文章目录
OkHttp 的使用
OkHttp 的基本使用网上非常多,这里不细说怎么使用,也可以参考我另外一篇文章:
OkHttp的使用
OkHttpClient
OkHttpClient
的主要功能就是
提供构建网络请求所需的一些参数设置,属于网络请求的参数管理类
。
看懂 OkHttpClient 的参数需要对
HTTP
有足够的了解,有理论支持的基础上再看 OkHttp 源码,将会变得非常简单。
接下来详细介绍 OkHttpClient 提供的可配置的参数具体有哪一些,这些配置又有什么作用。
1、
val dispatcher: Dispatcher
调度器。主要作用是分发处理在等待队列和执行队列的 Call,有序的处理 Call 执行 HTTP 请求。
2、
val connectionPool: ConnectionPool
连接池。发起 HTTP 请求需要建立连接,而连接
Connection
的建连和销毁是消耗资源的,和线程池一样,连接池的作用就是复用重用 Connection。不同的 HTTP 协议有不同的重用场景:
-
HTTP/1.1 连接池的重用场景:发起了多个 TCP 连接,其中一个连接已经使用完,这个已经用完没有回收的连接就可以重用
-
HTTP/2.0 连接池的重用场景:HTTP/2.0 可以实现多路复用,即发起一个 TCP 连接过程中,这个连接可以被其他多个 TCP 连接一起使用
3、
val interceptors: List<Interceptor>
自定义拦截器。OkHttp 支持自定义拦截器,同时也内置了 HTTP 请求所需的拦截器。使用方式如下:
new OkHttpClient.Builder()
.addInterceptor(new MyInterceptor1())
.addIntereptor(new MyInterceptor2());
需要注意的是,
拦截器是以列表
List
的方式存储,所以也就有前后顺序关系
,自定义的拦截器会在内置拦截器之前执行,自定义拦截器时也要注意
addInterceptor()
的添加顺序
4、
val networkInterceptors: List<Interceptor>
网络拦截器。同样也是自定义拦截器,但一般开发用得比较少,主要是用于添加网络监听,比如 Facebook 的开源框架
Steho
就是使用网络拦截器添加。使用方式如下:
new OkHttpClient.Builder()
.addNetworkInterceptor(new MyNetworkInterceptor());
5、
val eventListenerFactory: EventListener.Factory
记录网络处理的事件回调监听器,比如建立连接成功、网络连接成功监听等。
6、
val retryOnConnectionFailure: Boolean
请求失败、连接失败的时候是否尝试重试。客户端错误的不算失败(比如404等),该属性默认为
true
。
7、
val authenticator: Authenticator
自动认证修正验证器。比如 token 失效的时候返回 401,在这里重新获取刷新 token:
new OkHttpClient.Builder()
.authenticator(new Authenticator() {
@Override
@Nullable
public Request authenticator(@Nullable Route route, @NotNull Response response) {
// 网络请求后验证失败会进来这里,可以在这里重新请求发送处理
// 代码仅用于举例
return response.request.newBuilder().addHeader("token", "token1").build();
}
})
8、
val followRedirects: Boolean
是否跟随重定向。比如请求网页返回了301或其他返回码需要一次重定向,是直接将重定向后的结果返回给客户端,还是重定向时作为 Response 参数先返回给客户端。默认是
true
,直接返回重定向结果给客户端。
9、
val followSslRedirects: Boolean
在
followRedirects = true
的前提下,当重定向的时候发生了协议切换(请求时发送的是 HTTP,然后要求你是 HTTPS 做重定向,或请求发送 HTTPS 要求 HTTP),是否还跟随重定向。默认是
true
。
10、
val cookieJar: CookieJar
cookie 是小饼干的意思,cookieJar 是装满小饼干的盒子,也可以简单理解为存储 cookie 的罐子。
在 HTTP 中 cookie 是服务器通过响应报文中添加 set-cookie 字段传回给客户端的,用来在客户端下一次请求时带上 cookie 让服务器认知。
cookieJar 其实就是客户端可能会访问多个服务器,是各个服务器返回给客户端存储的 cookie。默认情况下不存储任何服务器返回的 cookie。
11、
val cache: Cache?
OkHttp 默认提供给上层使用的网络缓存,会将网络缓存存放在本地,存放网络缓存的路径和存储大小都可以自定义。默认只缓存 GET 请求,后续在讲解到
CacheInterceptor
时会详细再说明。
12、
val dns: Dns
域名转 ip 地址,可能会返回一个 ip 列表,因为一个主机名可以返回对应多个 ip 地址。
HttpDns 除了使用拦截器可以实现外,同样也可以使用这个属性实现,比如阿里云的 HttpDns:
public class MyDns implements Dns {
private HttpDnsService httpDns;
public MyDns(Context context) {
httpDns = HttpDns.getService(context, "account_id");
}
@Override
public List<InetAddress> lookup(String hostname) throws UnknownHostException {
String ip = httpDns.getIpByHostAsync(hostname);
if (ip != null) {
return Arrays.asList(InetAddress.getAllByName(ip));
}
return Dns.SYSTEM.lookup(hostname);
}
}
new OkHttpClient.Builder()
.dns(new MyDns(context));
13、
val proxy: Proxy?
代理,在 HTTP 请求的时候,除了 HTTP 直连直接和对应的服务器请求之外,还可以向另一个服务器发起请求,由这个服务器再转发给实际的服务器,实际接收的服务器将 Response 返回给这个中间服务器,中间服务器再把结果返回给客户端。
使用代理的理由有很多,比如做流量管制,客户端请求都先经过代理服务器,由代理服务器做分流分发等。
proxy 有三种类型: DIRECT 直连、HTTP、SOCKS,默认
proxy = null
。
14、
val proxySelector: ProxySelector
对上面的 proxy 代理的选择处理。
val proxySelector: ProxySelector = when {
// Defer calls to ProxySelector.getDefault() because it can throw a SecurityException
builder.proxy != null -> NullProxySelector
else -> builder.proxySelector ?: ProxySelector.getDefault() ?: NullProxySelector
}
15、
val proxyAuthenticator: Authenticator
如果代理需要授权才能使用,比如需要 token,和
authenticator
一样可以通过
proxyAuthenticator
处理。
16、
val socketFactory: SocketFactory
创建 TCP 端口 Socket,这里的 Socket 是用来建立通信的,建立 HTTP 连接而不使用 HTTPS 的可以使用它。
socketFactory
和
sslSocketFactory
不是并列的关系,用处不同。
17、
val sslSocketFactory: SSLSocketFactory?
也是 Socket,但和 socketFactory 不是并列关系且 Socket 功能也不一样,这里的 Socket 是用来通信时做加密解密的。
如果是建立的 HTTPS 连接,你需要先使用 socketFactory 然后再使用 sslSocketFactory。
18、
val x509TrustManager: X509TrustManager?
证书验证器。建立 HTTPS 时服务器会发过来证书,这个证书需要验证,那么验证这个证书的合法性,就需要对应签名机构和根证书签名机构查这个证书是否在可信列表里面,以及证书能否正确验证,需要对应签名机构的公钥,并且也要对应根证书的签名机构能够验证。
x509 其实就是证书的格式,现在 TLS 连接证书都是 x509 格式,x509TrustManager 就是证书 Manager。
19、
val connectionSpecs: List<ConnectionSpec>
加密连接的规则,和 TLS 或 SSL 相关的参数,比如 HTTPS 通信时要提供给服务端选择使用的加密套件,选择 HTTPS 通信需要使用的加密算法、hash 算法等。
OkHttp 已经提供了几种配置:
-
ConnectionSpecs.RESTRICTED_TLS:严格模式
-
ConnectionSpecs.MODERN_TLS:较宽松模式,默认使用模式
-
ConnectionSpecs.COMPATIBLE_TLS:宽松模式
-
ConnectionSpecs.CLEARTEXT:明文不加密传输 HTTP 报文,简单说就是使用 HTTPS,就是 HTTP
安全性从上往下越来越低,服务器兼容性越来越高(兼容多种 TLS 版本等)。
20、
val protocols: List<Protocol>
要支持的通信协议,比如 HTTP/1.1、HTTP/2.0。
比如协议试探,请求时使用 HTTP/1.1,发送 h2c 试探是否支持 HTTP/2.0,如果支持可以使用升级 HTTP/2.0。但一般情况在自家服务器就不需要做协议试探了,毕竟都是确认的。
21、
val hostnameVerifier: HostnameVerifier
主机名验证。在 HTTPS 加密验证时,除了证书验证合法性外,还需要确认主机名(即是否是我想要访问的那个网站),这是为了能够确认我们所需要的通信对象是正确的。
22、
val certificatePinner: CertificatePinner
certificate的意思是证书,pinner的意思是图钉,把证书用图钉固定,也就是固定证书。比如使用内网自己验证证书,就可以用这个参数,不过使用也比较危险,一般也不使用。
举个例子,设置当访问
api.github.com
时,使用提供的
sha256/xxxxxxx
证书来验证,不用系统验证证书:
CertificatePinner certificatePinner = new CertificatePinner.Builder()
.add("api.github.com", "sha256/xxxxxxxxxxxxx") // 支持填多个证书
.build();
new OkHttpClient.Builder()
.certificatePinner(certificatePinner)
.build();
23、
val certificateChainCleaner: CertificateChainCleaner?
操作 x509TrustManager 做证书验证合法性。
24、TimeoutMillis
-
val callTimeoutMillis: Int
:请求 HTTP 超时时间,默认为0s表示没有超时限制 -
val connectTimeoutMillis: Int
:TCP Socket 连接到主机的连接超时时间,设置为0s表示没有超时限制,默认10s -
val readTimeoutMillis: Int
:TCP Socket 和单次读取 IO 操作比如 Response 的读取超时时间,设置为0s表示没有超时限制,默认10s -
val writeTimeout: Int
:单次 IO 写入超时时间,设置为0s表示没有超时限制,默认10s -
val pingInterval: Int
:WebSocket 和 HTTP/2.0 ping 心跳时长,默认为0s不设置
OkHttp 请求解析
OkHttpClient client = new OkHttpClient();
Request request = new Request.Builder()
.url("http://www.baidu.com")
.build();
Response response = client.newCall(request).execute();
if (response.isSuccessful()) {
.....
}
可以看到最主要的是
client.newCall(request).execute()
传入
Request
构建的请求参数。
Call
是一个提供 HTTP 请求执行相关接口的接口类,具体的实现类是
RealCall
:
OkHttpClient
@Override public Call newCall(Request request) {
return RealCall.newRealCall(this, request, false /* for web socket */);
}
在创建 RealCall 后,实际是调用 RealCall 的
execute()
执行一次同步网络请求:
RealCall
@Override public Response execute() throws IOException {
...
try {
// 将任务添加到同步任务正在执行队列中,没有走线程池
client.dispatcher().executed(this);
// 设置拦截器并请求返回 Response
Response result = getResponseWithInterceptorChain();
if (result == null) throw new IOException("Canceled");
return result;
} catch (IOException e) {
...
} finally {
// 任务执行完从正在执行队列中移除
client.dispatcher().finished(this);
}
}
Dispatcher
synchronized void executed(RealCall call) {
runningSyncCalls.add(call); // 将任务添加到同步任务正在执行队列
}
execute()
最终是通过
Dispatcher
将 Call 添加到正在执行队列请求 HTTP。关于 Dispatcher 在下个节点会详细分析,我们继续看下异步请求。
OkHttpClient client = new OkHttpClient();
Request request = new Request.Builder()
.url("http://www.baidu.com")
.build();
client.newCall(request).enqueue(new Callback() {
@Override
public void onFailure(Call call, IOException e) {}
@Override
public void onResponse(Call call, Response response) {
if (response.isSuccessful()) {
...
}
}
});
异步请求和同步请求差不多,只是最终通过
enqueue()
发起一次异步网络请求,详细看下
enqueue()
代码:
RealCall
@Override public void enqueue(Callback responseCallback) {
...
// 还是在 Dispatcher 处理将 Call 添加到等待队列中
// AsyncCall 是 RealCall 的内部类
// AsyncCall extends NameRunnable
// NameRunnable implements Runnable
client.dispatcher().enqueue(new AsyncCall(responseCallback));
}
public abstract class NamedRunnable implements Runnable {
...
@Override public final void run() {
...
try {
// AsyncCall 执行 HTTP 异步请求的方法
execute();
} finally {
...
}
}
protected abstract void execute();
}
final class RealCall implements Call {
final class AsyncCall extends NameRunnalbe {
void executeOn(ExecutorService executorService) {
...
boolean success = false;
try {
// 线程池执行 Call,回调 run()
executorService.execute(this);
success = true;
} catch (RejectedExecutionException e) {
...
} finally {
if (!success) {
client.dispatcher().finished(this); // This call is no longer running!
}
}
}
@Override protected void execute() {
...
try {
// 设置拦截器并执行 HTTP 请求返回结果
Response response = getResponseWithInterceptorChain();
...
} catch (IOException e) {
...
} finally {
// 任务执行完从正在执行队列中移除
client.dispatcher().finished(this);
}
}
}
}
Dispatcher
void enqueue(AsyncCall call) {
synchronized (this) {
// 将异步 Call 添加到等待队列中
readyAsyncCalls.add(call);
}
// 执行异步任务
promoteAndExecute();
}
异步请求和同步请求不太一样,创建的是
AsyncCall
,先添加到等待队列,后续就是执行任务。
同步请求和异步请求的流程最终都会走到 Dispatcher。Dispatcher 是什么?经过 Dispatcher 是要做什么事情?接下来我们详细分析。
Dispatcher 任务分发器
Dispatcher 是任务分发器,它的业务目的是在于执行具体网络请求之前控制客户端的请求节奏。
网上很多文章对于 Dispatcher 都没有做一个详细的说明,只是简单的说明了 Dispatcher 维护了三个队列:
// 异步任务等待执行队列
private final Deque<AsyncCall> readyAsyncCalls = new ArrayDeque<>();
// 异步任务正在执行队列
private final Deque<AsyncCall> runningAsyncCalls = new ArrayDeque<>();
// 同步任务正在执行队列
private final Deque<RealCall> runningSyncCalls = new ArrayDeque<>();
OkHttp 为什么要维护三个队列?有什么作用?Java 提供的线程池有什么局限性?实际上仔细探究会发现里面大有学问,特别是涉及到线程池的设计。
我们可以思考一个问题:如果是由你设计 Dispatcher,网络请求是需要在子线程执行,线程使用的
线程池
,线程池需要提供一些主要参数:核心线程池数量、等待队列、最大线程数量、线程存活时间;针对网络业务场景,你打算怎么设置这些参数?
如果你有考虑这个问题,你会发现
核心线程数不好提供一个具体的数值,因为网络环境是波动的,网络请求使用的峰值不确定;等待队列长度也不好提供具体的数值,因为网络不接受阻塞性问题的出现,网络请求强调的及时性
。
基于以上两个问题,OkHttp 考虑了 Java 提供的线程池不能支持网络业务,对线程池做了设计:
-
不提供核心线程为 0
-
等待队列提供的是无界队列(相当于队列长度是 0,不给等待队列),并且自己来做等待队列,自己维护三个队列:同步任务正在执行队列 runningSyncCalls、异步任务等待执行队列 readyAsyncCalls、异步任务正在执行队列 runningAsyncCalls
-
请求数量也是自己控制 maxRequests 为 64
// 最大请求数量,相当于最多有 64 个线程同时正在执行
private int maxRequests = 64;
// 客户端请求服务端同一个链接最多的数量,比如客户端跑循环同时请求同一个链接
// 如果没有做限制会对服务器有较大的损耗
// 相当于这里做了截流,同一个 host 请求最多只能有 5 个,剩余的请求等待
private int maxRequestsPerHost = 5;
public synchronized ExecutorService executorService() {
if (executorService == null) {
// 核心线程为 0,队列给的无界队列长度为 0,最大线程数不限制、创建的线程没任务时存活 60s
executorService = new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>(), Util.threadFactory("OkHttp Dispatcher", false));
}
return executorService;
}
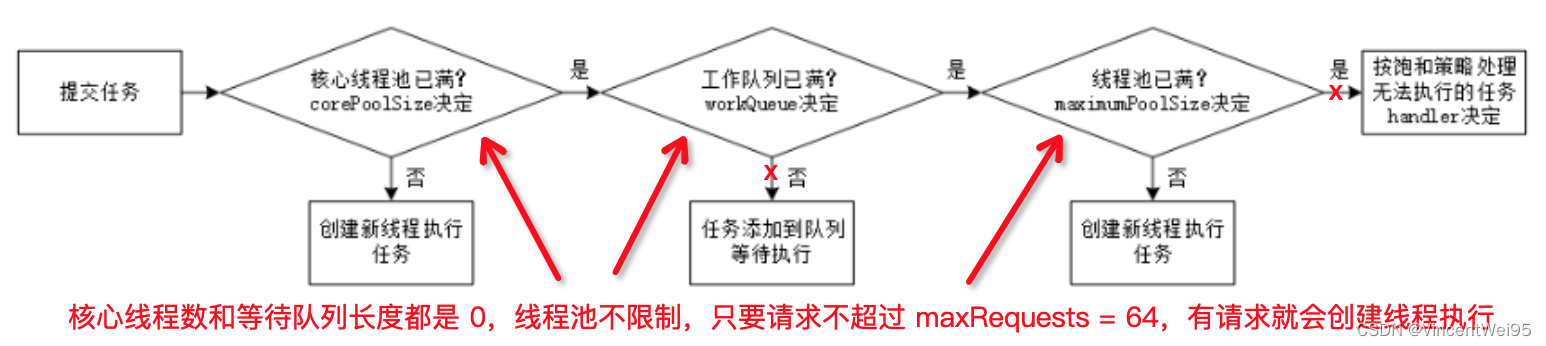
Dispatcher 线程池这样设计的好处是,可以根据时间段的不同动态的调整线程资源,维护 64 个线程同时运行,没有网络请求时空闲的线程也会在 60s 内释放,资源慢慢释放回落不会一直持有占用资源。这样的线程池设计能在不同时间段的网络峰值动态调整线程使用,这才是 Dispatcher 设计的核心目的
。
有了上面支持网络请求的线程池支撑,剩下的就是业务功能的完善:
public final class Dispatcher {
private int maxRequests = 64;
private int maxRequestsPerHost = 5;
private @Nullable ExecutorService executorService;
private final Deque<AsyncCall> readyAsyncCalls = new ArrayDeque<>();
private final Deque<AsyncCall> runningAsyncCalls = new ArrayDeque<>();
private final Deque<RealCall> runningSyncCalls = new ArrayDeque<>();
void enqueue(AsyncCall call) {
synchronized (this) {
readyAsyncCalls.add(call); // 异步任务添加到等待队列中
}
promoteAndExecute();
}
synchronized void executed(RealCall call) {
runningSyncCalls.add(call); // 同步任务直接添加到执行队列中,没有走线程池
}
// 只处理异步任务
private boolean promoteAndExecute() {
List<AsyncCall> executableCalls = new ArrayList<>();
boolean isRunning;
synchronized (this) {
for (Iterator<AsyncCall> i = readyAsyncCalls.iterator(); i.hasNext(); ) {
AsyncCall asyncCall = i.next();
if (runningAsyncCalls.size() >= maxRequests) break; // Max capacity.
if (runningCallsForHost(asyncCall) >= maxRequestsPerHost) continue; // Host max capacity.
i.remove(); // 将要执行的请求从等待队列移除
executableCalls.add(asyncCall); // 将要执行的请求添加到执行列表
runningAsyncCalls.add(asyncCall); // 将要执行的请求添加到执行队列
}
isRunning = runningCallsCount() > 0;
}
for (int i = 0, size = executableCalls.size(); i < size; i++) {
AsyncCall asyncCall = executableCalls.get(i);
// 最终是调用 Call 的 execute() 在线程池中执行 HTTP 请求
asyncCall.executeOn(executorService());
}
return isRunning;
}
// 异步或同步的 Call 请求结束后,会调用 finished()
// 将执行完成的 Call 从执行队列中移除,让下一个等待请求的 Call 添加到执行队列
void finished(AsyncCall call) {
finished(runningAsyncCalls, call);
}
void finished(RealCall call) {
finished(runningSyncCalls, call);
}
private <T> void finished(Deque<T> calls, T call) {
Runnable idleCallback;
synchronized (this) {
// 将执行完成的请求从执行队列移除
if (!calls.remove(call)) throw new AssertionError("Call wasn't in-flight!");
idleCallback = this.idleCallback;
}
// 如果有异步任务在等待队列,从等待队列拿请求继续执行在队列等待的异步任务
boolean isRunning = promoteAndExecute();
if (!isRunning && idleCallback != null) {
idleCallback.run();
}
}
}
拦截器处理流程
通过上面的分析,无论是同步请求还是异步请求,最终都是会调用方法
getResponseWithInterceptorChain()
设置拦截器并请求 HTTP 返回请求结果 Response。
@Throws(IOException::class)
internal fun getResponseWithInterceptorChain(): Response {
val interceptors = mutableListOf<Interceptor>()
interceptors += client.interceptors
interceptors += RetryAndFollowUpInterceptor(client)
interceptors += BridgeInterceptor(client.cookieJar)
interceptors += CacheInterceptor(client.cache)
interceptors += ConnectInterceptor
if (!forWebSocket) {
interceptors += client.networkInterceptors
}
interceptors += CallServerInterceptor(forWebSocket)
val chain = RealInterceptorChain(
call = this,
interceptors = interceptors,
index = 0,
exchange = null,
request = originalRequest,
connectTimeoutMillis = client.connectTimeoutMillis,
readTimeoutMillis = client.readTimeoutMillis,
writeTimeoutMillis = client.writeTimeoutMillis
)
val calledNoMoreExchanges = false
try {
val response = chain.proceed(originalRequest)
if (isCanceled()) {
response.closeQuietly()
throw IOException("Canceled")
}
return response
} catch (e: IOException) {
calledNoMoreExchanges = true
throw noMoreExchanges(e) as Throwable
} finally {
if (!calledNoMoreExchanges) {
noMoreExchanges(null)
}
}
}
在请求前会设置前面的自定义拦截器以及 HTTP 网络请求相关的拦截器,最终通过
RealInterceptorChain.proceed()
执行请求。也就是说,HTTP 网络请求都在拦截器中实现。
每个拦截器都遵循一定的规则:
@Override public Response intercept(Chain chain) throws IOException {
// 对请求的前置处理
....
// 以 proceed() 作为分界,每个拦截器的处理都可以分为前置、中置、后置处理(最后一个是没有后置)
// proceed() 就是中置处理,将当前 intercept 处理的请求递交给下一个 interceptor
// proceed() 的作用就是拿到下一个的 interceptor 去调用它的 intercept()
response = chain.proceed(request, streamAllocation, null, null);
// 后置处理
....
}
上面的处理流程可以用一张图来说明:

每一个拦截器调用了
proceed()
后就把前置处理的结果递交给下一个拦截器处理,每个拦截器只关心自己做的事情以及跟下一个拦截器交互,直到拦截器全部处理完成,将结果重新传递回来。拦截器的设计也是一个典型的责任链设计模式。
举个餐馆送餐的例子方便理解:
A interceptor 是餐馆老板,B interceptor 是餐馆员工,C interceptor 是顾客。
-
顾客在餐馆下了一个订单,餐馆老板知道有订单后就按订单做菜
A interceptor 前置处理,做菜
-
老板炒完菜后就把菜给餐馆员工
A interceptor 中置处理,将菜给餐馆员工 B interceptor
-
餐馆员工配送把菜给顾客
C interceptor 前置处理,配送;中置处理,把菜给顾客 C interceptor
-
顾客拿钱给了餐馆员工
C interceptor 前置处理,拿菜;中置处理,付钱
-
餐馆员工回到餐馆
B interceptor 后置处理,将钱拿回餐馆
-
把钱拿给了餐馆老板
A interceptor 后置处理,收到钱
OkHttp 拦截器
拦截器的业务目的
任何一个框架的设计都是服务于业务的,OkHttp 主要的目的是进行 HTTP 网络请求,那么在一次完整的网络请求业务过程中会包含以下的业务特性:
-
HTTP 有重试、重定向的业务支持
-
需要将数据包装成一组 HTTP 协议数据的格式,请求前需要添加 header 和 body
-
如果请求与上一次请求一致,则不需要进行二次请求,建立缓存机制,重复的请求直接本地返回数据
-
建立一个 TCP 连接的 socket 通讯
-
将数据输出到连接中,并且提取到响应数据后组装成 Response 数据对象返回给用户使用
以上的业务需求 OkHttp 将其拆成了不同的拦截器支持。为了方便理解,这里先把总体流程列出来:
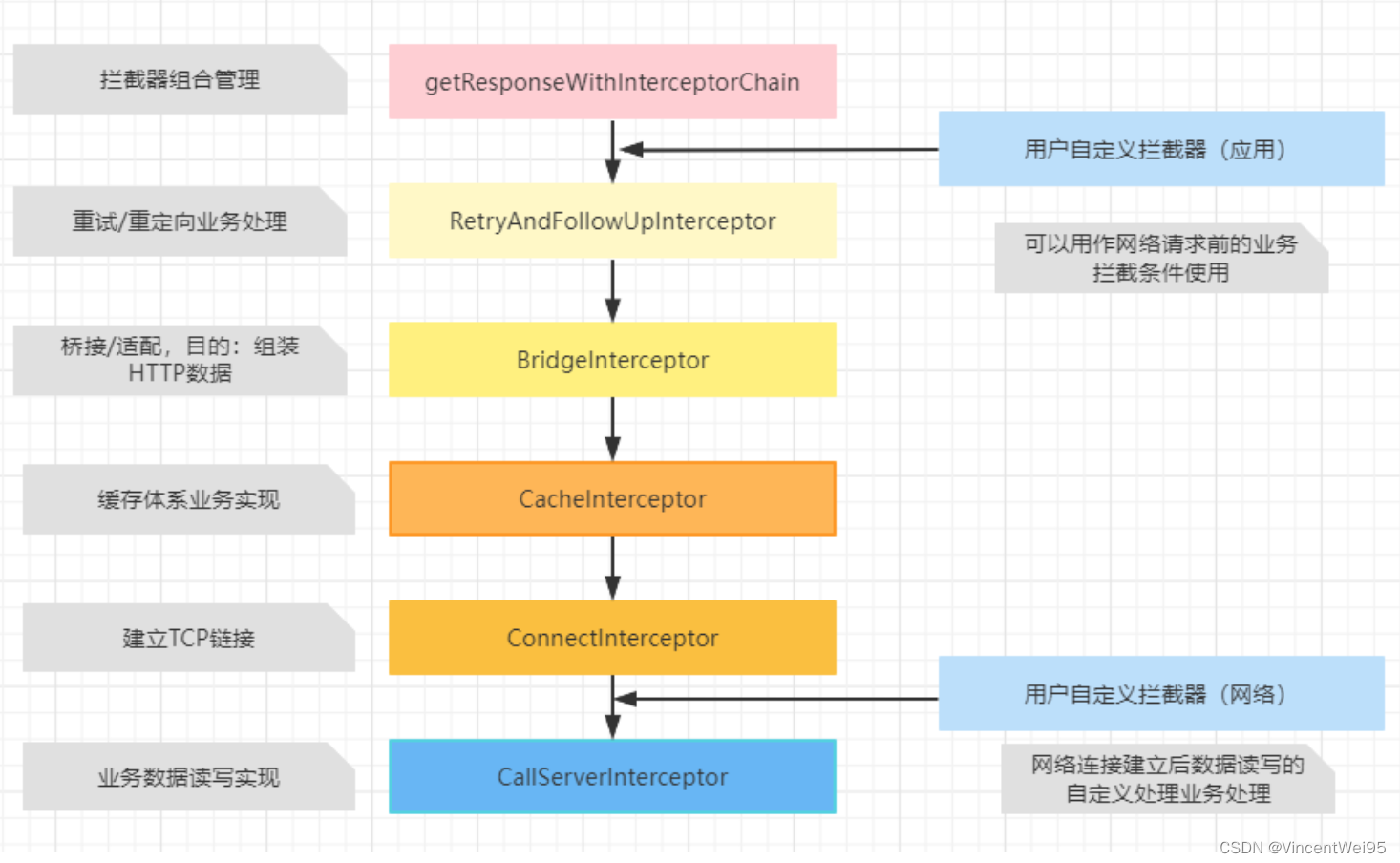
接下来我们对每个拦截器都做一个详细的分析。
RetryAndFollowUpInterceptor
RetryAndFollowUpInterceptor
主要处理请求重试和重定向,
请求重试说的是请求连接失败等,但不包括 4xx 客户端引发的错误
;重定向比如返回 301 时跟随重定向继续发送请求。
RetryAndFollowUpInterceptor 可以拆分成两部分来说明:
1、请求失败,请求重试
override fun intercept(chain: Interceptor.Chain): Response {
...
while (true) {
...
try {
response = realChain.proceed(request)
} catch (e: RouteException) {
// 路由异常情况,正在建立 socket 通信时出现的问题
if (!recover(e.lastConnectException, call, request, requestSendStarted = false)) {
throw e.firstConnectException.withSuppressed(recoveredFailures)
} else {
recoveredFailures += e.firstConnectException
}
newExchangeFinder = false
continue // 重新进入循环重试请求
} catch (e: IOException) {
// 请求发出去了,但是和服务器通信失败(socket 流正在读写数据时断开连接)
if (!recover(e, call, request, requestSendStarted = e !is ConnectionShutdownException)) {
throw e.withSuppressed(recoveredFailures)
} else {
recoveredFailures += e
}
newExchangeFinder = false
continue // 重新进入循环重试请求
}
}
}
// 判断是否能够进行重试,返回 true 表示允许重试
private fun recover(
e: IOException,
call: RealCall,
userRequest: Request,
requestSendStarted: Boolean
): Boolean {
// OkHttpClient 设置了不允许重试,则一旦请求失败不再重试
if (!client.retryOnConnectionFailure) return false
// requestSendStarted 只在 Http2 的 io 异常中为 true
if (requestSendStarted && requestIsOneShot(e, userRequest)) return false
// 判断是不是属于重试的异常
if (!isRecoverable(e, requestSendStarted)) return false
// 没有可以更多可以用来连接的路由路线
if (!call.retryAfterFailure()) return false
return true
}
private fun isRecoverable(e: IOException, requestSendStarted: Boolean): Boolean {
// 出现协议异常,不能重试
if (e is ProtocolException) {
return false
}
// socket 超时异常,直接判定可以重试
if (e is InterruptedIOException) {
return e is SocketTimeoutException && !requestSendStarted
}
// SSL 握手异常,证书出现问题不能重试
if (e is SSLHandshakeException) {
if (e.cause is CertificateException) {
return false
}
}
// SSL 握手未授权异常,不能重试
if (e is SSLPeerUnverifiedException) {
return false
}
return true
}
简单总结下重试逻辑:
-
如果是协议异常,直接判定不能重试(你的请求或者服务器的响应本身就存在问题,没有按照 HTTP 协议来定义数据,再重试也没用)
-
超时异常,可能由于网络波动造成了 socket 管道超时,可以重试
-
经过了异常的判定之后,如果仍然允许进行重试,就会再检查当前有没有可用路由路线进行连接。比如 DNS 对域名解析后可能会返回多个 ip,在一个 ip 失败后,尝试用另一个 ip 重试
2、请求重定向
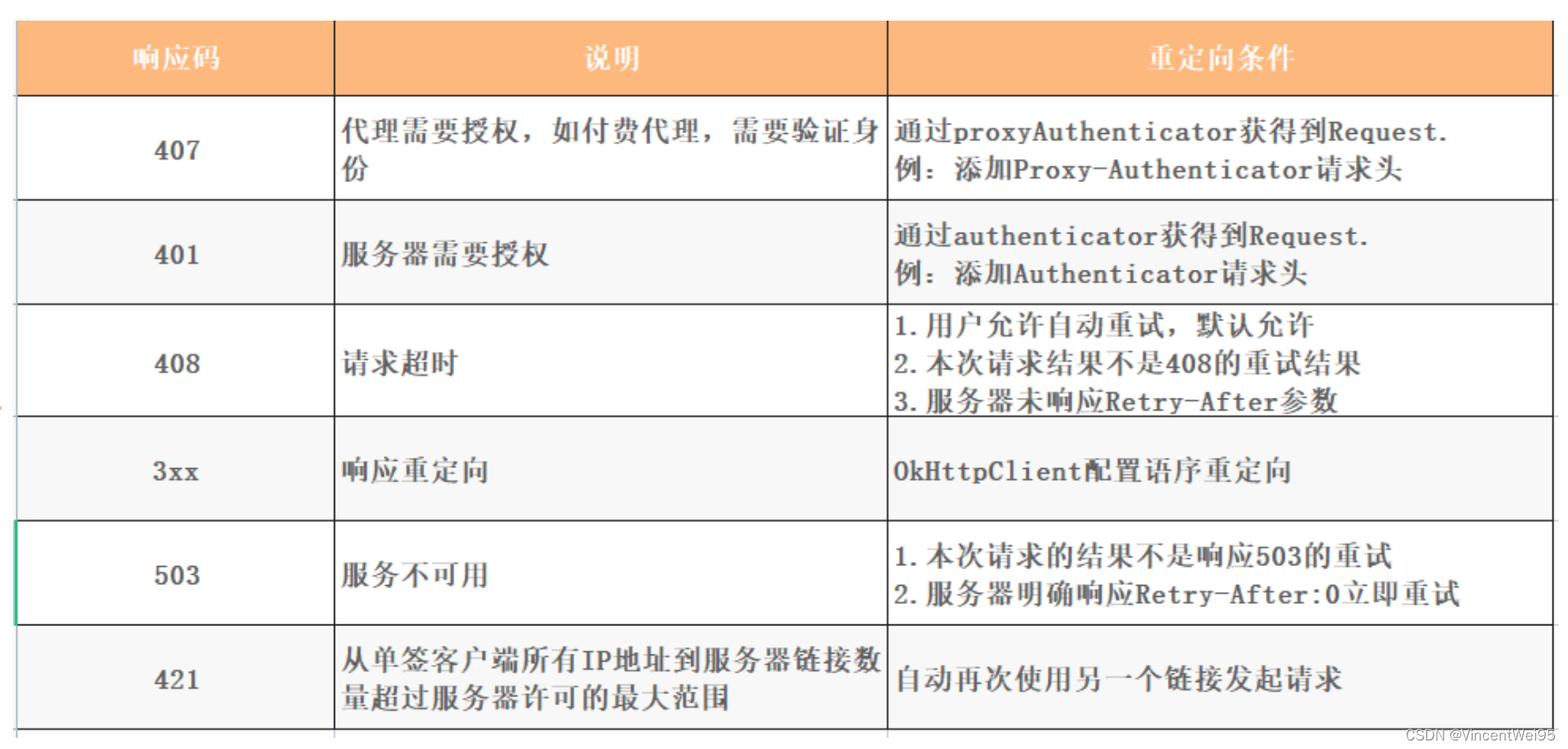
如果请求结束后没有发生异常并不代表当前获得的响应就是最终需要交给用户的,还需要进一步判断是否需要重定向的判断。
根据 HTTP 协议的约定,在响应码为 3xx 时为重定向,重定向实际上是一组服务器与客户端之间的约定业务。

重定向的判断位于 followUpRequest():
override fun intercept(chain: Interceptor.Chain): Response {
...
while (true) {
...
try {
response = realChain.proceed(request)
} catch (e: RouteException) {
...
} catch (e: IOException) {
...
}
...
// 通过返回的 Response 判断是哪种重定向
val followUp = followUpRequest(response, exchange)
// 如果没有重定向,说明请求成功可以返回response
if (followUp == null) {
...
return response;
}
// 同理,请求成功可以返回response
val followUpBody = followUp.body
if (followUpBody != null && followUpBody.isOneShot()) {
...
return response
}
// 拿到重定向需要构建的请求,重新请求做重定向操作
request = followUp
}
}
相关的重定向响应码如下表:
RetryAndFollowUpInterceptor 流程如下:
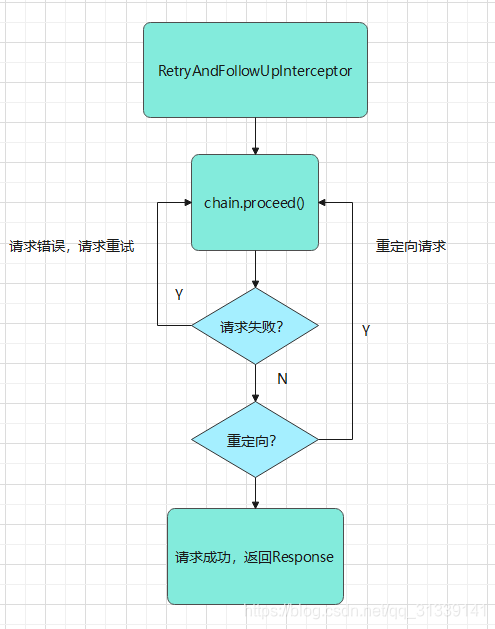
简单总结下总体流程:
-
中置处理
chain.proceed()
发送请求 -
如果请求失败,并且是请求错误(RouteException 或 IOException),尝试恢复重连
-
如果不是请求失败,而是重定向操作,根据返回的 Response 判断对应的重定向重新构建请求进行重定向请求,
重定向最大的次数为 20 次
-
直到既不需要重试又不需要重定向,返回最终的 Response
RetryAndFollowUpInterceptor 除了它的工作流程外,还有一个点需要留意一下:
override fun intercept(chain: Interceptor.Chain): Response {
// 传入 newExchangeFinder 标志
call.enterNetworkInterceptorExchange(request, newExchangeFinder)
...
try {
response = realChain.proceed(request)
newExchangeFinder = true
} catch (e: RouteException) {
...
newExchangeFinder = false // 连接重试
continue
} catch (e: IOException) {
...
newExchangeFinder = false // 连接重试
continue
}
}
...
}
在处理连接重试时,
newExchangeFinder
重置为 false,它是什么?有什么用?
RealCall
fun enterNetworkInterceptorExchange(request: Request, newExchangeFinder: Boolean) {
...
// newExchangeFinder = true,重新获取新的连接
if (newExchangeFinder) {
this.exchangeFinder = ExchangeFinder(
connectionPool,
createAddress(request.url),
this,
eventListener
)
}
}
ExchangeFinder 是 ConnectInterceptor 处理连接时所必要的,这里
newExchangeFinder = false
的意思是,如果是连接重试,就不要重新再创建新的 ExchangeFinder,否则在 ConnectInterceptor 获取连接的时候都要重新去获取新的连接,而不是复用之前查找连接失败重试前留下的处理。
BridgeInterceptor
BridgeInterceptor
主要是添加必要的请求头信息、gzip 处理等。
class BridgeInterceptor(private val cookieJar: CookieJar) : Interceptor {
@Throws(IOException::class)
override fun intercept(chain: Interceptor.Chain): Response {
val userRequest = chain.request()
val requestBuilder = userRequest.newBuilder()
// 添加必要的请求头信息
val body = userRequest.body
if (body != null) {
val contentType = body.contentType()
if (contentType != null) {
requestBuilder.header("Content-Type", contentType.toString())
}
val contentLength = body.contentLength()
if (contentLength != -1L) {
requestBuilder.header("Content-Length", contentLength.toString())
requestBuilder.removeHeader("Transfer-Encoding")
} else {
requestBuilder.header("Transfer-Encoding", "chunked")
requestBuilder.removeHeader("Content-Length")
}
}
if (userRequest.header("Host") == null) {
requestBuilder.header("Host", userRequest.url.toHostHeader())
}
if (userRequest.header("Connection") == null) {
requestBuilder.header("Connection", "Keep-Alive")
}
// 对请求做Gzip压缩,后续中置处理返回Response帮我们解压
var transparentGzip = false
if (userRequest.header("Accept-Encoding") == null && userRequest.header("Range") == null) {
transparentGzip = true
requestBuilder.header("Accept-Encoding", "gzip")
}
val cookies = cookieJar.loadForRequest(userRequest.url)
if (cookies.isNotEmpty()) {
requestBuilder.header("Cookie", cookieHeader(cookies))
}
if (userRequest.header("User-Agent") == null) {
requestBuilder.header("User-Agent", userAgent)
}
// 中置处理,发送的是添加了必要请求头信息的新构建的Request
val networkResponse = chain.proceed(requestBuilder.build())
cookieJar.receiveHeaders(userRequest.url, networkResponse.headers)
val responseBuilder = networkResponse.newBuilder()
.request(userRequest)
// 如果是Gzip压缩,解压Gzip
if (transparentGzip &&
"gzip".equals(networkResponse.header("Content-Encoding"), ignoreCase = true) &&
networkResponse.promisesBody()) {
val responseBody = networkResponse.body
if (responseBody != null) {
val gzipSource = GzipSource(responseBody.source())
val strippedHeaders = networkResponse.headers.newBuilder()
.removeAll("Content-Encoding")
.removeAll("Content-Length")
.build()
responseBuilder.headers(strippedHeaders)
val contentType = networkResponse.header("Content-Type")
responseBuilder.body(RealResponseBody(contentType, -1L, gzipSource.buffer()))
}
}
return responseBuilder.build()
}
}
-
为请求添加必要的 Headers,比如 Content-Type、Content-Length、Host、Connection、gzip
-
因为默认设置了 gzip,所以中置处理返回 Response 后会帮我们处理 gzip 解压
可以发现,BridgeInterceptor 在添加必要 Header 前做了判空处理后再添加的,这样是因为如果后续连接出错需要重连或重定向,拦截器按顺序又来到 BridgeInterceptor,就不会重复添加相同的 Headers。
CacheInterceptor
CacheInterceptor
主要是检查网络缓存以及处理存储网络缓存,相比起其他拦截器,CacheInterceptor 是相对比较独立的一个拦截器。
override fun intercept(chain: Interceptor.Chain): Response {
// 这里会根据 Request 的 Header 处理 Cache 相关的逻辑
// 比如 Date、Expires、Last-Modified、ETag、Age 和 If-None-Match、If-Modified-Since
val strategy = CacheStrategy.Factory(now, chain.request(), cacheCandidate).compute()
val networkRequest = strategy.networkRequest
val cacheResponse = strategy.cacheResponse
// 被禁止使用网络且没有缓存,返回失败
if (networkRequest == null && cacheResponse == null) {
...
}
// 不使用网络,返回缓存
if (networkRequest == null) {
...
}
try {
// 中置处理
networkResponse = chain.proceed(networkRequest)
}
...
if (cache != null) {
...
// 存储网络请求的缓存
val cacheRequest = cache.put(response)
return cacheWritingResponse(cacheRequest, response)
}
...
}
总体流程如下图:
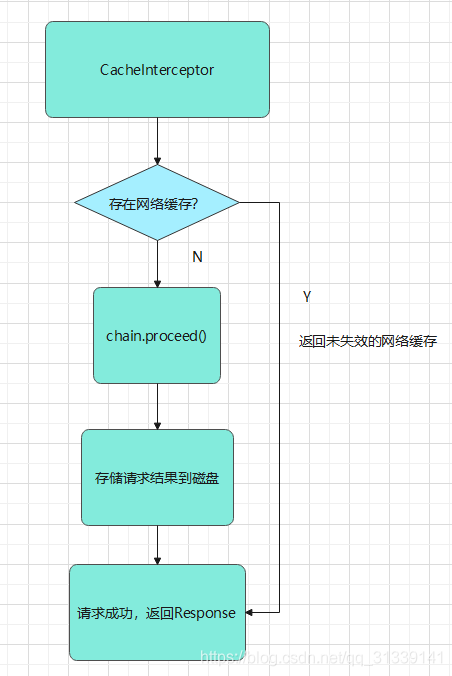
缓存根据处理方式可以分为两种:
-
强缓存:如果响应头中包含 Expires 或 Cache-Control 两个字端来控制,则表示资源的缓存时间,不会将这一次请求发给服务端,直接用本地缓存响应给用户(
客户端强制使用缓存
) -
协商缓存:会将请求发送至服务器,服务器根据 HTTP 头信息中的 Last-Modify/if-Modify-Since 或者是 ETag/if-None-Match 来判断是否命中协商缓存,
如果命中则 HTTP 返回 304 表示本地响应没有 body 内容
(
遵循 HTTP 协议与服务器协商是否缓存
)
关于协商缓存具体可以阅读文章
HTTP 缓存详解
具体了解,这里不再赘述。
CacheInterceptor 通过 CacheStrategy 策略判断使用缓存或发起网络请求,此对象中的 networkRequest 和 cacheResponse 分别代表发起请求和直接响应缓存:
| NetworkRequest | CacheResponse | 说明 |
|---|---|---|
| null | not null | 直接使用缓存 |
| not null | null | 向服务器发起请求 |
| null | null | 要求使用缓存,但是没有缓存,OkHttp 直接返回 504 提示错误 |
| not null | not null | 发起请求,若得到响应为 304(缓存未失效),则更新缓存响应并返回 |
缓存处理具体流程如下:
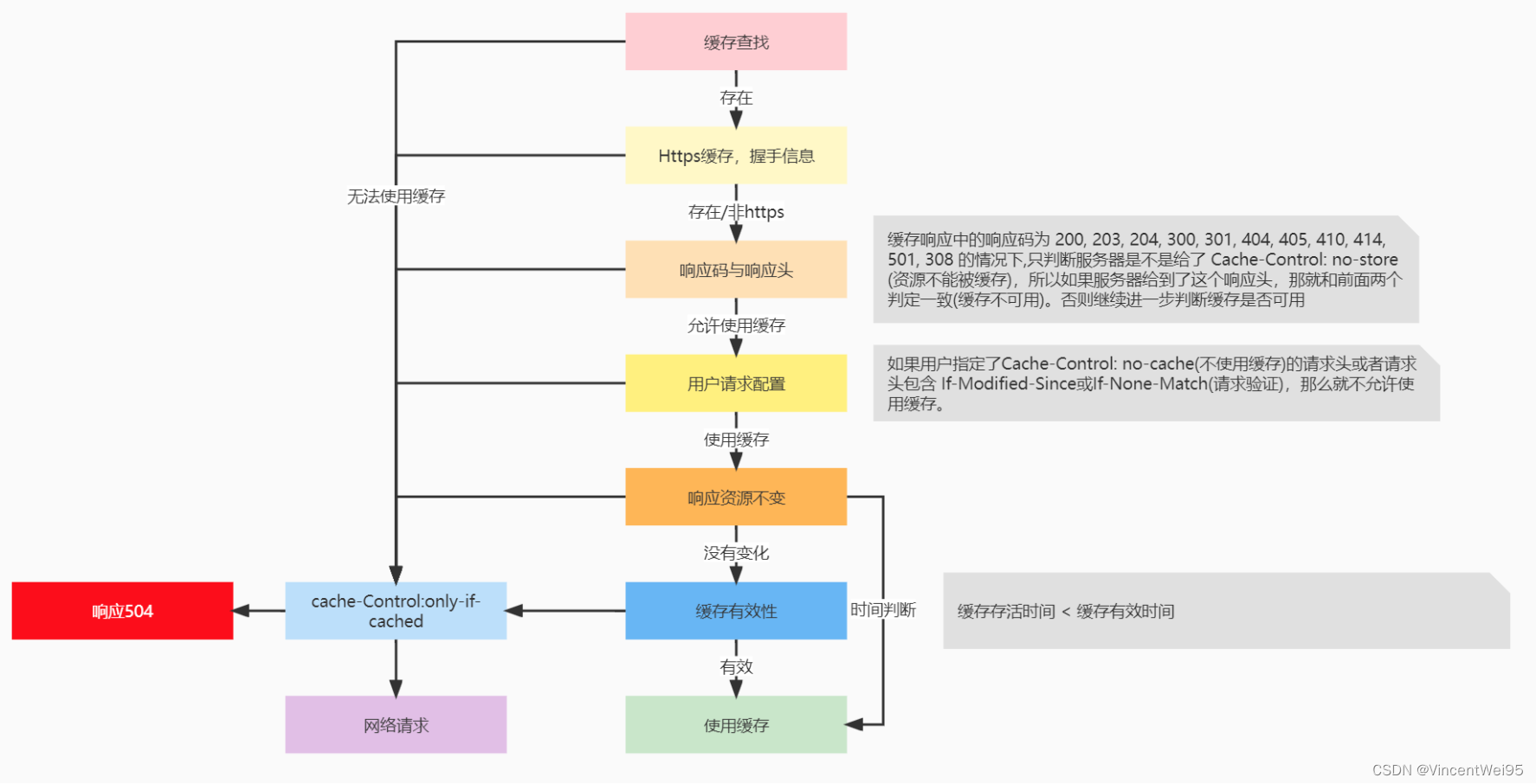
-
如果从缓存获取的 Response 是 null,那就需要使用网络请求获取响应
-
如果是 https 请求,但又丢失了握手信息,那也不能使用缓存,需要进行网络请求
-
如果判断响应码不能缓存且响应头有 no-store 标识,那就需要进行网络请求
-
如果请求头有 no-cache 标识或有 If-Modified-Since/If-None-Match,那么需要进行网络请求
-
如果响应头没有 no-cache 标识,且缓存时间没有过期,那么可以使用缓存,不需要进行网络请求
-
如果缓存过期了,判断响应头是否设置 ETag/Last-Modified/Date,没有就直接使用网络请求,否则需要考虑服务器返回 304
还有需要注意的是,
OkHttp 只缓存 GET 请求
,这在缓存的源码中注释有说明原因:
Cache.java
@Nullable CacheRequest put(Response response) {
String requestMethod = response.request().method();
...
if (!requestMethod.equals("GET")) {
// Don't cache non-GET responses. We're technically allowed to cache
// HEAD requests and some POST requests, but the complexity of doing
// so is high and the benefit is low.
return null;
}
...
}
ConnectInterceptor
ConnectInterceptor
的作用是找到一个可用的连接。
override fun intercept(chain: Interceptor.Chain): Response {
// 前置处理
val realChain = chain as RealInterceptorChain
val exchange = realChain.call.initExchange(chain)
val connectedChain = realChain.copy(exchange = exchange)
// 中置处理
return connectedChain.proceed(realChain.request)
}
看这个拦截器源码好像代码很少,其实反而是最重要而且是最难分析的,我们来具体分析一下。首先是
realChain.call.initExchange(chain)
:
RealCall
internal fun initExchange(chain: RealInterceptorChain): Exchange {
...
// codec,里面会有健康可用的连接以及编码解码器
val codec = exchangeFinder!!.find(client, chain)
// Exchange 其实是一个管理员的身份,实际和服务器沟通的是 codec
val result = Exchange(this, eventListener, exchangeFinder!!, codec)
...
}
在分析上面的代码前首先要搞明白什么是
exchange
?什么是
codec
?
-
exchange :我们一次数据请求,一次数据交换,就是一次 exchange,那么 exchangeFinder 就是寻找一次数据交换,什么是寻找一次数据交换?其实就是一个可用的 TCP 连接以及连接相关所需要的各种参数内容,比如使用的什么编码格式去交互 HTTP/1.1 或 HTTP/2.0
-
codec:
coder & decoder
编码解码器,我们去发请求报文和接收响应报文时,我们需要按照格式去读和写,是要按照 HTTP/1.1 的格式还是按照 HTTP/2.0 的格式去读和写,这种不同的格式就是不同的 codec
根据上面的说明,
val codec = exchangeFinder!!.find(client, chain)
这行代码返回的 codec 的意思就是
通过你的请求格式是 HTTP/1.1 或 HTTP/2.0 返回对应的 codec 编码解码器
。而 ExchangeFinder 这个类其实在 RetryAndFollowUpInterceptor 的前置处理就已经出现:
RetryAndFollowUpInterceptor
override fun intercept(chain: Interceptor.Chain): Response {
...
while (true) {
call.enterNetworkInterceptorExchange(request, newExchangeFinder)
...
}
}
RealCall
fun enterNetworkInterceptorExchange(request: Request, newExchangeFinder: Boolean) {
...
if (newExchangeFinder) {
this.exchangeFinder = ExchangeFinder(
connectionPool,
createAddress(request.url),
this,
eventListener
)
}
}
继续看
exchangeFinder!!.find(chain)
这句代码:
ExchangeFinder
fun find(
client: OkHttpClient,
chain: RealInterceptorChain
): ExchangeCodec {
try {
// 找到一个健康可用的连接
val resultConnection = findHealthyConnection(...)
// 使用连接获取编码解码器
// 确切说就是确定编码规则,是使用的 HTTP/1.1 去写和读还是使用 HTTP/2.0 去写和读
return resultConnection.newCodec(client, chain)
}
...
}
首先是去获取一个连接,然后根据连接去获取编码解码器,其实就是确认编码规则:
@Throws(SocketException::class)
internal fun newCodec(client: OkHttpClient, chain: RealInterceptorChain): ExchangeCodec {
...
// 如果是 HTTP/2.0 的连接,就返回 HTTP/2.0 的编码解码器
return if (http2Connection != null) {
Http2ExchangeCodec(client, this, chain, http2Connection)
}
// 否则就是返回 HTTP/1.1 的编码解码器
else {
...
Http1ExchangeCodec(client, this, source, sink)
}
}
那什么是编码解码器?我们可以进去
Http1ExchangeCodec
通过一个方法就可以了解:
Http1ExchangeCodec
override fun writeRequestHeaders(request: Request) {
val requestLine = RequestLine.get(request, connection.route().proxy.type())
writeRequest(request.headers, requestLine)
}
fun writeRequest(headers: Headers, requestLine: String) {
check(state == STATE_IDLE) { "state: $state" }
// 第一行请求行写完,换行
sink.writeUtf8(requestLine).writeUtf8("\r\n")
// 写 Headers
for (i in 0 until headers.size) {
sink.writeUtf8(headers.name(i))
.writeUtf8(": ")
.writeUtf8(headers.value(i))
.writeUtf8("\r\n")
}
// Headers 写完,换行
sink.writeUtf8("\r\n")
state = STATE_OPEN_REQUEST_BODY // body
}
其实对应的就是我们的 HTTP 请求报文:
// /r/n就是换行
GET path HTTP/1.1 -> sink.writeUtf8(requestLine).writeUtf8("\r\n")
// Headers -> for (i in 0 until headers.size) {} sink.writeUtf8("\r\n")
Host: test.com -> sink.writeUtf8(headers.name(i)).writeUtf8(": ").writeUtf8(headers.value(i)).writeUtf8("\r\n")
body -> state = STATE_OPEN_REQUEST_BODY
那 HTTP/2.0 的编码解码器有什么不同?也顺便看下代码:
Http2ExchangeCodec
override fun writeRequestHeaders(request: Request) {
if (stream != null) return
val hasRequestBody = request.body != null
val requestHeaders = http2HeadersList(request)
stream = http2Connection.newStream(requestHeaders, hasRequestBody)
...
}
和 HTTP/1.1 不同,HTTP/1.1 是一个请求一个响应这样的方式,而到了 HTTP/2.0 因为有多路复用,使用了
Stream
这种方式更加灵活支持请求响应,每个 Stream 可以有多个请求然后有多个响应。
因为 HTTP/1.1 和 HTTP/2.0 的格式不一样,所以也就需要不同的编码解码器,但本质上它们还是需要发送报文。
继续看是怎么去获取一个连接
findHealthyConnection()
,这是最核心复杂的一个方法:
ExchangeFinder
@Throws(IOException::class)
private fun findHealthyConnection(
...
): RealConnection {
while (true) {
// 获取一个连接
val candidate = findConnection(...)
// 确认这个连接是否是正常的
if (!candidate.isHealthy(doExtensiveHealthChecks)) {
candidate.noNewExchanges()
continue // 如果不正常,就进入循环重新拿一次
}
return candidate
}
拿到连接后会判断这个连接是否健康
candidate.isHealthy()
:
fun isHealthy(doExtensiveChecks: Boolean): Boolean {
val nowNs = System.nanoTime()
val rawSocket = this.rawSocket!!
val socket = this.socket!!
val source = this.source!!
if (rawSocket.isClosed || socket.isClosed || socket.isInputShutdown ||
socket.isOutputShutdown) {
return false
}
// 如果是 HTTP/2.0 的连接,还需要判断 ping pong 心跳是否正常
val http2Connection = this.http2Connection
if (http2Connection != null) {
return http2Connection.isHealthy(nowNs)
}
val idleDurationNs = nowNs - idleAtNs
if (idleDurationNs >= IDLE_CONNECTION_HEALTHY_NS && doExtensiveChecks) {
return socket.isHealthy(source) // 判断 Socket 是否关闭了
}
return true
}
Http2Connection
@Synchronized
fun isHealthy(nowNs: Long): Boolean {
if (isShutdown) return false
// A degraded pong is overdue.
if (degradedPongsReceived < degradedPingsSent
&& nowNs >= degradedPongDeadlineNs) return false
return true
}
简单总结下,ConnectionInterceptor 的总流程如下:
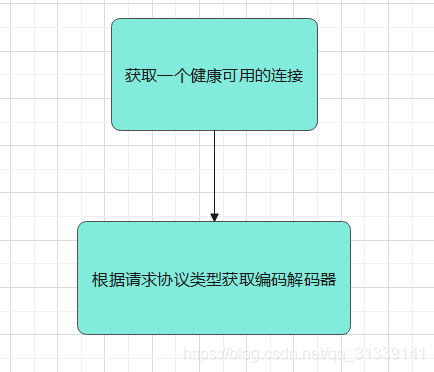
findConnection() 获取一个可用的连接
因为
findConnection()
这个方法比较复杂,拆分成几个部分来进行分析。
findConnection() 第一次进入获取连接
private fun findConnection(
...
): RealConnection {
...
synchronized(connectionPool) {
...
// 首次进入该方法时 result = null,先进入该方法
if (result == null) {
...
// 尝试从连接池获取一个连接,这里只能拿到 HTTP/1.1 方式的连接,后面讲到 routes 时会说明
if (connectionPool.callAcquirePooledConnection(address, call, null, false)) {
...
result = call.connection // 拿到一个有效的连接,后续就直接返回这个 result
}
...
}
}
...
// 已经拿到有效的连接,返回连接
if (result != null) {
return result!!
}
...
}
RealConnectionPool
fun callAcquirePooledConnection(
...
): Boolean {
...
for (connection in connections) {
// multiplex 就是多路复用,有多路复用的其实也就 HTTP/2.0
// 第一次查找连接调用该方法时,requireMultiplexed = false,所以先不用看
if (requireMultiplexed && !connection.isMultiplexed) continue
// 判断连接是否是有效的,不可用就循环拿另一个
if (!connection.isEligible(address, routes)) continue
// 确认 connection 是有效的,存储 connection 连接
call.acquireConnectionNoEvents(connection)
return true
}
return false
}
RealConnection
// 其实这个方法主要就是确认:
// 1、请求数没有超过限制
// 2、我们是使用同一个方式同样的路线连接的主机,比如dns、协议、端口、主机名要一致
internal fun isEligible(address: Address, routes: List<Route>?): Boolean {
// calls.size >= allocationLimit 判断请求是否超过限制,allocationLimit=1
// 在 HTTP/2.0 之前,比如 HTTP/1.1 一个 TCP 连接最多只能承受一个请求
// noNewExchange 表示没有请求
if (calls.size >= allocationLimit || noNewExchanges) return false
// 确认除了主机名外的地址的正确性,比如dns、协议、端口等
if (!this.route.address.equalsNonHost(address)) return false
// 确认主机名,根据上面的确认,主机名如果也确认说明是一个可用的连接
if (address.url.host == this.route().address.url.host) {
return true // This connection is a perfect match.
}
...
}
Address
internal fun equalsNonHost(that: Address): Boolean {
return this.dns == that.dns &&
this.proxyAuthenticator == that.proxyAuthenticator &&
this.protocols == that.protocols &&
this.connectionSpecs == that.connectionSpecs &&
this.proxySelector == that.proxySelector &&
this.proxy == that.proxy &&
this.sslSocketFactory == that.sslSocketFactory &&
this.hostnameVerifier == that.hostnameVerifier &&
this.certificatePinner == that.certificatePinner &&
this.url.port == that.url.port
}
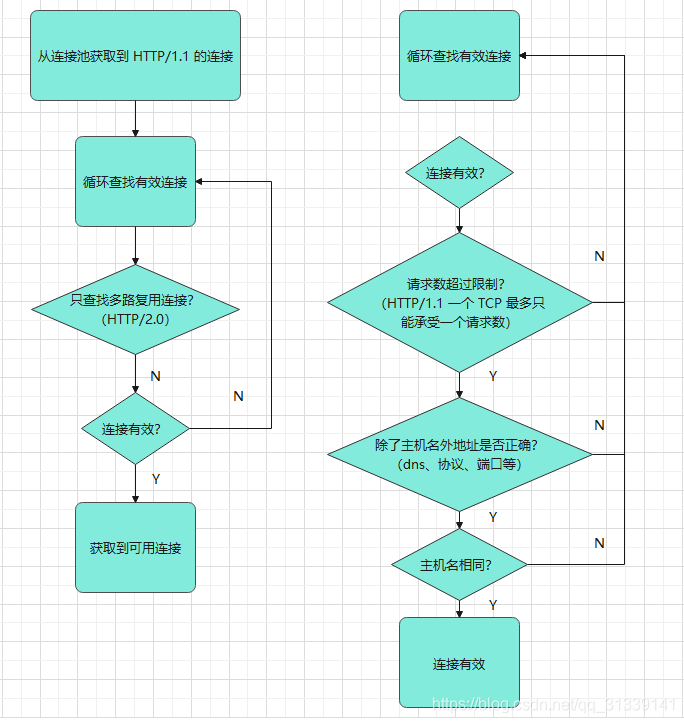
第一次尝试从连接池
connectionPool
获取到一个可用连接,符合条件的连接条件是:
-
HTTP/1.1 请求格式并且请求数量只支持一个(HTTP/1.1 只能接收一个请求,不像 HTTP/2.0 支持多路复用)并且没有新请求连接
noNewExchange
-
确认除了主机名外其他参数符合连接条件,比如dns、协议、端口等符合条件
-
确定主机名相同
根据上面三个条件确认,才能说明是一个可用的连接。
findConnection() 第一次从连接池获取失败,第二次获取连接
private fun findConnection(
...
): RealConnection {
...
// 第一次获取连接的代码,获取失败仍旧 result = null,继续下面的代码尝试再获取连接
...
// 获取要连接的路由,路由 Route 包含代理类型(直连或代理)、ip地址、ip端口
var newRouteSelection = false
if (selectedRoute == null && (routeSelection == null || !routeSelection!!.hasNext())) {
var localRouteSelector = routeSelector
// 获取 RouteSelector,RouteSelection 列表
if (localRouteSelector == null) {
localRouteSelector = RouteSelector(address, call.client.routeDatabase, call, eventListener)
this.routeSelector = localRouteSelector
}
newRouteSelection = true
// 如果一组 RouteSelection 已经尝试连接了没成功,拿下一组 RouteSelection
routeSelection = localRouteSelector.next()
}
var routes: List<Route>? = null
synchronized(connectionPool) {
if (call.isCanceled()) throw IOException("Canceled")
if (newRouteSelection) {
// 如果上面的操作从连接池获取失败,这里再重新获取连接一次
// 这里传入了 routes,上面的 HTTP/1.1 的连接获取失败,会尝试 HTTP/2.0 的连接获取
routes = routeSelection!!.routes
if (connectionPool.callAcquirePooledConnection(address, call, routes, false)) {
foundPooledConnection = true
result = call.connection
}
}
...
}
// 这里返回的连接是第二次从连接池获取的
if (foundPooledConnection) {
eventListener.connectionAcquired(call, result!!)
return result!!
}
...
return result!!
}
在梳理第二次连接流程之前,有必要说明一下
findConnection()
中出现了两个需要留意的地方:
相比第一次从连接池获取连接,第二次从连接池获取连接传入参数不同:
// 第一次从连接池获取连接
connectionPool.callAcquirePooledConnection(address, call, null, false)
// 第二次从连接池获取连接
connectionPool.callAcquirePooledConnection(address, call, routes, false)
相比第一次获取连接,第二次传入了参数
routes
,这里也有必要说明
address
和
routes
两个参数是什么。
1、Address
从连接池获取连接时会传入
address
参数,这个参数其实也和上面 exchangeFinder 创建的同时也一起创建出来,都是在 RetryAndFollowUpInterceptor:
RetryAndFollowUpInterceptor
override fun intercept(chain: Interceptor.Chain): Response {
...
while (true) {
call.enterNetworkInterceptorExchange(request, newExchangeFinder)
...
}
}
RealCall
fun enterNetworkInterceptorExchange(request: Request, newExchangeFinder: Boolean) {
...
if (newExchangeFinder) {
this.exchangeFinder = ExchangeFinder(
connectionPool,
createAddress(request.url), // 创建 Address
this,
eventListener
)
}
}
RealCall
private fun createAddress(url: HttpUrl): Address {
var sslSocketFactory: SSLSocketFactory? = null
var hostnameVerifier: HostnameVerifier? = null
var certificatePinner: CertificatePinner? = null
if (url.isHttps) {
sslSocketFactory = client.sslSocketFactory
hostnameVerifier = client.hostnameVerifier
certificatePinner = client.certificatePinner
}
return Address(
// 主机名和端口直接从 url 拿的,其他都是从 OkHttpClient 获取
uriHost = url.host,
uriPort = url.port,
dns = client.dns,
socketFactory = client.socketFactory,
sslSocketFactory = sslSocketFactory,
hostnameVerifier = hostnameVerifier,
certificatePinner = certificatePinner,
proxyAuthenticator = client.proxyAuthenticator,
proxy = client.proxy,
protocols = client.protocols,
connectionSpecs = client.connectionSpecs,
proxySelector = client.proxySelector
)
}
一个连接中有两个主要因素:主机名和端口
。从创建 Address 的代码可以看到,除了
host
和
port
主机名和端口号是从要访问的 url 获取的以外,其他的都是从 OkHttpClient 获取的。
Address
简单说其实就是主机名和端口,用来最后怎么解析路由要怎么连接过去
。比如要用某个 ip 地址去连接然后配合端口,或者用某个 ip 地址并且配合路由的代理模式去连。Address 就是用来做路由的前一步。
2、Route
① Route:
路由,来确定你具体要怎么连接
。一个 Route 包含
proxy
、
ip
、
port
即代理类型(直连或代理,默认是直连)、ip地址、ip端口
② RouteSelector.Selection:一个
RouteSelector.Selection
(后续说明简化为 RouteSelection) 包含多个 Route 组合(简单理解就是一个 Route 列表)。比如下面的 Route 组合:
http是80,https的端口是443
https://test.com/1
域名:test.com,一个域名下可能对应多个ip地址
// 一个 RouteSelection,其下的 Route 组合的端口都为443、代理类型都为直连
代理类型:直连
1.2.3.4:443
5.6.7.8:443
// 一个 RouteSelection,其下的 Route 组合的端口都为443、代理类型为代理
代理类型:代理 testproxy.com
9.10.11.12:443
13.14.15.16:443
17.18.19.29:443
Route 的端口在此时是固定了(使用的是 HTTP 或 HTTPS),那么不同的就只有代理类型和 ip 地址。
从上面例子可以发现,同一个 RouteSelection 的端口和代理类型是一样的,只有 ip 地址不一样。RouteSelection
就是同样端口同样代理类型下面的不同 ip 的多个 Route 组合
。
③ RouteSelector:一个
RouteSelector
下有多个 RouteSelection 组合(简单理解就是一个 RouteSelection 列表)
所以,RouteSelector、RouteSelection、Route 三者的关系就是:
一个 RouteSelector 有多个 RouteSelection ,每个相同端口相同代理类型而 ip 地址不同的 Route 列表会被归入一个 RouteSelection
。
整理为结构图如下:
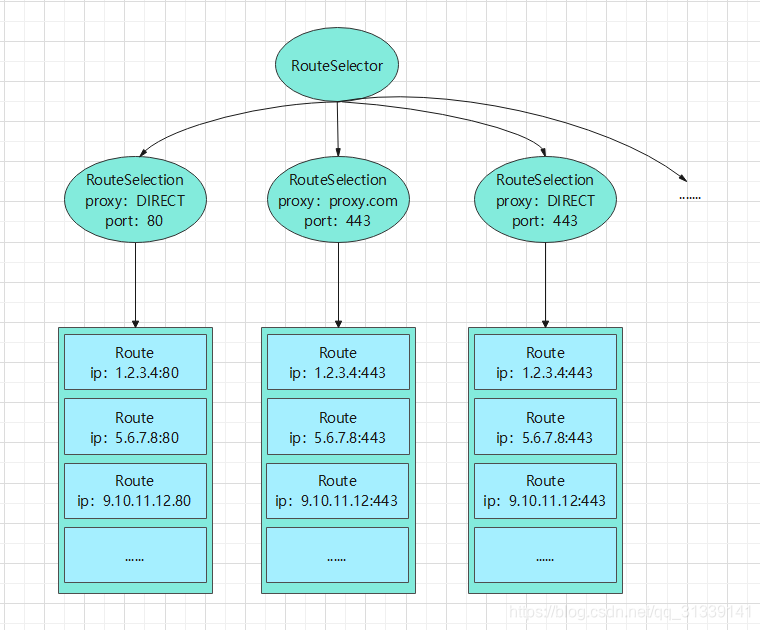
知道了 Address 和 Route 是什么, 就继续看下第二次从连接池获取连接是怎么判断获取一个合格的新连接:
RealConnectionPool
fun callAcquirePooledConnection(
...
): Boolean {
...
for (connection in connections) {
if (requireMultiplexed && !connection.isMultiplexed) continue
if (!connection.isEligible(address, routes)) continue
call.acquireConnectionNoEvents(connection)
return true
}
return false
}
RealConnection
internal fun isEligible(address: Address, routes: List<Route>?): Boolean {
// HTTP/1.1 连接的判断
if (calls.size >= allocationLimit || noNewExchanges) return false
if (!this.route.address.equalsNonHost(address)) return false
if (address.url.host == this.route().address.url.host) {
return true
}
// 下面主要是 HTTP/2.0 处理连接合并
// 执行到下面的代码说明首次从连接池获取 HTTP/1.1 的连接失败了
// 必须是 HTTP/2.0 连接
if (http2Connection == null) return false
// 一个主机下其实一般会对应很多域名地址
// 比如:
// http://test1.com
// http://test2.com
// 两个域名地址,其实都有可能对应的同一个 ip 地址 192.168.0.1
// 所以上面的 address.url.host 判断域名不相同没关系,这里会判断你的 ip 地址是否相同
// 当第二次连接时,从 routes 路由列表能拿到代理类型和 ip 地址都相同的路由 route
if (routes == null || !routeMatchesAny(routes)) return false
// 3. This connection's server certificate's must cover the new host.
if (address.hostnameVerifier !== OkHostnameVerifier) return false
// 判断端口和域名或证书一致
if (!supportsUrl(address.url)) return false
// 4. Certificate pinning must match the host.
try {
address.certificatePinner!!.check(address.url.host, handshake()!!.peerCertificates)
} catch (_: SSLPeerUnverifiedException) {
return false
}
return true
}
// 代理类型和 ip 地址要相同
private fun routeMatchesAny(candidates: List<Route>): Boolean {
return candidates.any {
it.proxy.type() == Proxy.Type.DIRECT &&
route.proxy.type() == Proxy.Type.DIRECT &&
route.socketAddress == it.socketAddress
}
}
fun supportsUrl(url: HttpUrl): Boolean {
val routeUrl = route.address.url
// 端口要相同
if (url.port != routeUrl.port) {
return false // Port mismatch.
}
// 端口和域名如果都相同,那么这个地址可以用
// 如果域名不相同,可以继续往下判断
if (url.host == routeUrl.host) {
return true // Host match. The URL is supported.
}
// 域名不相同没关系,就判断一下现在手上的证书是否和我需要访问的地址的证书相同
// 证书相同说明就是同一个地址,可以重用
// We have a host mismatch. But if the certificate matches, we're still good.
return !noCoalescedConnections && handshake != null && certificateSupportHost(url, handshake!!)
}
private fun certificateSupportHost(url: HttpUrl, handshake: Handshake): Boolean {
val peerCertificates = handshake.peerCertificates
return peerCertificates.isNotEmpty() && OkHostnameVerifier.verify(url.host,
peerCertificates[0] as X509Certificate)
}
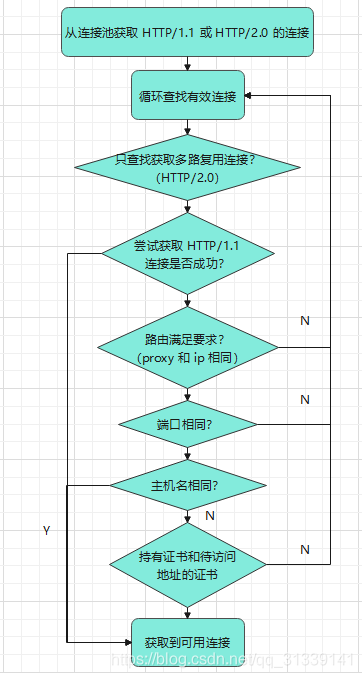
第二次尝试从连接池 connectionPool 获取到一个可用连接,符合条件的连接条件是:
-
再次尝试拿一次 HTTP/1.1 的连接(请求数量只支持一个、确认除主机名外dns、协议、端口等条件符合、主机名相同)
-
如果拿不到,就会根据 routes 路由尝试获取 HTTP/2.0 的连接(支持 HTTP/2.0、能从路由列表拿到 ip 地址、代理类型、端口都相同的连接),
通过代理类型、端口、主机名或证书是否相同获取到一个连接
findConnection() 两次从连接池获取连接都失败,自己创建连接
private fun findConnection(
...
): RealConnection {
...
// 第一次从连接池获取连接失败
...
synchronized(connectionPool) {
// 第二次从连接池获取连接失败
...
if (!foundPooledConnection) {
// 从 RouteSelection 拿到一个自己创建连接需要的 route,即 ip 地址、代理类型和端口
if (selectedRoute == null) {
selectedRoute = routeSelection!!.next()
}
// 创建一个连接
result = RealConnection(connectionPool, selectedRoute!!)
connectingConnection = result
}
}
...
// 建立连接,方法是阻塞的
// 两次从连接池都拿不到连接,自己创建 TCP + TLS 连接
result!!.connect(...)
call.client.routeDatabase.connected(result!!.route())
...
synchronized(connectionPool) {
connectingConnection = null
// 建立完连接后,再尝试重新从连接池获取一次
if (connectionPool.callAcquirePooledConnection(address, call, routes, true)) {
...
} else {
connectionPool.put(result!!) // 将自己创建的连接放进连接池
...
}
}
...
return result!!
}
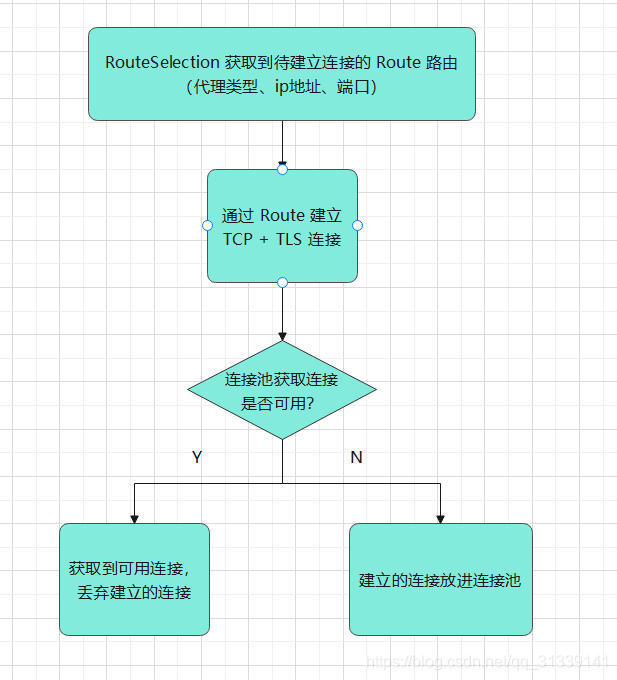
第三次是自己创建一个连接,创建流程:
-
先从
RouteSelection
拿到一个创建连接需要的
Route
,即创建连接需要的ip地址、代理类型和端口 -
通过
Route
创建一个连接并建立连接 -
在往连接池存放自己创建的连接前,尝试再从连接池拿一次连接,如果从连接池拿不到连接,就把自己创建的连接放进连接池;如果从连接池可以拿到连接,就用从连接池拿的连接,刚刚创建的连接丢弃
或许你会觉得疑惑,为什么自己创建了连接,不是建立连接完了就把它存进连接池,而是又要从连接池再拿一次连接?
首先我们先看一下它再拿一次连接的代码,也对比前两次从连接池获取连接的方式:
// 第一次
connectionPool.callAcquirePooledConnection(address, call, null, false)
// 第二次
connectionPool.callAcquirePooledConnection(address, call, routes, false)
// 第三次
connectionPool.callAcquirePooledConnection(address, call, routes, true)
RealConnectionPool
fun callAcquirePooledConnection(
...
): Boolean {
for (connection in connections) {
// 第三次 requiredMultiplexed = true,说明只获取多路复用 HTTP/2.0 的连接,否则不处理
// connection.isMultiplexted = http2Connection != null
if (requireMultiplexed && !connection.isMultiplexed) continue
if (!connection.isEligible(address, routes)) continue
call.acquireConnectionNoEvents(connection)
return true
}
return false
}
第三次获取最后一个参数
requireMultiplexed = true
,
multiplexed
就是多路复用的意思,多路复用是在 HTTP/2.0 才有,所以这次从连接池获取的连接是只获取 HTTP/2.0 的连接。
这里主要处理一种极端情况。假设现在我们要访问这两个连接:
https://test.com/1
https://test.com/2
上面两个连接两次从连接池里面都获取不到,即不需要连接合并的 HTTP/1.1 的连接拿不到,第二次 HTTP/1.1 或 HTTP/2.0 的连接也拿不到,因为没有任何一个连接指向
test.com:443
。所以根据上面第三次连接的代码,后续
https://test.com/1
会尝试创建连接,
https://test.com/2
也会尝试创建连接,然后都建立成功。如果刚好它们都是使用的 HTTP/2.0,HTTP/2.0 因为是多路复用,连接是可以被共享的,这样就会有其中一个重复建立了连接导致资源浪费。
而且我们留意代码是加上了同步锁:
synchronized(connectionPool) {
...
if (connectionPool.callAcquirePooledConnection(address, call, routes, true)) {
...
} else {
connectionPool.put(result!!)
...
}
}
所以针对上面的情况,先创建好的连接从连接池里面拿不到,所以会先被存进连接池;而后续创建的连接再从连接池拿的时候,拿到的是第一个创建的连接,后续创建的连接就都被丢弃。这样就能够节省资源。
还是看回刚才的代码,还有一个地方需要留意一下:
synchronized(connectionPool) {
...
if (connectionPool.callAcquirePooledConnection(address, call, routes, true)) {
...
// 将这个丢弃的连接暂存起来
// 因为后续连接重试或重定向当前的连接被丢弃时,这个已经验证过的可用的连接可以拿来使用
nextRouteToTry = selectedRoute
} else {
...
}
}
被丢弃的连接并不是直接不用,而是暂时存放在一个变量
nextRouteToRetry
,这样做的原因主要是在后续如果需要重试或重定向时,这个连接就可以直接使用了。
findConnection() 重试或重定向重新获取连接
经过上面的分析,现在只是走完了一轮获取连接的代码,而第二轮又有所不同:
@Throws(IOException::class)
private fun findConnection(
...
): RealConnection {
...
synchronized(connectionPool) {
if (call.isCanceled()) throw IOException("Canceled")
// 第一轮进入调用 findConnection() 获取连接时,call.connection = null
// 第二轮因为重试或重定向重新再获取连接时,call.connection != null
// toClose 就是待关闭的不满足判断的连接
val callConnection = call.connection
releasedConnection = callConnection
toClose = if (callConnection != null && (callConnection.noNewExchanges ||
!sameHostAndPort(callConnection.route().address.url))) {
// 释放 socket,将 connection = null,重新去获取连接
call.releaseConnectionNoEvents()
} else {
null
}
// 经过上面判断后连接没有被丢弃,说明是一个合适可使用的连接,直接返回
if (call.connection != null) {
result = call.connection
releasedConnection = null
}
if (result == null) {
...
if (connectionPool.callAcquirePooledConnection(address, call, null, false)) {
...
} else if (nextRouteToTry != null) { // 这个变量是我们当时被丢弃暂存的连接
selectedRoute = nextRouteToTry
nextRouteToTry = null
}
}
}
toClose?.closeQuietly()
...
if (result != null) {
return result!!
}
// 后续的第二次从连接池获取连接和自己创建建立连接
...
return result!!
}
第二轮因为重试或重定向再次获取连接时,如果之前的
call.connection
符合条件不是待关闭的连接,就直接返回这个连接。
不是待关闭连接的条件:
-
callConnection != null
-
callConnection.noNewExchanges
这个连接是有效的,只是之前没能连上;
sameHostAndPort()
主机名和端口相同
什么是待关闭的连接?举个例子:
有一个连接
http://test.com/1
,它是不能重试或重定向到一个
https://test.com/1
,因为
http://test.com/1
的端口是80,而
https://test.com/1
的端口是443,这就是一个待关闭的连接。
有一个连接
http://test.com/1
它可以重试或重定向到一个
http://test.com/2
,或者一个连接
https://test.com/1
它可以重试或重定向到一个
https://test.com/2
,这就是一个正常可用的连接。
findConnection() 总工作流程
这里总结一下
findConnection()
这个获取连接的方法的工作流程:
-
判断当前连接是否需要被丢弃要重新拿连接(连接重试或重定向操作)
-
第一步判断连接仍然可用,返回连接
-
第一步判断连接不可用,先从连接池获取一次非多路复用连接(即获取 HTTP/1.1 的连接),获取成功返回连接
-
第一次连接获取失败,第二次再从连接池获取一次非多路复用或多路复用连接(即 HTTP/1.1 或HTTP/2.0 连接),获取成功返回连接
-
第二次获取失败,自己创建连接并建立连接
-
创建建立连接后重新从连接池只获取多路复用连接,丢弃重复创建的连接
建立 TCP + TLS 连接
上面 ConnectInterceptor 连接的逻辑已经梳理完,接下来看下两次连接失败后,自己怎么手动创建建立连接的:
fun connect(
...
) {
...
while (true) {
try {
// HTTP 去代理 HTTPS 请求
if (route.requiresTunnel()) {
connectTunnel(connectTimeout, readTimeout, writeTimeout, call, eventListener)
if (rawSocket == null) {
// We were unable to connect the tunnel but properly closed down our resources.
break
}
} else {
// 不需要 HTTP 代理 HTTPS 请求,正常的 socket 连接
connectSocket(connectTimeout, readTimeout, call, eventListener)
}
establishProtocol(connectionSpecSelector, pingIntervalMillis, call, eventListener)
...
break
} catch (e: IOException) {
...
}
}
...
}
首先会判断你是否需要请求 Tunnel,如果需要就连接 Tunnel,否则连接 Socket 然后建立协议。
Tunnel
关于
Tunnel
上面有两行相关代码:
route.requiresTunnel()
和
connectTunnel()
。首先了解下什么是 Tunnel。
Tunnel 是一个标准术语,意思是用一个 HTTP 去代理 HTTPS 请求的一种方式。比如说,当前是一个HTTP 请求,但是需要访问一个 HTTPS 的连接。
connectTunnel()
的处理就是将我们的 HTTP 请求转给中介服务器,让中介服务器替我们发送 HTTPS 到目标服务器,这个 HTTP 就是一个 Tunnel。我们也可以看下具体代码:
Route
// HTTP 请求需要访问 HTTPS
fun requiresTunnel() = address.sslSocketFactory != null && proxy.type() == Proxy.Type.HTTP
RealConnection
@Throws(IOException::class)
private fun connectTunnel(
...
) {
var tunnelRequest: Request = createTunnelRequest()
val url = tunnelRequest.url
for (i in 0 until MAX_TUNNEL_ATTEMPTS) {
connectSocket(connectTimeout, readTimeout, call, eventListener)
tunnelRequest = createTunnel(readTimeout, writeTimeout, tunnelRequest, url)
?: break // Tunnel successfully created.
...
}
}
// 将我们的 HTTP 请求转为待会要代理的 HTTPS 请求信息
@Throws(IOException::class)
private fun createTunnelRequest(): Request {
val proxyConnectRequest = Request.Builder()
.url(route.address.url)
.method("CONNECT", null)
.header("Host", route.address.url.toHostHeader(includeDefaultPort = true))
.header("Proxy-Connection", "Keep-Alive") // For HTTP/1.0 proxies like Squid.
.header("User-Agent", userAgent)
.build()
val fakeAuthChallengeResponse = Response.Builder()
.request(proxyConnectRequest)
.protocol(Protocol.HTTP_1_1)
.code(HTTP_PROXY_AUTH)
.message("Preemptive Authenticate")
.body(EMPTY_RESPONSE)
.sentRequestAtMillis(-1L)
.receivedResponseAtMillis(-1L)
.header("Proxy-Authenticate", "OkHttp-Preemptive")
.build()
val authenticatedRequest = route.address.proxyAuthenticator
.authenticate(route, fakeAuthChallengeResponse)
return authenticatedRequest ?: proxyConnectRequest
}
@Throws(IOException::class)
private fun createTunnel(
readTimeout: Int,
writeTimeout: Int,
tunnelRequest: Request,
url: HttpUrl
): Request? {
var nextRequest = tunnelRequest
// Make an SSL Tunnel on the first message pair of each SSL + proxy connection.
// HTTP 代理 HTTPS 所需要的一种标准格式
val requestLine = "CONNECT ${url.toHostHeader(includeDefaultPort = true)} HTTP/1.1"
while (true) {
val source = this.source!!
val sink = this.sink!!
val tunnelCodec = Http1ExchangeCodec(null, this, source, sink)
source.timeout().timeout(readTimeout.toLong(), MILLISECONDS)
sink.timeout().timeout(writeTimeout.toLong(), MILLISECONDS)
tunnelCodec.writeRequest(nextRequest.headers, requestLine)
tunnelCodec.finishRequest()
val response = tunnelCodec.readResponseHeaders(false)!!
.request(nextRequest)
.build()
tunnelCodec.skipConnectBody(response)
when (response.code) {
HTTP_OK -> {
// Assume the server won't send a TLS ServerHello until we send a TLS ClientHello. If
// that happens, then we will have buffered bytes that are needed by the SSLSocket!
// This check is imperfect: it doesn't tell us whether a handshake will succeed, just
// that it will almost certainly fail because the proxy has sent unexpected data.
if (!source.buffer.exhausted() || !sink.buffer.exhausted()) {
throw IOException("TLS tunnel buffered too many bytes!")
}
return null
}
HTTP_PROXY_AUTH -> {
nextRequest = route.address.proxyAuthenticator.authenticate(route, response)
?: throw IOException("Failed to authenticate with proxy")
if ("close".equals(response.header("Connection"), ignoreCase = true)) {
return nextRequest
}
}
else -> throw IOException("Unexpected response code for CONNECT: ${response.code}")
}
}
}
可以发现它确实是使用特定的标准格式将我们的 HTTP 去代理 HTTPS 请求。
connectSocket()
如果我们不需要 Tunnel 即不需要将我们的 HTTP 去代理 HTTPS 请求,那么就建立 TCP Socket 连接。
@Throws(IOException::class)
private fun connectSocket(
...
) {
// 连接所需的代理、ip地址
val proxy = route.proxy
val address = route.address
val rawSocket = when (proxy.type()) {
// address.socketFactory.createSocket() 已经是 java 的 Sokect 建立了
Proxy.Type.DIRECT, Proxy.Type.HTTP -> address.socketFactory.createSocket()!!
else -> Socket(proxy)
}
// rawSocket 就是 RealConnection 内部实际的TCP端口
this.rawSocket = rawSocket
...
try {
Platform.get().connectSocket(rawSocket, route.socketAddress, connectTimeout)
}
...
}
connectSocket()
其实就是用
route
路由提供的连接地址(主机名和端口)、代理类型等这些信息去建立 TCP 连接。
establishProtocol()
建立了 TCP 连接,就要开始建立 HTTP 或 HTTP2 的协议搭建,协议搭建完成了也就可以和服务器沟通了。
@Throws(IOException::class)
private fun establishProtocol(
...
) {
// 不需要加密连接
if (route.address.sslSocketFactory == null) {
// H2_PRIOR_KNOWLEDGE:表示很明确自己要连接的服务器是支持 HTTP/2.0 的
// 我用明文的方式直接连过去
if (Protocol.H2_PRIOR_KNOWLEDGE in route.address.protocols) {
socket = rawSocket
protocol = Protocol.H2_PRIOR_KNOWLEDGE
// 发送一个 HTTP/2.0 的握手动作
startHttp2(pingIntervalMillis)
return
}
// HTTP/1.1 的连接
socket = rawSocket
protocol = Protocol.HTTP_1_1
return
}
...
connectTls(connectionSpecSelector) // 创建一个 TLS 加密的连接
...
// HTTP/2.0 的 TLS 加密连接,需要另外处理一下握手动作
if (protocol === Protocol.HTTP_2) {
startHttp2(pingIntervalMillis)
}
}
@Throws(IOException::class)
private fun connectTls(connectionSpecSelector: ConnectionSpecSelector) {
...
try {
sslSocket = sslSocketFactory!!.createSocket(
rawSocket, address.url.host, address.url.port, true /* autoClose */) as SSLSocket
...
// 在 connectSocket() 有一个 rawSocket 它是 TCP 连接
// 这里的 socket 如果是加密连接它就是一个 SSL 连接
// 如果不是加密连接它也是一个 TCP 连接
socket = sslSocket
...
}
...
}
startHttp2()
支持 HTTP/2.0 的连接,是需要发送一个 preface 说明,这是一个标准:
RealConnection
@Throws(IOException::class)
private fun startHttp2(pingIntervalMillis: Int) {
...
http2Connection.start()
}
Http2Connection
@Throws(IOException::class) @JvmOverloads
fun start(sendConnectionPreface: Boolean = true, taskRunner: TaskRunner = TaskRunner.INSTANCE) {
if (sendConnectionPreface) {
writer.connectionPreface()
...
}
}
Http2Writer
@Synchronized @Throws(IOException::class)
fun connectionPreface() {
if (closed) throw IOException("closed")
if (!client) return // Nothing to write; servers don't send connection headers!
if (logger.isLoggable(FINE)) {
logger.fine(format(">> CONNECTION ${CONNECTION_PREFACE.hex()}"))
}
// 支持 HTTP/2.0 的一个标准
// 需要发送一个 preface 说明支持 HTTP/2.0
sink.write(CONNECTION_PREFACE)
sink.flush()
}
connectTls()
如果是 TLS 加密连接,还需要做加密连接相关比如证书验证等处理。我们在
connectSocket()
有一个变量是
rawSocket
表示的是 TCP 连接;这里在建立 TLS 加密连接时有一个变量
socket
,如果是加密连接那它就是 SSL 连接,如果不是加密连接它就是 TCP 连接。
上面的处理分析:
-
如果不需要加密连接,如果是 HTTP/2.0 的连接,需要发送一个 preface
-
如果不需要加密连接,如果是 HTTP/1.1 的连接,
socket
就是
rawSocket
即 TCP 连接 -
如果需要加密连接,处理加密连接相关的处理,
socket
就是 SSL 连接,如果是 HTTP/2.0 的连接,还需要发送一个 preface
CallServerInterceptor
在 ConnectInterceptor 获取了可用的连接、建立了 TCP 连接或 TLS 连接、获取了编码解码器,剩下的数据交互就是
CallServerInterceptor
做的事情:
@Throws(IOException::class)
override fun intercept(chain: Interceptor.Chain): Response {
val realChain = chain as RealInterceptorChain
val exchange = realChain.exchange!!
val request = realChain.request
val requestBody = request.body
val sentRequestMillis = System.currentTimeMillis()
exchange.writeRequestHeaders(request)
var invokeStartEvent = true
var responseBuilder: Response.Builder? = null
if (HttpMethod.permitsRequestBody(request.method) && requestBody != null) {
// If there's a "Expect: 100-continue" header on the request, wait for a "HTTP/1.1 100
// Continue" response before transmitting the request body. If we don't get that, return
// what we did get (such as a 4xx response) without ever transmitting the request body.
if ("100-continue".equals(request.header("Expect"), ignoreCase = true)) {
exchange.flushRequest()
responseBuilder = exchange.readResponseHeaders(expectContinue = true)
exchange.responseHeadersStart()
invokeStartEvent = false
}
if (responseBuilder == null) {
if (requestBody.isDuplex()) {
// Prepare a duplex body so that the application can send a request body later.
exchange.flushRequest()
val bufferedRequestBody = exchange.createRequestBody(request, true).buffer()
requestBody.writeTo(bufferedRequestBody)
} else {
// Write the request body if the "Expect: 100-continue" expectation was met.
val bufferedRequestBody = exchange.createRequestBody(request, false).buffer()
requestBody.writeTo(bufferedRequestBody)
bufferedRequestBody.close()
}
} else {
exchange.noRequestBody()
if (!exchange.connection.isMultiplexed) {
// If the "Expect: 100-continue" expectation wasn't met, prevent the HTTP/1 connection
// from being reused. Otherwise we're still obligated to transmit the request body to
// leave the connection in a consistent state.
exchange.noNewExchangesOnConnection()
}
}
} else {
exchange.noRequestBody()
}
if (requestBody == null || !requestBody.isDuplex()) {
exchange.finishRequest()
}
if (responseBuilder == null) {
responseBuilder = exchange.readResponseHeaders(expectContinue = false)!!
if (invokeStartEvent) {
exchange.responseHeadersStart()
invokeStartEvent = false
}
}
var response = responseBuilder
.request(request)
.handshake(exchange.connection.handshake())
.sentRequestAtMillis(sentRequestMillis)
.receivedResponseAtMillis(System.currentTimeMillis())
.build()
var code = response.code
if (code == 100) {
// Server sent a 100-continue even though we did not request one. Try again to read the actual
// response status.
responseBuilder = exchange.readResponseHeaders(expectContinue = false)!!
if (invokeStartEvent) {
exchange.responseHeadersStart()
}
response = responseBuilder
.request(request)
.handshake(exchange.connection.handshake())
.sentRequestAtMillis(sentRequestMillis)
.receivedResponseAtMillis(System.currentTimeMillis())
.build()
code = response.code
}
exchange.responseHeadersEnd(response)
response = if (forWebSocket && code == 101) {
// Connection is upgrading, but we need to ensure interceptors see a non-null response body.
response.newBuilder()
.body(EMPTY_RESPONSE)
.build()
} else {
response.newBuilder()
.body(exchange.openResponseBody(response))
.build()
}
if ("close".equals(response.request.header("Connection"), ignoreCase = true) ||
"close".equals(response.header("Connection"), ignoreCase = true)) {
exchange.noNewExchangesOnConnection()
}
if ((code == 204 || code == 205) && response.body?.contentLength() ?: -1L > 0L) {
throw ProtocolException(
"HTTP $code had non-zero Content-Length: ${response.body?.contentLength()}")
}
return response
}
可以发现 CallServerInterceptor 其实就是拿着在 ConnectInterceptor 的 Exchange 处理 IO 读写数据,而 Exchange 只是作为一个管理员的身份,最终是由 codec 读写数据。
client.interceptors 和 client.networkInterceptors
client.interceptors
和
client.networkInterceptors
是可以提供自定义拦截器的地方,但是为什么要分两个地方处理?
val interceptors = mutableListOf<Interceptor>()
interceptors += client.interceptors
interceptors += RetryAndFollowUpInterceptor(client)
interceptors += BridgeInterceptor(client.cookieJar)
interceptors += CacheInterceptor(client.cache)
interceptors += ConnectInterceptor
if (!forWebSocket) {
interceptors += client.networkInterceptors
}
interceptors += CallServerInterceptor(forWebSocket)
根据源码我们可以看到,
client.interceptors
是放在最前面的,比 OkHttp 内置的拦截器都要靠前,在这里定义拦截器好处就在于,你的拦截器不会因为 OkHttp 内置的拦截器写入比如
Content-Type
、
Content-Length
这些 Header 影响,特别是 BridgeInterceptor 会写入很多请求相关的 Headers,所以一般我们都会在
client.interceptors
添加自己的拦截器。
而
client.networkInterceptors
一般是使用在做网络调试的时候使用,因为它放在 OkHttp 内置拦截器的最后,可以获取到 OkHttp 处理数据后的最终请求响应内容,比如 Facebook 开源网络调试库
steho
的拦截器就是
OkHttpClient.addNetworkInterceptor(new StehoInterceptor())
这里添加的。一般不会在这里处理自定义拦截,否则 OkHttp 内置的一些参数不就被你改坏了。
总结
通过源码的深入分析,我们可以知道 OkHttp 是一个非常优秀的网络框架,针对网络业务做了很多详细的工作,
特别值得学习的地方是 Dispatcher 任务分发器的线程池设计以及拦截器的设计
,还有做了一些优化工作比如该篇文章没有提及的 Okio 数据读写优化;要读懂 OkHttp 的源码最重要的是掌握 TCP 和 HTTP 网络原理,这样才能结合业务知其然知其所以然。