一、什么是堆?
C语言堆是由malloc(),calloc(),realloc()等函数动态获取内存的一种机制。使用完成后,由程序员调用free()等函数进行释放。使用时,需要包含stdlib.h头文件。
C++预言的堆管理则是使用new操作符向堆管理器申请动态内存分配,使用delete操作符将使用完毕内存的释放给堆管理器。
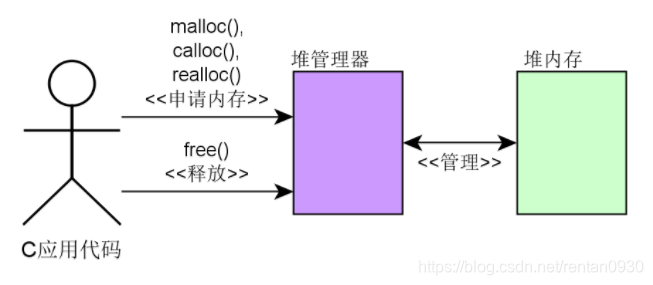
要动态管理一片内存,且需要动态分配释放,这样一个需求。很显然C语言需要将动态内存区抽象描述起来并实现动态管理。事实上,C语言中堆管理器其本质是利用数据结构将堆区抽象描述,所需要描述的方面:
- 可用于分配的内存
- 正在使用的内存块
- 释放掉的内存块
再利用相应算法对于这类数据结构对象进行动态管理而实现的堆管理器。
经常看到各种算法书很多只讲算法原理,而不讲应用实例,往往体会不深。私以为可以做些改善。学而不能致用,何必费力去学。所以不是晦涩难懂的算法无用,而是没有去真正结合应用。可以再进一步想,如果算法没有应用场景,也一定会在技术发展的历程中逐渐被世人遗忘。所以建议学习阅读算法书籍时,找些实例来看看,一定会加深对算法的理解领悟。这是比较重要的题外话,送给大家以共勉。
所以从本质上讲,堆管理器就是数据结构+算法实现的动态内存管理器,管理内存的动态分配以及释放。
二、为什么要用堆?
C编程语言对内存管理方式有
静态,自动或动态
三种方式。静态内存分配的变量通常与程序的可执行代码一起分配在主存储器中,并在程序的整个生命周期内有效。自动分配内存的变量在栈上分配,并随着函数的调用和返回而申请或释放。对于静态分配内存和自动分配内存的生命周期,分配的大小必须是编译时常量(可变长度自动数组[5]除外)。如果所需的内存大小直到运行时才知道(例如,如果要从用户或磁盘文件中读取任意大小的数据),则使用固定大小的数据对象则满足不了要求了。试想,即便假定都知道要多大内存,如在windows/Linux下有那么多应用程序,每个应用程序加载时都将运行中所需的内存采样静态分配策略,则如多个程序运行内存将很快耗尽。
分配的内存的生命周期也可能引起关注。静态或自动分配都不能满足所有情况。自动分配内存不能在多个函数调用之间保留,而静态数据在程序的整个生命周期中必然保留,无论是否真正需要(所以都采用这样的策略必然造成浪费)。在许多情况下,程序员在管理分配的内存的生命周期具有更多的灵活性。
通过使用动态内存分配则避免了这些限制/缺点,在动态内存分配中,更明确(但更灵活)地管理内存,通常是通过从免费存储区(非正式地称为“堆”)中分配内存(为此目的而构造的内存区域)进行分配的。在C语言中,库函数malloc用于在堆上分配一个内存块。程序通过malloc返回的指针访问该内存块。当不再需要内存时,会将指针传递给free,从而释放内存,以便可以将其用于其他目的。
堆可实现动态内存管理的多样性,在牺牲一定开销情况下(申请/释放开销,以及内存开销),可以提供内存的利用率,在一定程度上解决内存不足的需求。
三、谁实现堆?
如果一问到这个问题,马上会说C编译器。不错C编译器实现了堆管理器,而事实上并非编译器在编译的过程中实现动态内存管理器,而是C编译器所实现的C库实现了堆管理器,比如ANSI C,VC, IAR C编译器,GNU C等其实都需要一些C库的支持,那么这些库的内部就隐藏了这么一个堆管理器。操作系统内核也可能实现堆管理器。
四、堆使用常见错误
-
使用前没有检查分配失败
:内存分配不能保证成功,而是可能返回一个空指针。使用返回的值,而不检查分配是否成功,将调用未定义的行为。这通常会导致崩溃,但不能保证会发生崩溃,因此依赖于它而不检查结果也会导致问题。 -
内存泄露
:使用free释放内存失败会导致不可重用内存的累积,程序不再使用这些内存。这将浪费内存资源,并可能在耗尽这些资源时导致分配失败。 -
逻辑错误
:所有的分配必须遵循相同的模式:使用malloc分配,使用free释放,重新分配。如果不能坚持这种模式,例如在调用free(悬空指针)之后或在调用malloc(野指针)之前使用内存、调用free两次(“double free”)等,通常会导致分段错误并导致程序崩溃。这些错误可能是偶发的,而且很难调试。
免责声明:转载文章为传播相关技术,版权归原作者所有,如有侵权,请联系删除