() {
//判断是不是多核
if (os::is_MP()) {
// always use locked addl since mfence is sometimes expensive
#ifdef AMD64
__asm__ volatile ("lock; addl $0,0(%%rsp)" : : : "cc", "memory");
#else
__asm__ volatile ("lock; addl $0,0(%%esp)" : : : "cc", "memory");
#endif
}
}
GCC内嵌汇编语言
__asm__ volatile ("lock; addl $0,0(%%esp)" : : : "cc", "memory");
__asm__ (汇编语句模板: 输出部分: 输入部分: 破坏描述部分)
破坏描述符: 用于通知编译器我们使用了哪些寄存器或内存,由逗号格开的字符串组成,每个字符串描述一种情况,一般是寄存器名;,此外还有内存“memory”和“cc”。我们称形如:“%eax”、“%ebx”、“%ecx”等为寄存器破坏描述符;称“memory”为内存描述符,表示修改了memory;“cc” 表示汇编程序代码修改了标志寄存器’
memory: 破坏描述符,告诉GCC 内存已经被修改,GCC会保证在此内联汇编之前,如果某个内存的内容被装入了寄存器,那么在这个内联汇编之后,如果需要使用这个内存处的内容;就会在这段指令之前,插入必要的指令将寄存器中的变量值先写回主存,指令之后读取时也会直接到这个内存处重新读取,而不是使用被存放在寄存器中的拷贝。(CPP 转化成汇编语言还会再优化的)
volatile 是C++的一个关键字: 遇到这个关键字声明的变量,编译器对访问该变量的代码就不再进行优化,而可以提供对特殊地址的稳定访问。
声明时语法:int volatile vInt;
当要求使用 volatile 声明的变量的值的时候,系统总是重新从它所在的内存读取数据,即使它前面的指令刚刚从该处读取过数据。而且读取的数据立刻被保存
在x86处理器当中,会忽略掉前三种,只关心storeload(读写屏障)
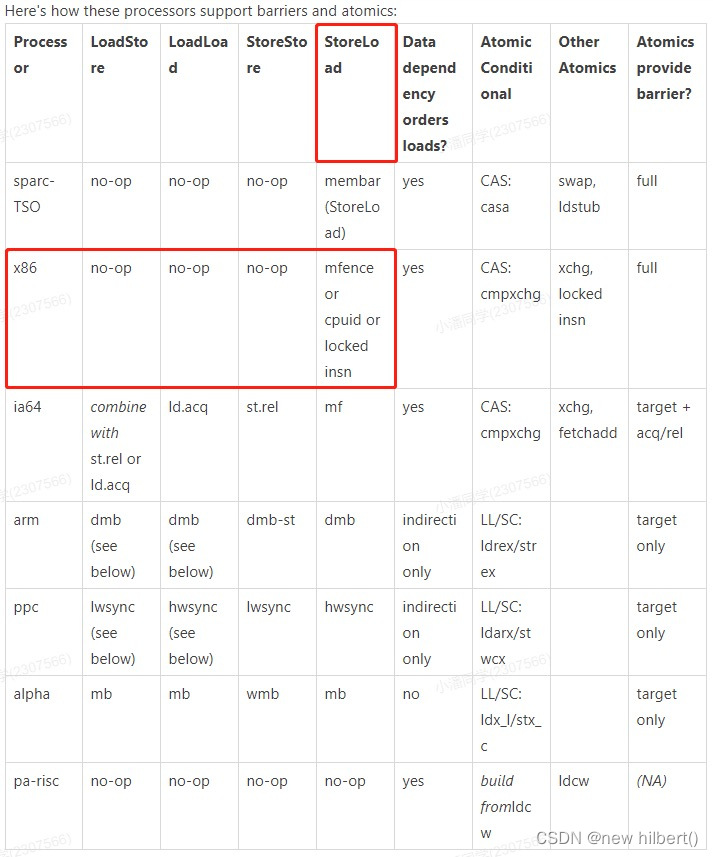
对于storeload(读写屏障),走到的是 mfence方法,os::is_MP()用于判断是否是多核架构,#ifdef AMD64用于判断是否是64位处理器,然后会添加一句汇编码:lock; addl $0,0(%%rsp),这就是使用了lock来达到内存屏障的效果
那为什么Lock 关键字能够达到内存屏障的效果?
Lock前缀,Lock不是一种内存屏障,但是它能完成类似内存屏障的功能。Lock会对CPU总线和高速缓存加锁,可以理解为CPU指令级的一种锁。它后面可以跟ADD, ADC, AND, BTC, BTR, BTS, CMPXCHG, CMPXCH8B, DEC, INC, NEG, NOT, OR, SBB, SUB, XOR, XADD, and XCHG等指令
- 总线锁
LOCK#信号就是我们经常说到的总线锁,处理器使用LOCK#信号达到锁定总线,来解决原子性问题,当一个处理器往总线上输出LOCK#信号时,其它处理器的请求将被阻塞,此时该处理器此时独占共享内存
总线锁这种做法锁定的范围太大了,导致CPU利用率急剧下降,因为使用LOCK#是把CPU和内存之间的通信锁住了,这使得锁定时期间,其它处理器不能操作其内存地址的数据 ,所以总线锁的开销比较大
- 缓存锁(锁缓存行,其他CPU不能缓存改行)
如果访问的内存区域已经缓存在处理器的缓存行中,P6系统和之后系列的处理器则不会声明LOCK#信号,它会对CPU的缓存中的缓存行进行锁定,在锁定期间,其它CPU 不能同时缓存此数据,在修改之后,通过缓存一致性协议来保证修改的原子性,这个操作被称为“缓存锁”
- 什么情况下使用总线锁(LOCK#)
当操作的数据不能被缓存在处理器内部,或操作的数据跨多个缓存行时,也会使用总线锁
因为从P6系列处理器开始才有缓存锁,所以对于早些处理器是不支持缓存锁定的,也会使用总线锁
- LOCK#作用总结
- 锁总线,其它CPU对内存的读写请求都会被阻塞,直到锁释放,因为锁总线的开销比较大,后来的处理器都采用锁缓存替代锁总线,在无法使用缓存锁的时候会降级使用总线锁
- lock期间的写操作会回写已修改的数据到主内存,同时通过缓存一致性协议让其它CPU相关缓存行失效
- 总线锁、缓存锁可以保证原子性,缓存一致性协议可以保证可见性
X86版本的Storeload 是用于volatile的写操作,那如何做到volatile写完之后的值,被观察到?
if (cache->is_volatile()) {
if (tos_type == itos) {
obj->release_int_field_put(field_offset, STACK_INT(-1));
}
......
OrderAccess::storeload();
}
inline void OrderAccess::storeload() { fence(); }
inline void OrderAccess::fence() {
//判断是不是多核
if (os::is_MP()) {
// always use locked addl since mfence is sometimes expensive
#ifdef AMD64
__asm__ volatile ("lock; addl $0,0(%%rsp)" : : : "cc", "memory");
#else
__asm__ volatile ("lock; addl $0,0(%%esp)" : : : "cc", "memory");
#endif
}
}
addl $0,0(%%esp): 表示将数值0加到esp寄存器中,而该寄存器指向栈顶的内存单元。加上一个0,esp寄存器的数值依然不变。本身没有太大的意义。
memory: 破坏描述符,告诉GCC 内存已经被修改,GCC会保证在此内联汇编之前,如果某个内存的内容被装入了寄存器,那么在这个内联汇编之后,如果需要使用这个内存处的内容;就会在这段指令之前,插入必要的指令将寄存器中的变量值先写回主存,指令之后读取时也会直接到这个内存处重新读取,而不是使用被存放在寄存器中的拷贝。(会强制刷回内存,和读内存的值)
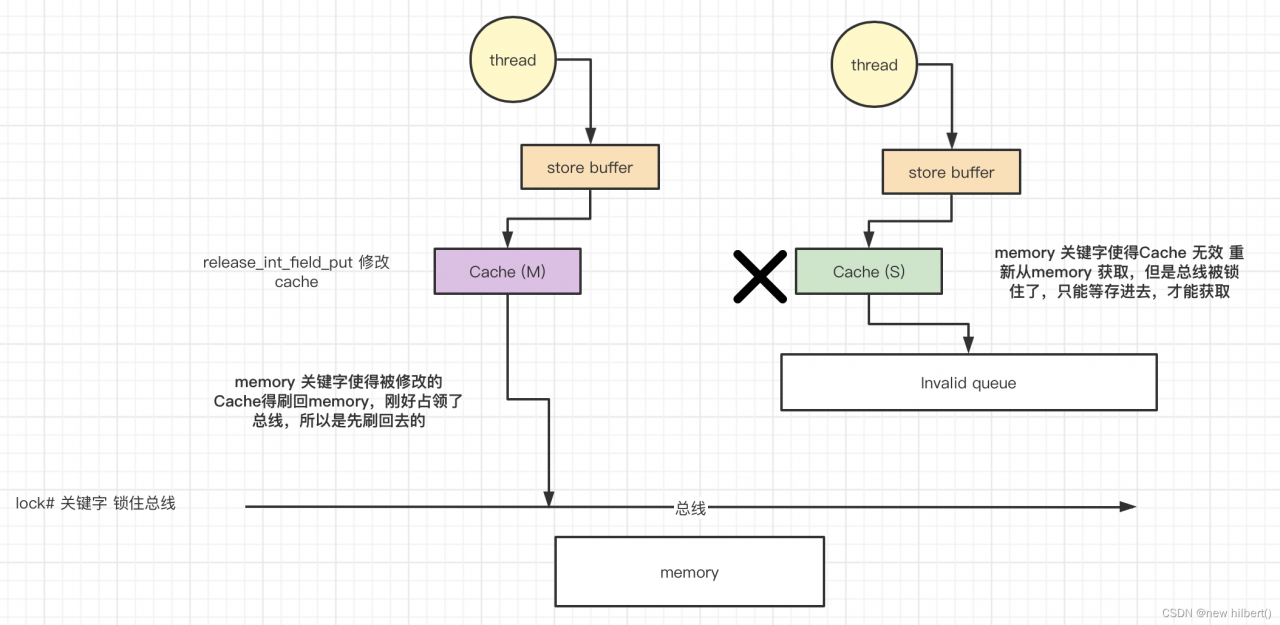
保证可见性步骤如下:
- release_int_field_put 修改cache,使得cache变成modified状态
- lock# 关键字 锁住总线
- memory 关键字使得被修改的Cache得刷回memory,刚好占领了总线,所以是先刷回去的
- memory 关键字使得其他cpu 的Cache 无效 重新从memory 获取,但是总线被锁住了,只能等存进去,才能获取
volatile 保证原子性吗?
public class AtomicVolatile {
public static volatile int a = 0;
public static void main(String[] args) throws Exception {
Thread t1 = new Thread(() -> {
for (int i = 0; i < 10000; i++) {
a++;
}
System.out.println("t1 执行完了");
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 10000; i++) {
a++;
}
System.out.println("t2 执行完了");
});
t1.start();t2.start();
t1.join(); t2.join();;
System.out.println("a的值:" + a);
}
}
//执行结果
t2 执行完了
t1 执行完了
a的值:13585
为什么volatile 修饰的变量没有办法保证原子性?最后相加的结果不是20000
原子性:即一个操作或者多个操作,要么全部执行并且执行的过程不会被任何因素打断,要么就都不执行
JVM 8种原子性操作:
- read(读取):作用于主内存,它把变量值从主内存传送到线程的工作内存中
- load(载入):作用于工作内存,它把read操作的值放入工作内存中的变量副本中;
- use(使用):作用于工作内存,它把工作内存中的值传递给执行引擎
- assign(赋值):作用于工作内存,它把从执行引擎获取的值赋值给工作内存中的变量
- store(存储):作用于工作内存,它把工作内存中的一个变量传送给主内存中
- write(写入):作用于主内存,它把store传送值放到主内存中的变量中。
- unlock(解锁):作用于主内存,它将一个处于锁定状态的变量释放出来,释放后的变量才能够被其他线程锁定
- lock(锁定):作用于主内存,它把一个变量标记为一条线程独占状态;
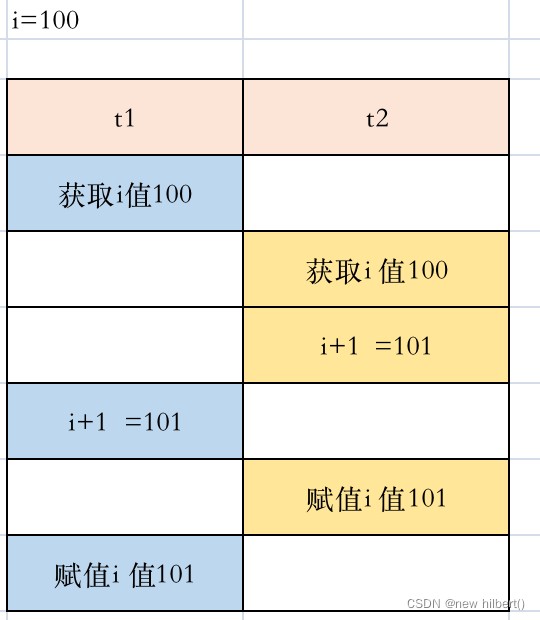
I++ 其实 是三个动作
- 获取I的值
- 将I的值进行+1 得到x
- 将x赋值于I
因为I++ 这个语句可以被拆成3个动作来执行,I++是非原子性动作,无法保证一起完成。所以存在下面这种情况发生
使用synchronized关键字来保证原子性
public class AtomicVolatile {
public static volatile Integer a = 0;
public static Integer b = 0;
public static void main(String[] args) throws Exception {
Thread t1 = new Thread(() -> {
//不要拿a来做锁对象,Integer 大于127就变了新的对象了,踩坑,切记切记
synchronized (b) {
for (int i = 0; i < 10000; i++) {
a++;
}
}
System.out.println("t1 执行完了a:" + a);
});
Thread t2 = new Thread(() -> {
synchronized (b) {
for (int i = 0; i < 10000; i++) {
a++;
}
}
System.out.println("t2 执行完了a:" + a);
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println("a的值:" + a);
}
}
//执行结果
t1 执行完了a:20000
t2 执行完了a:20000
a的值:20000

总结:
volatile 可以保证可见性和顺序性(通过内存屏障的方式)
volatile 不保证原子性
课外拓展
为什么 多线程创建 new 实例的时候需要加上Volatile关键字?
public class SingletonFactory {
private volatile static SingletonFactory myInstance;
public static SingletonFactory getMyInstance() {
if (myInstance == null) {
synchronized (SingletonFactory.class) {
if (myInstance == null) {
myInstance = new SingletonFactory();
}
}
}
return myInstance;
}
public static void main(String[] args) {
SingletonFactory.getMyInstance();
}
}
synchronized已经保证线程可见性了,为什么还需要volatile来修饰SingletonFactory myInstance呢?
myInstance = new SingletonFactory(); 反编译得到 初始化一个对象分为三步
- new 分配一片内存空间(在类加载时就已经确定需要分配多少空间了)
- invokespecial 对象的初始化 (构造方法)
- astore_2 myInstance引用指向对象的内存地址
在单线程情况下,不一定是按照123顺序执行的,可能是132,因为有CPU的指令重排序
在多线程情况下,线程1执行时,如果发生了指令重排序,1,3执行完后,myInstance指向的对象非空,此时线程2执行时,正好执行到 if (myInstance == null),那么就不会为 当前this对象初始化变量SingletonFactory myInstance了,不符合程序运行的预期
加上volatile后,禁止指令重排序,不会有以上问题