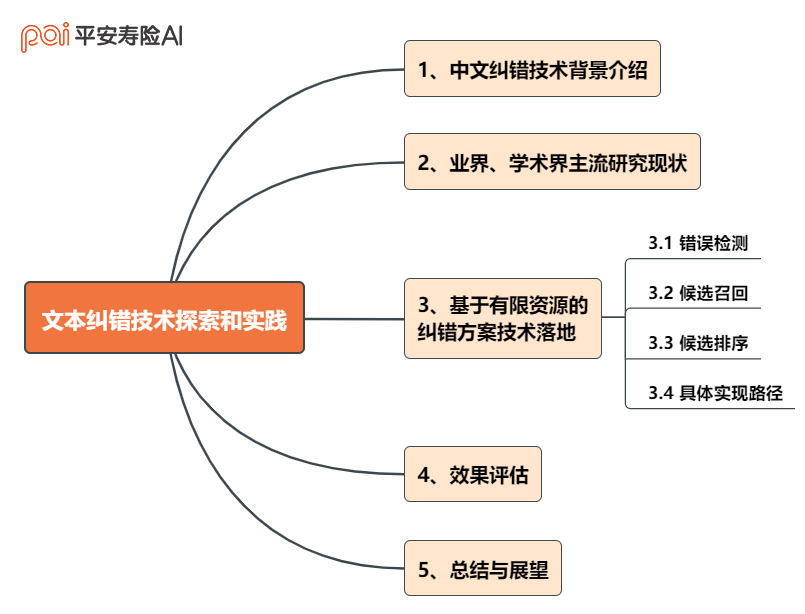
全文框架概览
一、背景与意义
中文纠错技术
是实现中文语句自动检查、自动纠错的一项重要技术,其目的是提高语言正确性的同时减少人工校验成本。
纠错模块
作为自然语言处理最基础的模块,其重要程度不言而喻。
在日常生活中,我们经常会在微信、微博等社交工具或公众号文章中发现许多错别字。我们在几个方面对文本出错概率进行了统计:在微博等新媒体领域中,文本出错概率在2%左右;在语音识别领域中,出错率最高可达8-10%;而在平安人寿问答领域中,用户提问出错率在去重后仍高达9%。
在平安人寿问答领域的用户问题中,我们发现多种类型错误。其中占比最高的错误是语言转化和发音不标准的错误,占错误总量的50%。比如一款保险产品“少儿平安福”被语言识别转化为“少儿平安符”、“飞机”因方言差异被读成“灰机”、“难受想哭”变成“难受香菇”等。
占比第二高的错误类型是拼写错误,占错误总量的35%。这些错误主要发生在通过拼音、五笔和手写输入文本的场景。比如“眼镜蛇”-“眼睛蛇”、“缺铁性贫血”-“缺铁性盆血”等。剩余的错误我
版权声明:本文为weixin_35645460原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。