sql索引–Index
索引的作用
在数据库中,对某字段添加索引后,会对该列的字段值进行排序,形成目录,从而能够提高查询效率。
数据库中的索引类比于新华字典的目录。
索引提高查询效率的原理(索引使用的数据结构)
给某字段添加索引后,会对该列的值进行排序,形成目录,这个目录其实是一种数据结构–B+TREE,该数据结构就可以提高该字段的查询效率。
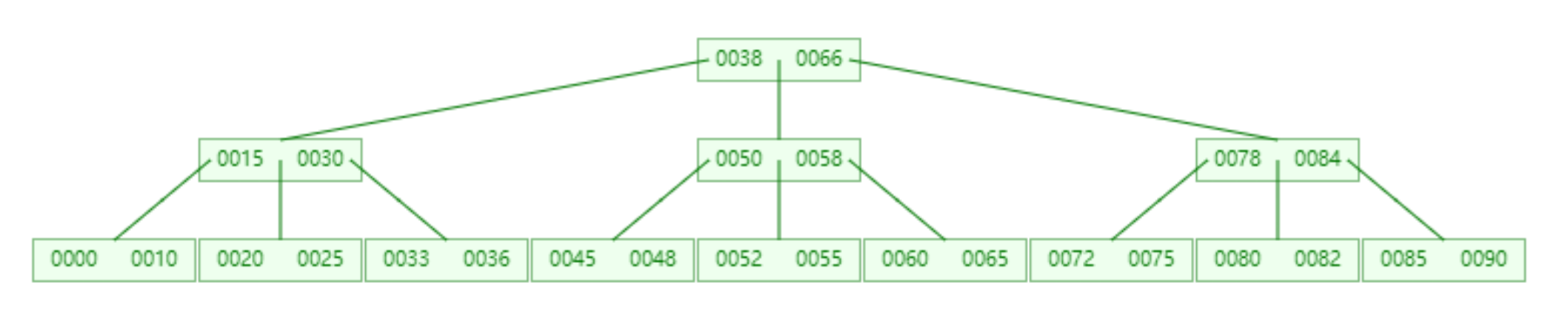
BTree数据结构
数据结构可视化网址:https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
BTree:设置好度为n后,添加元素时,会实现排序,以数据块的形式保存元素,每个数据块中最多能保存n-1个元素,当数据块中的元素数量达到n时,此时会进行分裂提取,将数据块最中间的元素提取到上一级数据块中,左右两侧分裂为2个数据块。
优点:查询效率高
树的专业术语
高度:树的层次
度:degree 树中所有节点的最大子节点数
叶子节点:度为0的节点
根节点:一棵树中有且仅有一个根节点
B+Tree数据结构
B+Tree是从BTree发展而来的。
-
对存入的元素进行排序,设置好度n后,每个数据块中最多保存n-1个元素,当数据块中的元素数量达到n时,进行分裂提取–分裂提取时:
- 若从叶子节点数据块进行分裂提取,则提取的元素依然会留在叶子数据块中
-
若从非叶子节点数据块进行分裂提取,则提取的元素不再留在原数据块中
– 以上做法的意义:查找的元素一定位于叶子节点中,非叶子节点的作用就是目录,提高查询效率。
-
B+TREE叶子节点数据块之间通过链表进行维护,目的是为了提高区域范围内元素的查询效率。
叶子节点数据块之间链表的作用:为了提高区域范围内数据的查询效率。eg:查询70-76之间的所有数据

索引底层实现就是B+Tree
给某列添加索引后,会对该列的值进行排序,形成目录(B+TREE),目录会保存到磁盘上,后续用于提高查询效率。
形成索引会耗费比较长的时间(正常的),将形成的索引(即B+TREE)保存到磁盘上,后续若要根据该字段查询数据时,使用索引查询,对磁盘进行3此IO操作,会大大的提高查询效率。
若顺序查找该字段的某个值,每次从数据库查询一条数据,都是对磁盘进行IO操作,所以若从数据库中顺序查找元素,会进行若干次磁盘IO操作,和索引的3次IO操作相对比,索引的查询效率要远远高于顺序查找。
索引能提高查询效率的根本原因
降低磁盘IO操作
索引的高度会固定为3,则从索引中查询元素会进行3次磁盘IO操作,每次读取到数据块后,会将数据块缓存到内存中,接下来对内存进行IO操作来确定查询元素所处的数据块,每次读取数据块都会缓存到内存中,进行内存IO操作,从而大大降低磁盘IO操作,从而提高查询效率.
若从数据量大的表中顺序查询数据,每次读取一条数据,均是一次磁盘IO操作,则最次的情况,查询会经过n此磁盘IO,而磁盘IO的时间级别为ms级别,内存IO的时间级别为ns级别。
磁盘IO操作时间级别: ms级别
内存IO操作时间级别: ns级别
索引的分类
- 聚集索引(主索引):给主键添加的索引,叫做聚集索引
- 非聚集索引(辅助索引):给非主键字段添加的索引,叫做非聚集索引
聚集索引:
mysql5.5版本开始,数据库存储引擎为了Innodb
Innodb存储引擎:
1. 该存储引擎支持事务和行锁
2. 会自动给表的主键添加聚集索引,若表中没有主键,此时Innodb会默认给添加了unique约束的字段添加索引,若表中没有主键,且没有添加了unique约束的字段,此时Innodb会自动给该表添加一个默认的主键,该主键类型为long,长度为6,直接给该主键添加聚集索引。
注意点:Innodb存储引擎会自动给表中的主键,添加了unique约束的字段,添加了外键约束(不建议使用/严禁使用)的字段添加索引。
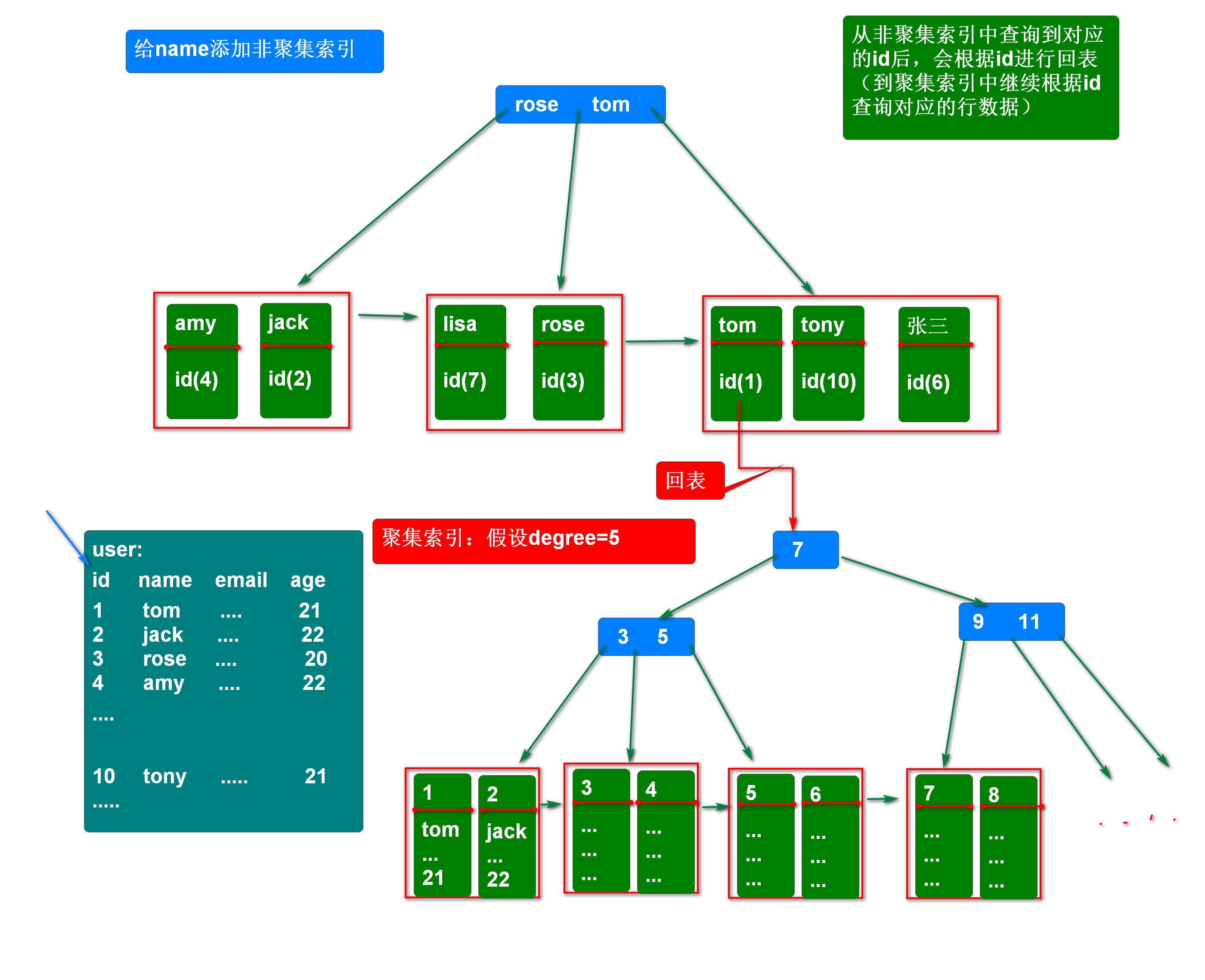
索引的底层实现为B+Tree,但是在叶子数据块中保存的是键值对数据
索引叶子数据块中的键值对数据
聚集索引:key–主键值 value – 行数据
非聚集索引: key–添加了索引的字段的值 value–主键值
索引的适用场景
- 当表中数据量大时,建议使用索引,可以提高查询效率;但是若表中数据量小时,不建议使用索引,因为创建索引所消耗的时间反而会比顺序查找的时间更长。
- 添加索引的字段:通常会选择作为查询条件的字段,给其添加索引
- 若作为查询条件的某字段值会被频繁的修改(增删改),不建议给该字段添加索引,因为每修改字段值后,索引会重建,反而会降低效率。
- 表中的索引并不是越多越好,通常情况下,表中索引最好不要超过6个
索引的sql操作
查询某表中的索引: show index from table_name
创建索引: create index index_name on table_name(col);
删除索引: drop index index_name on table_name
索引失效的场景
索引失效是指:因为一些不当操作,导致进行全表扫描,而不适用索引,这种情况我们叫做索引失效。
使用索引时sql语句要避免的情况:
1.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描
2.应尽量避免在 where 子句中使用!=操作符,否则将引擎放弃使用索引而进行全表扫描
3.应尽量避免在 where 子句中使用 or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描
4.not in 也要慎用,否则会导致全表扫描,in并不会导致索引失效
5.尽量避免在where子句中对字段使用like左侧模糊查询,会导致全表扫描
6.应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描
eg: select…from user where age+4>12
7.应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描
eg:select…from …where avg(score)>…
使用索引注意事项:
索引并不是越多越好,索引固然可以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率,因为 insert 或 update 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。一个表的索引数最好不要超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有必要。
常见面试题:如何提高sql查询效率
- 尽量使用联查,避免使用嵌套查询
- 尽量不要使用*
- 表数据量大时,添加索引来提高查询效率,但是需要注意,不要添加索引失效的场景,否则索引会失效。
索引注意事项
使用索引时sql语句要避免的情况:
1.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描
2.应尽量避免在 where 子句中使用!=操作符,否则将引擎放弃使用索引而进行全表扫描
3.应尽量避免在 where 子句中使用 or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描
4.not in 也要慎用,否则会导致全表扫描
5.尽量避免在where子句中对字段使用like左侧模糊查询,会导致全表扫描
6.应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描
7.应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描
使用索引注意事项:
索引并不是越多越好,索引固然可以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率,因为 insert 或 update 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。一个表的索引数最好不要超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有必要。