文章目录
前言: 为什么看源码
类比的例子:
python的机器学习算法库.scikit-learn中的一个函数

函数全部代码:
def fit(self, X, y, sample_weight=None):
"""
Fit the model according to the given training data.
Parameters
----------
X : {array-like, sparse matrix} of shape (n_samples, n_features)
Training vector, where n_samples is the number of samples and
n_features is the number of features.
y : array-like of shape (n_samples,)
Target vector relative to X.
sample_weight : array-like of shape (n_samples,) default=None
Array of weights that are assigned to individual samples.
If not provided, then each sample is given unit weight.
.. versionadded:: 0.17
*sample_weight* support to LogisticRegression.
Returns
-------
self
Fitted estimator.
Notes
-----
The SAGA solver supports both float64 and float32 bit arrays.
"""
solver = _check_solver(self.solver, self.penalty, self.dual)
if not isinstance(self.C, numbers.Number) or self.C < 0:
raise ValueError("Penalty term must be positive; got (C=%r)"
% self.C)
if self.penalty == 'elasticnet':
if (not isinstance(self.l1_ratio, numbers.Number) or
self.l1_ratio < 0 or self.l1_ratio > 1):
raise ValueError("l1_ratio must be between 0 and 1;"
" got (l1_ratio=%r)" % self.l1_ratio)
elif self.l1_ratio is not None:
warnings.warn("l1_ratio parameter is only used when penalty is "
"'elasticnet'. Got "
"(penalty={})".format(self.penalty))
if self.penalty == 'none':
if self.C != 1.0: # default values
warnings.warn(
"Setting penalty='none' will ignore the C and l1_ratio "
"parameters"
)
# Note that check for l1_ratio is done right above
C_ = np.inf
penalty = 'l2'
else:
C_ = self.C
penalty = self.penalty
if not isinstance(self.max_iter, numbers.Number) or self.max_iter < 0:
raise ValueError("Maximum number of iteration must be positive;"
" got (max_iter=%r)" % self.max_iter)
if not isinstance(self.tol, numbers.Number) or self.tol < 0:
raise ValueError("Tolerance for stopping criteria must be "
"positive; got (tol=%r)" % self.tol)
if solver == 'lbfgs':
_dtype = np.float64
else:
_dtype = [np.float64, np.float32]
X, y = self._validate_data(X, y, accept_sparse='csr', dtype=_dtype,
order="C",
accept_large_sparse=solver != 'liblinear')
check_classification_targets(y)
self.classes_ = np.unique(y)
multi_class = _check_multi_class(self.multi_class, solver,
len(self.classes_))
if solver == 'liblinear':
if effective_n_jobs(self.n_jobs) != 1:
warnings.warn("'n_jobs' > 1 does not have any effect when"
" 'solver' is set to 'liblinear'. Got 'n_jobs'"
" = {}.".format(effective_n_jobs(self.n_jobs)))
self.coef_, self.intercept_, n_iter_ = _fit_liblinear(
X, y, self.C, self.fit_intercept, self.intercept_scaling,
self.class_weight, self.penalty, self.dual, self.verbose,
self.max_iter, self.tol, self.random_state,
sample_weight=sample_weight)
self.n_iter_ = np.array([n_iter_])
return self
if solver in ['sag', 'saga']:
max_squared_sum = row_norms(X, squared=True).max()
else:
max_squared_sum = None
n_classes = len(self.classes_)
classes_ = self.classes_
if n_classes < 2:
raise ValueError("This solver needs samples of at least 2 classes"
" in the data, but the data contains only one"
" class: %r" % classes_[0])
if len(self.classes_) == 2:
n_classes = 1
classes_ = classes_[1:]
if self.warm_start:
warm_start_coef = getattr(self, 'coef_', None)
else:
warm_start_coef = None
if warm_start_coef is not None and self.fit_intercept:
warm_start_coef = np.append(warm_start_coef,
self.intercept_[:, np.newaxis],
axis=1)
# Hack so that we iterate only once for the multinomial case.
if multi_class == 'multinomial':
classes_ = [None]
warm_start_coef = [warm_start_coef]
if warm_start_coef is None:
warm_start_coef = [None] * n_classes
path_func = delayed(_logistic_regression_path)
# The SAG solver releases the GIL so it's more efficient to use
# threads for this solver.
if solver in ['sag', 'saga']:
prefer = 'threads'
else:
prefer = 'processes'
fold_coefs_ = Parallel(n_jobs=self.n_jobs, verbose=self.verbose,
**_joblib_parallel_args(prefer=prefer))(
path_func(X, y, pos_class=class_, Cs=[C_],
l1_ratio=self.l1_ratio, fit_intercept=self.fit_intercept,
tol=self.tol, verbose=self.verbose, solver=solver,
multi_class=multi_class, max_iter=self.max_iter,
class_weight=self.class_weight, check_input=False,
random_state=self.random_state, coef=warm_start_coef_,
penalty=penalty, max_squared_sum=max_squared_sum,
sample_weight=sample_weight)
for class_, warm_start_coef_ in zip(classes_, warm_start_coef))
fold_coefs_, _, n_iter_ = zip(*fold_coefs_)
self.n_iter_ = np.asarray(n_iter_, dtype=np.int32)[:, 0]
n_features = X.shape[1]
if multi_class == 'multinomial':
self.coef_ = fold_coefs_[0][0]
else:
self.coef_ = np.asarray(fold_coefs_)
self.coef_ = self.coef_.reshape(n_classes, n_features +
int(self.fit_intercept))
if self.fit_intercept:
self.intercept_ = self.coef_[:, -1]
self.coef_ = self.coef_[:, :-1]
else:
self.intercept_ = np.zeros(n_classes)
return self
1. Flask源码目录结构
flask-master源码目录(截止2021.1.3)

__init__.py: 构造文件, 导入所有其他模块中开放的类和函数

__main__.py: 启动flask命令
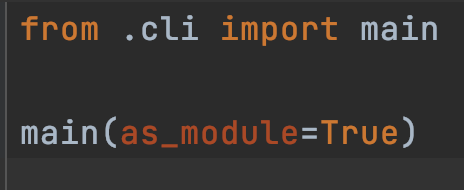
globals.py: 定义全局变量, 比如request, session等(都是代理对象提升为全局变量, 不会修改原对象)

helper.py: 一些常用的辅助函数, 如url_for()
templating.py: 模板渲染功能
testing.py: 用于测试的辅助函数
views.py: 提供类似Django中的类视图, 用于Web API的MethodView在这里定义

2. Flask的两个核心依赖包
Werkzeug: WSGI交互. 有些函数如redirect, abort直接从中引入
Jinja2: 模板引擎
3. 不同状态下的本地上下文
在请求处理中, 可以使用传参的方式, 将请求数据进行传递, 但会让逻辑冗余不易维护, 所以另一种方式是让其设为全局变量, 为了不同线程中不导致混乱, 引入了本地线程(thread locals). 使用的Werkzeug实现的werkzeug.local.Local()
当Flask类实例化
就进入了程序设置状态, 这是所有的全局对象都还没有绑定

当Flask启动, 但还没有请求进入时候
Flask进入了程序运行状态, 这时, 程序上下文对象current_app和g都已经绑定了各自对象.
可以尝试模拟这种状态:

当请求进入时
或是使用test_request_context()方法时, Flask会进入请求运行状态, 因为请求上下文被推送时, 程序上下文也会自动推送, 所以这个状态下, 4个全局对象都会被绑定

这就是为什么可以直接在视图函数和相应的回调函数里直接使用这些上下文对象, 而不用推送上下文, 因为Flask在处理请求时会自动推送请求上下文和程序上下文.(这里没有设置程序密钥, 所以session是无效session的NullSession类实例)
其中对应用到的函数


4. Flask的WSGI APP与Werkzeug的 WSGI Server的互相调用
Flask类是满足WSGI协议的WSGI APP, 负责与满足WSGI协议的Werkzeug这样的WSGI Server进行通信.
感兴趣可以了解WSGI协议的规定.
这里只放一个交互图


Flask提供的请求对象有对environ字典的解析的一些数据.
5. Flask工作流程
启动流程(flask run 或以前的app.run())
最终都会调用Werkzeug提供的run_simple()函数, 这就是WSGI Server.

run_simple函数中, 如果开启debug, 会通过DebuggedApplication为程序添加调试功能. 如果static_file是True, 同样使用中间件提供静态文件功能

开始对外提供服务
在最后inner(), 在其中会调用make_server()创建应用服务器, 调用serve_forever()方法运行服务器

当应用服务器接到请求后, 会调用可调用对象, 就是程序实例app. 这就是WSGI APP.
请求处理流程
Flask类实现了__call__()方法,.
这是WSGI协议中需要与WSGI协议服务器交互, WSGI应用类必须实现的方法, 没有理由, 协议规定.(或者不用类的__call__方法, 直接用函数的方式实现亦可.)

看一下实际中, environ和start_response是什么内容,
前者是WSGI服务器给WSGI应用的环境变量environ,
后者是WSGI应用要调用的WSGI服务器的响应返回的回调函数

在其中调用了wsgi_app方法, 其中try,except中的逻辑就是重点, , 它先尝试从Flask.full_dispatch_request()中获取响应, 如果出错, 根据错误类型生成错误响应

请求调度full_dispatch_request
发送请求进入信号
预处理请求
进一步处理请求, 获取返回值

preprocess_request()方法会对请求进行预处理, 在这里会执行所有before_request的钩子函数(如果有注册的话)

接着, 会在dispatch_request中根据注册的视图函数, 通过url匹配到对应的函数并且执行.

响应输出
最后调用finalize_request()函数生成响应,
make_response会创建响应对象

接着的process_response函数会在把响应发送给WSGI服务器前执行所有after_request钩子函数, 另外还会根据session设置cookie(如果需要的话)

最后回到wsgi_app()函数, 返回响应对象, WSGI把这个响应对象, 转换成HTTP请求发给客户端.

至此, 一个Flask请求-响应的流程就结束了.
6. 路由系统
flask的路由是基于Werkzeug中的Map实现的.
先看下Werkzeug如何实现

Flask中添加路由的实现

接下来可以看下如何匹配规则的, 每个map.bind(),都有一个MapAdapter对象, 负责匹配和构建URL


而flask的url_for()内部就是用MapAdapter的build()方法实现的


深入下去需要了解Werkzeug的内容, 路由暂且看到这里.
8. 理解本地上下文(*)
Flask提供2种上下文: 请求上下文 和 程序上下文.
这两种上下文分别包含request, session, 和 current_app, g这四个变量.
这些变量是实际对象Local()的本地代理LocalProxy(), 被称为本地上下文.
定义在globals.py.
LOCAL()
为保证多线程执行中, 数据不错乱, 引入了本地线程的概念, 在保存数据时, 记录线程ID, 获取时根据所在线程的ID获取对应的数据.
Local中构造函数定义了2个属性:
__storage__ 和 __ident_func__
其中__storage__是一个嵌套字典
外层的字典使用线程ID作为键来匹配内部的字典.
内部字典即真实对象.
{线程ID: {名称: 实际数据}}
为了保存请求相关信息, 但又不想通过函数传参的方式实现.

LocalStack()
上下文堆栈由Werkzeug提供的LocalStack类创建, 以栈的形式存放多个上下文对象Local().
为了支持多个程序.

LocalProxy()代理了Local()
代理是一种设计模式, 通过创建一个代理对象, 使用代理对象来操作实际对象. 代理是使用一个中间人来转发操作.
为了支持动态获取上下文对象.

代理对象可在线程间共享
请求上下文栈 _request_ctx_stack 与 应用上下文栈 _app_ctx_stack
请求上下文
把自己推入_request_ctx_stack栈中, 用top可以总是访问到当前栈最顶层的上下文.

应用上下文 也是同理, 把自己推入_app_ctx_stack栈中
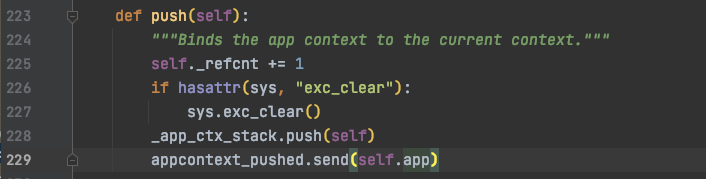

globals.py中定义了以上所有上下文变量.
验证LocalProxy()代理的request 与 Local()对象中原本的request的关系
current_app是LocalProxy()代理出来的, 其实就是当前应用上下文栈的top.app
其中LocalProxy()的传参需要时一个具有可调用的函数, 函数返回一个Local()对象.
当对比dir(current_app)和dir(_app_ctx_stack.top.app)时发现是一致的, 接下来继续证明他们操作的是完全相同的一个对象

这里直接访问current_app这个LocalProxy()的私有变量__local,这是一个可调用函数, 直接加括号()调用, 返回一个app对象, 就是压入应用栈的那个.

到这里, 即使不看请求上下文, 也可以猜到实现会一模一样的. 接下来再证明一下


上下文总结
(以下总结来自Flask框架官方开发人员GreyLi总结)
- 需要保存请求相关信息–>有了请求上下文
- 为了更好地分离程序的状态, 应用更加灵活–>有了程序上下文
- 为了让上下文对象可以全局动态访问, 而不用显式地传入视图函数, 同时确保线程安全–>有了本地线程(Local)
- 为了支持多个程序–> 有了本地堆栈(LocalStack)
- 为了支持动态获取上下文对象–>有了本地代理(LocalProxy)
9. 模板渲染
视图函数中, 可以使用render_template()函数来渲染模板, 传入模板名称和需要注入模板的关键字参数即可.
会创建Jinja2.


10. 可获取帮助