一、理论基础
多目标优化问题可以描述如下:
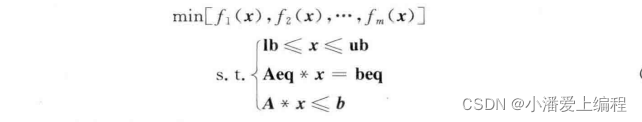
其中,f(x) 为待优化的
目标函数
;x 为
待优化的变量
;lb 和 ub 分别为
变量 x 的下限和上限约束
;Aeq * x = beq 为
变量 x 的线性等式约束
;A * x <= b 为
变量 x 的线性不等式约束
。

在上图所示的优化问题中,目标函数 f1 和 f2 是相互矛盾的。因为 A1 < B1 且 A2 > B2,也就是说,某一个目标函数的提高需要以另一个目标函数的降低作为代价,称这样的解 A 和解 B 是非劣解,或者说是
Pareto 最优解
。多目标优化算法的目的就是要寻找这些 Pareto 最优解。
目前的多目标优化算法有很多,Kalyanmoy Deb 的
带精英策略的快速非支配排序遗传算法
(nondominated sorting genetic algorithm II,NSGA- II)无疑是其中应用最为广泛也是最为成功的一种。MATLAB R2009a 版本提供的
函数 gamultiobj
所采用的算法就是基于 NSGA – II 改进的一种多目标优化算法(a variant of NSGA – II)。本案例将以函数 gamultiobj 为基础,对基于遗传算法的多目标优化算法进行详细分析,并介绍函数gamultiobj的使用。
1、支配(dominnate)与非劣(non – inferior)
在多目标优化问题中,如果个体 p 至少有一个目标比个体 q 的好,而且个体 p 的所有目标都不比个体 q 的差,那么称个体 p 支配个体 q(p dominates q),或者称个体 q 受个体 p 支配(qis dominated by p),也可以说,个体 p 非劣于个体 q(p is non – inferior to q)。
2、序值(rank)和前端(front)
如果 p 支配 q,那么 p 的序值比 q 的低。如果 p 和 q 互不支配,或者说, p 和 q 相互非劣,那么 p 和 q 有相同的序值。序值为 1 的个体属于第一前端,序值为 2 的个体属于第二前端,依次类推。显然,在当前种群中,第一前端是完全不受支配的,第二前端受第一前端中个体的支配。这样,通过排序,可以将种群中的个体分到不同的前端。
3、拥挤距离(crowding distance)
拥挤距离用来计算某前端中的某个体与该前端中其他个体之间的距离,用以表征个体间的拥挤程度。显然,拥挤距离的值越大,个体间就越不拥挤,种群的多样性就越好。需要指出的是,只有处于同一前端的个体间才需要计算拥挤距离,不同前端之间的个体计算拥挤距离是没有意义的。
4、最优前端个体系数(ParetoFraction)
最优前端个体系数定义为最优前端中的个体在种群中所占的比例,即最优前端个体数 = min { ParetoFraction * 种群大小,前端中现存的个体数目 },其取值范围为 0~1。需要指出的是,ParetoFraction 的概念是函数 gamultiobj 所特有的,在 NSGA – II 中是没有的,这也是为什么称函数 gamultiobj 是一种多目标优化算法的原因。
二、案例简述
1、问题描述
待优化的多目标问题表述如下:

2、解题思路及步骤
这里将使用函数 gamultiobj 求解以上多目标优化问题。同函数 ga 的调用一样,函数 gamultiobj 的调用方式也有两种:
GUI 方式和命令行方式
。
通过 GUI 方式调用 gamultiobj
通过以下两种方式可以调出函数 gamultiobj 的 GUI 界面:
(1)在 MATLAB主界面上依次单击 APPS→Optimization,在弹出的 Optimization Tool 对话框的 Solver 中选择 “gamultiobj – Multiobjective optimization using Genetic Algorithm” 。
(2)在 Command Window 中输入:optimtool(‘gamultiobj’) 命令
可以看到,函数 gamultiobj 的 GUI 界面与函数 ga 的 GUI 界面大致相同,仅在以下几个方面
存在区别
:
(1)前者比后者多了 Distance measure function 和 Pareto front population fraction 两个参数。
(2)前者比后者少了参数 Elite count,这是因为函数 gamultiobj 的精英是自动保留的;前者比后者少了 Scaling function,这是因为函数 gamultiobj 的选择是基于序值和拥挤距离的,故不再需要 Scaling 的处理;函数 gamultiobj 没有非线性约束。
(3)绘图函数不同及下列设置的默认值不同;种群大小(Population size)、选择函数(Selection function)、交叉函数(Crossover function)最大进化代数(Generations)停止代数(Stall generations)适应度函数值偏差(Function tolerance)。
通过命令行方式调用函数 gamultiobj
gamultiobj 的命令行调用格式为:
[x, fval] = gamultiobj(fitnessfcn, nvars, A, b, Aeq, beq, lb, ub, options)
其中,
x 为函数 gamultiobj 得到的 Pareto 解集
;
fval 为 x 对应的目标函数值
;
fitnessfcn 为目标函数句柄
,同函数 ga 一样,需要编写一个描述目标函数的 M 文件;nvars 为变量数目;A、b、Aeq、beq 为线性约束,可以表示为 A * x <= B,Aeq * x = beq;lb,ub为上、下限约束,可以表述为 lb <= x <= ub,当没有约束时,用 “ [ ] ” 表示即可;
options 中需要对多目标优化算法进行一些设置
,即
options = gaoptimset('Param1', value1, 'Param2', value2, ... );
其中,Param1,Param2 等是需要设定的参数,如
最优前端个体系数、拥挤距离计算函数、约束条件、终止条件
等;valuel,value2 等是 Param 的具体值。Param 有专门的表述方式,如最优前端个体系数对应于 ParetoFraction,拥挤距离计算函数对应于 DistanceMeasureFcn 等。
三、MATLAB 程序实现
1、使用函数 gamultiobj 求解多目标优化问题
(1)使用函数 gamultiobj 求解多目标优化问题的第一步是编写目标函数的M文件。对于以上问题,函数名为my_first_multi,目标函数代码如下:
function f = my_first_multi(x)
f(1) = x(1)^4 - 10*x(1)^2+x(1)*x(2) + x(2)^4 - (x(1)^2)*(x(2)^2);
f(2) = x(2)^4 - (x(1)^2)*(x(2)^2) + x(1)^4 + x(1)*x(2);(2)使用命令行方式调用 gamultiobj 函数,代码如下:
clear
clc
fitnessfcn = @my_first_multi; % Function handle to the fitness function
nvars = 2; % Number of decision variables
lb = [-5,-5]; % Lower bound
ub = [5,5]; % Upper bound
A = []; b = []; % No linear inequality constraints
Aeq = []; beq = []; % No linear equality constraints
options = gaoptimset('ParetoFraction',0.3,'PopulationSize',100,'Generations',200,'StallGenLimit',200,'TolFun',1e-100,'PlotFcns',@gaplotpareto);
[x,fval] = gamultiobj(fitnessfcn,nvars, A,b,Aeq,beq,lb,ub,options);
其中,fitnessfcn 即(1)中定义的目标函数 M 文件,设置的
最优前端个体系数 ParetoFrac -tion
为 0.3,
种群大小 PopulationSize
为 100,
最大进化代数 Generations
为 200,
停止代数StallGenLimit
也为 200,
适应度函数值偏差 TolFun
为 le – 100,
绘制 Pareto 前端
。当然,也可以通过 GUI 方式调用函数 gamultiobj,其方法与函数 ga 的调用相同。
2、结果分析
可以看到,在基于遗传算法的多目标优化算法的运行过程中,自动绘制了第一前端中个体的分布情况,且分布随着算法进化一代而更新一次。当迭代停止后,得到如下图所示的
第一前端个体分布图
。

同时, Worksapce 中返回了函数 gamultiobj 得到的 Pareto 解集 x 及与 x 对应的目标函数值。需要说明的是,由于算法的初始种群是随机产生的,因此每次运行的结果不一样。
从上图可以看到,第一前端的 Pareto 最优解分布均匀。返回的 Pareto 最优解个数为 30 个,而种群大小为 100,可见,
ParetoFraction 为 0.3 的设置发挥了作用
。另外,个体被限制在了 [ -5,5 ] 的上下限范围内。