
四、列表
列表(list),可以包含不同类型的对象,甚至可以包括其他列表。列表的灵活性使得它非常有用。
例如,用R 拟合一个线性回归模型,其返回结果就是一个列表,其中包含了线性回归的详细结果,如线性回归系数(数值向量)、残差(数值向量)、QR 分解(包含一个矩阵和其他对象的列表)等。因为这些结果全都被打包到一个列表中,就可以很方便地提取所需信息,而无需每次调用不同的函数。
1. 创建列表
可以用函数list()创建一个列表。不同类型的对象可以被装进同一个列表中。例如,创建了一个列表,包含3个成分:一个单元素的数值向量、一个两元素的逻辑向量和一个长度为3的字符向量:
> 也在创建列表时,为列表的每个成分指定名称:
> 也可以创建列表后再对列表成分命名或修改命名:
>
2. 从列表中提取元素
提取列表中的元素,最常用的方法是用$,通过成分名称来提取该成分下的元素(内容):
> 也可以用 [[ n ]] 来提取列表第n个成分的内容,n也可以换成成分的名字:
> 使用 [[ ]] 提取列表中某个成分的内容更加灵活,因为可以赋值改变想要提取其内容的成分名字:
>
3. 构建列表子集
经常也需要从列表中提取多个成分的内容,由这些成分组成的列表构成了原列表的一个子集。
就像构建向量和矩阵的子集一样,构建一个列表子集是用 [ ],可以取出列表中的一些成分,然后放到一个新的列表中。
[ ] 中可以用字符向量表示成分名称,用数值向量表示成分位置,或用逻辑向量指定是否选择,来取出列表成分。
>
注
:用 [ ] 提取若干成分时,返回列表的子集,还是一个列表;用[[ ]]提取单个成分的元素,返回的是对应成分的元素。总之,[ ] 提取对象的子集,类型仍是该对象;[[ ]] 提取对象的内容(下一级元素)。
4. 对列表的成分赋值
> 若给一个不存在的成分赋值,列表会自动地在对应名称或位置下增加一个新成分:
> 也可以同时给多个列表成分赋值:
> 若要移除列表中的某些成分,只需赋值为 NULL:
>
5. 列表函数
用as.list( )函数可将向量转换成列表:
> 用函数unlist(),可将一个列表强制转换成一个向量。该函数基本上对所有列表成分进行转换,并把它们存储在一个类型兼容的向量中:
> 若对一个混合了数值和文本的列表进行去列表化(unlist),则每个成分都会被转换为其所能转换成的最近类型(closest type):
> 这里的l4$a 和l4$b都是数值,可以被转换为字符向量;但是,l4$c是字符向量,无法被转换为数值。因此,能够兼容这些元素的最近类型就是字符向量。
函数summary() 可以查看列表的汇总信息:
>
五、数据框(数据表)
R语言中做统计分析的样本数据,都是按数据框类型操作的。
数据框是指有若干行和列的数据集,它与矩阵类似,但并不要求所有列都是相同的类型;本质上讲,数据框就是一个列表,它的每个成分都是一个向量,并且长度相同,以表格的形式展现。总之,
数据框是由列向量组成、有着矩阵形式的列表
。
数据框与最常见的数据表是一致的:每一列代表一个变量属性,每一行代表一条样本数据:
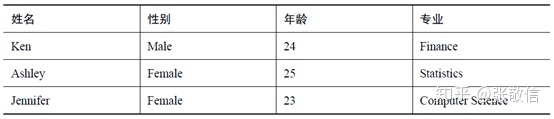
1. 创建数据框
可以用data.frame()函数,对每一列提供相应类型的列向量来创建一个数据框。
> 注意,数据框的创建方式与列表完全一致。也可以对列表直接调用data.frame( )或者as.data.frame( )将其转换为数据框:
> 同样的方式,也可以将矩阵转化为数据框:
>
注
:若矩阵有行名或列名,则转换中会被保留下来。
数据框既是列表的特例,也是矩阵的推广,因此访问这两类对象的方式都适用于数据框。例如与矩阵类似,对数据框的行列重新命名:
> 另外,可用names()查看或修改数据框的列名。
2. 提取数据框的元素、子集
数据框是由列向量组成、有着矩阵形式的列表,所以可以用两种操作方式来访问数据框的元素和子集。
(1) 以列表方式提取数据框的元素、子集
若把数据框看作是由向量组成的列表,则可以沿用列表的操作方式来提取元素或构建子集。例如,可以用$按列名来提取某一列的值,或者用[[ ]]按照位置提取。
> 以列表形式构建子集完全适用于数据框,同时也会生成一个新的数据框。提取子集的操作符 [ ] 允许用数值向量表示列的位置,用字符向量表示列名,或用逻辑向量指定是否选择。
>
(2) 以矩阵方式提取数据框的元素、子集
以列表形式操作并不支持行选择。以矩阵形式操作更加灵活,若将数据框看作矩阵,其二维形式的存取器可以很容易地获取一个子集的元素,同时支持列选择和行选择。
换句话说,可以使用 [i, j] 指定行或列来提取数据框子集,[ , ]内可以是数值向量、字符向量或者逻辑向量。
选择指定的列:
>
选择指定的行:
>
同时选择指定的行和列:
> 注意,以矩阵形式操作会自动简化结果,也就是说,若只提取一列,那么结果将不再是数据框形式,而只是一个列向量。若要保留数据框的形式,一种方法是以结合使用两种操作方式:
> 这里,第1 组 [ , ] 以矩阵形式提取数据框的前4行和所有的列,第2 组 [ ] 再以列表形式提取列名为id 的这一列,结果即表现为数据框的形式。
另一种方法是通过设定参数drop = FALSE 避免简化结果:
>
用条件筛选数据:
例如,用score >= 0.5 筛选df1 的行,并选择id 和level 两列:
> 按行名属于集合{a, d, e}来筛选 df1的行,并选择id和score两列:
>
注
:还可以用sqldf包中的sqldf()函数,借助sql语句索引。例如,
>
3. 给数据框赋值
(1) 以列表方式给数据框赋值
>
注
:用[[ ]]只能对数据框的1列进行赋值。
用[ ]则既可以对数据框的1列,也可以对数据框的多列进行赋值:
>
(2) 以矩阵方式给数据框赋值
以列表方式对数据框进行赋值时,也是只能访问列。若需要更加灵活地进行赋值操作,可以以矩阵方式进行。
>
4. 数据框函数
str()函数作用在R对象上,显示该对象的结构:
> summary()函数作用在数据框上,将生成一个汇总表来显示每一列的情况:
> 经常需要将多个数据框(或矩阵)按行或按列进行合并,使用函数rbind(),增加行(样本数据),要求宽度(列数)相同;使用函数cbind(),增加列(属性变量),要求高度(行数)相同。
例如,向数据框persons数据框中添加一个人的新记录:
> 向persons数据框中添加两个新列表示每个人是否已注册和其手头的项目数量:
> 注意,rbind()和cbind()不会修改原始数据,而是生成一个添加了行或列的新数据框。
另一个实用函数是expand.grid(),它会生成多个属性水平值所有组合(笛卡尔积)的数据框:
>
六、因子(factor)
变量分为
名义型
(无顺序好坏之分的分类变量,如性别)、
有序型
(有顺序好坏之分的分类变量,如疗效)、
连续型
(通常的数值变量,可带小数位)。
名义型和有序型的类别变量,在R语言中称为因子,因子本质上是一个带有水平(level)属性的整数向量,其中“水平”是指事前确定可能取值的有限集合。
因子提供了一个简单且紧凑的形式来处理分类数据,因子用
水平
来表示所有可能的取值,例如,性别有两个水平:男、女。
1. 创建因子
(1) 用函数factor()创建因子,其基本格式为:
factor其中,
x为创建因子的数据向量;
levels指定因子的水平数,默认为x中不重复的所有值;
labels设置各水平名称(前缀),与水平一一对应;
exclude指定有哪些水平是不需要的;
ordered设置是否对因子水平排序,默认为TRUE即有序因子,FALSE为无序因子;
nmax设定水平数的上限。
ff
注
:函数substring()用来提取字符串的子串,第2个参数是起始位置,第3个参数是终止位置;letters和LETTERS是R中专有变量,表示26个小写/大写字母组成的字符向量。
(2) 用函数gl()创建因子序列
用函数gl()生成不同水平的因子序列,基本格式为:
gl其中,
n表示因子水平数;
k表示每个水平的重复数;
length表示生成序列的长度;
labels为表示因子水平的n维向量;
ordered指定是否为有序因子,TRUE为有序因子,FALSE为无序因子。
#
2. 使用因子
R语言中,因子是以整数型向量存储的,每个因子水平对应一个整数型的数。对字符型向量创建的因子,可以指定因子水平顺序,否则默认会按照字母顺序,再对应到整数型向量。
考虑用一个变量存储字符串型的月份:
x1 这有两个问题:
(1) 实际只需要12个月份值,对拼写错误也无能为力;
(2) 不会按照想要的方式排序:
> 若改用因子型就能避免上述问题。创建因子型,首先要创建一个有效的“水平值”列表:
month_levels <- c(
"Jan", "Feb", "Mar", "Apr", "May", "Jun",
"Jul", "Aug", "Sep", "Oct", "Nov", "Dec"
)现在来创建因子:
> 并且任何不在水平集中的值都将转化为NA值:
> 有时候你可能更希望让水平的顺序与其在数据集中首次出现的次序相匹配,设置levels=unique(x)即可,或者用管道操作在其后增加fct_inorder():
> 用levels()函数可以返回因子变量所有的有效水平:
>
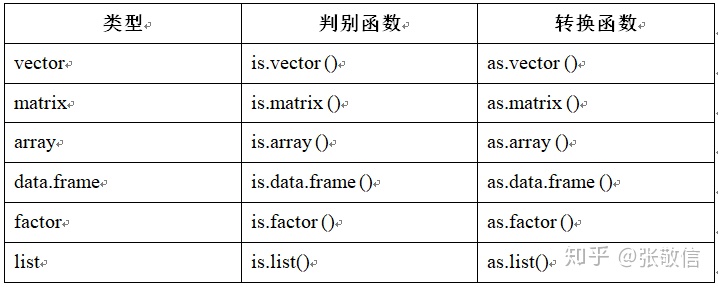
附
数据结构的判别与转换
主要参考文献:
[1] 任坤,R语言编程指南. 人民邮电出版社, 2017.
[2] R for Data Science. Hadley Wickham, Garrett Grolemund,O’Reilly, 2017.
原创作品,转载请注明。