1、概念
- selenium是一个用于Web应用程序测试的工具,其用电脑模拟人操作浏览器网页,可以实现自动化网页操作等。
- selenium支持的浏览器有Chrome、Firefox、IE、Edge、Opera等等。
- 本博客将以Chrome为演示对象。
2、安装
- 安装selenium库
pip install selenium
- selenium对浏览器进行模拟操作,需下载对应浏览器的驱动:
Chrome浏览器驱动:Chromedriver
Firefox浏览器驱动:Geckodriver
IE浏览器驱动:IEDriverServer
Edge浏览器驱动:MicrosoftWebDriver
Opera浏览器驱动:Operadriver
- 以Chromedriver为例:
(1)首先打开Chrome浏览器,点击右上角三点-设置-关于Chrome,查看浏览器版本(博主的版本为91.0.4472.77)。
(2)进入上述驱动下载网站,点击对应的Chrome版本号下载对应的Chromedriver。网站中版本号最后的101与19无关紧要,前三部分相同即可。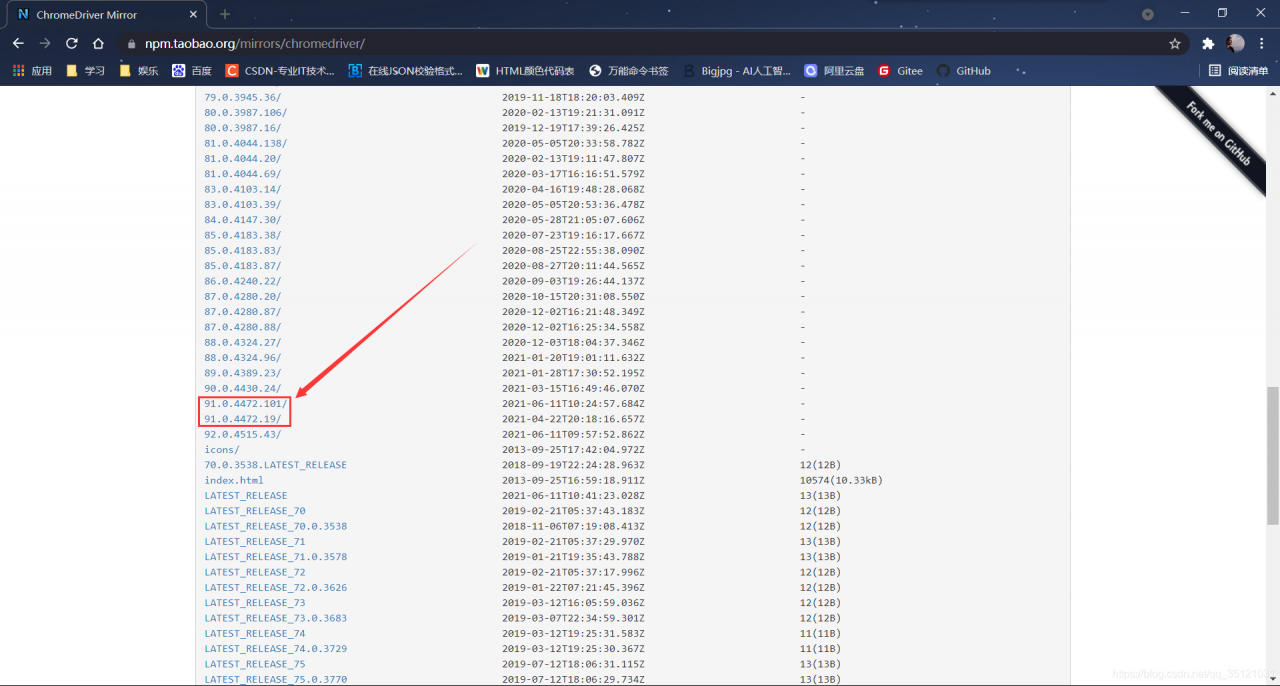
(3)将下载好的Chromedriver.exe文件移动至自己的Chrome的Application文件夹下,完成配置。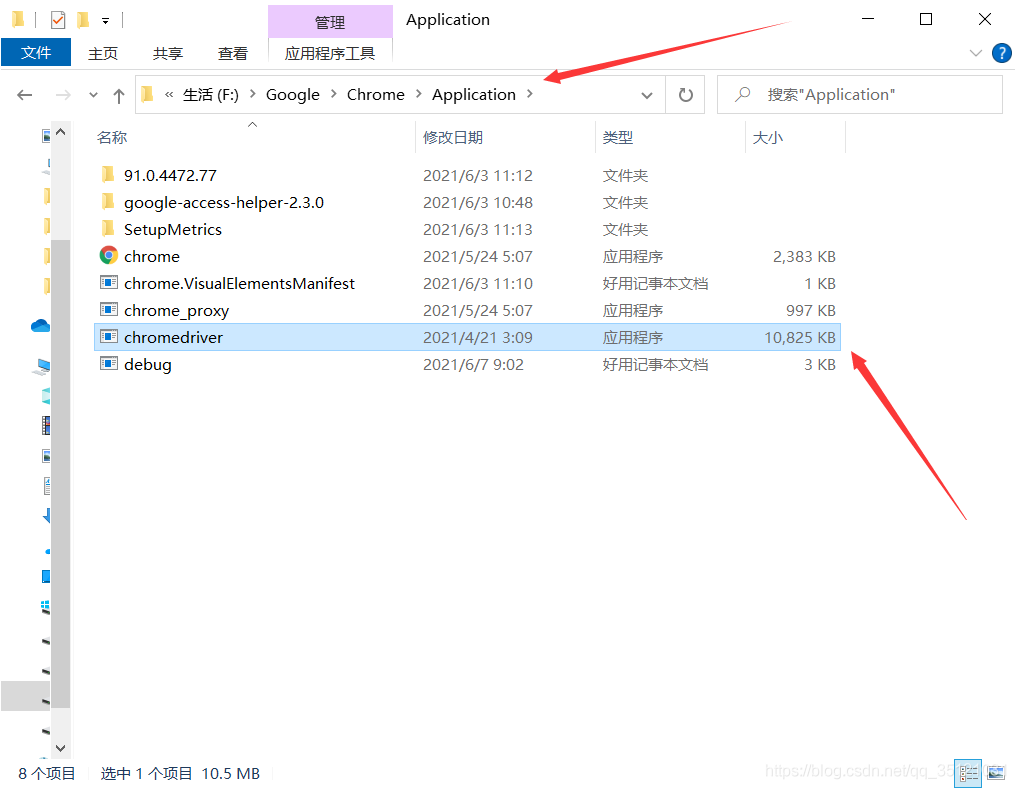
3、代码
-
还是延续前章,以爬取豆瓣Top250电影网站电影名为例。
-
导包:
from selenium import webdriver
- 我们主要使用webdriver库进行模拟浏览器操作,也可通过webdriver.ChromeOptions(),为浏览器添加一些附加属性。
- 仅需三行简单的代码,点击运行,即可自动打开浏览器,并访问豆瓣Top250电影网站。我们使用webdriver.Chrome()获取到浏览器对象并保存到browser变量中,之后browser的相关操作即为对浏览器当前网页的操作。
url = 'https://movie.douban.com/top250'
browser = webdriver.Chrome()
browser.get(url)
- 使用webdriver.ChromeOptions()为浏览器添加一些属性,以下只列出极少部分。当然,豆瓣爬虫案例较为简单,并不需要Options,读者可酌情添加。
opts = webdriver.ChromeOptions()
opts.add_argument('--headless') # 浏览器不提供可视化页面
opts.add_argument('--no-sandbox') # 解决DevToolsActivePort文件不存在的报错
opts.add_argument('blink-settings=imagesEnabled=false') # 禁止网页加载图片
browser = webdriver.Chrome(options=opts)
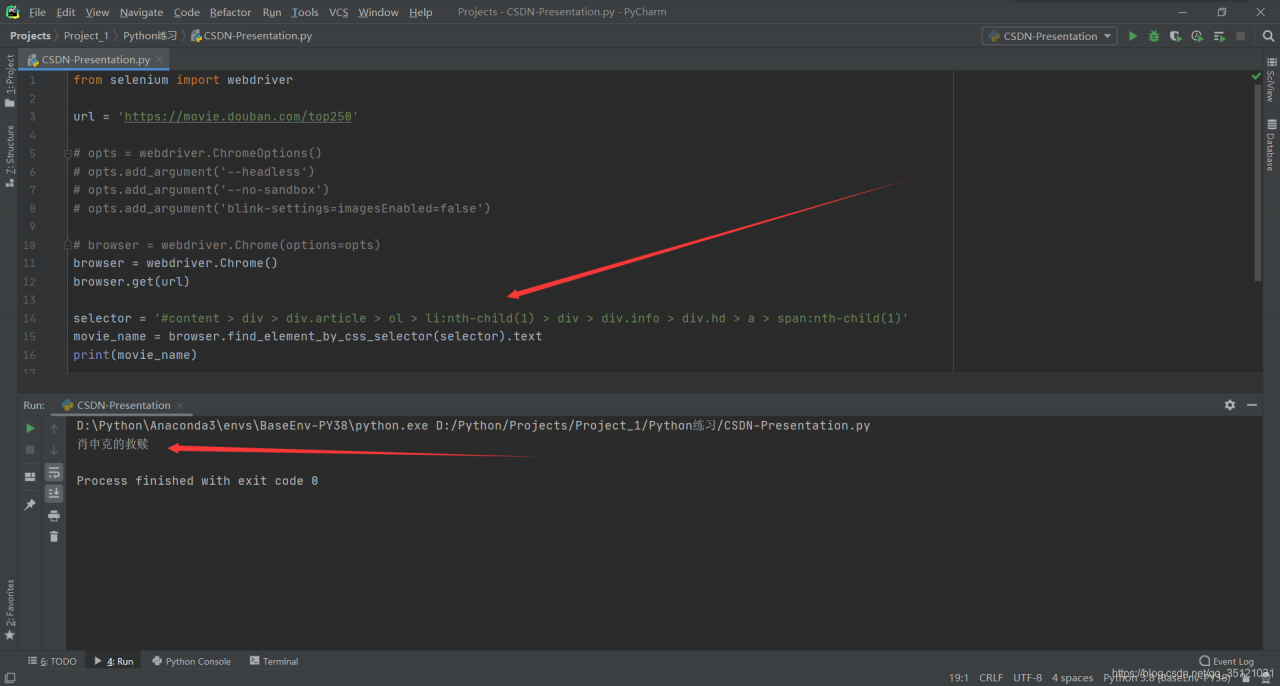
- 浏览器界面按F12或者右键>检查功能获取电影名《肖申克的救赎》的Selector(XPath等均可),使用find_element_by_css_selector()方法,获取到电影名的<span></span>标签,通过.text获取标签内容即电影名。
selector = '#content > div > div.article > ol > li:nth-child(1) > div > div.info > div.hd > a > span:nth-child(1)'
movie_name = browser.find_element_by_css_selector(selector).text
print(movie_name)
selenium有众多元素定位方法,将方法名中的element改为复数elememts即可定位多个元素:
- xpath定位:find_element_by_xpath()
- id定位:find_element_by_id()
- name定位:find_element_by_name()
- class定位:find_element_by_class_name()
- tag定位:find_element_by_tag_name()
- link定位:find_element_by_link_text()
- partial_link定位:find_element_by_partial_link_text()
- 对比第二部电影《霸王别姬》的Selector路径:
Xiao='#content > div > div.article > ol > li:nth-child(1) > div > div.info > div.hd > a > span:nth-child(1)'
Wang='#content > div > div.article > ol > li:nth-child(2) > div > div.info > div.hd > a > span:nth-child(1)'
- 可发现唯一的不同即为“ li:nth-child(n) ”,第一部电影n为1,第二部电影n为2,可试推出,若去掉 li 后的“ :nth-child(n) ”,则应可以获取所有的电影名(使用find_elements_by_css_selector()方法):
selector = '#content > div > div.article > ol > li > div > div.info > div.hd > a > span:nth-child(1)'
movie_names = browser.find_elements_by_css_selector(selector)
for movie_name in movie_names:
print(movie_name.text)
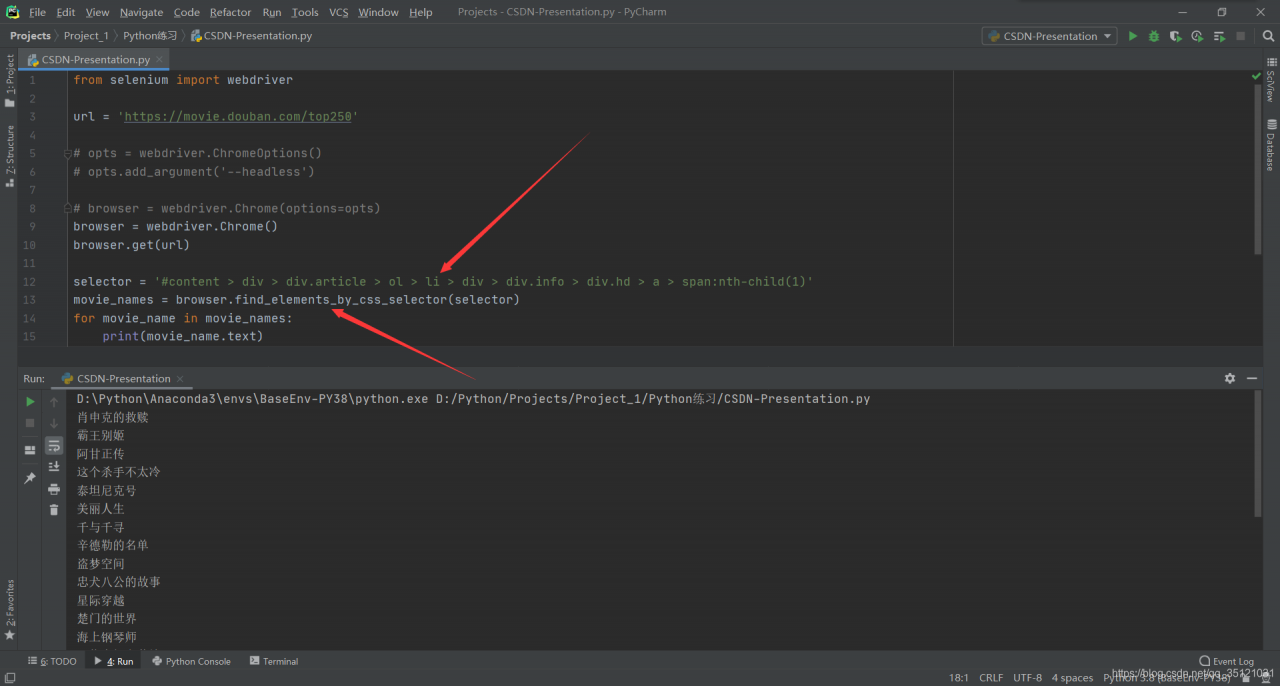
- 完整代码如下:
from selenium import webdriver
url = 'https://movie.douban.com/top250'
# opts = webdriver.ChromeOptions()
# opts.add_argument('--headless')
# browser = webdriver.Chrome(options=opts)
browser = webdriver.Chrome()
browser.get(url)
selector = '#content > div > div.article > ol > li > div > div.info > div.hd > a > span:nth-child(1)'
movie_names = browser.find_elements_by_css_selector(selector)
for movie_name in movie_names:
print(movie_name.text)
4、总结
- selenium可用于爬虫、浏览器自动化等,在网站反爬措施较强、requests效果较差时,使用selenium有较好效果。
- 但selenium配置稍微复杂一些,运行速度也较慢,需要读者对浏览器与网页结构有更加深入的了解。
- 学如逆水行舟,不进则退!
- (ง •̀-•́)ง
版权声明:本文为qq_35121031原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。