这是入手nlp词义消歧看的第一篇论文,如下:
http://链接:https://pan.baidu.com/s/1TNZUypbKetWVeeffx0kuZw 提取码:egxg
文章关注的是:如何在监督神经WSD系统中更好地利用光泽信息?
首先,词义消歧是nlp中一项基本任务和长期存在的挑战,目的是在特定的上下文中找到一个歧义词的确切意义。在本篇论文中,建立了上下文光泽对并提出了3个基于bert(关于bert的知识其实我学得不够多,所以这里需要挖个坑后期填补)的WSD模型,对SenCor3.0训练语料库上的预训练bert模型进行了微调。
微调的注意事项:
1)通常的做法是截断预先训练好的网络的最后一层(softmax层),并用与我们自己的问题相关的新的softmax层替换它。
2)使用
较小的学习率
来训练网络。
3)如果数据集数量过少,我们进来只训练最后一层,如果数据集数量中等,冻结预训练网络的前几层的权重也是一种常见做法。
Fine-tune(迁移学习)
:冻结预训练模型的部分卷积层(通常是靠近输入的多数卷积层),训练剩下的卷积层(通常是靠近输出的部分卷积层)和全连接层。
3种glossbbert模型:
-
token-cls:取与目标此对应的标记的最终隐藏状态(如果有多个的话就平均)来
突出显示目标词
,并添加一个分类层。
-
S
ent-cls:将第一个标记[cls]的最终隐藏状态作为整个序列的表示,并添加一个分类层,
没有突出显示目标词
。(结果比token好)
-
S
ent-cls-ws:具有若监督的上下文光泽对作为输入,并添加一个分类层,
通过弱监督突出显示目标词
。(表现最好,总结了前两个的优点)
预先训练过的模型bert-base进行微调(bert-large效果比较差)
(dev)验证集
看完论文后就去跑了项目代码,花了我很多时间,最后发现我的电脑显存不够带不动,所以后面拿了导的服务器跑代码,batchsize也调小了,跑了我一天多,然后直接黑屏,估计是我没开空调,但是发现是有结果的,虽然结果没有出全,但是那个结果已经可以进行研究了,但是最近的任务有些多,所以还需要往后推一推。
接下来是我记录的复现时遇到的问题:
-
已经下载过了pytorch但是代码还是一样标红,发现是系统已经下载过,在pip命令后面添加
–traget= 地址是pip是出现的地址
行不通?
2.我的pychram环境是有问题的,系统中装上了pytorch但是我的项目没有
问题已解决:
(8条消息) Pycharm创建虚拟环境_冲冲冲鸭鸭鸭~的博客-CSDN博客_pycharm创建虚拟环境
在terminal先建立一个虚拟环境,再将项目建于虚拟环境之中,
Conda create -n xxx(自定义一个名字) python==?(所需要的版本)
然后输入y
激活虚拟环境!!!
Conda activate xxx (windows环境)
Source activate xxx (linux环境)
如果有requirements.txt文件的话,可以直接使用
Pip install -r requirements.txt
如果没有的话,就将所需要的包pip进去
添加环境,file-settings-add conda environment(existinng,是刚刚创建的环境名)-最后ok搞定
3.出现一个新的问题:MemoryError ???
尝试过更改电脑内存发现并没有用。
更改batchsize?(更改参数的话其实也没用耶,有用的,只不过要去服务器,我的电脑带不动)
尝试跑了一下bertbaseline的,然后出现了100%后还是MemoryError。
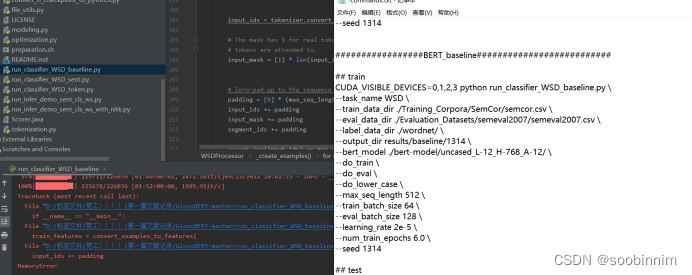
最终发现是我这台电脑的显存不够用,所以问题出在设备上,所以接下来要使用服务器去跑代码,linux系统,要学一下命令打法。
关于读取xml将其整合成一个句子,后期要改这块代码去跑自己的数据集,这部分搞定后就可以试试改变模型。
[error]
_pickle.UnpicklingError: A load persistent id instruction was encountered,
but no persistent_load function was specified.
尝试修改:
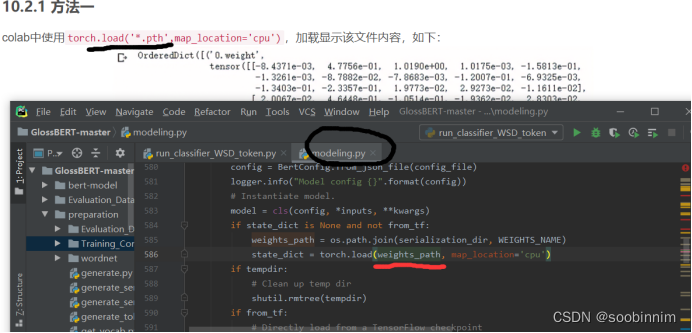
Modeling 586行 (没用!!!)

看到这么一个方法,所以可以选择从头再来?
重新训练了一下,好像能跑了?
ModuleNotFoundError: No module named ‘keras_applications’
出现了上面这个问题,就是版本不一致的问题,所以卸载重装
pip
un
install keras_preprocessing
pip
un
install keras_applications
pip install keras_preprocessing
pip install keras_applications
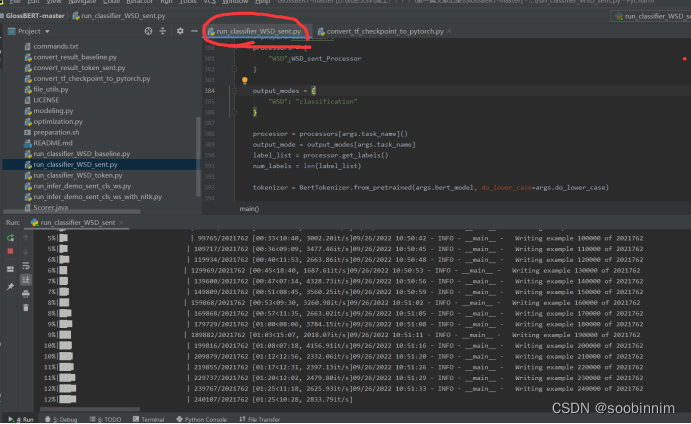

正在跑?
数据读取成功,竟然有这么多条数据,200多万条数据
RuntimeError: CUDA out of memory. Tried to allocate 24.00 MiB (GPU 0; 10.76 GiB total capacity; 9.81 GiB already allocated; 15.44 MiB free; 23.13 MiB cached)
又出现了错误!
我的电脑好像带不动,黑屏了好几次,是可以运行的就是承载不了
跑出来啦!!! 10.08
本来是打算重新跑的,但是发现已经有生成的文件了,所以就查看了一下
虽然没有全部跑出来 但是有几个是出来的了,所以现在就是要进行分析
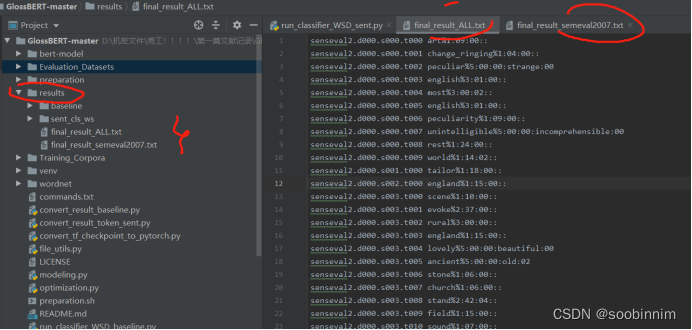
数据集太大可以通过减少batchsize再次运行
所训练出来的数据就是选出单词最为接近的意思
其实最好的做法就是进行数据集的更换,但是目前我还没学到那个地步,所以也只能等后期再进行学习更改代码和微调。
(下面是处理xml文件产生句子的代码,将这些进行修改就可以更改数据集)
Import xml.etree.ElementTree as ET
def generate(file_name):
tree = ET.ElementTree(flie=file_name)
root = tree.getroot()
Sentences = []
Poss = []
Targets = []
Targets_index_start = []
Targets_index_end = []
Lemmas = []
for doc in root:
for sent in doc:
Sentence = []
Pos = []
Target = []
Traget_index_start = []
Target_index_end = []
Lemmas = []
For token in sent:
assert token.tag == ‘wf’ or token.tag ==’instance’ # 断言,是一种很好的编程写法,如果这里发生了错误报错的时候就会有提示这里出现问题,容易进行修改
If token.tag == ‘wf’:
For i in token.text.split(‘ ‘):
Sentence.append(i)
Pos.append(token.attrib[‘pos’])
Target.append(‘X’)
Lemma.append(token.attrib[‘lemma’])
If token.tag == ‘instance’:
Target_start = len(sentence)
For i in token.text.split(‘ ’):
Sentence.append(i)
Pos.append(token.attrib[‘pos’])
Target.append(token.attrib[‘id’])
Lemma.append(token.attrib[‘lemma’])
Target_end = len(sentence)
Assert ‘ ‘.join(sentence[target_start:target_end]) == token.text
Target_index_start.append(target_start)
Target_index_end.append(target_end)
Sentences.append(sentence)
Poss.append(pos)
Targets.append(target)
Targets_index_start.append(target_index_start)
Targets_index_end.append(target_index_end)
Lemma.append(lemma)
上周把这篇论文中的数据替换成了实验室自己的数据集,也算是学会了替换数据集这一简单的步骤,接下来就是看看能不能在此上面进行改进,不能的话也算是有所进展了,自己数据集上面的准确率确实挺高的,感觉处理数据集就是一个大工程了。