MobileNet v3论文原地址:
该架构在一定程度上是通过自动网络架构搜索(NAS)找到的。
1.亮点
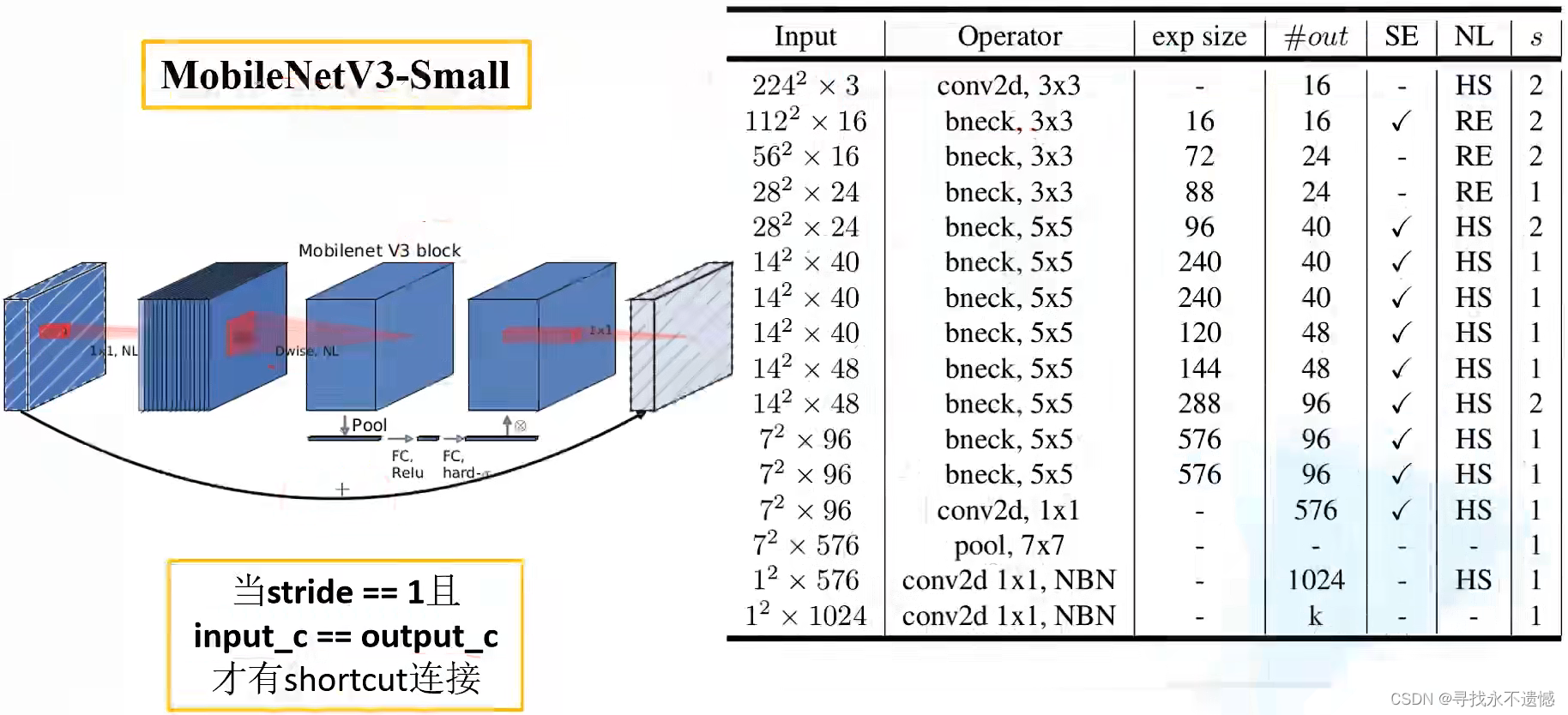
论文推出两个版本:Large 和 Small,分别适用于不同的场景;
使用NetAdapt算法获得卷积核和通道的最佳数量;
继承V1的深度可分离卷积与V2的具有线性瓶颈的残差结构;
更新block结构:引入SE通道注意力结构;
使用了一种新的激活函数hard-swish(x)代替Relu6;使用了Relu6(x + 3)/6来近似SE模块中的sigmoid。
2.block


上面两张图是MobileNetV2和MobileNetV3的网络块结构。通道可分离卷积+SE通道注意力机制+残差连接,可以看出,MobileNetV3是综合了以下三种模型的思想:MobileNetV1的深度可分离卷积(depthwise separable convolutions)、MobileNetV2的具有线性瓶颈的逆残差结构(the inverted residual with linear bottleneck)和MnasNet的基于SE结构的轻量级注意力模型。
此处更新的激活函数在图中用NL(非线性)统一表示,因为用到的激活函数不一样,主要有hardswish、relu两种。
最后那个
1x1
降维投影层用的是线性激活(f(x)=x),也可以理解为没用激活。
SE模块理解
SE模块类似于一个注意力模块,以在Mobilenetv3中的应用为例进行理解,如下图所示。

ReLu6和hardswish激活函数理解
ReLu6激活函数如下图所示,相当于加了个最大值6进行限制。

利用近似操作模拟swish
![]()

这种非线性在保持精度的情况下带了了很多优势,首先ReLU6在众多软硬件框架中都可以实现,其次量化时避免了数值精度的损失,运行快。这一非线性改变将模型的延时增加了15%。但它带来的网络效应对于精度和延时具有正向促进,剩下的开销可以通过融合非线性与先前层来消除。
3. 网络结构的改进

MobileNetV2模型中反转残差结构和变量利用了1*1卷积来构建最后层,以便于拓展到高维的特征空间,虽然对于提取丰富特征进行预测十分重要,但却引入了二外的计算开销与延时。为了在保留高维特征的前提下减小延时,将平均池化前的层移除并用1*1卷积来计算特征图。特征生成层被移除后,先前用于瓶颈映射的层也不再需要了,这将为减少10ms的开销,在提速15%的同时减小了30ms的操作数。
在MobileNetV2中,在全局平均池化层之前,是一个1 × 1卷积,将通道数从320扩展到1280,因此我们就能得到更高维度的特征,供分类器层使用。 这样做的好处是,在预测时有更多更丰富的特征来满足预测,但是同时也引入了额外的计算成本与延时。
所以,需要改进的地方就是要保留高维特征的前提下减小延时。
在MobileNetV3中,这个1 x 1卷积层位于全局平均池化层的后面,因此它可用于更小的特征图,因此速度更快。这样使我们就能够删除前面的bottleneck层和depthwise convolution层,而不会降低准确性。
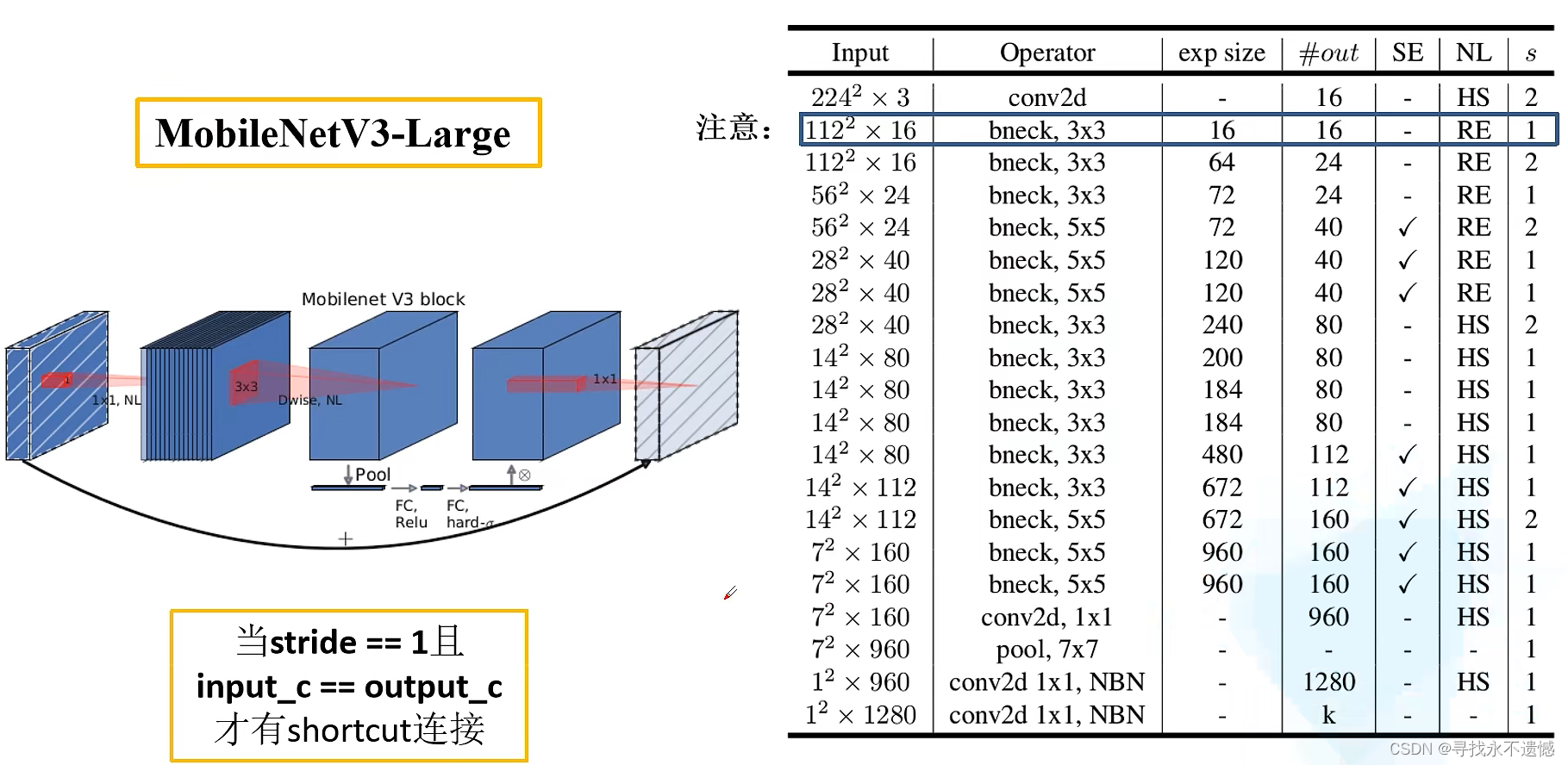
4. MobileNet v3网络结构
- Input表示输入尺寸
- Operator中的NBN表示不使用BN,最后的conv2d 1×1相当于全连接层的作用
- exp size表示bottleneck中的第一层1×1卷积升维,维度升到多少(第一个bottleneck没有1×1卷积升维操作)
- out表示bottleneck输出的channel个数
- SE表示是否使用SE模块
- NL表示使用何种激活函数,HS表示HardSwish,RE表示ReLu
- s表示步长(s=2,长宽变为原来一半)
5. 创新点理解
重新设计了耗时层
:MobileNet v1和v2都从具有32个滤波器的常规3×3卷积层开始,然而实验表明,这是一个相对耗时的层,只要16个滤波器就足够完成对224 x 224特征图的滤波。虽然这样并没有节省很多参数,但确实可以提高速度;
使用H-wish而不是ReLU6
:作者发现,h-swish仅在更深层次上有用, 此外,考虑到特征图在较浅的层中往往更大,因此计算其激活成本更高,所以作者选择在这些层上简单地使用ReLU(
而非ReLU6
),因为它比h-swish省时。
参考:
【论文学习】轻量级网络——MobileNetV3终于来了(含开源代码)
仅作为学习记录,侵删!