背景
众所周知,软件开发没有银弹,但总有一些经典的设计模式,可以在我们编程时作为方法论指导我们,避免我们日益复杂的业务逻辑变成一堆“大泥球”,比如说责任链模式,今天本文就聊一聊对于责任链模式应用的一些思考与改进。
本文不对责任链模式的定义再做赘述,直接贴一下维基百科的定义:
责任链模式
责任链基本应用
责任链模式的常见应用方式就是构建一个通用上下文(context),里面包含一些通用业务信息,然后将需要处理的数据传递给多个处理器(processor)组成的处理链处理,每个处理器按业务边界划分,职责尽量单一。每个processor处理结束后,将数据传递给下一个processor,中途processor可与context进行交互,拿到所需要的参数,如下图所示:
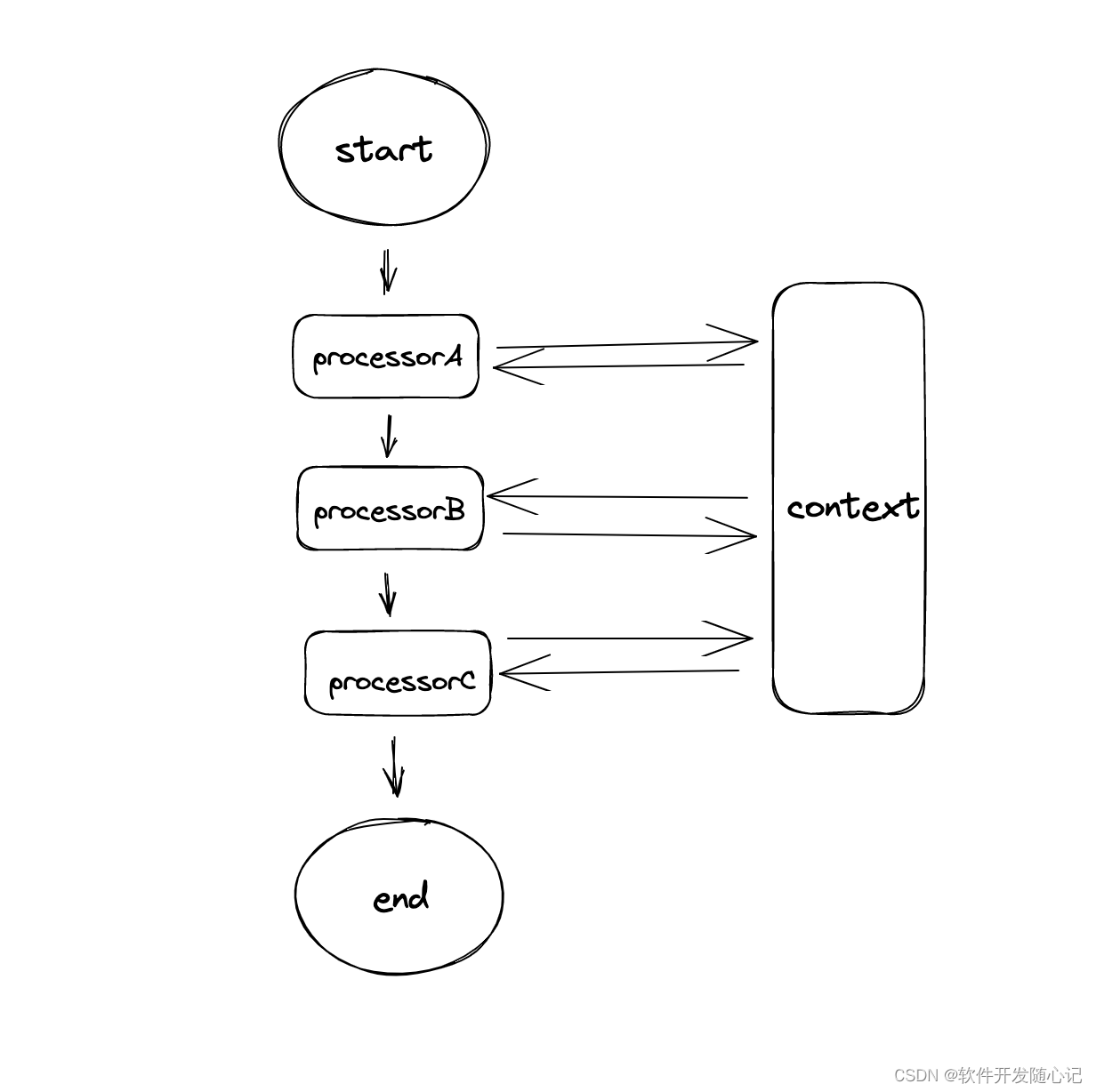
这样解构的好处是业务逻辑清晰,每个processor职责单一,方便复用,也利于扩展,符合开闭原则。
一些小问题:
但是在实际的使用当中我们往往会遇到一些小问题:
例如:
- 处理链路较长时,上下文容易膨胀,构建性能低下。
- 上下文中容易出现”幽灵字段”,即在processorA中往context中setAttr1(),在其他process中去获取,有时会发现某些值获取时还是为null,导致处理异常。
- 若是处理器拆分不够细,会导致单个处理器成为大泥球。
读扩散问题
对于上下文膨胀的问题,可能会有同学会提出,将业务信息都放到每个processor中去获取,这样可以做到随用随取,但是这样做也会导致多个processor重复去获取相同的字段,在processor较多的情况下,会造成数倍的读扩散。
膨胀的上下文
那么对于读扩散和上下文的构建性能,这里是否真的就无法两全了呢?
也不尽然,我们还有一种常用的策略—懒加载。
懒加载是一种将资源标识为非阻塞(非关键)资源并仅在需要时加载它们的策略。
我们可以在构建上下文时,使用懒加载的策略,延迟构建,这样可以提高上下文的构建效率。
现实中可能会有多层依赖求值的场景,例如A→B→C,我们在获取C时,优先计算出A和B的值即可。
除了懒加载,我们还以利用缓存,进一步减少重复计算的请求。
关于如何使用java函数式编程优雅实现惰性求值,这里有一篇写的很好的文章可以参考:
https://zhuanlan.zhihu.com/p/428529310
消灭”幽灵字段”
其实“幽灵字段”出现的根源,还是源于context的不规范,对于上下文这种基础信息流,应当具有不可变性,即不允许在一个processor中set值,然后去另一个processor中获取。
假如有这种倾向,可以考虑:
1.应该将字段优先放在上下文中,
2.假使这个字段非常不通用,那么应该考虑将两个需要这个字段的processor合并,这两个processor应当是耦合的。
大泥球Processor
大泥球processor一般是业务不断迭代的结果,源源不断的业务逻辑涌入到单一的processor中,导致单个processor逻辑膨胀严重,再难以保证单个processor的原子性和职责单一。
这个问题其实很好办,再根据业务性质细分,将processor重构再细分processor就好了。
日益冗杂的代码就是腐败的温床,如若不及时处理,很可能就会在某天给你个大大的惊喜。
总结
设计模式是无数业务场景积累沉淀的方法论,值得我们不断借鉴和学习,我们也应在不断的实践当中去对经典的设计模式,做出符合时代的优化和改进。唯一不变的,只有改变。
—-by eric02.li