我们项目中用到groovy去做爬虫,这也是我第一次学习爬虫和groovy,毕竟jvm语言学习发现和java还是很像的,相关资料网上都能搜到,这里整理了我实际项目中遇到的问题和解决的大致思路(附代码)
我们项目中是要从12315爬取客诉数据,通过jsoup拿到指定html表格页面数据然后通过list打入我们系统内部,这几步很常见就不说了。
然后主要的坑是在登录的场景,登录需要用户名+密码+验证码,登录后拿取cookie,之后爬接口用这个cookie就行了,用户名密码都有了,这么第一步就是获取验证码
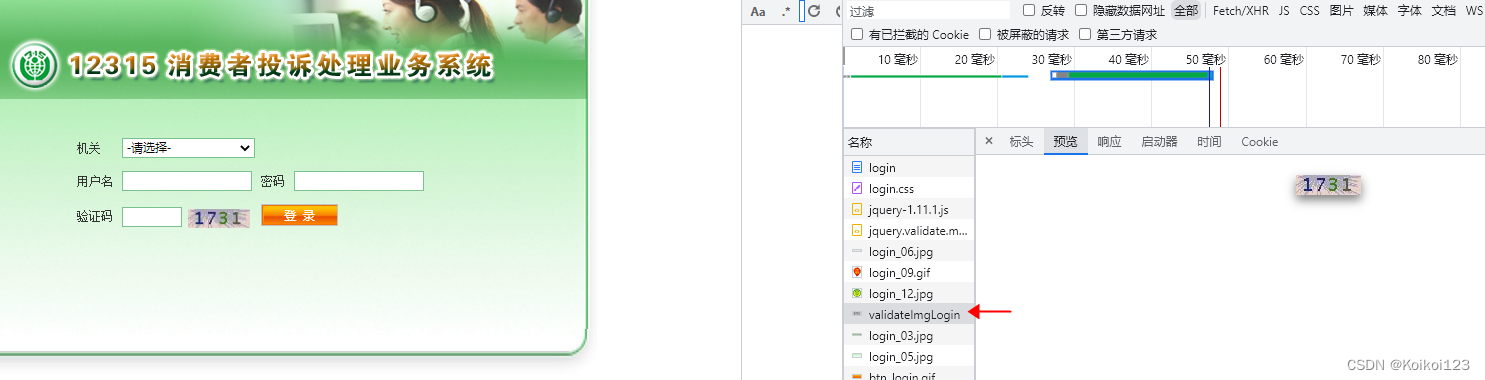
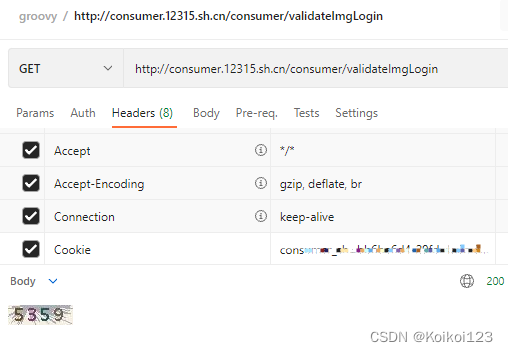
其实就是走get请求拿到图片文件,一开始我用共用httpUtil走获取失败,发现了第一个坑,原因在于postman等都是自动转成文件,代码里直接走get请求行不通,所以我的解决办法是需要走IO获取文件并落地
失败案例
static String imgCodeReload(String cookie) {
String url = "http://consumer.12315.sh.cn/consumer/validateImgLogin";
HttpUtil httpUtil = HttpUtil.newHttp();
httpUtil.addHeaders("Cookie", cookie);
httpUtil.addHeaders("Accept", "*/*");
Map<String, String> configs = new HashMap<>();
HttpUtil.Response response = httpUtil.get(url, configs)
String content = response.content;
return content;
}
成功转file获取
/**
* 下载文件
* @param url
* @param dest
* @return
*/
static String downloadFileAndGetCode(String cookie, String url) {
//def fos = new FileOutputStream(dest)
File file = getImgPath();
def fos = new FileOutputStream(file);
def out = new BufferedOutputStream(fos)
//必须带cookie拿到图片文件,否则登录不通过
out << getInputStream(cookie,url) //<< new URL(url).openStream()
fos.close();
out.close()
String orcText = ""
int count = 0
//重试三次,图片识别有误判几率会读出2313.和23o1
while ((!isNumeric(orcText) || orcText.length() != 4) && count++ < 3) {
orcText = CommonUtils.getImgOcrText("https://xxxxxxx.com/fileUpload/singleUpload", file, "eng");
orcText = orcText.replaceAll("\r|\n*", "")
System.out.println(orcText);
}
file.delete();
return orcText;
}
static File getImgPath() {
File dirFile = new File(".jpg");
if (!dirFile.exists()) {
dirFile.mkdirs();
}
return new File(dirFile, CommonUtils.createId() + ".jpg");
}
static boolean isNumeric(String str) {
if (str == "") return false
Pattern pattern = Pattern.compile("[0-9]*");
return pattern.matcher(str).matches();
}
public static InputStream getInputStream(String cookie,String urlReq) {
InputStream inputStream = null;
HttpURLConnection httpURLConnection = null;
try {
URL url = new URL(urlReq);//创建的URL
if (url != null) {
httpURLConnection = (HttpURLConnection) url.openConnection();//打开链接
httpURLConnection.setConnectTimeout(3000);//设置网络链接超时时间,3秒,链接失败后重新链接
httpURLConnection.setDoInput(true);//打开输入流
httpURLConnection.setRequestMethod("GET");//表示本次Http请求是GET方式
httpURLConnection.setDoOutput(true)
DataOutputStream outStream = new DataOutputStream(httpURLConnection.getOutputStream());
outStream.write(cookie.getBytes());
int responseCode = httpURLConnection.getResponseCode();//获取返回码
if (responseCode == 200) {//成功为200
inputStream = httpURLConnection.getInputStream();
}
}
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return inputStream
}
CommonUtils.getImgOcrText()
是我们图片识别的SDK,这里不方便展示
这一步其实就是落地,相对路径创建目录
static File getImgPath() {
File dirFile = new File(".jpg");
if (!dirFile.exists()) {
dirFile.mkdirs();
}
return new File(dirFile, CommonUtils.createId() + ".jpg");
}
这一步做验证,因为12315的验证码场景比较简单,是4位纯数字,这里是做了图片识别会有误判的情况下,做了重试机制,具体处理还是得按照自己的OCR服务来做调整
static boolean isNumeric(String str) {
if (str == "") return false
Pattern pattern = Pattern.compile("[0-9]*");
return pattern.matcher(str).matches();
}
这一步是重点,为了能让URL带cookie获取文件,需要使用IO流传入cookie的字节
public static InputStream getInputStream(String cookie,String urlReq) {
InputStream inputStream = null;
HttpURLConnection httpURLConnection = null;
try {
URL url = new URL(urlReq);//创建的URL
if (url != null) {
httpURLConnection = (HttpURLConnection) url.openConnection();//打开链接
httpURLConnection.setConnectTimeout(3000);//设置网络链接超时时间,3秒,链接失败后重新链接
httpURLConnection.setDoInput(true);//打开输入流
httpURLConnection.setRequestMethod("GET");//表示本次Http请求是GET方式
httpURLConnection.setDoOutput(true)
DataOutputStream outStream = new DataOutputStream(httpURLConnection.getOutputStream());
outStream.write(cookie.getBytes());
int responseCode = httpURLConnection.getResponseCode();//获取返回码
if (responseCode == 200) {//成功为200
inputStream = httpURLConnection.getInputStream();
}
}
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return inputStream
}
这里传入到BufferedOutputStream即可,注意这里最后要把落地的file删除
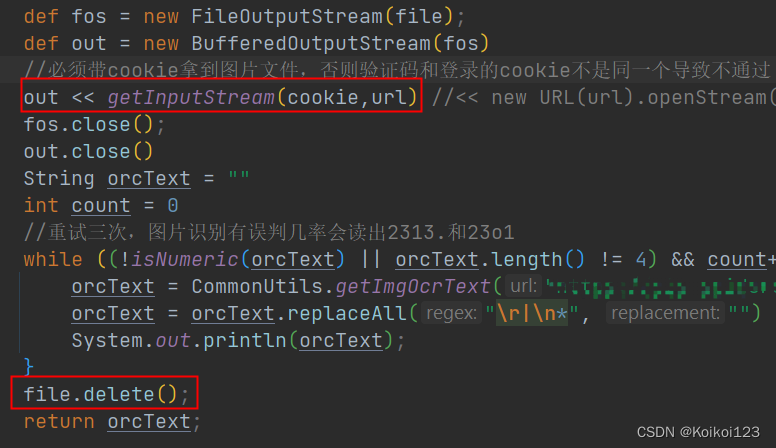
文件落地后效果如图,这就可以拿file文件去走图片识别的SDK了,然后如果代码发生异常,文件也会落地,而不会走
file.delete()
这一步,注意不要让应用内图片越堆越多,一定要
file.delete()
掉
上游调用代码,开始登录
static String loginOnAndGetCookie(String cookie,int i) {
String url = "http://consumer.12315.sh.cn/consumer/logon";
Map<String, String> args = new HashMap<>()
args.put("organId", "organId");
args.put("loginN", "user");
args.put("loginP", "password");
args.put("imgcode", downloadFileAndGetCode(cookie, "http://consumer.12315.sh.cn/consumer/validateImgLogin"));
HttpUtil httpUtil = HttpUtil.newHttp();
httpUtil.addHeaders("Cookie", cookie);
Map<String, String> configs = new HashMap<>();
HttpUtil.Response response = httpUtil.post(url, args, configs);
String content = response.content;
System.out.println(content)
Map<String, String> headers = response.headers;
String cookieReturn = headers.get("Set-Cookie").toString();
if (cookieReturn != null)
cookieReturn = cookieReturn.split("; ")[0];
System.out.println(cookieReturn)
if ("rememberMe=deleteMe".equals(cookieReturn)){
return cookie
}else if (cookieReturn.contains("consumer_sh=") && i==0) {
i++;
return loginOnAndGetCookie(cookieReturn,i)
}
return ""
}
这里递归走了两次是因为第一次调用拿到cookie,用于传了拿到验证码图片和登录用,第二次拿到的就是登陆后的cookie。具体判断是通过resp中header做的,属于特有场景
最后的上游方法就是爬取方法了,一个完整逻辑闭环
static def String process(String url, Map<String, String> args, CrawlerTask crawlerTask, org.dom4j.Document context, SpiderClient client) {
//args.put(HttpUtil.USER_AGENT,"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.94 Safari/537.36");
//if (url==null){
//}
url = "http://consumer.12315.sh.cn/consumer/accuse/queryResult";
String endTime = new SimpleDateFormat("yyyy-MM-dd").format(new Date());
SimpleDateFormat df = new SimpleDateFormat("yyyy-MM-dd");
Date dtDate = df.parse(endTime);
//设置抓3天数据,防止job停止漏一天
Calendar calendar = Calendar.getInstance();
calendar.setTime(dtDate);
calendar.add(Calendar.DAY_OF_MONTH, -3);
dtDate = calendar.getTime();
String startTime = new SimpleDateFormat("yyyy-MM-dd").format(dtDate);
args.put("currentPage", "1");
args.put("cnnAppCondition.startDate", startTime);
args.put("cnnAppCondition.endDate", endTime);
def logList = [];
def rsList = [];
HttpUtil httpUtil = HttpUtil.newHttp();
String newCookie = loginOnAndGetCookie("",0)
if (newCookie=="") logList.add("cookie get fail!!!")
httpUtil.addHeaders("Cookie", newCookie);
Map<String, String> configs = new HashMap<>();
String content = httpUtil.post(url, args, configs).content;
Document doc = Jsoup.parse(content, url);
def element = doc.select("table").first();
System.out.println(element);
if (element != null) {
def els = element.select("tr");
for (i in 1..<els.size()) {
Elements ele = els.get(i).select("td");
rsList.add(["numNo" : ele.get(1).text().toString()
, "date" : ele.get(2).text().toString()
, "name" : ele.get(3).text().toString()
, "category": ele.get(5).text().toString()]);
}
} else {
logList.add("element null!!!")
}
return JSON.toJSONString(["rs": rsList, "log": logList]);
}