第一步 将数据降维3维
pca = PCA(n_components = 3)
pca_weight_vec = pca.fit_transform(weight_vec)
pca_weight_vec[0:5]第二步 基于轮廓系数的最优簇数
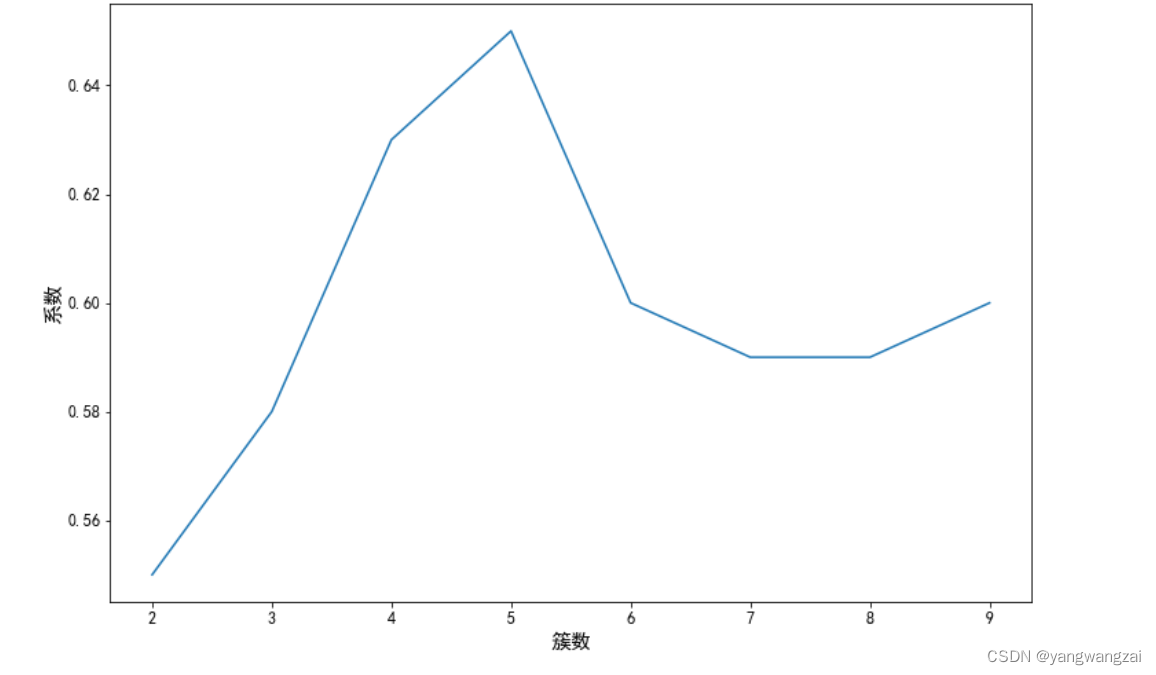
# 轮廓系数确定簇数 -> 最佳值为1,最差值为-1。接近0的值表示重叠的群集
def silhouette_score_show(data_vec=None, name=None):
k = range(2, 10)
score_list = []
for i in k:
model = KMeans(n_clusters=i).fit(data_vec)
y_pre = model.labels_
score = round(silhouette_score(data_vec, y_pre), 2) #round函数 返回, 前的数字的指定位数的值round(89.63222,2) = 89.63
score_list.append(score)
plt.figure(figsize=(12, 8))
plt.plot(list(k), score_list)
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.xlabel('簇数', fontsize=15)
plt.ylabel('系数', fontsize=15)
plt.savefig(f'{name}轮廓系数.jpg')
plt.show()
版权声明:本文为yangwangzai原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。