Zookeeper 是由 Java 编写,运行在 JVM ,所以需要提前安装 JDK 运行环境;
01 JDK 安装与配置
1. 下载 JDK
可以到官网下载对应版本的 jdk,这里选择安装 jdk1.8 版本,并上传至 /home/hadoop/app 目录下

2. 解压 JDK
通过 tar -zxvf 命令对 jdk 安装包进行解压即可


3. 创建软连接
如果有多个版本 JDK ,我们后面如果要换版本,我们的 jdk 都要改,为了方便版本的更换和学习使用,可以创建 jdk 软连接指向 jdk 真实安装路径。可以使用如下命令:
ln -s jdk1.8.0_251 jdk
-
1

4. 配置环境变量的两种方式
-
1)修改 /etc/profile
-
如果你的计算机仅仅作为开发使用时推荐使用这种方法,因为所有用户的 shell 都有权限使用这些环境变量,但是可能会给系统带来安全性问题,因为这里是针对所有的用户的,所有的 shell。
-
>>> vi /etc/profile
JAVA_HOME=/home/hadoop/app/jdk
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:/home/hadoop/tools:$PATH
export JAVA_HOME CLASSPATH PATH
>>> source /etc/profile
-
1
-
2
-
3
-
4
-
5
-
6
-
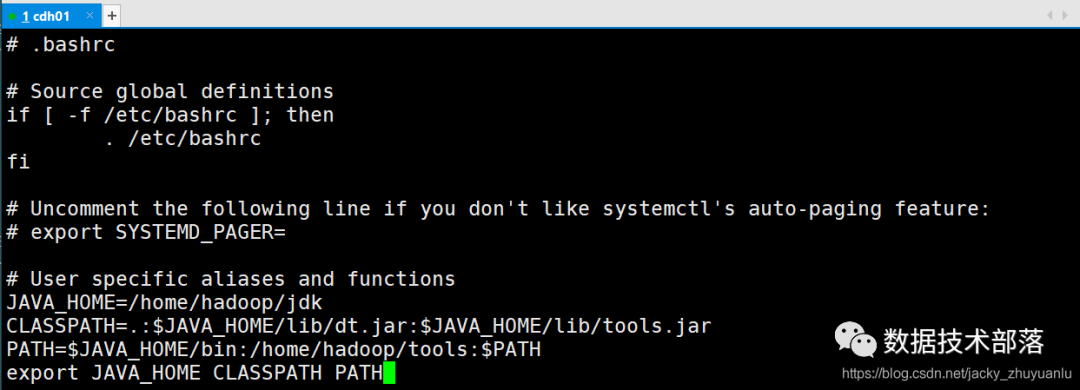
2 )修改 .bashrc 文件
-
这种方法更为安全,它可以把使用这些环境变量的权限控制到用户级别,这里是针对某一个特定的用户,如果你需要给某个用户权限使用这些环境变量,你只要修改其个人用户主目录下的 .bashrc 文件就可以了。
-
vi ~/.bashrc
JAVA_HOME=/home/hadoop/jdk
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:/home/hadoop/tools:$PATH
export JAVA_HOME CLASSPATH PATH
-
1
-
2
-
3
-
4
-
5

5. 让配置生效
source ~/.bashrc
-
1
02 Zookeeper 安装与配置
1. 下载 Zookeeper
Apache 版本下载地址:下载地址
CDH 版本下载地址:下载地址
下载对应版本 Zookeeper,这里下载 zookeeper-3.4.5-cdh5.10.0.tar.gz 版本,并上传至 /home/hadoop/app 目录下。
2. 上传、解压、创建软连接
同第一步部分 JDK

3. 修改 zoo.cfg 配置文件
zoo.cfg
#每个tick的毫秒数,每个确认消息持续2秒,等待应答。
tickTime= 2000
#初始同步阶段,可以发送的确认的最大的同步消息的数量
initLimit = 10
#发送请求并获得确认之间可以在两者之间传递的最大tick滴答数
#也就是同步消息的最大数量
syncLimit= 5
#存储快照数据的目录。后期搭建集群,可以在data文件夹保存myid文件,存储服务器编号。
# 数据目录要提前创建 (这里配置是重点)
dataDir= /home/hadoop/data/zookeeper/zkdata
# 日志目录需要提前创建
dataLogDir=/home/hadoop/data/zookeeper/zkdatalog
#客户端连接的端口,可以修改,默认是2181
clientPort=2181
#最大客户端连接数。控制连接并发sh
#如果需要处理更多客户端连接,可以增加此值
#maxClientCnxns= 60
#
#一定要阅读的维护部分
#谨慎开启自动数据清理功能。
#
#http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
#要在dataDir中保留的快照数量
#autopurge.snapRetainCount= 3
#以小时为单位清除任务时间间隔
#设置为“0”以禁用自动清除功能
#autopurge.purgeInterval= 1
#Cluster 集群模式的配置,3个节点,2个端口分别用于节点通信和集群选举
server.1=cdh01:2888:3888
server.2=cdh02:2888:3888
server.3=cdh03:2888:3888
-
1
-
2
-
3
-
4
-
5
-
6
-
7
-
8
-
9
-
10
-
11
-
12
-
13
-
14
-
15
-
16
-
17
-
18
-
19
-
20
-
21
-
22
-
23
-
24
-
25
-
26
-
27
-
28
-
29
-
30
-
31
-
32
4. 创建规划的目录
mkdir -p /home/hadoop/data/zookeeper/zkdata
mkdir -p /home/hadoop/data/zookeeper/zkdatalog
-
1
-
2
5. 修改每个节点服务编号
分别到各个节点,进入 /home/hadoop/data/zookeeper/zkdata 目录,创建文件 myid,里面内容分别填充为:1、2、3

6. 测试运行 zookeeper
./zkServer.sh start