首先打开网址:https://www.elastic.co/cn/
进入如下页面:
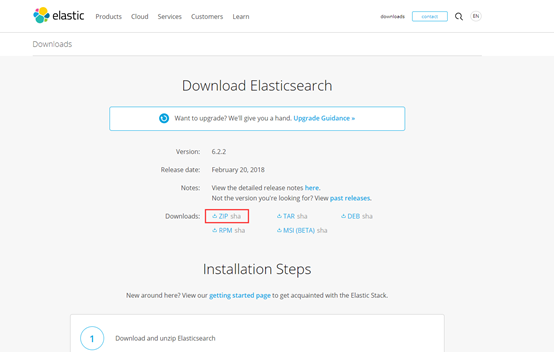
下载:

解压:

进入bin文件夹下,运行bat文件:

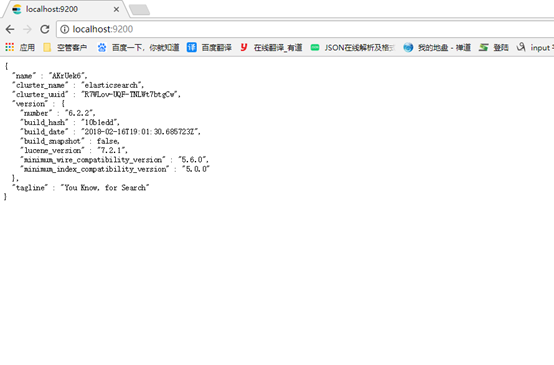
成功后打开浏览器输入地址:
安装head插件:
首先安装node.js:https://nodejs.org/en/download/
安装完成后:node -v

安装grunt:npm install -g grunt-cli
安装完成后:grunt -version
进入conf文件夹,修改elasticsearch.yml文件:
放开cluster.name;node.name;http.port的注释
放开network.host: 192.168.0.1的注释并改为network.host: 127.0.0.1
在文件最后加入
http.cors.enabled: true
http.cors.allow-origin: “*”
node.master: true
node.data: true
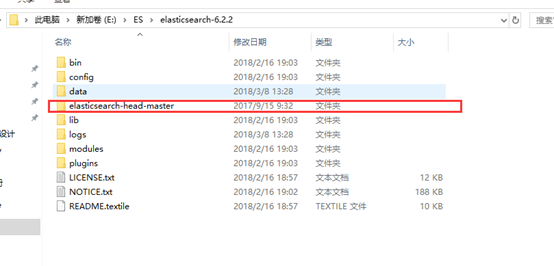
到https://github.com/mobz/elasticsearch-head 下载zip文件

解压到es文件夹下:
修改Gruntfile.js

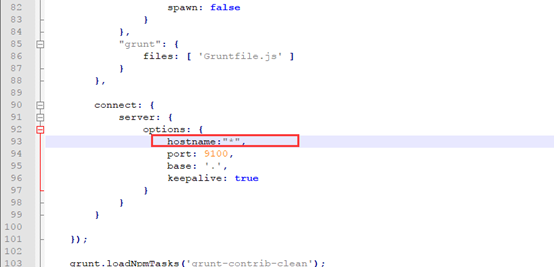
添加主机:
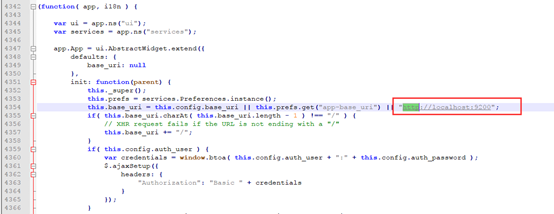
进入app.js修改服务器地址:
如果是在本机部署,则可不修改此项
cmd 进入elasticsearch-head-master文件夹
执行npm install
等待安装完成
执行bin目录下elasticsearch.bat启动es,cmd进入elasticsearch-head-master文件夹执行grunt server 或者npm run start
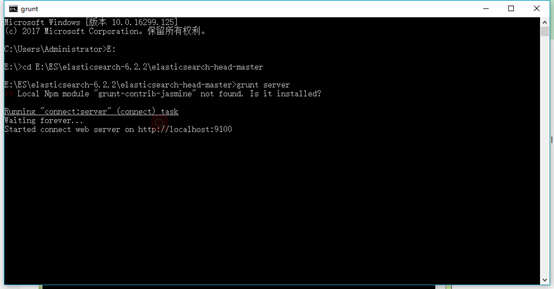
打开浏览器:
配置Windows下ES集群
把es解压后的文件夹复制两份分别命名


修改conf文件夹下的elasticsearch.yml文件:
node1的配置信息:
cluster.name: my-application #集群名称,保证唯一
node.name: node-1 #节点名称,必须不一样
network.host: 127.0.0.1 #ip地址
http.port: 9200 #服务端口号,在同一机器下必须不一样
transport.tcp.port: 9300 #集群间通信端口号,在同一机器下必须不一样
#设置集群自动发现机器ip集合
discovery.zen.ping.unicast.hosts: [“127.0.0.1:9300”, “127.0.0.1:9301”, “127.0.0.1:9302”]
node2的配置信息:
cluster.name: my-application #集群名称,保证唯一
node.name: node-2 #节点名称,必须不一样
network.host: 127.0.0.1 # ip地址
http.port: 9201 #服务端口号,在同一机器下必须不一样
transport.tcp.port: 9301 #集群间通信端口号,在同一机器下必须不一样
#设置集群自动发现机器ip集合
discovery.zen.ping.unicast.hosts: [“127.0.0.1:9300”, “127.0.0.1:9301”, “127.0.0.1:9302”]
node3的配置信息:
cluster.name: my-application #集群名称,保证唯一
node.name: node-3 #节点名称,必须不一样
network.host: 127.0.0.1 # ip地址
http.port: 9202 #服务端口号,在同一机器下必须不一样
transport.tcp.port: 9302 #集群间通信端口号,在同一机器下必须不一样
#设置集群自动发现机器ip集合
discovery.zen.ping.unicast.hosts: [“127.0.0.1:9300”, “127.0.0.1:9301”, “127.0.0.1:9302”]
分别启动三个节点,启动head插件查看:
不成功?删掉之前各个es文件夹下的data文件夹

重新启动:mast节点按照启动顺序自动分配
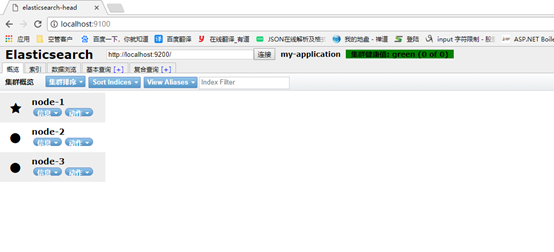
配置成功。
ES中建表测试:
ES版本:

通过postman请求:

返回true,通过head插件查看:
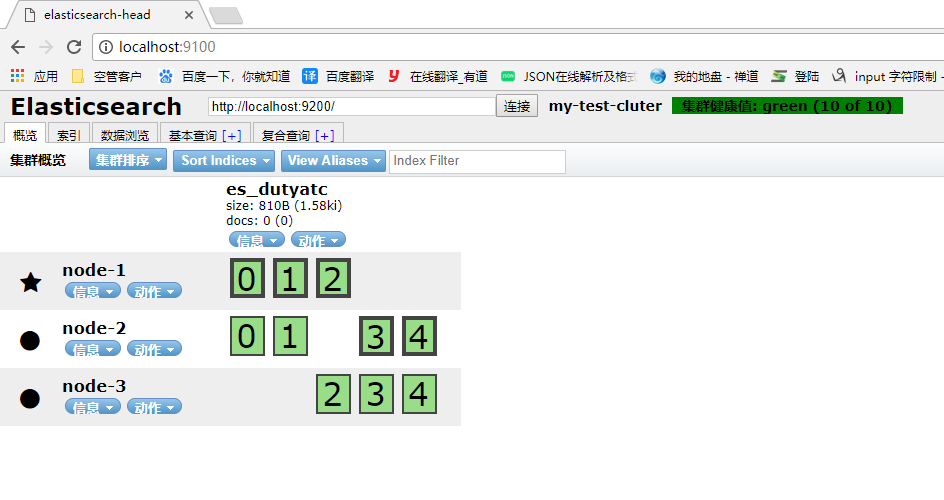
属性说明:
properties表示表的字段
- type字段类型,所有得字段都设置成了string,是因为在查询和编码过程中,有些类型不能很好的被转换,例如boolean
- store是否存储,属性有yes或者no,无论那种属性都会被存储,但如果设置成no,在查询的时候是无法用此属性作为查询项的,基于拓展和业务方便维护,建议使用yes
- index是否索引,属性有not_analyzed(分词不分析)、analyzed(分词分析)、no(不分析不分词)
- analyzer使用哪种分词器,在安装es的时候会自己安装分词器,例如IK分词器,在此指定分词的时候使用的是哪种分词器
- search_analyzer使用哪种分词器,但不是在入库的时候,而是在做查询的时候使用哪种分词器
- ignore_above对超过 ignore_above 的字符串,analyzer 不会进行处理;所以就不会索引起来。导致的结果就是最终搜索引擎搜索不到了。这个选项主要对 not_analyzed 字段有用,这些字段通常用来进行过滤、聚合和排序。而且这些字段都是结构化的,所以一般不会允许在这些字段中索引过长的项。
- format日期格式要求,例如设置为”yyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis”
dynamic表示是否使用动态映射,属性有
- true默认值,动态添加字段
- false忽略新字段
- strict如果碰到陌生字段,抛出异常
settings表示设置
num_of_shards设置分片数量,默认为5
num_of_replicas设置副本数量,默认为1
删除索引:

使用postman添加数据:
使用PUT:

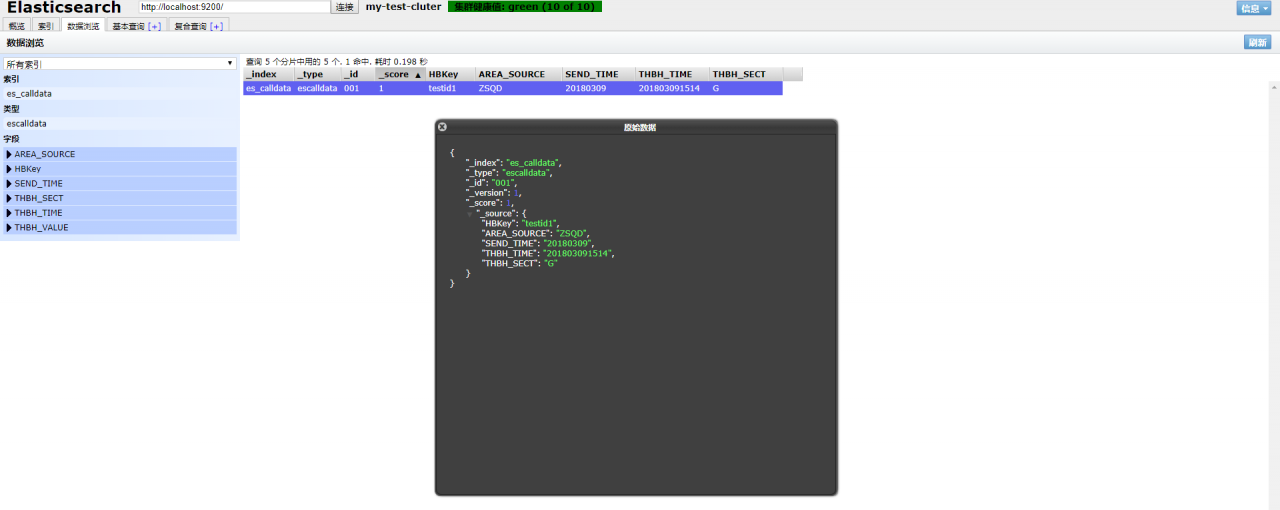
postman GET查询:
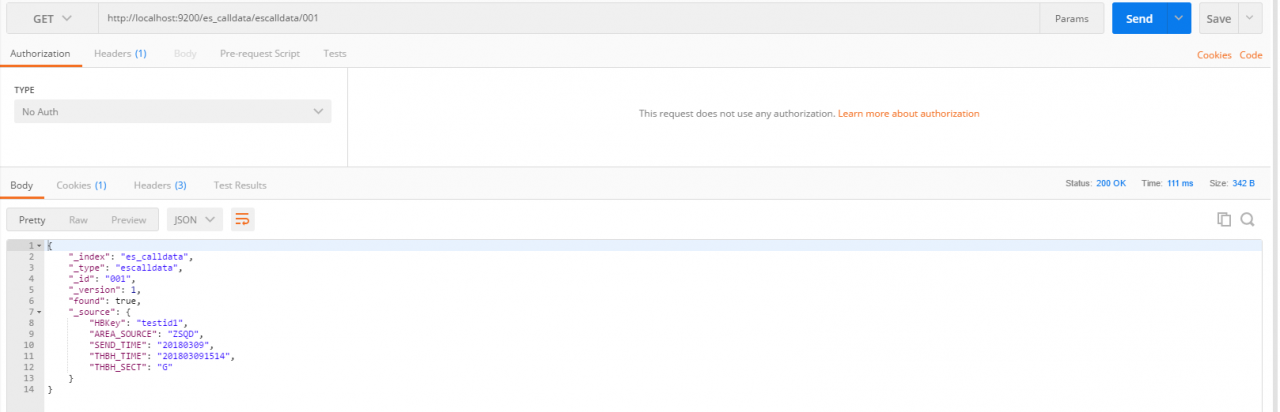
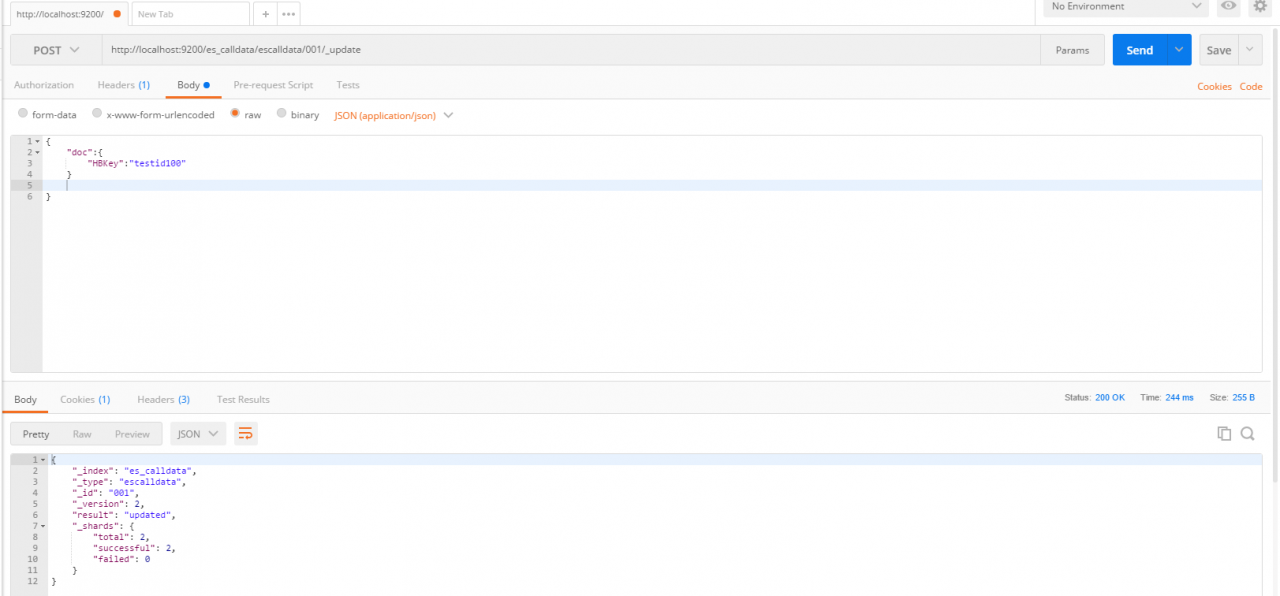
修改:
转载于:https://www.cnblogs.com/MrZheng/p/8529375.html