消息队列是一种
系统间相互协作的通信机制
,使用消息队列的场景一般有
异步处理、解耦、流量削峰、日志收集、事务最终一致性
这几种,
主要解决
诸如
消息堆积、消息持久化、可靠投递、消息重复、严格有序、集群
等各种问题,目前的消息中间件种类有很多,比如ActiveMQ/RabbitMQ/RocketMQ/Kafka,
我司使用的中间件为包裹RockerMQ的ZMQ,以及用于日志收集的kafka
,本文分析了这几种中间件的特点,并结合公司使用情况,重点阐述RocketMQ的使用。
文章目录
-
-
-
推荐书籍
-
0、为什么学习MQ?
-
1、MQ的使用场景?
-
2、该如何选择消息队列?
-
3、消息模型:主题和队列有什么区别
-
4、RocketMQ 系统架构(重点)
-
5、MQ使用规范
-
6、RocketMQ工作原理
-
7、MQ如何整合到spring中去?
-
8、消息的模式?
-
10、mq如何避免重复提交/消息丢失的问题?
-
11、AcitveMQ的作用、原理、特点?(生产者。消费者。 p2p、订阅实现流程)
-
12、ActiveMQ在项目中如何应用的?(deprecated)
-
13、消息队列 参考资料:亿级流量网站架构核心技术 张开涛
-
15、MQ,如何做到==消息必达==? 消息的补发重传解决思路?**20181222**
-
16、MQ、如何做到消息幂等? 幂等性的解决思路?20181222(任意多次执行所产生的影响均与一次执行的影响相同)
-
17、MQ、如何做到延时消息?
-
18、MQ、如何做到流量控制? 消息的堆积解决思路?20181222
-
19、了解哪些消息队列,及其对比?
-
20、ActiveMQ 如果数据提交不成功怎么办?
-
21、ActiveMQ消息是被顺序接受的吗?如果不是,如何确保它具有顺序的消息?如何保证消息的有序性?20181222
-
22、MQ集群部署?
-
23、MQ的持久化存储方案(被政采云问到了)
-
24、RocketMq的存储机制?(消息的存储和发送)
-
25、RabbitMQ 由Erlang语言开发 端口号5672 (out)
-
26、Rocketmq的事务消息,问了TCC?
-
27、列举一个常用的消息中间件,如果消息要==保序==如何实现? 政采云问到了
-
28、Mq的持久化机制
-
29、RocketMQ项目实战`在这里插入代码片`
-
30、高级功能和源码分析
-
31、Kafka消息中间件+Flink实时计算框架
-
32、RocketMQ常见面试题
-
33、MQ踩坑review
-
34、MQ 开发规范
-
-
推荐书籍
《消息队列高手课》
《分布式消息中间件实战(倪炜)沈剑》
《架构师之路》
《分布式消息队列RocketMQ》
GItHub官网
0、为什么学习MQ?
首先
:MQ属于微服务级系统间的观察者模式,它可以被用于实现服务的异步处理,让结果更快地返回,减少等待,提升系统总体的性能;
其次
:我们在单体应用里面需要用队列解决的问题,在分布式系统中大多都可以用消息队列来解决;
最后
:学习MQ同步转异步,多应用解耦合的思想
1、MQ的使用场景?
流量控制
- MQ可以将系统的超量请求暂存其中,以便系统后期可以慢慢进行处理,从而避免了请求的丢失或系统被压垮。
-
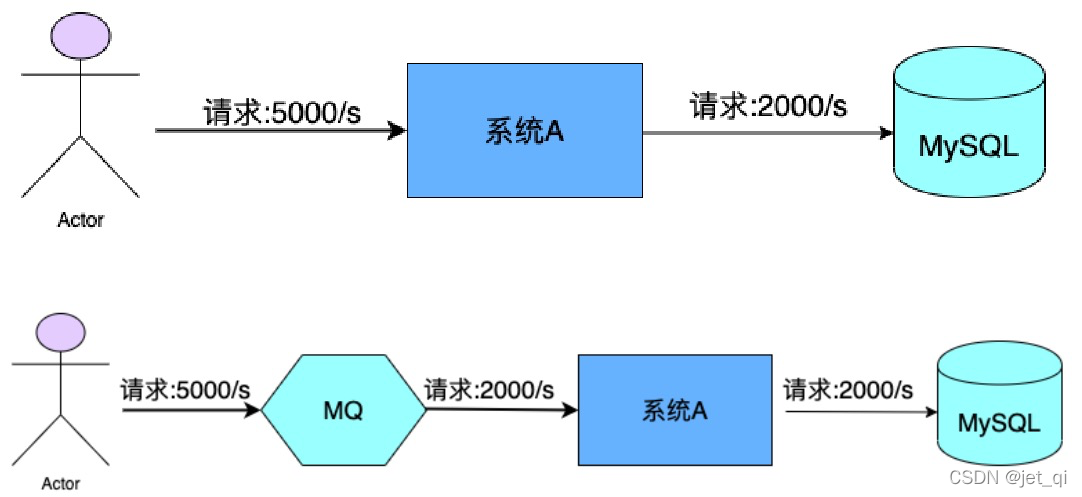
异步处理
-
上游系统对下游系统的调用若为
同步调用
,则会大大降低系统的吞吐量与并发度,且系统耦合度太高。而异步调用则会解决这些问题。所以
两层之间若要实现由同步到异步的转化,一般性做法就是,在这两层间添加一个MQ层
。 - 秒杀系统
服务解耦
- 引入消息队列后,上游服务在业务变化时发送一条消息到消息队列的一个主题中,所有下游系统都订阅该主题。无论增加、减少下游系统或是下游系统需求如何变化,上游系统都无需做任何更改,实现了上游服务与下游服务的解耦。
-
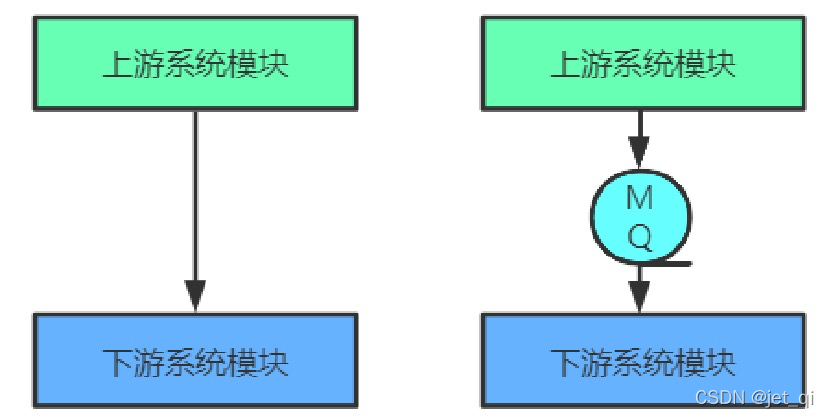
缺点:
①系统可用性降低
- 系统引入的外部依赖越多,越容易挂掉
②系统复杂度提升
- 怎么保证消息没有重复消费?怎么处理消息丢失的情况?怎么保证消息传递的顺序性?问题一大堆
③一致性问题
- A系统处理完直接返回成功了,就以为这个请求就成功了;但要是BCD 三个系统那里,BD 两个系统写库成功了,结果 C 系统写库失败了,咋整。
使用推荐
-
结论:调用方
实时
依赖执行结果的业务场景,请使用调用,而不是MQ
2、该如何选择消息队列?
2.1、该如何选择消息队列?
1、必须是开源的产品,这个非常重要;
2、这个产品必须是近年来比较流行并且有一定社区活跃度的产品;
3、消息的可靠传递:确保不丢消息;
4、支持集群,确保不会因为某个节点宕机导致服务不可用,当然也不能丢消息;
5、性能:具备足够好的性能,能满足绝大多数场景的性能要求。
2.2、常见的MQ产品
ActiveMQ
- ActiveMQ是使用Java语言开发一款MQ产品。早期很多公司与项目中都在使用。但现在的社区活跃度已经很低。现在的项目中已经很少使用了。
RabbitMQ
- RabbitMQ是使用ErLang语言开发的一款MQ产品。其吞吐量较Kafka与RocketMQ要低,且由于其不是 Java语言开发,所以公司内部对其实现定制化开发难度较大。
Kafka
- Kafka是使用Scala/Java语言开发的一款MQ产品。其最大的特点就是高吞吐率,常用于大数据领域的实时计算、日志采集等场景。其没有遵循任何常见的MQ协议,而是使用自研协议。对于Spring Cloud Netçix,其仅支持RabbitMQ与Kafka。
RocketMQ
- RocketMQ是使用Java语言开发的一款MQ产品。经过数年阿里双11的考验,性能与稳定性非常高。其没有遵循任何常见的MQ协议,而是使用自研协议。对于Spring Cloud Alibaba,其支持RabbitMQ、Kafka,但提倡使用RocketMQ。
对比
| 关键词 | ACTIVEMQ | RABBITMQ | KAFKA | ROCKETMQ | Pulsar |
|---|---|---|---|---|---|
| 开发语言 | Java | ErLan 语言非常难学 | Java | Java | – |
| 单机吞吐量 | 万级 | 万级 | 十万级 |
十万级 |
– |
| 产生时间 | 2007 | – | 2012 | 2017 | 2018 |
| 贡献公司 | Apache | – | 阿里巴巴 | 雅虎 | |
| 特性 | (1)支持协议众多:AMQP, STOMP, MQTT, JMS (2)消息是持久化的JDBC | – | (1)超高写入速率(2)end-to-end耗时毫秒级 |
(1)万亿级消息支持,(2)万亿Topic数量支持(3)end-to-end 耗时毫秒级 |
(1)存储和计算分离(2)支持SQL数据查询 |
| 商业公司实践 | 国内部分企业 | – | 阿里巴巴 | 雅虎、腾讯、智联招聘 | |
| 容错 | 无重试机制 | – | 无重试机制 |
支持重试,死信消息 |
支持重试,死信消息 |
| 顺序消息 | 支持 | 支持 | 支持 | 支持 | 支持 |
| 定时消息 | 不支持 | 支持 | 不支持 | 支持 | 支持 |
| 消息查询 | 数据库中查询 | – | 不支持 | 支持 | 支持SQL |
| Topic | – | – | 百级Topic时会影响系统吞吐量 |
千级Topic时会影响系统吞吐量 |
|
| 社区活跃度 | 低 | 高 | 高 | 高 | 低 |
| 使用建议 | 无论是功能还是性能方面,与后面消息队列差异巨大,不推荐 |
RabbitMQ 对 消息堆积 的支持并不好 |
Kafka 与周边生态系统的兼容性是最好的没有之一,尤其在 大数据和流计算领域 ,几乎所有的相关开源软件系统都会优先支持 Kafka,由于异步批量的设计,Kafka不太适合在线业务场景 |
如果你的 应用场景很在意响应时延 ,那应该选择使用 RocketMQ |
Pulsar 采用存储和计算分离的设计 |
| 适用场景 | – | RabbitMQ 支持优先级队列 | kafka 更加擅长于日志、大数据计算、流式计算等场景 | RocketMQ 提供了消息重试、消息过滤、消息轨迹、消息检索等功能特性,特别是 RocketMQ 的消息检索功能,因此 RocketMQ 很适合核心业务场景 | – |
Action
1、一套架构中是否可能存在多套中间件?在线的生产业务使用rocketmq,运维/监控方面使用kafka。
- 当然可以,架构无所谓好坏,关键是适合。用多套MQ好处是发挥各自的长处,
- 代价是维护成本比较高。
2、RocketMQ是怎么做到低延时的?
-
主要是设计上的选择问题
,Kafka中到处都是“批量和异步”设计,它更关注的是整体的吞吐量,而RocketMQ的设计选择更多的是尽量及时处理请求。比如发消息,同样是用户调用了send()方法,RocketMQ它会直接把这个消息发出去,而Kafka会把这个消息放到本地缓存里面,然后择机异步批量发送。所以,RocketMQ它的时延更小一些,而Kafka的吞吐量更高。
3、每秒处理几万~几十万数据,是按照下游业务的消费能力还是指发送到消息队列的能力?还是只针下游业务只打个日志专门用来做性能测试的情况?
-
指消息队列本身的性能,不包括生产者和消费者处理各自业务逻辑的时间。
一般测试消息队列性能的时候,生产者和消费者是没有任何业务逻辑的
。
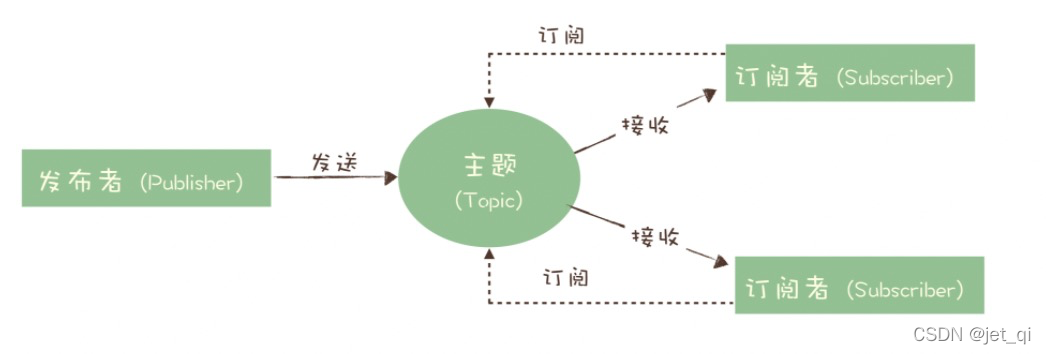
3、消息模型:主题和队列有什么区别
消息队列中像队列、主题、分区等基础概念。这些基础的概念,类似学习一门编程语言中的基础语法一样
到底什么是队列?什么是主题?主题和队列又有什么区别呢?
- 生产者就是发布者,消费者就是订阅者,队列就是主题,并没有本质的区别。
- 使用了观察者模式
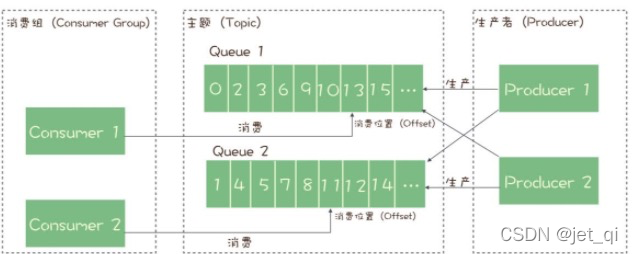
消息(Message)
:消息系统所传输信息的物理载体,生产和消费数据的最小单位,每条消息必须属于一个主题
主题(Topic)
:表示一类消息的集合,是RocketMQ进行消息订阅的基本单位。
- 一个生产者可以同时发送多种Topic的消息;而一个消费者只对某种特定的Topic感兴趣
标签(Tag)
:
用于同一主题下区分不同类型的消息
。即来自同一业务单元的消息,可以根据不同业务目的在同一主题下设置不同标签。
- Topic是消息的一级分类,Tag是消息的二级分类
队列(Queue)
: 存储消息的物理实体。
- 一个Topic中可以包含多个Queue,每个Queue中存放的就是该Topic的消息。一个Topic的queue也被称为一个Topic中消息的分区(Partition);
- 一个Topic的Queue中的消息只能被一个消费者组中的一个消费者消费。一个Queue中的消息不允许同一个消费者组中的多个消费者同时消费。
分片(Sharding)
: 在RocketMQ中,分片指的是存放相应 Topic 的 Broker。每个分片中会创建出相应数量的分区,即 Queue,每个Queue的大小都是相同的。
消息标识(MessageId/Key):
RocketMQ中每个消息拥有唯一的MessageId,且可以携带具有业务标识的Key,以方便对消息的查询。不过需要注意的是,MessageId有两个:在生产者send()消息时会自动生成一个MessageId(msgId),当消息到达Broker后,Broker也会自动生成一个MessageId(offsetMsgId)。msgId、offsetMsgId与key都称为消息标识。
RabbitMQ的消息模型
在 RabbitMQ 中,Exchange 位于生产者和队列之间,生产者并不关心将消息发送给哪个队列,而是将消息发送给 Exchange,由 Exchange 上配置的策略来决定将消息投递到哪些队列中。
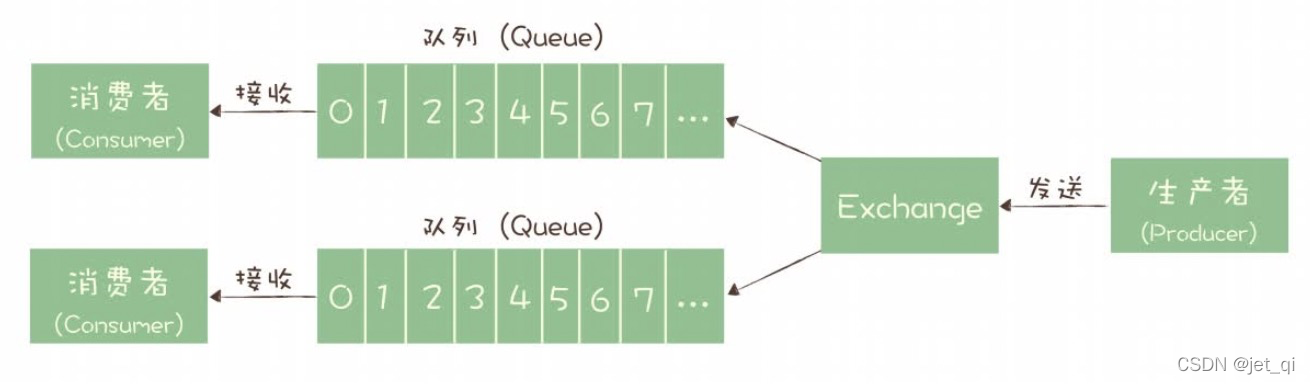
RocketMQ 的消息模型
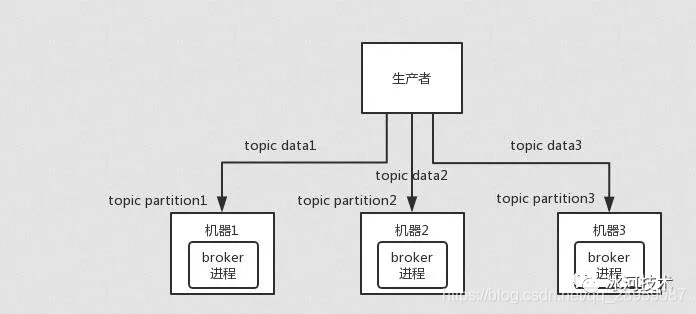
4、RocketMQ 系统架构(重点)
-
RocketMQ是一个统一消息引擎、轻量级数据处理平台
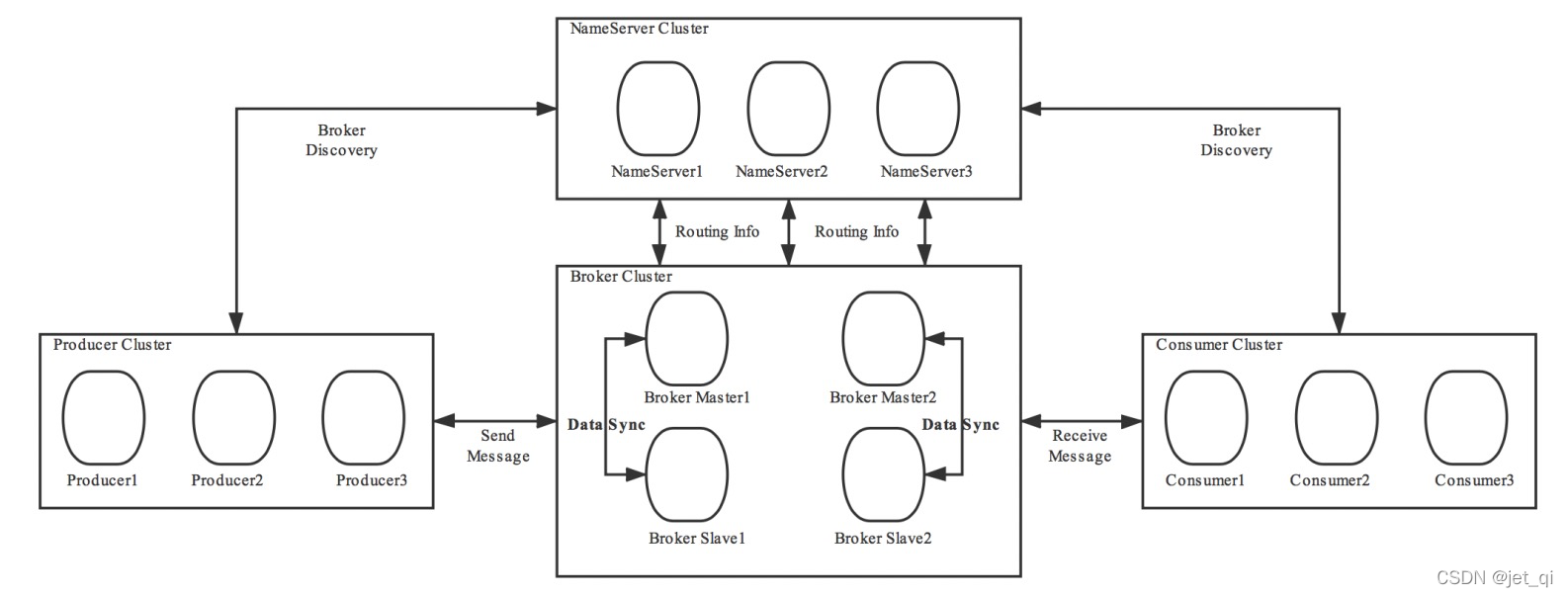
RocketMQ架构上主要分为四部分构成:
1 Producer
消息生产者,负责生产消息
。Producer通过MQ的负载均衡模块选择相应的Broker集群队列进行消息投递,投递的过程支持快速失败并且低延迟。
案例:①业务系统产生的日志写入到MQ的过程,就是消息生产的过程 ②电商平台中用户提交的秒杀请求写入到MQ的过程,就是消息生产的过程
RocketMQ中的消息生产者都是以生产者组(Producer Group)的形式出现的。
生产者组是同一类生产者的集合
,这类Producer发送相同Topic类型的消息。一个生产者组可以同时发送多个主题的消息。
源码:DefaultMQProducerImpl#start
- 1、检查 productGroup,默认为 CLIENT_INNER_PRODUCER。
- 2、将 instanceName 修改为 PID。即 clientId 格式为 ip@pid
- 3、创建 MQClientInstance 实例,给交给 MQClientManager 管理
- 4、创建默认的 Topic(TBW102),并放到 topicPublishInfoTable 中。
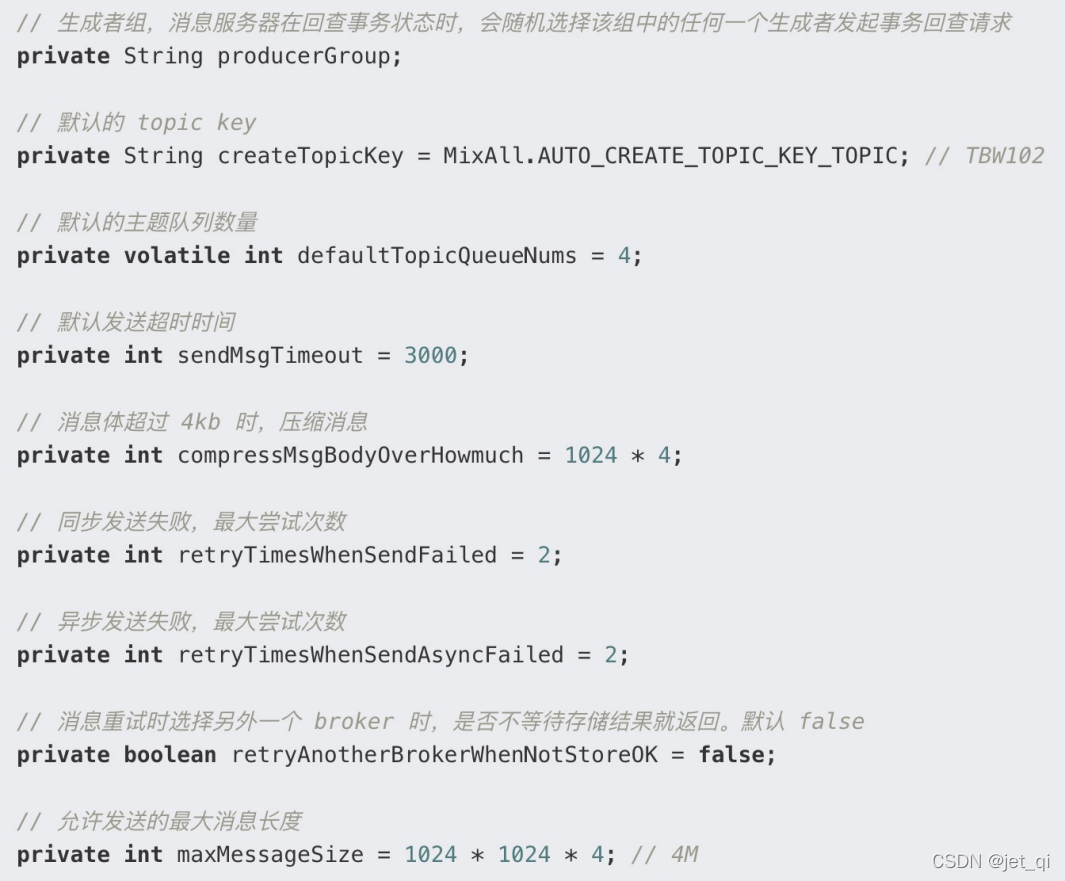
生产者 DefaultMQProducer 核心属性
消息发送流程
流码:DefaultMQProducerImpl#sendDefaultImpl
①验证消息
②查找路由
- Producer 优先从缓存中查找,存在并且正常直接返回;
- 如果没有,则向 namesrv 发起请求, namesrv 返回 TopicRouteData。
- 判断返回的 TopicRouteData 与旧的是否被改变过;如果是,则TopicPublishInfo 更新 queueDatas,brokerDatas 信息。
重要的类:TopicPublishInfo 代码位于:DefaultMQProducerImpl#tryToFindTopicPublishInfo(final String topic)
选择消息队列
MessageQueueSelector 有三个实现类:
- SelectMessageQueueByHash (默认):它是一种不断自增、轮询的方式。
- SelectMessageQueueByRandom:随机选择一个队列。
- SelectMessageQueueByMachineRoom:返回空,没有实现。
除了上面自带的策略,也可以自动定义MessageQueueSelector,作为参数传进去
a. 不启用故障延迟机制sendLatencyFaultEnable = false 默认不启用 broker 故障延迟机制。
RocketMQ 会避开上一次发送失败的 broker
代码入口:TopicPublishInfo#selectOneMessageQueue(final String lastBrokerName)
b. 启用故障延迟机制
代码入口:MQFaultStrategy#selectOneMessageQueue
消息发送
代码入口:DefaultMQProducerImpl#sendKernelImpl
找到所要发送的 broker 地址
为消息分配全局唯一ID,消息体超过4kb,则采用ZIP压缩。
如果注册了消息发送钩子函数,则执行消息发送之前的增强逻辑。通过DefaultMQProducerImpl#registerSendMessageHook() 注册钩子处理类,且可以注册多个
构造消息发送请求包
根据消息发送方式,进行发送(
同步
、异步、单向)
如果注册了消息发送钩子函数,执行after 逻辑
如果发送失败,则继续重复 选择消息队列,然后发送
消息结构
org.apache.rocketmq.common.message.Message

properties 存放的扩展属性主要有:
- tags: 用于过滤消息
- keys: Message 索引键,多个用空格隔开,RocketMQ 可根据这些 key 快速检索消息
- waitStoreMsgOk: 消息发送时,是否等到消息存储完,再返回
- delayTimeLevel: 消息延迟级别,用于定时消息或消息重试
消息类型——普通消息、顺序消息、定时/延时消息、事务消息。
什么是顺序消息
-
顺序消息(FIFO消息)是消息队列RocketMQ版提供的一种严格按照顺序来发布和消费的消息。顺序发布和顺序消费是指对于指定的一个Topic,生产者按照一定的先后顺序发布消息;消费者按照既定的先后顺序订阅消息,
即先发布的消息一定会先被客户端接收到
。
全局顺序消息
- 对于指定的一个Topic,所有消息按照严格的先入先出(FIFO)的顺序来发布和消费。
-
适用场景
:适用于性能要求不高,所有的消息严格按照FIFO原则来发布和消费的场景。 -
示例:
在证券处理中
,以人民币兑换美元为Topic,在价格相同的情况下,先出价者优先处理,则可以按照FIFO的方式发布和消费全局顺序消息。
分区顺序消息
- 对于指定的一个Topic,所有消息根据Sharding Key进行区块分区。同一个分区内的消息按照严格的FIFO顺序进行发布和消费。Sharding Key是顺序消息中用来区分不同分区的关键字段,和普通消息的Key是完全不同的概念。
- 适用场景 : 适用于性能要求高,以Sharding Key作为分区字段,在同一个区块中严格地按照FIFO原则进行消息发布和消费的场景。
-
示例
-
用户注册需要发送发验证码,以
用户ID
作为Sharding Key,那么同一个用户发送的消息都会按照发布的先后顺序来消费。 -
电商的订单创建,以
订单ID
作为Sharding Key,那么同一个订单相关的创建订单消息、订单支付消息、订单退款消息、订单物流消息都会按照发布的先后顺序来消费。
-
用户注册需要发送发验证码,以
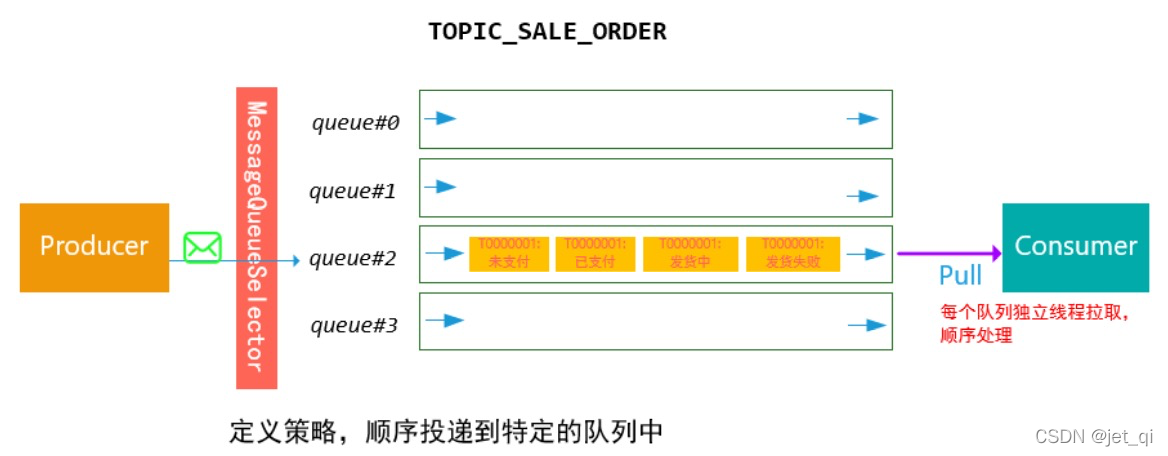
- 阿里巴巴集团内部电商系统均使用分区顺序消息,既保证业务的顺序,同时又能保证业务的高性能。
全局顺序消息与分区顺序消息对比
| Topic的消息类型 | 是否支持事务消息 | 是否支持定时和延时消息 | 性能 |
|---|---|---|---|
| 无序消息(普通、事务、定时和延时消息) | 是 | 是 | 最高 |
| 分区顺序消息 | 否 | 否 | 高 |
| 消息类型 | 是否支持可靠同步发送 | 是否支持可靠异步发送 | 是否支持OneWay发送 |
|---|---|---|---|
| 无序消息(普通、事务、定时和延时消息) | 是 | 是 | 是 |
| 分区顺序消息 | 是 | 否 | 否 |
| 全局顺序消息 | 是 | 否 | 否 |
顺序消息的生产、存储、消费
-
(1) 生产顺序消息——单线程发送
生产者发送消息的时候,到达Broker应该是有序的。
所以对于生产者,不能使用多线程异步发送,而是顺序发送
。- 问题:顺序消息的发送应该使用哪种发送方式?为什么?
- 采用同步的方式,保证顺序
-
(2) 存储顺序消息 —— 顺序写入同一个queue
- 写入Broker的时候,应该是顺序写入的。也就是相同主题的消息应该集中写 入,选择同一个queue,而不是分散写入。
-
(3) 消费顺序消息——保证一个队列只有一个线程消费
- 消费者消费的时候只能有一个线程。否则由于消费的速率不同,有可能出现记录到数据库的时候无序。
可以自由控制重试次数,默认1s重试1次,重试时:此comsumerQueue一直被挂起阻塞,多个线程交替重试。 问题:为什么此时会发生线程切换?
注意事项
发送顺序消息时,请注意以下几点:
- 建议同一个Group ID只对应一种类型的Topic,即不同时用于顺序消息和无序消息的收发。
-
对于全局顺序消息,
建议消息不要有阻塞
。同时运行多个实例,是为了防止工作实例意外退出而导致业务中断。当工作实例退出时,其他实例可以立即接手工作,不会导致业务中断,实际工作的只会有一个实例。
顺序消息常见问题
同一条消息是否可以既是顺序消息,又是定时消息和事务消息?
- 不可以。顺序消息、定时消息、事务消息是不同的消息类型,三者是互斥关系,不能叠加在一起使用。
为什么全局顺序消息性能一般?
-
全局顺序消息是
严格按照FIFO的消息阻塞原则
,即上一条消息没有被成功消费,那么下一条消息会一直被存储到Topic队列中。如果想提高全局顺序消息的TPS,可以升级实例配置,同时消息客户端应用尽量减少处理本地业务逻辑的耗时。
顺序消息支持哪种消息发送方式?
- 顺序消息只支持可靠同步发送方式,不支持异步发送方式,否则将无法严格保证顺序。
顺序消息是否支持集群消费和广播消费?
- 顺序消息暂时仅支持集群消费模式,不支持广播消费模式。
延时消息实现原理
定义:当消息写入到Broker后,在指定的时长后才可被消费处理的消息,称为延时消息
应用场景:电商交易中超时未支付关闭订单的场景,12306平台订票超时未支付取消订票的场景
- 在商品中心的应用:todo
延时等级
延时消息的延迟时长不支持随意时长的延迟,是通过特定的延迟等级来指定的。延时等级定义在RocketMQ服务端的MessageStoreConfig类中的如下变量中
-
若指定的延时等级为3,则表示延迟时长为10s

具体实现方案是:
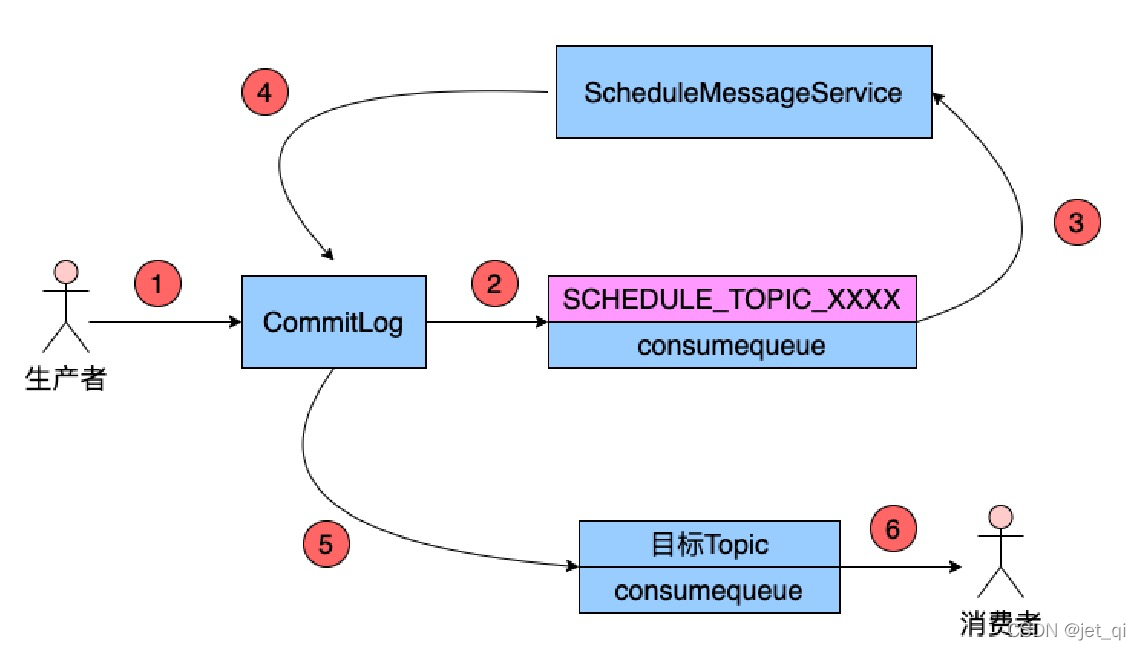
修改消息
Producer将消息发送到Broker后,Broker会首先将消息写入到commitlog文件,然后需要将其分发到相应的consumequeue。不过,
在分发之前,系统会先判断消息中是否带有延时等级
。若没有,则直接正常分发;若有则需要经历一个复杂的过程
-
修改消息的Topic为
SCHEDULE
_TOPIC_XXXX -
根据延时等级,在consumequeue目录中SCHEDULE_TOPIC_XXXX主题下创建出相应的queueId目录与consumequeue文件(如果没有这些目录与文件的话)
-
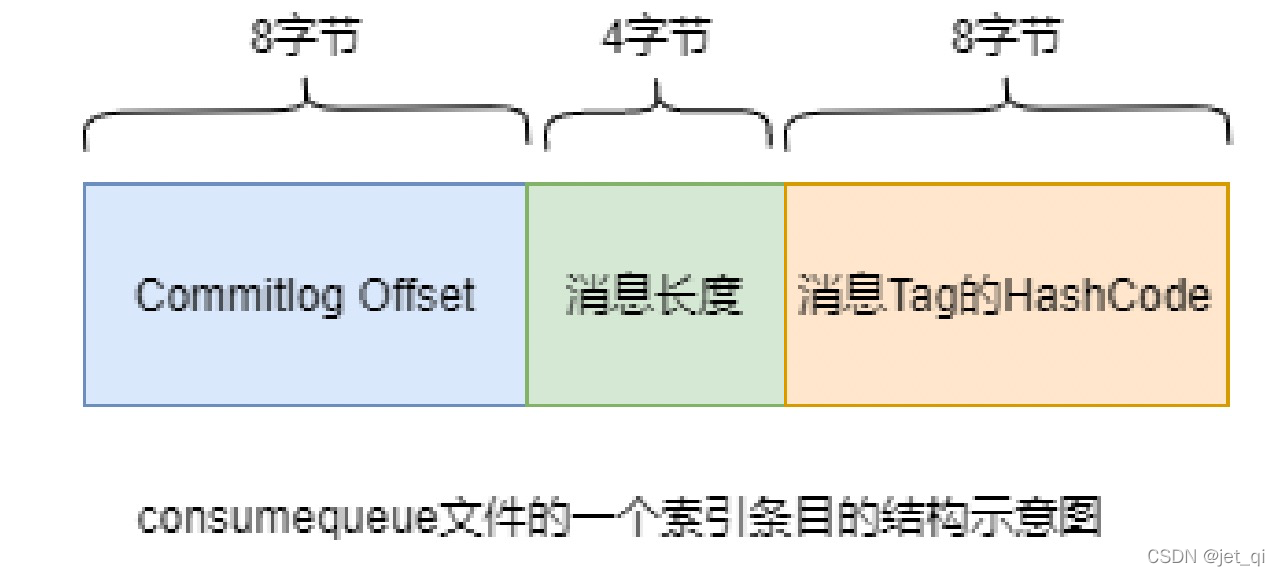
修改消息索引单元内容。索引单元中的Message Tag HashCode部分原本存放的是消息的Tag的Hash值。
现修改为消息的投递时间
。投递时间是指该消息被重新修改为原Topic后再次被写入到commitlog中的时间。投递时间 = 消息存储时间 + 延时等级时间。消息存储时间指的是消息被发送到Broker时的时间戳。 -
将消息索引写入到SCHEDULE_TOPIC_XXXX主题下相应的consumequeue中
SCHEDULE_TOPIC_XXXX目录中各个延时等级Queue中的消息是如何排序的?
是按照消息投递时间排序的。一个Broker中同一等级的所有延时消息会被写入consumequeue
目录中SCHEDULE_TOPIC_XXXX目录下相同Queue中。即一个Queue中消息投递时间的延迟等级时间是相同的。那么投递时间就取决于于 消息存储时间了。即按照消息被发送到Broker的时间进行排序的。
投递延时消息
-
Broker内部有⼀个延迟消息服务类ScheuleMessageService,其会消费SCHEDULE_TOPIC_XXXX中的消息,即按照每条消息的投递时间,将延时消息投递到⽬标Topic中。不过,
在投递之前会从commitlog中将原来写入的消息再次读出,并将其原来的延时等级设置为0,即原消息变为了一条不延迟的普通消息
。然后再次将消息投递到目标Topic中.
将消息重新写入commitlog(
现在是普通消息
)
- 延迟消息服务类 ScheuleMessageService 将延迟消息再次发送给了commitlog,并再次形成新的消息索引条目,分发到相应Queue。
商品中心是这样的骚操作:写个定时任务,到点了投递普通消息
2 Consumer
消息消费者,负责消费消息
。一个消息消费者会从Broker服务器中获取到消息,并对消息进行相关业务处理。支持以push推,pull拉两种模式对消息进行消费。同时也支持集群方式和广播方式的消费,它提供实时消息订阅机制,可以满足大多数用户的需求。
电商平台的业务系统从MQ中读取到秒杀请求,并对请求进行处理的过程就是消息消费的过程
RocketMQ中的消息消费者都是以消费者组(Consumer Group)的形式出现的。
消费者组是同一类消费者的集合,这类Consumer消费的是同一个Topic类型的消息
。消费者组使得在消息消费方面,实现负载均衡(将一个Topic中的不同的Queue平均分配给同一个Consumer Group的不同的Consumer,注意,并不是将消息负载均衡)和容错(一个Consmer挂了,该Consumer Group中的其它Consumer可以接着消费原Consumer消费的Queue)的目标变得非常容易。
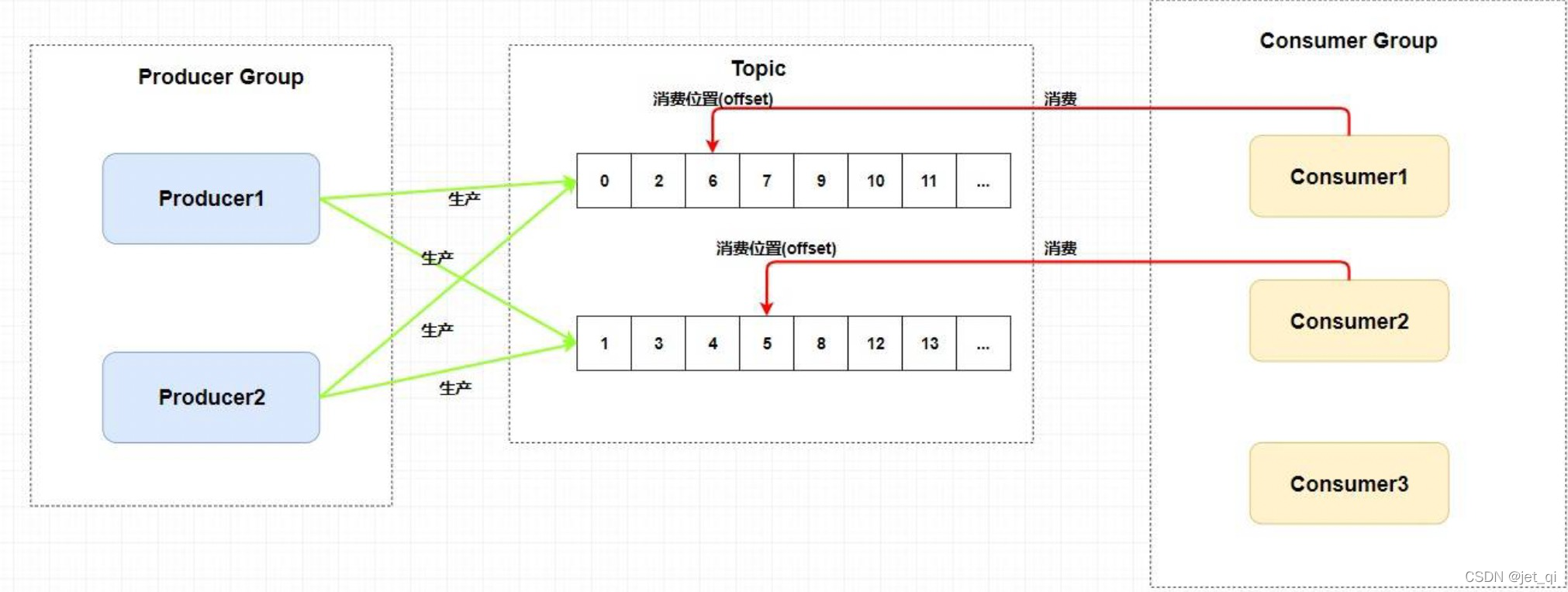
- 注意:如上图所示,消费者组中Consumer的数量应该小于等于订阅Topic的Queue数量。如果超出Queue数量,则多出的Consumer将不能消费消息。
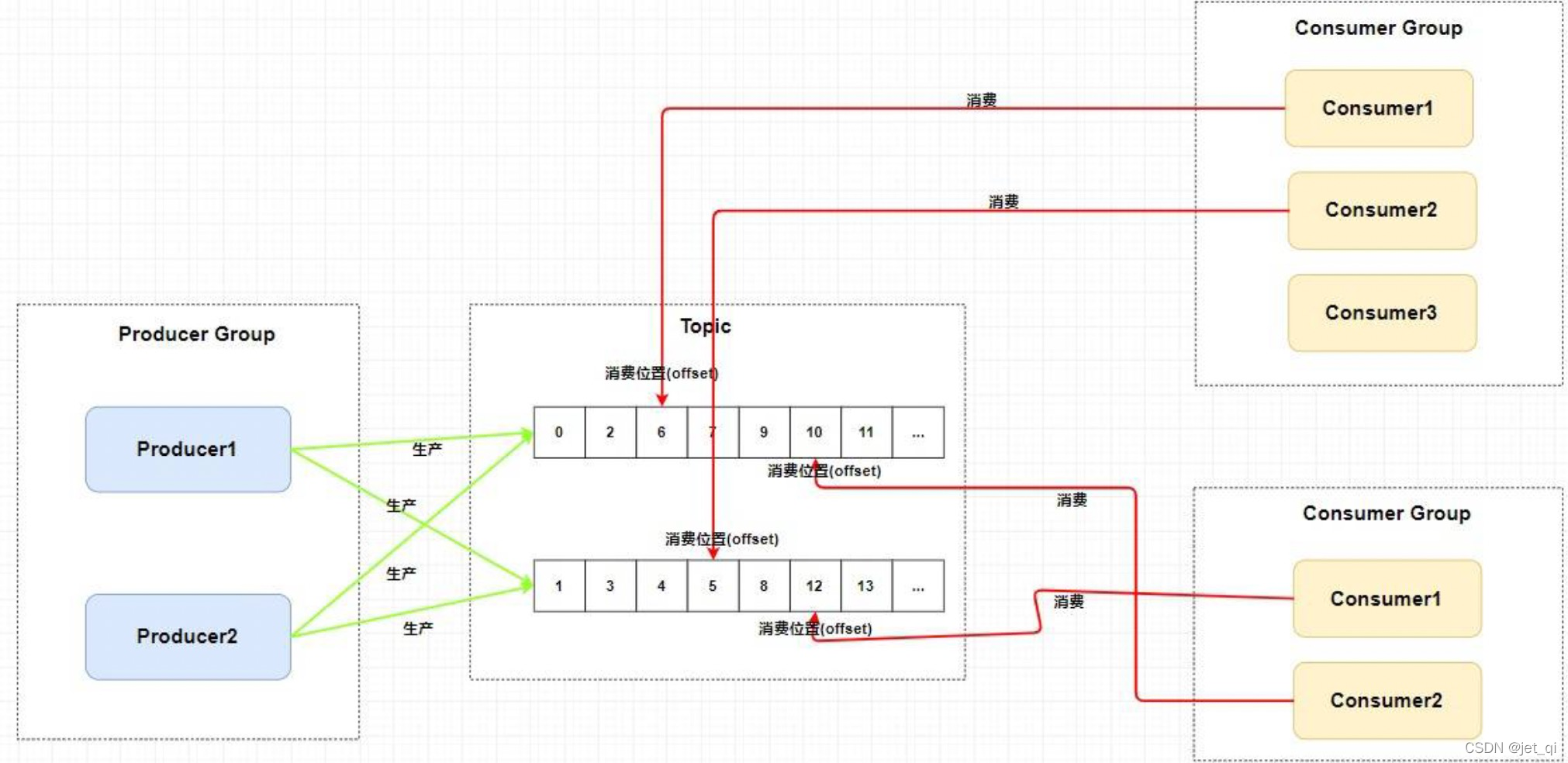
-
如上图所示:一个Topic类型的消息可以被多个消费者组同时消费
-
消费者组只能消费一个Topic的消息,不能同时消费多个Topic消息
-
一个消费者组中的消费者必须订阅完全相同的Topic
-
3 Name Server(注册中心)
NameServer是一个Broker与Topic路由的注册中心,支持Broker的动态注册与发现。
作用类似 Dubbo中的zookeeper
RocketMQ的思想来自于Kafka,而Kafka是依赖了Zookeeper的。所以,在RocketMQ的早期版本,即在MetaQ v1.0与v2.0版本中,也是依赖于Zookeeper的。从MetaQ v3.0,即RocketMQ开始去掉了Zookeeper依赖,使用了自己的NameServer.
Namesrv vs Zookeeper
| 功能点 | Zookeeper | NameSrv |
|---|---|---|
| 角色 | 协调者 | 协调者 |
| 配置保存 | 持久化到磁盘 |
保存内存 |
| 是否支持选举 | 是 |
否 |
| 数据一致性C | 强一致 |
弱一致,各个节点无状态,互不通信,依靠心跳保持数据一致 |
| 是否高可用A | 是 | 是 |
| 设计逻辑 | 支持Raft选举,逻辑复杂难懂,排查问题较难 | CRUD,仅此而已 |
问题:为什么不用Zookeeper? 为什么自己造轮子呢?
实际上不是不用,在RocketMQ的早期版本,即MetaQi.x和2.x阶段,服务管理 也是用Zookeeper实现的,跟kafka —样。但MetaQ 3.x (即RocketMQ)却去掉了ZooKeeper依赖,转而采用自己的NameServer。
RocketMQ的架构设计决定了只需要一个轻量级的元数据服务器就足够了,
只需要保持最终一致
,而不需要
Zookeeper这样的强一致性解决方案
,不需要再依赖另一个中间件,从而减少整体维护成本。
根据著名的CAP理论:一致性(Consistency)、可用性(Availability)、分区容错 (Partiton Tolerance)。 Zookeeper 实现了 CP(C强一致性、A选举期间不可用、P集群中一个结点宕机,整体服务仍可用),
NameServer 选择了 AP(BASE), 放弃了实时一致性
。
Namesrv主要包括两个功能:
-
Broker管理
:接受Broker集群的注册信息并且保存下来作为路由信息的基本数据;提供心跳检测机制,检查Broker是否还存活。 -
路由信息管理
:每个NameServer中都保存着Broker集群的整个路由信息和用于客户端查询的队列信息。Producer和Conumser通过NameServer
就可以获取整个Broker集群的路由信息,从而进行消息的投递和消费
。
路由原理:路由注册、路由剔除、路由发现
简称对 broker 信息在并发下的 CRUD
-
QueueData、BrokerData、BrokerLiveInfo;需要知道这些类的数据结构,
有助于理解路由注册、剔除、发现的基本原理
; -
只要知道 RouterInfoManager 中的几个 Map。基本能知道,路由注册、剔除、发现的基本原理,因为本质都是对这几个集合进行操作
RouteInfoManager
// 读写锁
private final ReadWriteLock lock = new ReentrantReadWriteLock();
// 主题队列表,初始化时,topic 默认有 4 个队列
private final HashMap<String/* topic */, List<QueueData>> topicQueueTable;
// broker 信息。包含集群名称、broker 名称、主备 broker 地址
private final HashMap<String/* brokerName */, BrokerData> brokerAddrTable;
// broker 集群信息。存储集群中所有的名称
private final HashMap<String/* clusterName */, Set<String/* brokerName */>> clusterAddrTable;
// broker 状态信息,namesrv 每次收到心跳包,会替换该信息
private final HashMap<String/* brokerAddr */, BrokerLiveInfo> brokerLiveTable;
// broker FilterService 列表,用于类模式消息过滤
private final HashMap<String/* brokerAddr */, List<String>/* Filter Server */> filterServerTable;
QueueData
private String brokerName;
private int readQueueNums;
private int writeQueueNums;
// 读写权限,参考 permName
private int perm;
private int topicSynFlag;
BrokerData
private String cluster;
private String brokerName;
private HashMap<Long/* brokerId */, String/* broker address */> brokerAddrs;
BrokerLiveInfo
// 最后一次更新时间, namesrv 收到 broker 心跳后,会更新该信息。
private long lastUpdateTimestamp;
private DataVersion dataVersion;
private Channel channel;
private String haServerAddr;
路由注册(源码分析)
【broker 发送心跳包:Broker 在启动 10 秒 后,每隔 30 秒 会向注册过的所有 namesrv 发送心跳包 】
BrokerController#start()
this.scheduledExecutorService.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
try {
BrokerController.this.registerBrokerAll(true, false, brokerConfig.isForceRegister());
} catch (Throwable e) {
log.error("registerBrokerAll Exception", e);
}
}
}, 1000 * 10, Math.max(10000, Math.min(brokerConfig.getRegisterNameServerPeriod(), 60000)), TimeUnit.MILLISECONDS);
// brokerConfig.getRegisterNameServerPeriod() = 30000
BrokerOuterAPI@registerBrokerAll()
// 使用 CountDownLatch 等到向所有 namesrv 注册完毕,才会放行
final CountDownLatch countDownLatch = new CountDownLatch(nameServerAddressList.size());
for (final String namesrvAddr : nameServerAddressList) {
brokerOuterExecutor.execute(new Runnable() {
@Override
public void run() {
try {
RegisterBrokerResult result = registerBroker(namesrvAddr,oneway, timeoutMills,requestHeader,body);
if (result != null) {
registerBrokerResultList.add(result);
}
log.info("register broker[{}]to name server {} OK", brokerId, namesrvAddr);
} catch (Exception e) {
log.warn("registerBroker Exception, {}", namesrvAddr, e);
} finally {
countDownLatch.countDown();
}
}
});
}
try {
countDownLatch.await(timeoutMills, TimeUnit.MILLISECONDS);
} catch (InterruptedException e) {
}
【Namesrv 接收心跳包】
请求被 DefaultRequestProcessor 接收,code = REGISTER_BROKER
DefaultRequestProcessor#processRequest()
switch (request.getCode()) {
...
...
case RequestCode.REGISTER_BROKER:
Version brokerVersion = MQVersion.value2Version(request.getVersion());
if (brokerVersion.ordinal() >= MQVersion.Version.V3_0_11.ordinal()) {
return this.registerBrokerWithFilterServer(ctx, request);
} else {
return this.registerBroker(ctx, request);
}
...
...
}
接着由 RouteInfoManager 执行注册的操作,维护 broker 信息,主要维护以下几个Map 的信息
clusterAddrTable、brokerAddrTable、topicQueueTable、brokerLiveTable、filterServerTable
RouterInfoManager#registerBroker()
...
...
// 拿到 写锁
this.lock.writeLock().lockInterruptibly();
// 维护 clusterAddrTable
Set<String> brokerNames = this.clusterAddrTable.get(clusterName);
if (null == brokerNames) {
brokerNames = new HashSet<String>();
this.clusterAddrTable.put(clusterName, brokerNames);
}
brokerNames.add(brokerName);
// 维护 brokerAddrTable
BrokerData brokerData = this.brokerAddrTable.get(brokerName);
if (null == brokerData) {
registerFirst = true;
brokerData = new BrokerData(clusterName, brokerName, new HashMap<Long, String>());
this.brokerAddrTable.put(brokerName, brokerData);
}
// 维护 topicQueueTable
if (null != topicConfigWrapper && MixAll.MASTER_ID == brokerId) {
if (this.isBrokerTopicConfigChanged(brokerAddr, topicConfigWrapper.getDataVersion()) || registerFirst) {
ConcurrentMap<String, TopicConfig> tcTable = topicConfigWrapper.getTopicConfigTable();
if (tcTable != null) {
for (Map.Entry<String, TopicConfig> entry : tcTable.entrySet()){
// 真正做维护操作的方法
this.createAndUpdateQueueData(brokerName, entry.getValue());
}
}
}
}
// 维护 brokerLiveTable
BrokerLiveInfo prevBrokerLiveInfo = this.brokerLiveTable.put(brokerAddr, new BrokerLiveInfo(
System.currentTimeMillis(),
topicConfigWrapper.getDataVersion(),
channel,
haServerAddr));
...
...
// 释放写锁
this.lock.writeLock().unlock();
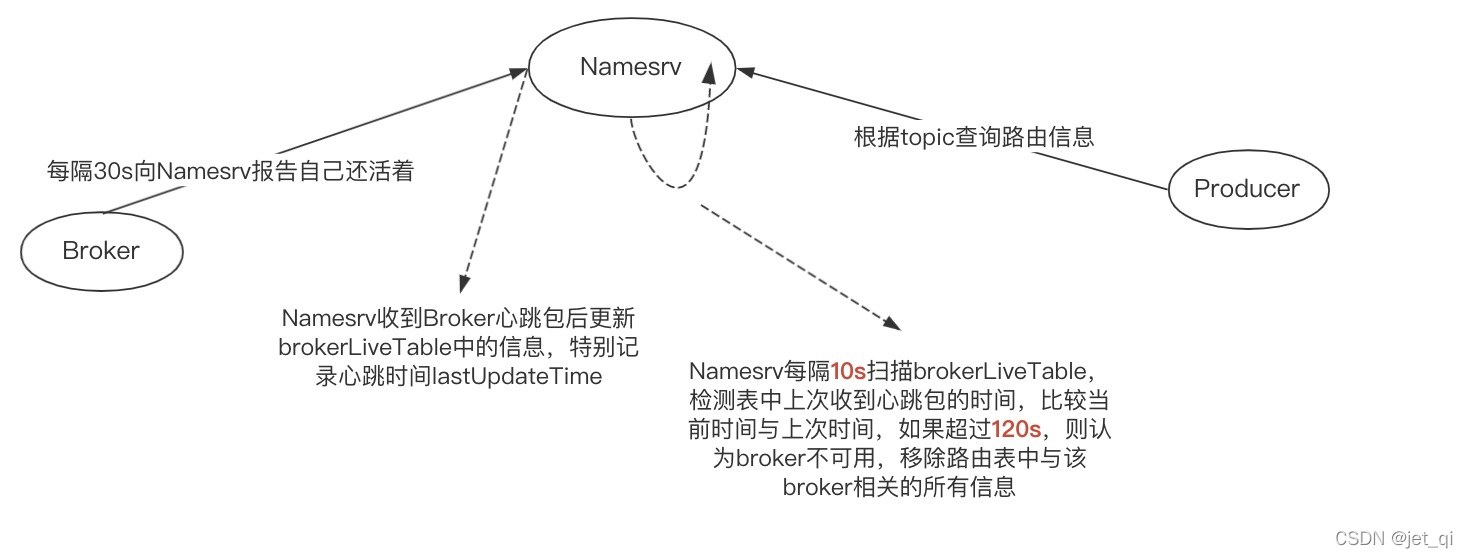
路由剔除
Namesrv 路由剔除触发时机:
- Namesrv 每隔 10 秒 扫描 brokerLiveInfo。 检查 lastUpdateTimestamp 与当前系统时间差 120s,则剔除该broker;
- Broker 正常关闭,触发 JVM 钩子函数,执行 unregisterBroker 操作
路由剔除的操作, 同样无非是对 RouterInfoManager 中维护的 broker 信息进行 CURD。
路由发现
RocketMQ 路由发现非实时,
发现采用的是Pull模型
。当 Topic 路由发生变化后,Namesrv 不主动推送给客户端,而是由客户端拉取主题最新的路由;
- 根据主题名称拉取路由信息的 code = RequestCode.GET_ROUTEINTO_BY_TOPIC
RouteInfoManager#pickupTopicRouteData()
- 主要是操作 topicQueueTable, brokerAddrTable, filterServerMap,填充 topicRouteData。
try {
// 获取读锁
this.lock.readLock().lockInterruptibly();
// 从 topicQueueTable 拿到topic 对应的 队列数据
List<QueueData> queueDataList = this.topicQueueTable.get(topic);
if (queueDataList != null) {
topicRouteData.setQueueDatas(queueDataList);
foundQueueData = true;
Iterator<QueueData> it = queueDataList.iterator();
while (it.hasNext()) {
QueueData qd = it.next();
brokerNameSet.add(qd.getBrokerName());
}
// 从 brokerAddrTable 获取 broker 对应的地址
for (String brokerName : brokerNameSet) {
BrokerData brokerData = this.brokerAddrTable.get(brokerName);
if (null != brokerData) {
BrokerData brokerDataClone = new BrokerData(brokerData.getCluster(), brokerData.getBrokerName(), (HashMap<Long, String>) brokerData.getBrokerAddrs().clone());
brokerDataList.add(brokerDataClone);
foundBrokerData = true;
for (final String brokerAddr : brokerDataClone.getBrokerAddrs().values()) {
List<String> filterServerList = this.filterServerTable.get(brokerAddr);
filterServerMap.put(brokerAddr, filterServerList);
}
}
}
}
} finally {
this.lock.readLock().unlock();
}
路由发现 扩展:
1)
Push模型
:推送模型。其实时性较好,是一个“发布-订阅”模型,需要维护一个长连接。而长连接的维护是需要资源成本的。该模型适合于的场景:①实时性要求较高 ② Client数量不多,Server数据变化较频繁
2)
Pull模型
:拉取模型。存在的问题是,实时性较差。
3)
Long Polling模型
:长轮询模型。其是对Push与Pull模型的整合,充分利用了这两种模型的优势,屏蔽了它们的劣势。
客户端(Producer与Consumer) NameServer选择策略
- 客户端在配置时必须要写上NameServer集群的地址,那么客户端到底连接的是哪个NameServer节点呢?客户端首先会生产一个随机数,然后再与NameServer节点数量取模,此时得到的就是所要连接的节点索引,然后就会进行连接。如果连接失败,则会采用round-robin策略,逐个尝试着去连接其它节点。
NameSrv启动、停止流程
源码:org.apache.rocketmq.namesrv.NamesrvStartup#main
1、初始化资源: NamesrvController#initialize()
namesrv 启动时,主要是加载配置文件,初始化 NettyServer,NamesrvController。 并由 NamesrvController 创建 2 个线程池(每 10 秒 扫描不可用的 broker、每 10 分钟 打印 KV 配置)
/** 1、加载KV配置:从本地文件中加载KV配置到内存中 */
this.kvConfigManager.load();
/** 2、初始化Netty通信层实例。 RocketMQ基于Netty实现了一个RPC服务器,及NettyRemotingServer. 通过参数nettyServerConfig,会启动9876端口监听。 */
this.remotingServer = new NettyRemotingServer(this.nettyServerConfig, this.brokerHousekeepingService);
this.remotingExecutor = Executors.newFixedThreadPool(nettyServerConfig.getServerWorkerThreads(), new ThreadFactoryImpl("RemotingExecutorThread_"));
/** 3、10s一次扫描不可用broker */
this.scheduledExecutorService.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
NamesrvController.this.routeInfoManager.scanNotActiveBroker();
}
}, 5, 10, TimeUnit.SECONDS);
/** 3、10min打印一次KV配置 */
this.scheduledExecutorService.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
NamesrvController.this.kvConfigManager.printAllPeriodically();
}
}, 1, 10, TimeUnit.MINUTES);
2、注册 JVM 钩子,释放资源
在启动后,注册 JVM 钩子函数,在程序停止时,优雅的关闭资源
Runtime.getRuntime().addShutdownHook(new ShutdownHookThread(log, new Callable<Void>() {
@Override
public Void call() throws Exception {
// 关闭Namesrv
controller.shutdown();
return null;
}
}));
/**
* 关闭Namesrv
*/
public void shutdown() {
/** 1.关闭Netty服务端,主要是关闭Netty时间处理器、时间监听器等全部初始化的组件 */
this.remotingServer.shutdown();
/** 2.关闭Namesrv接口处理线程池 */
this.remotingExecutor.shutdown();
/** 3.关闭全部已经启动的定时任务 */
this.scheduledExecutorService.shutdown();
if (this.fileWatchService != null) {
this.fileWatchService.shutdown();
}
}
3、停止
通过关闭命令 ./mqshutdown namesrv -> 调用kill命令将关闭进程通知发各个JVM,JVM调用关机Hook执行停止逻辑。
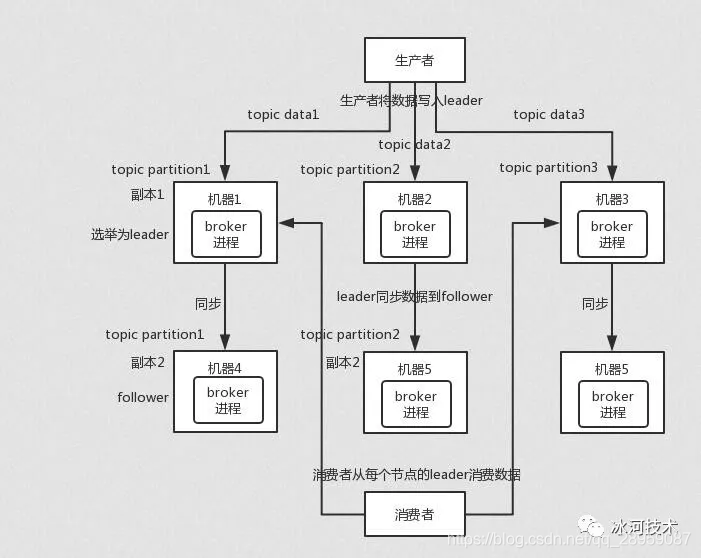
4 Broker(最复杂)
Broker充当着消息中转角色,负责存储消息、转发消息、以及服务高可用保证
。Broker在RocketMQ系统中负责接收并存储从生产者发送来的消息,同时为消费者的拉取请求作准备。Broker同时也存储着消息相关的元数据,包括消费者组消费进度偏移offset、主题、队列等。
为了实现这些功能,Broker包含了以下几个重要子模块,下图为Broker Server的功能模块示意图。
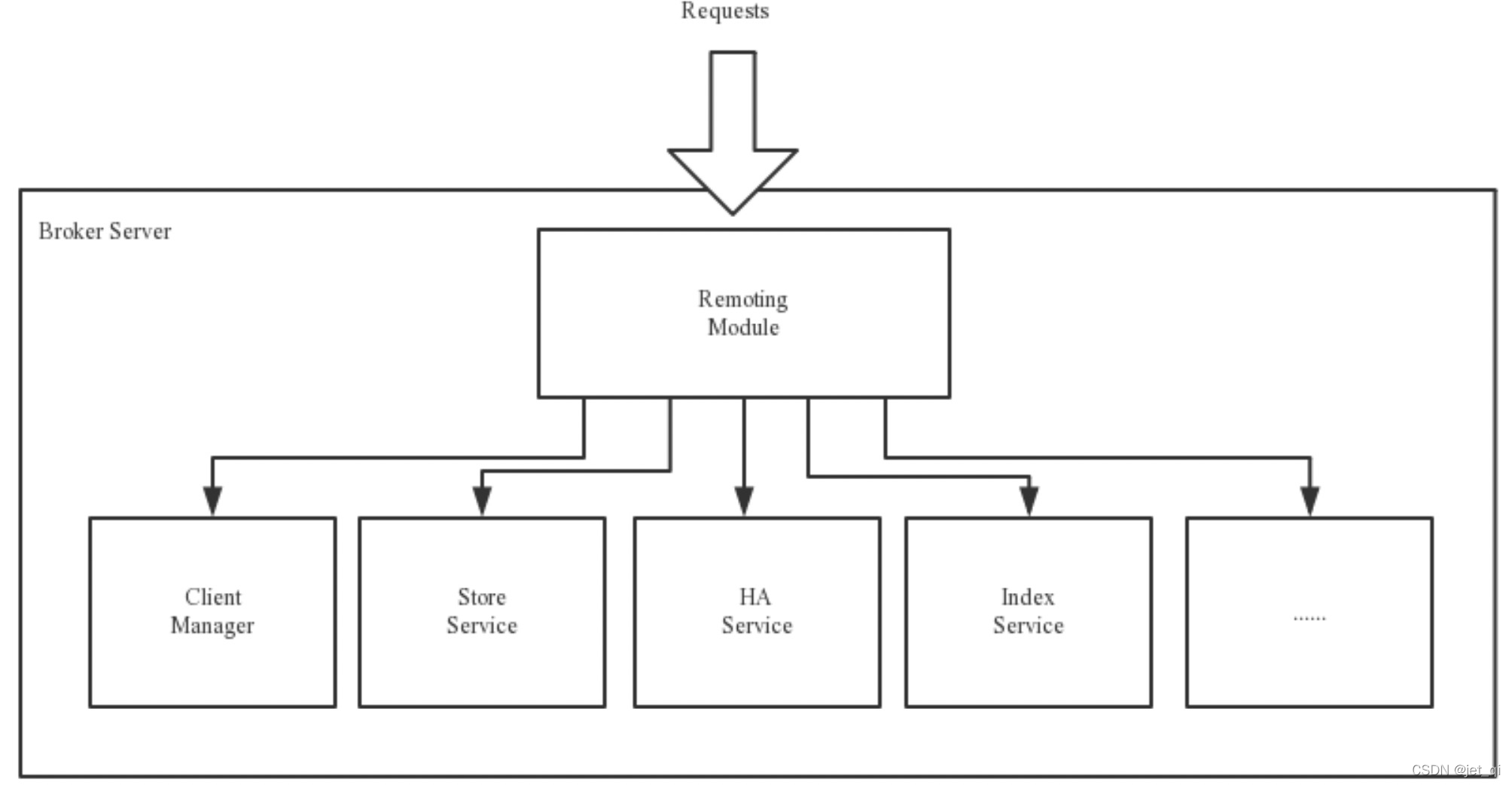
Remoting Module
:整个Broker的实体,负责处理来自clients端的请求。而这个Broker实体则由以下模块构成。
-
Client Manager:客户端管理器。负责接收、解析客户端(Producer/Consumer)请求,管理客户端。例如,
维护Consumer的Topic订阅信息
; - Store Service:存储服务。提供方便简单的API接口,处理消息存储到物理硬盘和消息查询功能。
- HA Service:高可用服务,提供Master Broker 和 Slave Broker之间的数据同步功能。
- Index Service:索引服务。根据特定的Message key,对投递到Broker的消息进行索引服务,同时也提供根据Message Key对消息进行快速查询的功能
集群部署(运维)
-
为了增强Broker性能与吞吐量,Broker一般都是以集群形式出现的。各集群节点中可能存放着相同Topic的不同Queue。不过,这里有个问题,
如果某Broker节点宕机,如何保证数据不丢失呢?
其解决方案是,将每个Broker集群节点进行横向扩展,即将Broker节点再建为一个HA集群,解决单点问题。
Broker节点集群是一个主从集群,即集群中具有Master与Slave两种角色。Master负责处理读写操作请求,Slave负责对Master中的数据进行备份。当Master挂掉了,Slave则会自动切换为Master去工作。
所以这个Broker集群是主备集群
。一个Master可以包含多个Slave,但一个Slave只能隶属于一个Master。Master与Slave 的对应关系是通过指定相同的BrokerName、不同的BrokerId 来确定的。BrokerId为0表示Master,非0表示Slave。每个Broker与NameServer集群中的所有节点建立长连接,定时注册Topic信息到所有NameServer。
消息存储整体架构
5 集群工作流程
1)启动NameServer,NameServer启动后开始监听端口,等待Broker、Producer、Consumer连接,相当于一个路由控制中心;
2)启动Broker时,Broker会与所有的NameServer建立并保持长连接,然后每30秒向NameServer 定时发送心跳包。心跳包中包含当前Broker信息(IP+端口等)以及存储所有Topic信息。注册成功后,NameServer集群中就有Topic跟Broker的映射关系;
3)发送消息前,可以先创建Topic,创建Topic时需要指定该Topic要存储在哪些Broker上,当然,在创建Topic时也会将Topic与Broker的关系写入到NameServer中,也可以在发送消息时自动创建Topic;
4)Producer发送消息,启动时先跟NameServer集群中的其中一台建立长连接,并从NameServer中获取路由信息,即当前发送的Topic消息的Queue与Broker的地址(IP+Port)的映射关系。然后根据算法策略(默认轮询)从队选择一个Queue,与队列所在的Broker建立长连接从而向Broker发消息。
5)Consumer跟Producer类似,跟其中一台NameServer建立长连接,获取其所订阅Topic的路由信息,然后根据算法策略从路由信息中获取到其所要消费的Queue,然后直接跟Broker建立长连接,开始消费其中的消息。
Topic的创建模式
手动创建Topic时,有两种模式:
- 集群模式:该模式下创建的Topic在该集群中,所有Broker中的Queue数量是相同的。
- Broker模式:该模式下创建的Topic在该集群中,每个Broker中的Queue数量可以不同。
自动创建Topic时,默认采用的是Broker模式,会为每个Broker默认创建4个Queue
。
读/写队列
- 从物理上来讲,读/写队列是同一个队列。所以,不存在读/写队列数据同步问题。读/写队列是逻辑上进行区分的概念。一般情况下,读/写队列数量是相同的
例如,创建Topic时设置的写队列数量为8,读队列数量为4,此时系统会创建8个Queue,分别是0 1 2 3 4 5 6 7。Producer会将消息写入到这8个队列,但Consumer只会消费0 1 2 3这4个队列中的消息,4 5 6 7中的消息是不会被消费到的。
再如,创建Topic时设置的写队列数量为4,读队列数量为8,此时系统会创建8个Queue,分别是0 1 2 3 4 5 6 7。Producer会将消息写入到0 1 2 3 这4个队列,但Consumer只会消费0 1 2 3 4 5 6 7这8个队列中的消息,但是4 5 6 7中是没有消息的。此时假设Consumer Group中包含两个Consuer,Consumer1消费0 1 2 3,而Consumer2消费4 5 6 7。但实际情况是,Consumer2是没有消息可消费的。也就是说,当读/写队列数量设置不同时,总是有问题的。那么,为什么要这样设计呢?
其这样设计的目的是为了,
方便Topic的Queue的缩容。
(考点)
例如,原来创建的Topic中包含16个Queue,如何能够使其Queue缩容为8个,还不会丢失消息?可以动态修改写队列数量为8,读队列数量不变。此时新的消息只能写入到前8个队列,而消费都消费的却是16个队列中的数据。当发现后8个Queue中的消息消费完毕后,就可以再将读队列数量动态设置为8。整个缩容过程,没有丢失任何消息。
perm用于设置对当前创建Topic的操作权限:2表示只写,4表示只读,6表示读写
消费线程数与队列的关系
真线topic默认分16个队列、单机默认消费线程数20

读写队列的关系

查看消费线程栈及状态
1、查看并记录Java进程的PID: ps -ef
2、查看堆栈信息: /opt/jdk1.8.0_231/bin/jstack -l 1 > /tmp/1.jstack 【jstack -l pid > /tmp/pid.jstack】
3、查看ConsumeMessageThread的信息:cat /tmp/1.jstack|grep ConsumeMessageThread -A 10 –color 【cat /tmp/pid.jstack|grep ConsumeMessageThread -A 10 –color】
常见的异常堆栈信息如下:
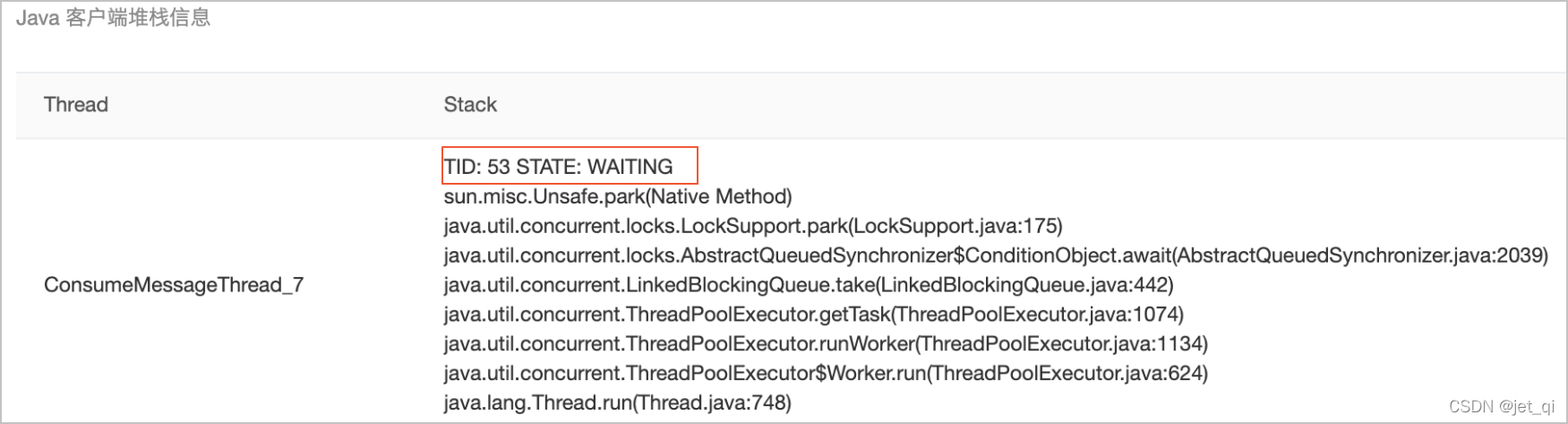
示例一:空闲无堆积的堆栈。
-
消费空闲情况下消费线程都会处于WAITING状态等待从消费任务队里中获取消息。
示例二:消费逻辑有抢锁休眠等待等情况。 消费线程阻塞在内部的一个睡眠等待上,导致消费缓慢。

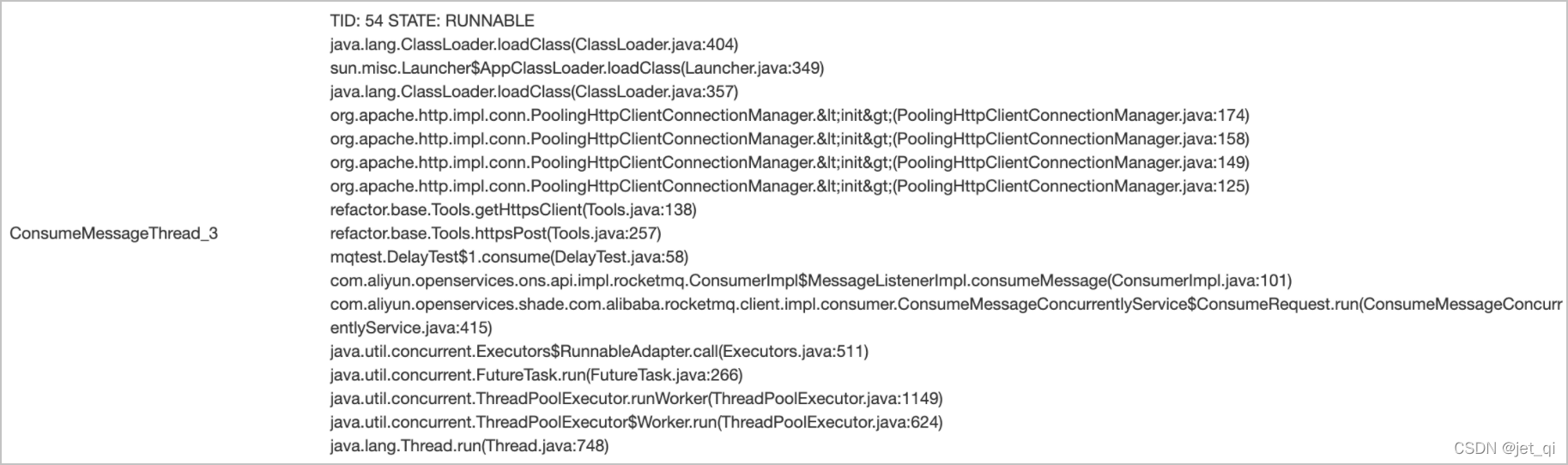
示例三:消费逻辑操作数据库等外部存储卡住。消费线程阻塞在外部的HTTP调用上,导致消费缓慢
5、MQ使用规范
5.1、如何写好MQ发送逻辑

申请发送方 PID GID_P_

Demo1 发送普通消息
ItemMigrateContextEvent itemMigrateContextEvent = ItemMigrateContextEvent.builder()
.orgId(orgId)
.batchJobId(batchJob.getResult())
.protocolId(itemMigrateRequestDto.getFromAgreementId())
.build();
ZMQResponse zmqResponse = zmqTemplate.sendCommonMsg(
MqConfigContant.ITEM_MIGRATE_TOPIC,
// 一定要指定tag
MqConfigContant.ITEM_MIGRATE_TAG,
null,
ImJsonUtils.objToJson(itemMigrateContextEvent));
Demo2 发送顺序消息
/**
* 发送记录日志消息
* @param typeEnum 日志详情
* @param bizType 操作类型
* @param value 参数类型
* @param shardingKey 保证消息局部有序的一个值
*/
private void sendRecordLogMsg(LogRecordParamTypeEnum typeEnum, BizTypeEnum bizType, OperationRecordLogDto value, String shardingKey) {
String message = "";
try {
message = buildMessage(typeEnum, bizType, value);
// 指定顺序消息分区键
ZMQResponse zmqResponse = zmqTemplate.sendOrderMsg(MqConfigContant.ITEM_STANDARD_LOG_RECORD_TOPIC, MqConfigContant.ITEM_STANDARD_LOG_RECORD_TAG, null, message, shardingKey);
if (!zmqResponse.isSuccess()) {
log.warn("[日志系统] 发送日志消息失败, topic:{}, tag:{}, message:{}, cause:{}", MqConfigContant.ITEM_STANDARD_LOG_RECORD_TOPIC, typeEnum, message, zmqResponse.getResult());
}
} catch (ZMQException e) {
log.warn("[日志系统] 发送日志消息失败, tag:{}, message:{}", MqConfigContant.ITEM_STANDARD_LOG_RECORD_TAG, message, e);
}
}
/**
* 构建消息体
* @param typeEnum 类型
* @param value 日志详情
* @return String
*/
private String buildMessage(LogRecordParamTypeEnum typeEnum,
BizTypeEnum bizType,
OperationRecordLogDto value) {
LogRecordMq logRecordMq = new LogRecordMq(typeEnum,bizType, value);
return JSON.toJSONString(logRecordMq);
}
5.2、使用MQ发送消息的注意事项
| 注意点 | 细节说明 |
|---|---|
| 消息类型:普通消息、顺序消息(分区顺序)、事务 | 普通消息和顺序消息不能混用topic、 顺序消息一定要采用分区顺序。 |
| 生产组、topic、tag | 一定要有tag |
| 发送方式:同步、异步、单向 | 一般采用同步发送方式 |
| 发送节点 |
非事务消息要放到事务提交后发送 |
| 消息丢失 | 如何避免? 采用同步发送方式,宁重复不丢失 |
| 重试 |
失败重试、异常重试 (但有可能已经成功,返回结果时由于网络等问题以为失败,又发了一条重复消息。 所以消费时,一定要做幂等) |
| 消息格式 |
含字段:业务唯一id
如发消息失败重试,导致多次发送:但消息id不一样。 此时如果有业务唯一id,则可根据其做幂等。 |
| 消息体条数 | 单条or 批量 |
| 消息体大小 | < 4M |
| log | 做开关 |
| 告警:error告警 | |
5.3、如何写好MQ消费逻辑
一定要指明tag,不可凭空捏造tag名,一定要去发送方找目前有哪些tag,你需要消费哪些tag,才在这里配置哪些tag

Demo3 消息消费
@Autowired
@Qualifier(ItemMigrateMessageCallBack.RATE_LIMITER_NAME)
private RateLimiter rateLimiter;
public ZMQConsumeStatus messageArrived(ZMQMessage msg) {
rateLimiter.acquire();
String tag = msg.getTag();
// 该行日志请勿删除
log.info("创建店铺信息: msgId:{} ,topic:{}, tag:{} , message:{}" , msg.getMsgId(), msg.getTopic(), tag, msg);
String message = new String(msg.getBody());
try {
if(MqConfigContant.ITEM_MICRO_SHOP_CREATE_TAG.equals(tag)){
log.info("创建店铺消息 messageId:{}, body转换后为:{}", msg.getMsgId(), message);
return this.consumeConcurrentlyStatus(message);
}
return ZMQConsumeStatus.CONSUME_SUCCESS;
} catch (Exception e) {
log.error("店铺创建消费失败, message:{}", message, e);
return ZMQConsumeStatus.RECONSUME_LATER;
}
}
5.4、使用MQ接收消息的注意事项
| 注意点 | 细节说明 |
|---|---|
| 消息类型:普通、顺序、定时/延时、事务 | 普通、顺序 |
| 消费方式:广播、集群 | 集群、广播 |
| 消息过滤 |
tag:由于在Broker服务端只是根据tag的hashcode进行判断,无法精确对tag原始字符串进行过滤,故在消息消费端拉取到消息后,还需要对消息的原始tag字符串进行比对,如果不同,则丢弃该消息,不进行消息消费。 |
| 限流 |
单机QPS、避免QPS过大 打垮应用
|
| 幂等 | |
| 重试 |
普通消息:重试有延时等级、21次。 每一次重试都需要log.error 超过最大重试次数后log.error、且配置死信告警。 顺序消息: 重试前sleep暂停几秒,避免短时间内重试次数太多,因为顺序消息重试时没有延时等级,会立即再次收到这条消息。 每一次重试都需要log.error 设置重试阈值,超过最大重试次数后:手动退出 避免无限重试阻塞、 log.error 兜底策略:超过最大重试次数,还是失败,可采用落库,job补偿的方式兜底。 |
| trace 追踪能力 |
02-zmq 消费方增强trace、消费延时通知能力 |
| 消息丢失 | |
| 批量 | |
| log |
不要只打印body, messageId、重试次数等都打出来。 做开关。 |
| 告警 |
堆积告警、延时告警、死信告警 |
| 重置消费线程数 |
默认20个。 zcy.zmq.ext.consumerHints. |
| 重置超时时间 |
默认15分钟。 zcy.zmq.ext.consumerHints. topic _ cid .consumeTimeout = 2 |
5.5、MQ其它实用技巧
配置告警:堆积、延迟等
查看:堆积、生产/消费速度、延迟、死信
查看消费线程
调整消费线程数、调整超时时间
6、RocketMQ工作原理
6.1、消息的生产
1 消息的生产过程
Producer可以将消息写入到某Broker中的某Queue中,其经历了如下过程:
- Producer发送消息之前,会先向NameServer发出获取消息Topic的路由信息的请求;
- NameServer返回该Topic的路由表及Broker列表;
- Producer根据代码中指定的Queue选择策略,从Queue列表中选出一个队列,用于后续存储消息;
- Produer对消息做一些特殊处理,例如,消息本身超过4M,则会对其进行压缩;
- Producer向选择出的Queue所在的Broker发出RPC请求,将消息发送到选择出的Queue
路由表
:
实际是一个Map
,key为Topic名称,value是一个QueueData实例列表。QueueData并不是一个Queue对应一个QueueData,而是一个Broker中该 Topic 的所有 Queue对应一个QueueData。即,只要涉及到该 Topic 的 Broker,一个Broker对应一个QueueData。QueueData中包含brokerName。简单来说,路由表的key为Topic名称,value则为所有涉及该Topic的BrokerName列表.
Broker列表
:实际也是一个Map。key为brokerName,value为BrokerData。一个Broker对应一个BrokerData实例,对吗?不对。一套brokerName名称相同的Master-Slave小集群对应一个BrokerData。BrokerData中包含brokerName及一个map。该map的key为brokerId,value为该broker对应的地址。
brokerId为0表示该broker为Master,非0表示Slave
。
2 Queue选择算法
对于无序消息,其Queue选择算法,也称为消息投递算法,常见的有两种:
轮询算法
-
默认选择算法
。该算法保证了每个Queue中可以均匀的获取到消息
该算法存在一个问题:由于某些原因,在某些Broker上的Queue可能投递延迟较严重。从而导致Producer的缓存队列中出现较大的消息积压,影响消息的投递性能
最小投递延迟算法
该算法会统计每次消息投递的时间延迟,然后根据统计出的结果将消息投递到时间延迟最小的Queue。如果延迟相同,则采用轮询算法投递。该算法可以有效提升消息的投递性能。
该算法也存在一个问题:消息在Queue上的分配不均匀。投递延迟小的Queue其可能会存在大量的消息。而对该Queue的消费者压力会增大,降低消息的消费能力,可能会导致MQ中消息的堆积
6.2、消息的存储
RocketMQ中的消息存储在本地文件系统中,这些相关文件默认在当前用户主目录下的store目录中
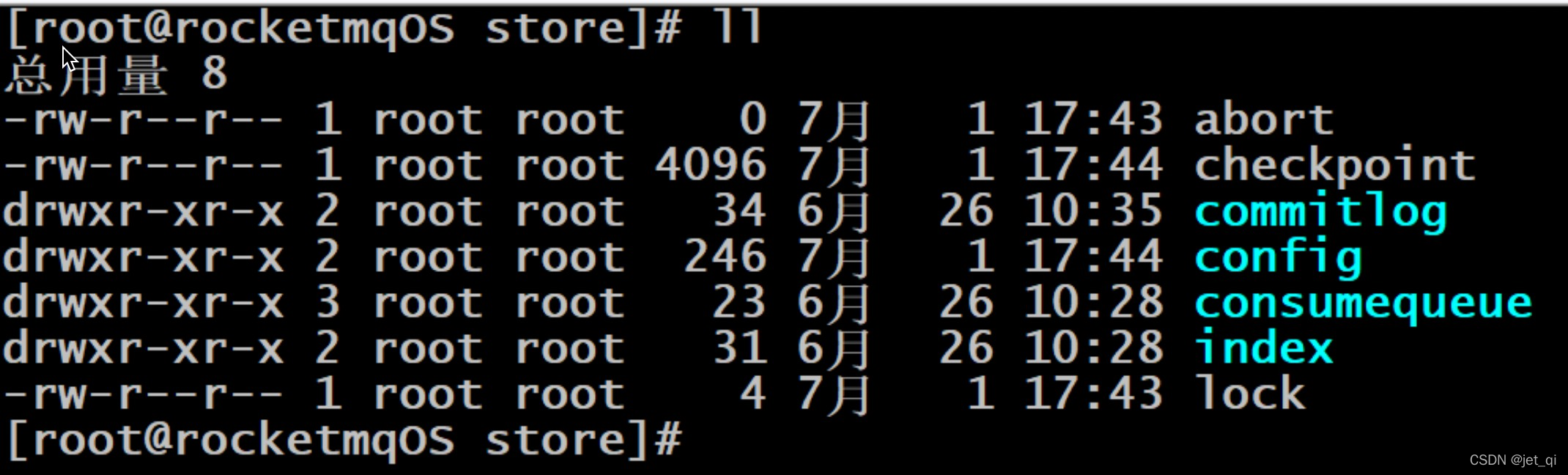
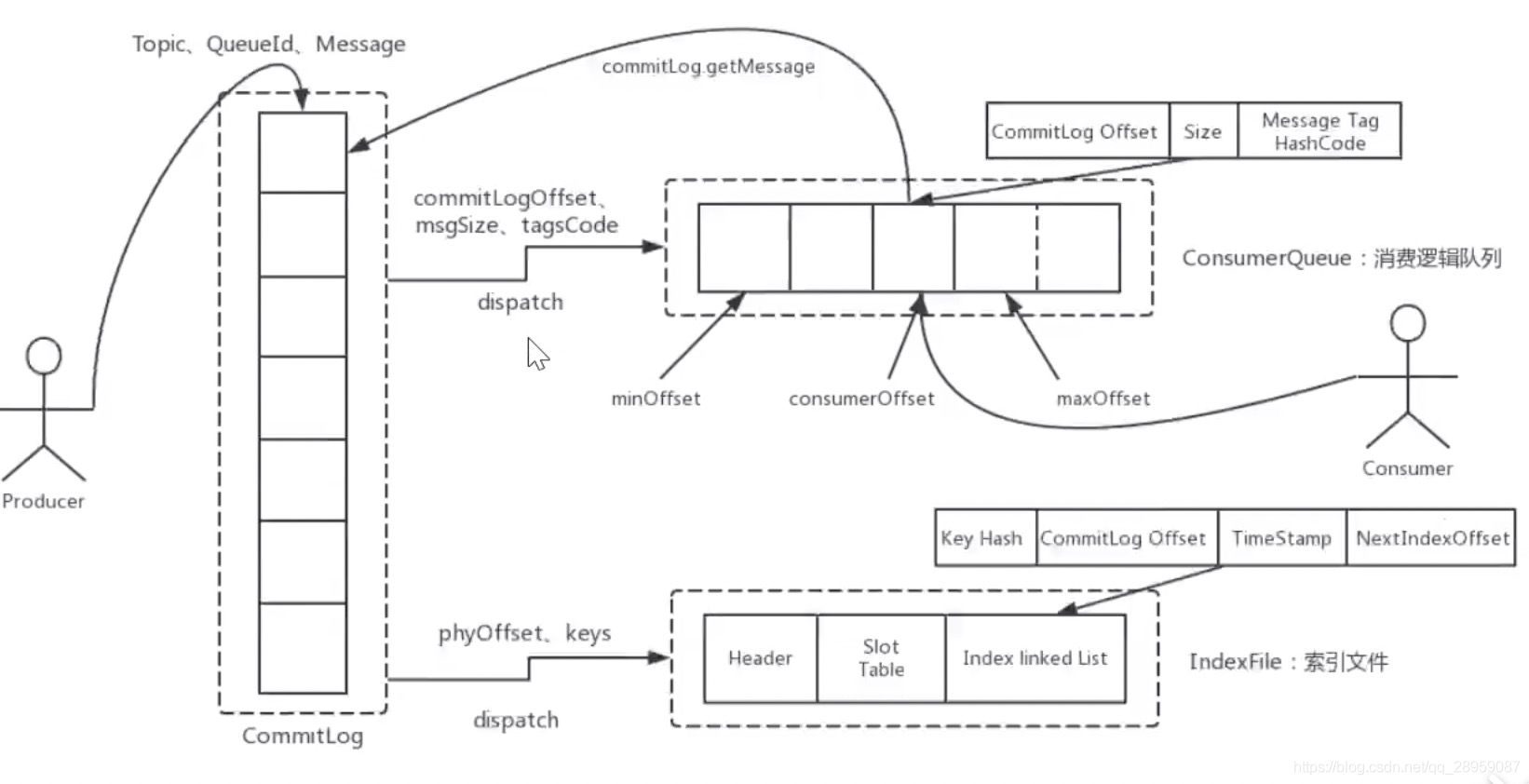
1 commitlog文件
- 消息主体以及元数据的存储主体
commitlog目录中存放着很多的mappedFile文件,当前Broker中的所有消息都是落盘到这些mappedFile文件中的。
mappedFile文件大小为1G(小于等于1G)
,文件名由20位十进制数构成,表示当前文件的第一条消息的起始位移偏移量
消息单元

mappedFile文件内容由一个个的消息单元构成。每个消息单元中包含消息总长度MsgLen、消息的物理位置physicalOffset、消息体内容Body、消息体长度BodyLength、消息主题Topic、Topic长度TopicLength、消息生产者BornHost、消息发送时间戳BornTimestamp、消息所在的队列QueueId、消息在Queue中存储的偏移量QueueOffset等近20余项消息相关属性.
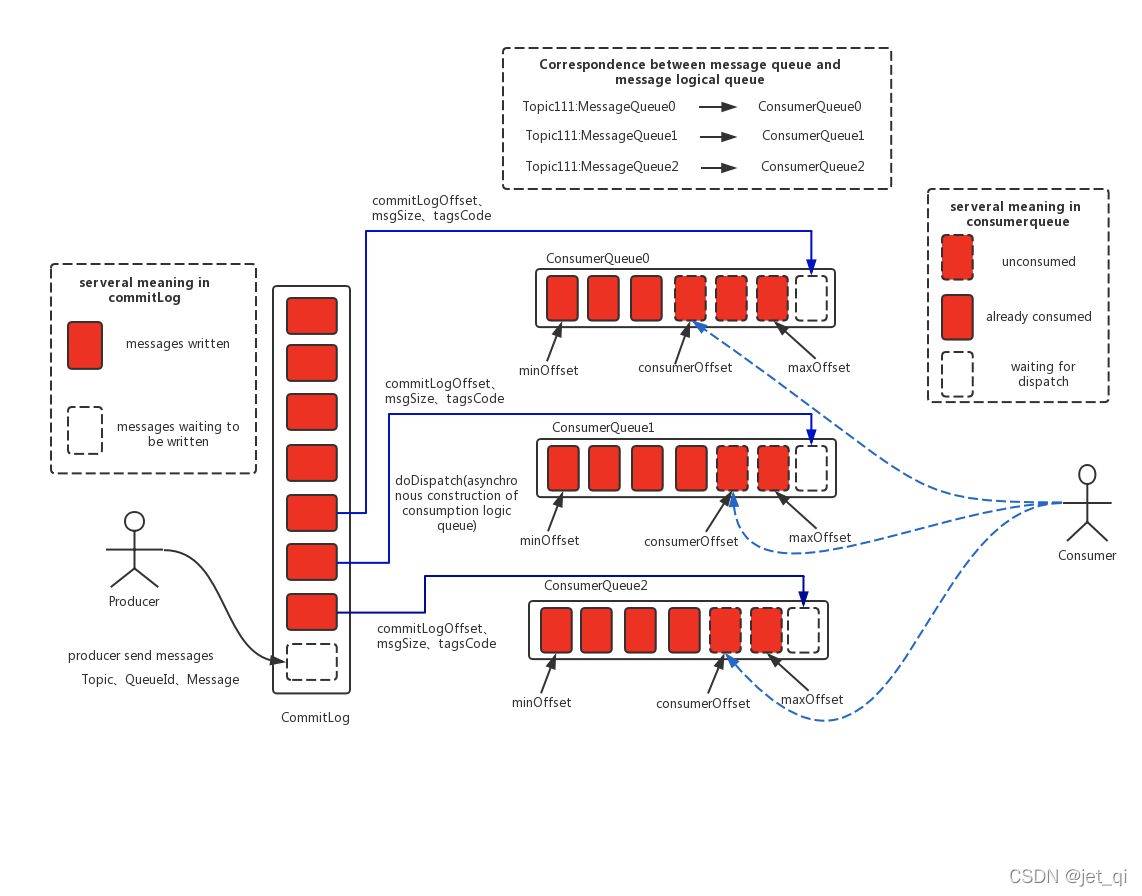
2 consumequeue
- 消息消费队列,引入的目的主要是提高消息消费的性能
为了提高效率,会为每个Topic在~/store/consumequeue中创建一个目录,目录名为Topic名称。在该Topic目录下,会再为每个该Topic的Queue建立一个目录,目录名为queueId。每个目录中存放着若干consumequeue文件,
consumequeue文件是 commitlog 的索引文件
,可以根据consumequeue定位到具体的消息.
consumequeue文件夹的组织方式如下:topic/queue/file三层组织结构,具体存储路径为:$HOME/store/consumequeue/{topic}/{queueId}/{fileName}。同样consumequeue文件采取定长设计,每一个条目共20个字节,分别为8字节的commitlog物理偏移量、4字节的消息长度、8字节tag hashcode,单个文件由30W个条目组成,可以像数组一样随机访问每一个条目,每个ConsumeQueue文件大小约5.72M;
消息写入
一条消息进入到Broker后经历了以下几个过程才最终被持久化。
- Broker根据queueId,获取到该消息对应索引条目要在consumequeue目录中的写入偏移量,即QueueOffset
- 将queueId、queueOffset等数据,与消息一起封装为消息单元
- 将消息单元写入到commitlog
- 同时,形成消息索引条目
- 将消息索引条目分发到相应的consumequeue
消息拉取
当Consumer来拉取消息时会经历以下几个步骤:
-
Consumer获取到其要消费消息所在Queue的消费偏移量offset,计算出其要消费消息的消息offset
消费offset即消费进度,consumer对某个Queue的消费offset,即消费到了该Queue的第几条消息
消息offset = 消费offset + 1 -
Consumer向Broker发送拉取请求,其中会包含其要拉取消息的Queue、消息offset及消息Tag。
-
Broker计算在该consumequeue中的queueOffset。
queueOffset = 消息offset * 20字节
-
从该queueOffset处开始向后查找第一个指定Tag的索引条目。
-
解析该索引条目的前8个字节,即可定位到该消息在commitlog中的commitlog offset
-
从对应commitlog offset中读取消息单元,并发送给Consumer
6.3、性能提升
RocketMQ中,无论是消息本身还是消息索引,都是存储在磁盘上的。其不会影响消息的消费吗?当然不会。其实RocketMQ的性能在目前的MQ产品中性能是非常高的。
因为系统通过一系列相关机制大大提升了性能
首先,RocketMQ对文件的读写操作是通过
①mmap零拷贝
进行的,将对文件的操作转化为直接对内存地址进行操作,从而极大地提高了文件的读写效率;
其次,consumequeue中的数据是顺序存放的,还引入了
②PageCache的预读取机制
,使得对consumequeue文件的读取几乎接近于内存读取,即使在有消息堆积情况下也不会影响性能
PageCache机制
,页缓存机制,是OS对文件的缓存机制,用于加速对文件的读写操作。一般来说,程序对文件进行顺序读写 的速度几乎接近于内存读写速度,主要原因是由于OS使用
PageCache机制对读写访问操作进行性能优化,将一部分的内存用作PageCache
。
写操作
:OS会先将数据写入到PageCache中,随后会以异步方式由pdflush(page dirty flush)内核线程将Cache中的数据刷盘到物理磁盘;
读操作
:若用户要读取数据,其首先会从PageCache中读取,若没有命中,则OS在从物理磁盘上加载该数据到PageCache的同时,也会顺序对其相邻数据块中的数据进行预读取。
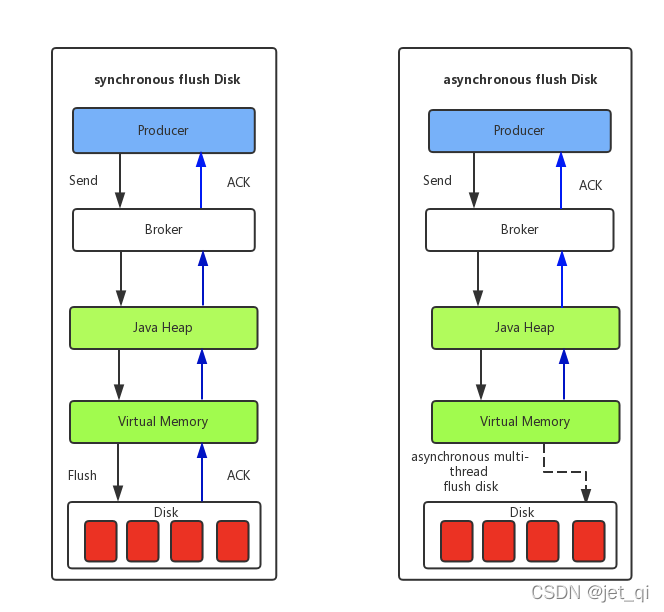
RocketMQ中可能会影响性能的是对commitlog文件的读取。因为对commitlog文件来说,读取消息时会产生大量的随机访问,而随机访问会严重影响性能。不过,如果选择合适的系统IO调度算法,比如设置调度算法为Deadline(采用SSD固态硬盘的话),随机读的性能也会有所提升。
RocketMQ主要通过MappedByteBuffer对文件进行读写操作。其中,利用了NIO中的FileChannel模型将磁盘上的物理文件直接映射到用户态的内存地址中(这种Mmap的方式减少了传统IO将磁盘文件数据在操作系统内核地址空间的缓冲区和用户应用程序地址空间的缓冲区之间来回进行拷贝的性能开销),将对文件的操作转化为直接对内存地址进行操作,从而极大地提高了文件的读写效率(正因为需要使用内存映射机制,故RocketMQ的文件存储都使用定长结构来存储,方便一次将整个文件映射至内存)。
【采用MappedByteBuffer这种内存映射的方式有几个限制,其中之一是一次只能映射1.5~2G 的文件至用户态的虚拟内存,这也是为何RocketMQ默认设置单个CommitLog日志数据文件为1G的原因了】
6.4、与Kafka的对比
RocketMQ的很多思想来源于Kafka,其中commitlog与consumequeue就是。
RocketMQ中的commitlog目录与consumequeue的结合就类似于Kafka中的partition分区目录。mappedFile文件就类似于Kafka中的segment段
Kafka中的Topic的消息被分割为一个或多个partition。partition是一个物理概念,对应到系统上就是topic目录下的一个或多个目录。每个partition中包含的文件称为segment,是具体存放消息的文件。
Kafka中消息存放的目录结构是:topic目录下有partition目录,partition目录下有segment文件
Kafka中没有二级分类标签Tag这个概念
Kafka中无需索引文件。因为生产者是将消息直接写在了partition中的,消费者也是直接从partition中读取数据的
三、indexFile
除了通过通常的指定Topic进行消息消费外,RocketMQ还提供了根据key进行消息查询的功能。该查询是通过store目录中的index子目录中的indexFile进行索引实现的快速查询。当然,这个indexFile中的索引数据是在包含了key的消息被发送到Broker时写入的。如果消息中没有包含key,则不会写入
6.5、消息的消费
消费者从Broker中获取消息的方式有两种:pull拉取方式和
push推动方式
。消费者组对于消息消费的模式又分为两种:
集群消费Clustering
和广播消费Broadcasting
1 获取消费类型
拉取式消费
-
Consumer主动从Broker中拉取消息,主动权由Consumer控制。一旦获取了批量消息,就会启动消费过程。不过,
该方式的实时性较弱
,即Broker中有了新的消息时消费者并不能及时发现并消费。 - 由于拉取时间间隔是由用户指定的,所以在设置该间隔时需要注意平稳:间隔太短,空请求比例会增加;间隔太长,消息的实时性太差
推送式消费
- 该模式下Broker收到数据后会主动推送给Consumer。该获取方式一般实时性较高。
-
该获取方式是
典型的发布-订阅模式
,即Consumer向其关联的Queue注册了监听器,一旦发现有新的消息到来就会触发回调的执行,回调方法是Consumer去Queue中拉取消息。而这些都是基于Consumer与Broker间的长连接的。长连接的维护是需要消耗系统资源的.
对比
- pull:需要应用去实现对关联Queue的遍历,实时性差;但便于应用控制消息的拉取
- push:封装了对关联Queue的遍历,实时性强,但会占用较多的系统资源
2 消费模式
广播消费
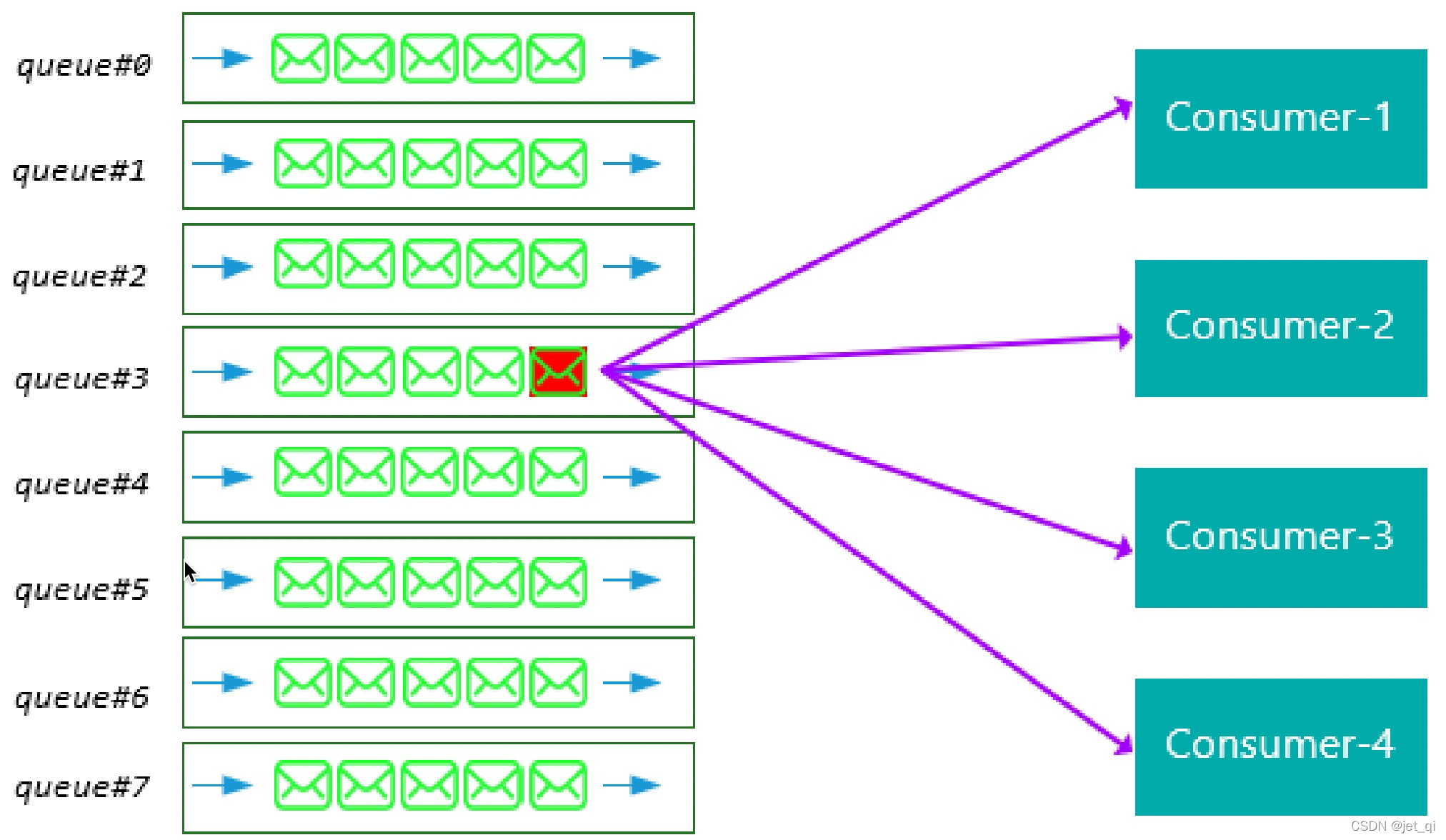
广播消费模式下,相同Consumer Group的每个Consumer实例都接收同一个Topic的全量消息。即每条消息都会被发送到Consumer Group中的每个Consumer。
-
广播方式不提供失败重试特性,即消费失败后,失败消息不再重试,继续消费新的消息
。
集群消费
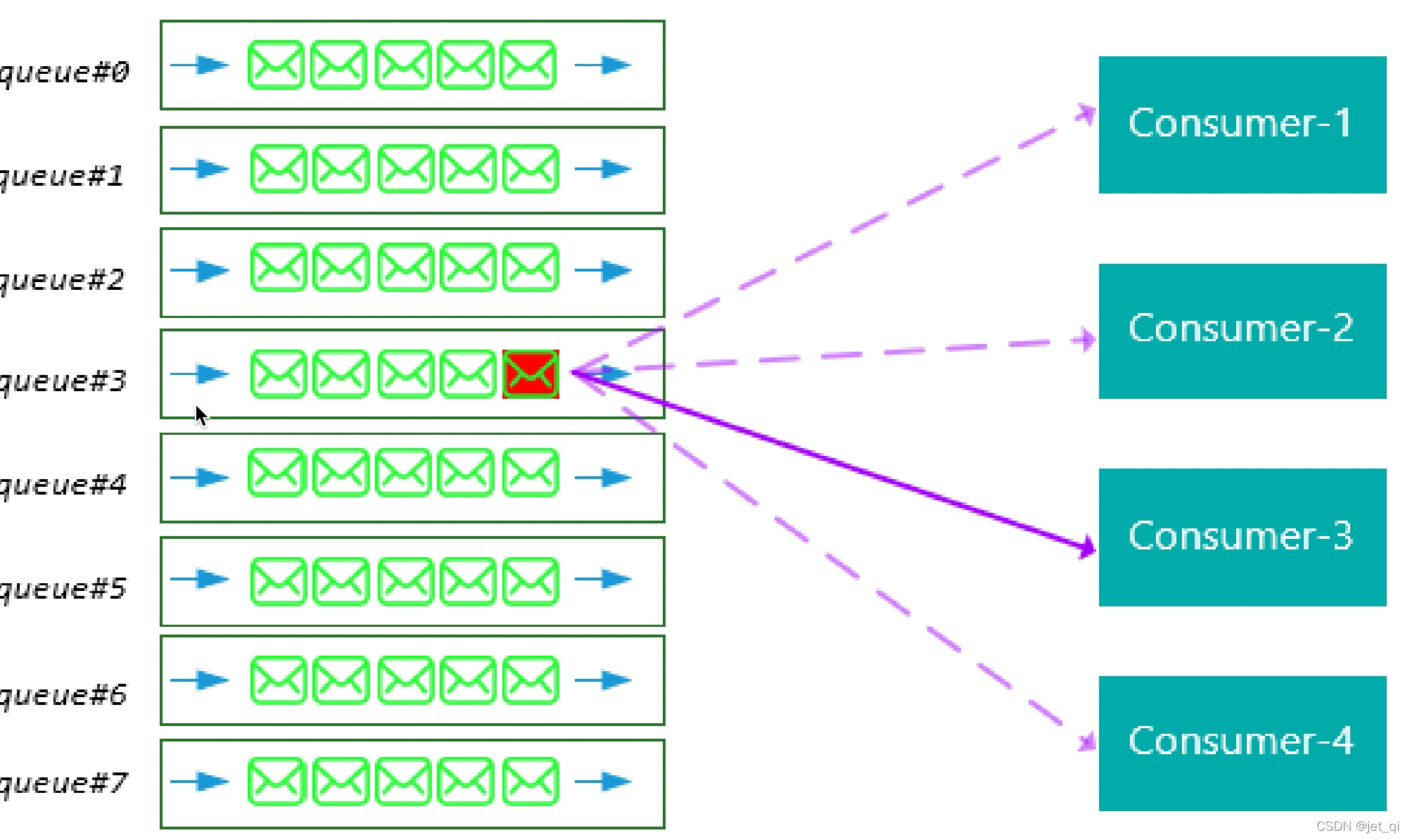
集群消费模式下,相同Consumer Group的每个Consumer实例平均分摊同一个Topic的消息。即每条消息只会被发送到Consumer Group中的某个Consumer
消费并行度问题
| 消息类型 | 消费并发度 |
|---|---|
| 普通消息 | 单节点线程数*节点数量 |
| 定时和延时消息 | 单节点线程数*节点数量 |
| 事务消息 | 单节点线程数*节点数量 |
| 顺序消息 | Min单(节点线程数*节点数量,分区数) |
消费线程数:
默认20 RocketMQ 4.7之后 有最大最小限制,默认都是20
/** Minimum consumer thread number */
private int consumeThreadMin = 20;
/** Max consumer thread number */
private int consumeThreadMax = 20;
如何动态修改线上单机消费线程数:
zcy.zmq.ext.consumerHints.TOPIC_消费组名称.consumeThreadNum (非4.7、重启应用后生效)
- 例如zcy.zmq.ext.consumerHints.ZCY_ITEM_CRAWLER_TASK_GID_C_ZCY_ITEM_CRAWLER_TASK.consumeThreadNum
消息进度保存
- 广播模式:消费进度保存在consumer端。因为广播模式下consumer group中每个consumer都会消费所有消息,但它们的消费进度是不同。所以consumer各自保存各自的消费进度。
-
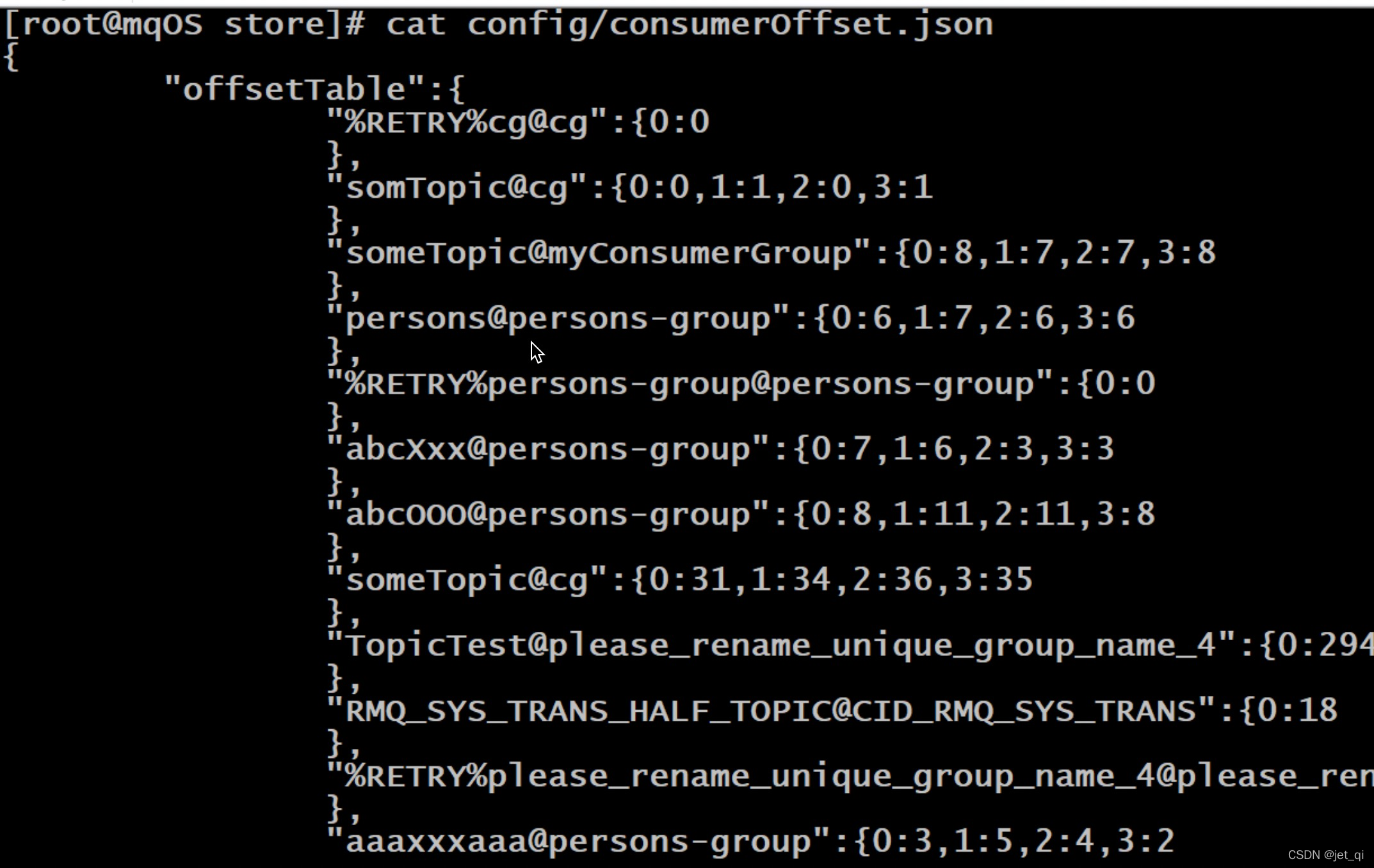
集群模式:消费进度保存在broker中
。consumer group中的所有consumer共同消费同一个Topic中的消息,同一条消息只会被消费一次。消费进度会参与到了消费的负载均衡中,故消费进度是需要共享的。下图是broker中存放的各个Topic的各个Queue的消费进度。
3 Rebalance机制
Rebalance机制讨论的前提是:集群消费
什么是Rebalance
-
Rebalance即再均衡,指的是,将⼀个Topic下的多个Queue在同⼀个Consumer Group中的多个Consumer间进行重新分配的过程
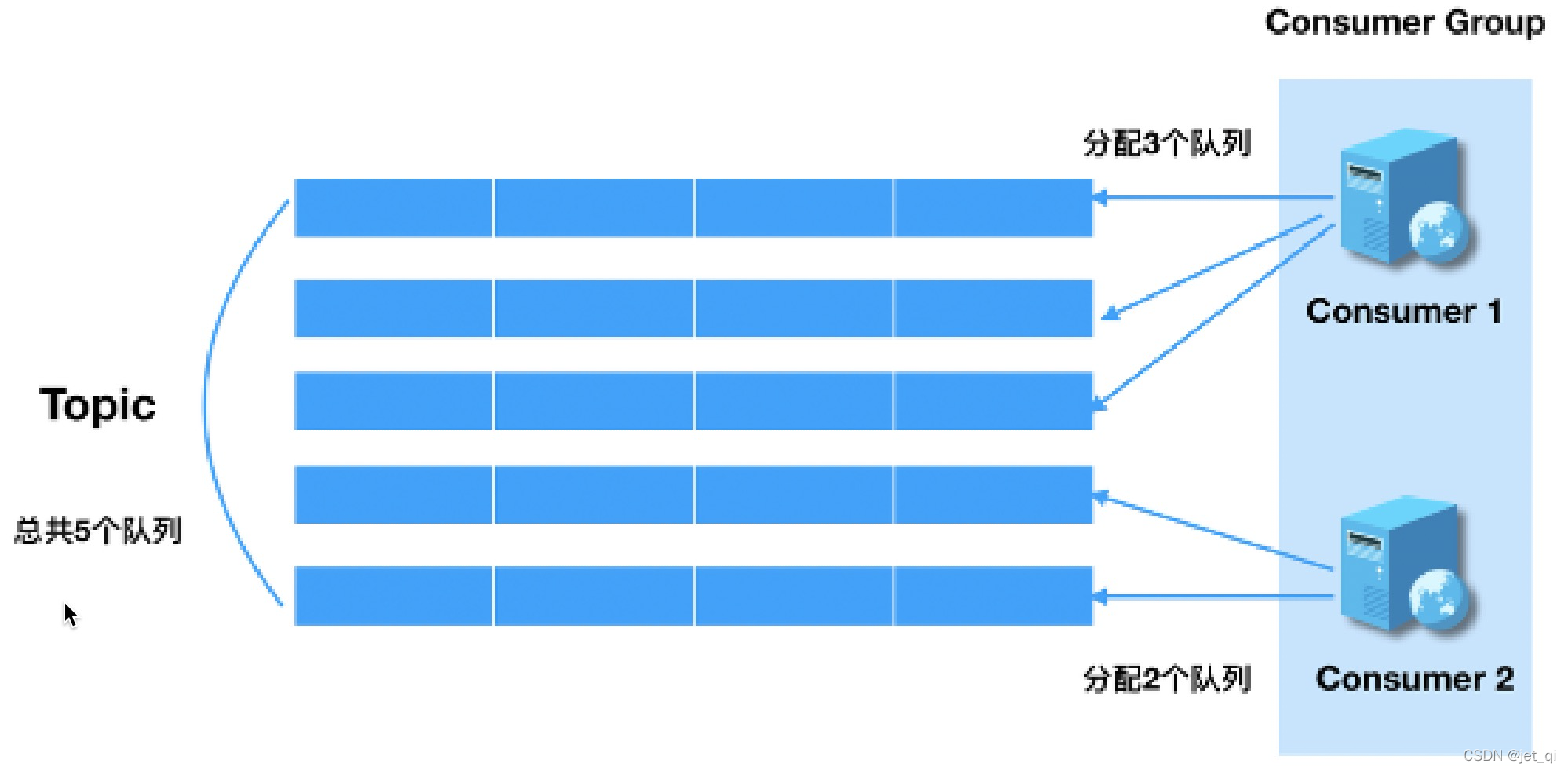
Rebalance机制的本意是为了提升消息的并行消费能力。例如,⼀个Topic下5个队列,在只有1个消费者的情况下,这个消费者将负责消费这5个队列的消息。如果此时我们增加⼀个消费者,那么就可以给其中⼀个消费者分配2个队列,给另⼀个分配3个队列,从而提升消息的并行消费能力。
Rebalance限制
- 由于⼀个队列最多分配给⼀个消费者,因此当某个消费者组下的消费者实例数量大于队列的数量时,多余的消费者实例将分配不到任何队列。
Rebalance危害
- Rebalance的在提升消费能力的同时,也带来一些问题:
- 消费暂停:在只有一个Consumer时,其负责消费所有队列;在新增了一个Consumer后会触发Rebalance的发生。此时原Consumer就需要暂停部分队列的消费,等到这些队列分配给新的Consumer后,这些暂停消费的队列才能继续被消费。
- 消费重复:Consumer 在消费新分配给自己的队列时,必须接着之前Consumer 提交的消费进度的offset继续消费。然而默认情况下,offset是异步提交的,这个异步性导致提交到Broker的offset与Consumer实际消费的消息并不一致。这个不一致的差值就是可能会重复消费的消息.
同步提交
:consumer提交了其消费完毕的一批消息的offset给broker后,需要等待broker的成功ACK。当收到ACK后,consumer才会继续获取并消费下一批消息。在等待ACK期间,consumer是阻塞的。
异步提交
:consumer提交了其消费完毕的一批消息的offset给broker后, 不需要等待broker的成功ACK。consumer可以直接获取并消费下一批消息。
对于一次性读取消息的数量,需要根据具体业务场景选择一个相对均衡的是很有必要的。因为数量过大,系统性能提升了,但产生重复消费的消息数量可能会增加;数量过小,系统性能会下降,但被重复消费的消息数量可能会减少
消费突刺:由于Rebalance可能导致重复消费,如果需要重复消费的消息过多,或者因为Rebalance暂停时间过长从而导致积压了部分消息。那么有可能会导致在Rebalance结束之后瞬间需要消费很多消息
Rebalance产生的原因
导致Rebalance产生的原因,无非就两个:消费者所订阅Topic的Queue数量发生变化,或消费者组中消费者的数量发生变化。
1)Queue数量发生变化的场景:
- Broker扩容或缩容
- Broker升级运维
- Broker与NameServer间的网络异常
-
Queue扩容或缩容
2)消费者数量发生变化的场景: - Consumer Group扩容或缩容
- Consumer升级运维
- Consumer与NameServer间网络异常
Rebalance过程
- 在Broker中维护着多个Map集合,这些集合中动态存放着当前Topic中Queue的信息、Consumer Group中Consumer实例的信息。一旦发现消费者所订阅的Queue数量发生变化,或消费者组中消费者的数量发生变化,立即向Consumer Group中的每个实例发出Rebalance通知
TopicConågManager:key是topic名称,value是TopicConåg。TopicConåg中维护着该Topic中所有Queue的数据。
ConsumerManager:key是Consumser Group Id,value是ConsumerGroupInfo。 ConsumerGroupInfo中维护着该Group中所有Consumer实例数据。
ConsumerOffsetManager:key为 Topic与订阅该Topic的Group的组合,即topic@group,value是一个内层Map。内层Map的key为QueueId,内层Map的value为该Queue的消费进度offset
Consumer实例在接收到通知后会采用Queue分配算法自己获取到相应的Queue,即由Consumer实例自主进行Rebalance。
与Kafka对比
在Kafka中,一旦发现出现了Rebalance条件,Broker会调用Group Coordinator来完成Rebalance。Coordinator是Broker中的一个进程。Coordinator会在Consumer Group中选出一个Group Leader。由这个Leader根据自己本身组情况完成Partition分区的再分配。这个再分配结果会上报给Coordinator,并由Coordinator同步给Group中的所有Consumer实例。
Kafka中的Rebalance是由Consumer Leader完成的。而RocketMQ中的Rebalance是由每个Consumer自身完成的,Group中不存在Leader。
4 Queue分配算法
一个Topic中的Queue只能由Consumer Group中的一个Consumer进行消费,而一个Consumer可以同时消费多个Queue中的消息。那么Queue与Consumer间的配对关系是如何确定的,即Queue要分配给哪个Consumer进行消费,也是有算法策略的。常见的有四种策略。这些策略是通过在创建Consumer时的构造器传进去的。
①平均分配策略
②环形平均策略
③一致性hash策略
- 该算法会将consumer的hash值作为Node节点存放到hash环上,然后将queue的hash值也放到hash环上,通过顺时针方向,距离queue最近的那个consumer就是该queue要分配的consumer
-
存在的问题:分配不均
④同机房策略
对比
一致性hash算法存在的问题:两种平均分配策略的分配效率较高,一致性hash策略的较低。因为一致性hash算法较复杂。另外,一致性hash策略分配的结果也很大可能上存在不平均的情况。
一致性hash算法存在的意义:
- 其可以有效减少由于消费者组扩容或缩容所带来的大量的Rebalance
-
应用场景
:Consumer数量变化频繁的场景。
5 至少一次原则
RocketMQ有一个原则:每条消息必须要被成功消费一次。
那么什么是成功消费呢?Consumer在消费完消息后会向其消费进度记录器提交其消费消息的offset,offset被成功记录到记录器中,那么这条消费就被成功消费了
什么是消费进度记录器?
对于广播消费模式来说,Consumer本身就是消费进度记录器。
对于集群消费模式来说,Broker是消费进度记录器
6.6、订阅关系的一致性
订阅关系的一致性指的是,同一个消费者组(Group ID相同)下所有Consumer实例所订阅的Topic与Tag及对消息的处理逻辑必须完全一致。否则,消息消费的逻辑就会混乱,甚至导致消息丢失
1 正确订阅关系
多个消费者组订阅了多个Topic,并且每个消费者组里的多个消费者实例的订阅关系保持了一致。
6.7、offset管理
指的是Consumer的消费进度offset
- 消费进度offset是用来记录每个Queue的不同消费组的消费进度的。根据消费进度记录器的不同,可以分为两种模式:本地模式和远程模式
1 offset本地管理模式
-
当消费模式为
广播消费
时,offset使用本地模式存储。因为每条消息会被所有的消费者消费,每个消费者管理自己的消费进度,各个消费者之间不存在消费进度的交集。 - Consumer在广播消费模式下offset相关数据以json的形式持久化到Consumer本地磁盘文件中
2、offset远程管理模式(为了保证Rebalance机制)
-
当消费模式为
集群消费
时,offset使用远程模式管理。因为所有Cosnumer实例对消息采用的是均衡消费,所有Consumer共享Queue的消费进度 - Consumer在集群消费模式下offset相关数据以json的形式持久化到Broker磁盘文件中
- Broker启动时会加载这个文件,并写入到一个双层Map(ConsumerOffsetManager)。外层map的key为topic@group,value为内层map。内层map的key为queueId,value为offset。当发生Rebalance时,新的Consumer会从该Map中获取到相应的数据来继续消费。
3 offset用途
- 消费者是如何从最开始持续消费消息的?消费者要消费的第一条消息的起始位置是用户自己通过consumer.setConsumeFromWhere()方法指定的。
public enum ConsumeFromWhere {
// 从queue的当前最后一条消息开始消费
CONSUME_FROM_LAST_OFFSET,
/** @deprecated */
@Deprecated
CONSUME_FROM_LAST_OFFSET_AND_FROM_MIN_WHEN_BOOT_FIRST,
/** @deprecated */
@Deprecated
CONSUME_FROM_MIN_OFFSET,
/** @deprecated */
@Deprecated
CONSUME_FROM_MAX_OFFSET,
// 从queue的第一条消息开始消费
CONSUME_FROM_FIRST_OFFSET,
// 从指定的具体时间戳位置的消息开始消费。这个具体时间戳是通过另外一个语句指定的
CONSUME_FROM_TIMESTAMP;
private ConsumeFromWhere() {
}
}
当消费完一批消息后,Consumer会提交其消费进度offset给Broker,Broker在收到消费进度后会将其更新到那个双层Map(ConsumerOffsetManager)及consumerOffset.json文件中,然后向该Consumer进行ACK,而ACK内容中包含三项数据:
当前消费队列的最小offset(minOffset)、最大offset(maxOffset)、及下次消费的起始offset(nextBeginOffset)
4 重试队列
当rocketMQ对消息的消费出现异常时,会将发生异常的消息的offset提交到Broker中的重试队列。系统在发生消息消费异常时会为当前的topic@group创建一个重试队列,该队列以%RETRY%开头,到达重试时间后进行消费重试。
5 offset的同步提交与异步提交
集群消费模式下,Consumer消费完消息后会向Broker提交消费进度offset,其提交方式分为两种
同步提交:消费者在消费完一批消息后会向broker提交这些消息的offset,然后等待broker的成功响应
异步提交:消费者在消费完一批消息后向broker提交offset,但无需等待Broker的成功响应,可以继续读取并消费下一批消息.
6.8、消费幂等
当出现消费者对某条消息重复消费的情况时,重复消费的结果与消费一次的结果是相同的,并且多次消费并未对业务系统产生任何负面影响,那么这个消费过程就是消费幂等的。
幂等:若某操作执行多次与执行一次对系统产生的影响是相同的,则称该操作是幂等的。
在互联网应用中,尤其在网络不稳定的情况下,消息很有可能会出现重复发送或重复消费。如果重复的消息可能会影响业务处理,那么就应该对消息做幂等处理。
2 消息重复的场景分析
什么情况下可能会出现消息被重复消费呢?最常见的有以下三种情况:
①发送时消息重复
- 当一条消息已被成功发送到Broker并完成持久化,此时出现了网络闪断,从而导致Broker对Producer应答失败。 如果此时Producer意识到消息发送失败并尝试再次发送消息,此时Broker中就可能会出现两条内容相同并且Message ID也相同的消息,那么后续Consumer就一定会消费两次该消息
②消费时消息重复
消息已投递到Consumer并完成业务处理,当Consumer给Broker反馈应答时网络闪断,Broker没有接收到消费成功响应。
为了保证消息至少被消费一次的原则
,Broker将在网络恢复后再次尝试投递之前已被处理过的消息。此时消费者就会收到与之前处理过的内容相同、Message ID也相同的消息
③Rebalance时消息重复
当Consumer Group中的Consumer数量发生变化时,或其订阅的Topic的Queue数量发生变化时,会触发Rebalance,此时Consumer可能会收到曾经被消费过的消息
3 通用解决方案
两要素
幂等解决方案的设计中涉及到两项要素:
幂等令牌
,与
唯一性处理
。只要充分利用好这两要素,就可以设计出好的幂等解决方案。
-
幂等令牌:是生产者和消费者两者中的既定协议,
通常指具备唯⼀业务标识的字符串
。例如,订单号、流水号。一般由Producer随着消息一同发送来的。 - 唯一性处理:服务端通过采用⼀定的算法策略,保证同⼀个业务逻辑不会被重复执行成功多次。
- 例如,对同一笔订单的多次支付操作,只会成功一次。
解决方案
对于常见的系统,幂等性操作的通用性解决方案是:
- 首先通过缓存去重。在缓存中如果已经存在了某幂等令牌,则说明本次操作是重复性操作;若缓存没有命中,则进入下一步。
- 在唯一性处理之前,先在数据库中查询幂等令牌作为索引的数据是否存在。若存在,则说明本次操作为重复性操作;若不存在,则进入下一步。
- 在同一事务中完成三项操作:唯一性处理后,将幂等令牌写入到缓存,并将幂等令牌作为唯一索引的数据写入到DB中
以支付场景为例:
- 当支付请求到达后,首先在Redis缓存中却获取key为支付流水号的缓存value。若value不空,则说明本次支付是重复操作,业务系统直接返回调用侧重复支付标识;若value为空,则进入下一步操作
- 到DBMS中根据支付流水号查询是否存在相应实例。若存在,则说明本次支付是重复操作,业务系统直接返回调用侧重复支付标识;若不存在,则说明本次操作是首次操作,进入下一步完成唯一性处理
- 在分布式事务中完成三项操作:
- 完成支付任务
- 将当前支付流水号作为key,任意字符串作为value,通过set(key, value, expireTime)将数据写入到Redis缓存
- 将当前支付流水号作为主键,与其它相关数据共同写入到DBMS
6.9、消息堆积与消费延迟
1 概念
消息处理流程中,如果Consumer的消费速度跟不上Producer的发送速度,MQ中未处理的消息会越来越多(进的多出的少),这部分消息就被称为
堆积消息
。消息出现堆积进而会造成消息的消费延迟。
以下场景需要重点关注消息堆积和消费延迟问题:
- 业务系统上下游能力不匹配造成的持续堆积,且无法自行恢复。
- 业务系统对消息的消费实时性要求较高,即使是短暂的堆积造成的消费延迟也无法接受
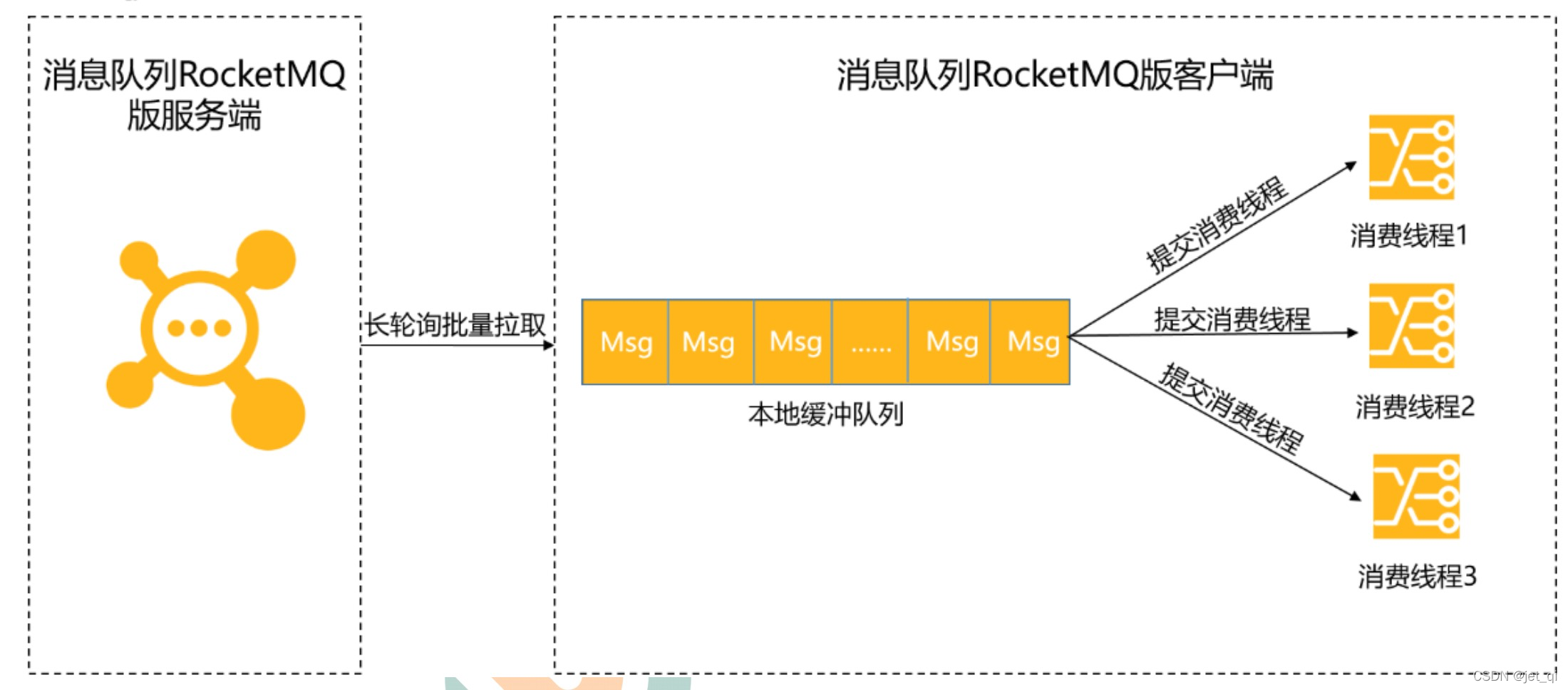
Consumer使用长轮询Pull模式消费消息时,分为以下两个阶段
消息拉取
- Consumer通过长轮询Pull模式批量拉取的方式从服务端获取消息,将拉取到的消息缓存到本地缓冲队列中
消息消费
-
Consumer将本地缓存的消息提交到消费线程中,使用业务消费逻辑对消息进行处理,处理完毕后获取到一个结果
,此时Consumer的消费能力就完全依赖于消息的消费耗时和消费并发度了
消费并发度
- 消费者端的消费并发度由单节点线程数和节点数量共同决定,其值为单节点线程数*节点数量
单节点线程数,即单个Consumer所包含的线程数量;
节点数量,即Consumer Group所包含的Consumer数量;
对于普通消息、延时消息及事务消息,并发度计算都是
单节点线程数 * 节点数量
。但对于顺序消息则是不同的。顺序消息的消费并发度等于
Topic的Queue分区数量
。
单机线程数计算
- 理想环境下单节点的最优线程数计算模型为:C *(T1 + T2)/ T1
-
C:CPU内核数
T1:CPU内部逻辑计算耗时
T2:外部IO操作耗时
注意,该计算出的数值是理想状态下的理论数据,在生产环境中,不建议直接使用。而是根据当前环境,先设置一个比该值小的数值然后观察其压测效果,然后再根据效果逐步调大线程数,直至找到在该环境中性能最佳时的值
如何避免
梳理消息的消费耗时和设置消息消费的并发度
消息的清理
消息被消费过后会被清理掉吗?不会的。
消息是被顺序存储在commitlog文件的,且消息大小不定长,所以消息的清理是不可能以消息为单位进行清理的,而是以commitlog文件为单位进行清理的。否则会急剧下降清理效率,并实现逻辑复杂。
commitlog文件存在一个过期时间,
默认为72小时,即三天
。除了用户手动清理外,在以下情况下也=会被自动清理,无论文件中的消息是否被消费过:
- 文件过期,且到达清理时间点(默认为凌晨4点)后,自动清理过期文件
- 文件过期,且磁盘空间占用率已达过期清理警戒线(默认75%)后,无论是否达到清理时间点,都会自动清理过期文件
- 磁盘占用率达到清理警戒线(默认85%)后,开始按照设定好的规则清理文件,无论是否过期。默认会从最老的文件开始清理
- 磁盘占用率达到系统危险警戒线(默认90%)后,Broker将拒绝消息写入
需要注意以下几点:
1)对于RocketMQ系统来说,删除一个1G大小的文件,是一个压力巨大的IO操作。在删除过程中,系统性能会骤然下降。所以,
其默认清理时间点为凌晨4点
,访问量最小的时间。也正因如果,我们要保障磁盘空间的空闲率,不要使系统出现在其它时间点删除commitlog文件的情况。
2)官方建议RocketMQ服务的Linux文件系统采用ext4。因为对于文件删除操作,ext4要比ext3性能更好
7、MQ如何整合到spring中去?
使用的jar包,5.11.2版本,不要使用5.12.0版本
1、创建连接工厂
- connectionfactory 端口号61616 使用brokerURL中的URL指定指定连接工厂要连接到本地机器的61616端口
2、配置生产者(声明消息的目的地)
- jmsTemplate jms工具类 queue的目的地 topic的目的地 发送消息 在messagecreator()里面写想要发送的消息
3、配置消费者
-
通过messagelistenercontainer实现,他负责接受消息,并把接受到的信息发送给真正的messagelistener进行处理。
指定三个属性:
1、表示从哪里监听的connectionfactory
2、监听的destination
3、接收到消息以后进行消息处理的messageListener
8、消息的模式?
推模式还是拉模式?
两个或多个客户端在相互发送或接受消息是,通常使用两种方法来传递消息。
- 1、消息推送(点对点),也就是有消息发送方确保接收者成功接收到消息
-
2、消息拉取 (广播) 这种方法由接收者自己去获取存储在某种邮箱里面的消息。
默认情况下只通知一次,如果接收不到此消息就没有了。如果要求消息必须送达不可以丢失的话,需要配置持久订阅。
发布消息和接收消息时需要配置发送模式为持久化。此时 如果客户端接收不到消息,消息会持久化到服务端
消息是被推送(消息生产者)和拉取的(消费端),
流程:
- 1、消息的发送者把消息发送activeMQ消息服务器进行存储,消息发送者发送消息之前,必须在mq服务器开辟一块消息空间,并给消息空间起个名
-
2、消费者监听消息空间,一旦发现这个空间有消息,立马接受。
特点:
1、一条消息可以被多消费者接受
2、消息被消费后,持久化
3、消费者必须先监听,才能获得消息内容;
4、发布订阅,只能使用监听模式接受
10、mq如何避免重复提交/消息丢失的问题?
幂等性
11、AcitveMQ的作用、原理、特点?(生产者。消费者。 p2p、订阅实现流程)
Activemq的作用就是系统之间进行通信。当然可以使用其他方式进行系统间通信,如果使用Activemq的话可以对系统之间的调用进行解耦,实现系统间的异步通信。
-
原理就是生产者生产消息,把消息发送给activemq。Activemq接收到消息,然后查看有多少个消费者,然后把消息转发给消费者,此过程中生产者无需参与。
消费者接收到消息后做相应的处理和生产者没有任何关系。 - 使用的传输协议? tcp nio ssl等等
- 特点:1.对Spring的支持 2.支持多种传送协议 3.完全支持jms规范
12、ActiveMQ在项目中如何应用的?(deprecated)
1、管理员在商品管理模块添加/更新商品时,需要把数据提交到数据库中,同时,还得把数据发送到solr索引系统,来同步索引库的商品,另一方面,缓存系统来删除此商品的缓存
因此,用到了消息队列MQ,来保证消息处理的有序性及是否能重复消费及如何保证重复消费的幂等性。
Activemq在项目中主要是完成系统之间通信,并且将系统之间的调用进行解耦。例如在添加、修改、删除商品信息后,需要将商品信息同步到solr索引库、同步缓存中的数据redis以及生成静态页面freemarker一系列操作。
- 在此场景下就可以使用activemq。一旦后台对商品信息进行修改后,就向activemq发送一条消息,然后通过activemq将消息发送给消息的消费端,消费端接收到消息可以进行相应的业务处理。
13、消息队列 参考资料:亿级流量网站架构核心技术 张开涛
使用队列保证最终一致性即可,不需要强一致性。我们也要考虑是否需要保证消息处理的有序性及如何保证,是否能重复消费及如何保证重复消费的幂等性。在实际开发中,我们经常使用队列进行异步处理、系统解耦、数据同步、流量消峰、扩展性、缓冲等。
应用场景:(优点)
-
异步处理
:用户注册后,需要发送注册成功邮件/新用户积分/优惠券等,缓存过期后,先返回过期数据,然后异步更新缓存,异步写日志等。可以提升主流程响应速度。 -
系统解耦
:比如:用户成功支付完成订单后,需要通知生产配货系统、发票系统、库存系统、推荐系统、搜索系统等进行业务处理,而未来需要支持哪些业务是不知道的,并且这些业务不需要实时处理、不需要强一致,只需要保证最终一致性即可。 -
数据同步
:比如:想把Mysql变更的数据同步到redis,或者将mysql的数据同步到mongodb,或者让机房之间的数据同步,或者主从数据同步等,此时可以考虑使用databus、canal、otter等。使用数据总线队列进行数据同步的好处是可以保证数据修改的有序性。 -
流量削峰
:系统瓶颈一般在数据库上,比如扣减库存、下单等。此时可以考虑使用队列将变更请求暂时放入队列,通过缓存+队列暂存的方式将数据库流量削峰。同样,对于秒杀系统,下单服务会是该系统的瓶颈,此时,可以使用队列进行排队和限流,从而保护下单服务,通过队列暂存或者队列限流进行流量削峰。 -
1、缓冲队列
典型的如log4j日志缓冲区,当我们使用log4j记录日志时,可以配置直字节缓冲区,字节缓冲区满后,会立即同步到磁盘,log4j是使用bufferedWriter实现的。在缓冲区满时,还是会阻塞主线程。 -
2、任务队列
线程池任务队列 默认使用linkedblockingQueue(重点)和Disruptor任务队列。如用户注册完成后,将发送邮件/送积分/送优惠券任务扔到任务队列中进行异步处理。刷数据时,将任务扔到异步处理,处理成功后在异步通知用户;删除SKU操作,在用户请求时直接将任务分解并扔到队列进行异步处理,处理成功后异步通知用户。 -
3、消息队列
消息队列有ActiveMQ,Kafka,Redis。使用消息队列存储各业务数据,其他系统根据需要订阅即可。常见的订阅模式是:点对点(一个消息只有一个消费者),发布订阅(一个消息可以有多个消费者)最常使用发布订阅模式。比如:修改商品数据,变更订单状态时,都应该将变更的信息发送到消息队列。其他模块有需要,就直接订阅该消息队列即可。一般我们在应用能够系统中采用双写模式,同时写DB和MQ,然后异构系统订阅MQ进行业务处理。没有事务保证,可能会出现数据不一致的情况。如果对一致性要求没那么严格,这种模式没什么问题。重点来了:如果在事务中发MQ,会存在事务回滚,但是MQ已经发送成功了,则需要消费者进行幂等处理(外部对接口的多次调用得到的结果是相同的)。如果事务提交慢,但是MQ已经发出去了,则此时根据MQ获取数据库的数据可能不是最新的。如果MQ发送慢,则会导致事务无法快速提交,造成数据库堵塞。同样不要在事务中掺杂RPC调用,rpc服务不稳定,同样会引起数据库阻塞。 -
4、请求队列
-
5、数据总线队列
-
6、混合队列
-
7、其他队列
15、MQ,如何做到
消息必达
? 消息的补发重传解决思路?
20181222
MQ要想尽量消息必达,架构上有两个核心设计点:
(1)消息落地 (2)消息超时、重传、确认
MQ既然将消息投递拆成了上下半场,为了保证消息的可靠投递,上下半场都必须尽量保证消息必达。
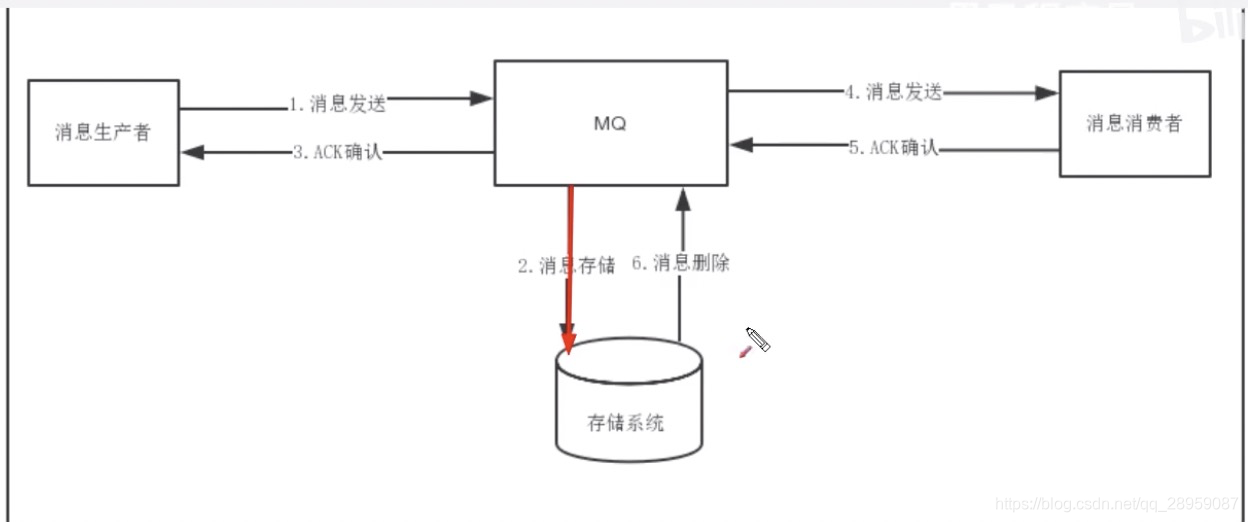
MQ-client–1–> MQ-server–4–>MQ-client
<–3– l l <–5—
2 6
db
-
MQ消息投递上半场
(1)MQ-client将消息发送给MQ-server(此时业务方调用的是API:SendMsg)
(2)MQ-server将消息落地,落地后即为发送成功
(3)MQ-server将应答ACK发送给MQ-client(此时回调业务方是API:SendCallback) -
MQ消息投递下半场
(1)MQ-server将消息发送给MQ-client(此时回调业务方是API:RecvCallback)
(2)MQ-client回复ACK给MQ-server(此时业务方主动调用API:SendAck)
(3)MQ-server收到ack,将之前已经落地的消息删除,完成消息的可靠投递 -
MQ消息投递的上下半场,都可以出现消息丢失,为了降低消息丢失的概率,MQ需要进行超时和重传。
-
上半场的超时与重传:MQ上半场的1或者2或者3如果丢失或者超时,MQ-client-sender内的timer会重发消息,直到期望收到3,如果重传N次后还未收到,则SendCallback回调发送失败,需要注意的是,这个过程中MQ-server可能会收到同一条消息的多次重发。
-
下半场的超时与重传:MQ下半场的4或者5或者6如果丢失或者超时,MQ-server内的timer会重发消息,直到收到5并且成功执行6,这个过程可能会重发很多次消息,一般采用指数退避的策略,先隔x秒重发,2x秒重发,4x秒重发,以此类推,需要注意的是,这个过程中MQ-client-receiver也可能会收到同一条消息的多次重发
16、MQ、如何做到消息幂等? 幂等性的解决思路?20181222(任意多次执行所产生的影响均与一次执行的影响相同)
- 为保证消息的可达性,超时、重传、确认机制可能导致消息总线、或者业务方收到重复的消息,从而对业务产生影响。
例子:上架图书,后台上传模块负责图书上架,下游索引模块负责更新索引库,通过MQ异步通知,不管是上半场的ACK丢失,导致MQ收到重复的消息,还是下面的ACK丢失,导致索引系统收到重复的商品id。
上半场的幂等
:步骤2落地重复的消息,对每条消息,MQ系统内部必须生成一个inner-msg-id,作为去重和幂等的依据,这个内部消息ID的特性是:全局唯一,MQ生成,具备业务无关性。
下半场的幂等
:业务消息体中,必须有一个biz-id,作为去重和幂等的依据,这个业务ID的特性是:对于同一个业务场景(支付ID,订单ID,帖子ID),全局唯一,由业务消息消费方负责判重,以保证幂等。
mq为了保证消息必达,消息上下半场均可能发送重复消息,如何保证消息的幂等性?
总结:MQ-client生成inner-msg-id,保证上半场幂等 这个id全局唯一,业务无关,由MQ保证
业务发送发带入biz-id,业务接收方去重保证幂等,这个ID对单业务唯一,业务相关,对MQ透明
RocketMQ中的处理方法:
已业务唯一标识作为幂等处理的关键依据,而业务的唯一标识可以通过消息key进行设置:
Message msg = new Message();
Msg.setKey(“ORDERID_100”);
sendResult sendResult = producer.send(message);
订阅方收到消息时可以根据消息的key进行幂等处理:
public Action consumer(Message message, ConsumeContext context){
String key = message.getKey();
//根据业务唯一标识的key做幂等处理
}
17、MQ、如何做到延时消息?
例如:图书商城订单完成后,如果用户一直不评价,一周后会将自动评价。
高效延时消息,包含两个重要的数据结构
(1)
环形队列
,例如可以创建一个包含3600个slot的环形队列(本质是个数组)
(2)
任务集合
,环上每一个slot是一个Set
同时,启动一个timer,这个timer每隔1s,在上述环形队列中移动一格,有一个Current Index指针来标识正在检测的slot
Task结构中有两个很重要的属性:
(1)Cycle-Num:当Current Index第几圈扫描到这个Slot时,执行任务
(2)Task-Function:需要执行的任务指针
假设当前Current Index指向第一格,当有延时消息到达之后,例如希望3610秒之后,触发一个延时消息任务,只需:
(1)计算这个Task应该放在哪一个slot =11 (2)计算这个Task的Cycle-Num =1 减法运算 如果变为0,说明马上要执行这个Task了,取出Task-Funciton,使用了“延时消息”方案之后,只需要在订单完成后,触发一个48小时之后的延时消息即可。
总结:
环形队列是一个实现“延时消息”的好方法,开源的MQ好像都不支持延迟消息
对比:
- rabbitMQ:如何实现消息延时?
18、MQ、如何做到流量控制? 消息的堆积解决思路?20181222
系统瓶颈一般在数据库上,比如扣减库存、下单等。此时可以考虑使用队列将变更请求暂时放入队列,通过缓存+队列暂存的方式将数据库流量削峰。
流量冲击
:订单模块发起下单操作,下游模块完成业务逻辑(库存检查,库存冻结,余额检查,余额冻结,订单生成,余额扣减,库存扣减,生成流水,余额解冻,库存解冻)
上游业务简单,下游业务复杂,很有可能上游不限速的下单,导致下游系统被压垮。
如何缓冲流量?
可以利用哪个MQ来缓冲,MQ-server推模式改为MQ-client拉模式。MQ-client根据自己的处理能力,每隔一定时间,或者每次拉取若干条消息,实施流控,达到保护自身的效果。
总结
:MQ-client提供拉模式,定时或者批量拉取,可以削平流量,下游自我保护的作用(MQ来做)
要想提升整体吞吐量,需要下游优化,例如批量处理等方式。
19、了解哪些消息队列,及其对比?
| 消息中间件 | 开发语言 | 单机吞吐量 | 时效性 | 消息的存储 | 可用性 | 功能特性 |
|---|---|---|---|---|---|---|
| activeMQ | java | 万级 | ms级 | 关系型数据库KahaDB | 高(主从架构) | 成熟的产品,在很多公司得到应用,有较多的文档;各种协议支持较好 |
| RabbitMQ | erlang | 万级 | us级 | 文件系统 | 高(主从架构) | 基于erlang开发,所以并发能力很强,性能极其好,延时2很低,管理界面较丰富 |
| RocketMQ | java | 10万级 | ms级 | 文件系统 | 非常高(分布式架构) | Mq功能比较完善,扩展性佳 |
| Kafka | scala | 10万级 | ms级以内 | 文件系统 | 非常高(分布式架构) | 只支持主要的mq功能,像一些消息查询,消息回溯等功能没有提供,毕竟是为大数据准备的,在大数据领域应用广。 |
特点补充
它能够以广播和点对点的技术实现队列,它少量代码就可以高效地实现高级应用场景
它非常重量级,更适合于企业级的开发。同时实现了Broker构架,这意味着消息在发送给客户端时先在中心队列排队。对路由,负载均衡或者数据持久化都有很好的支持
1、是一个分布式的、支持分区的、多副本的、支持zookeeper协调的分布式消息系统
2、可以实时的处理大量数据以满足各种需求场景:比如:基于Hadoop的批处理系统、低延时的实时系统、storm/spark流式处理引擎、web/ nginx日志、访问日志、消息服务等
3、高性能跨语言分布式发布/订阅消息队列系统,可以处理大规模网站中所有动作流数据:网页浏览、搜索和其他用户的行为
3、kafka(scala语言开发): java优先
- 1、高吞吐量、低延时:kafka每秒可以处理几十万条消息、他的延迟最低只有几毫秒,每个topic(广播)可以分为多个partition、consumer group对partition进行consume操作
- 2、可扩展性:kafka集群支持热扩展
- 3、持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
- 4、容错性:允许集群中结点失败(若副本数据为n,则允许n-1个结点失败)
-
5、高并发:支持数千个客户端同时读写
原理
:通常由两种消息模型:队列和发布-订阅模式,kafka为这两种模型提供了单一的消费者抽象模型:消费者组(消费者用一个消费者组名标记自己) 一个发布在topic上的消息被分发给此消费者组中的一个消费者。假如所有的消费者都在一个组中,那么这就变成了queue模型。假如所有的消费者都在不同的组中,那么就完全变成了发布-订阅模型.
特点
:(消息的顺序保证性强)
- 1、kafka 能够保证生产者发送到一个特定的Topic的分区上,消息将会按照它们发送的顺序依次加入
- 2、如果一个 Topic 配置了复制因子(replication facto)为 N,那么可以允许 N-1 服务器宕机而不丢失任何已经提交(committed)的消息
kafka设计思想,底层原理 个推
Controller在ZooKeeper注册Watch:
- kafka broker集群收zookeeper管理,所有kafka broker结点一起去zookeeper上注册一个临时结点,因为只有一个kafka broker会注册成功,所以这个成功。在zookeeper上注册临时结点的这个kafka broker会成为 Kafka Broker Controller,其他的 Kafka broker 叫 Kafka Broker follower。这个 Controller 会监听其他的 Kafka Broker 的所有信息,如果这个kafka broker controller宕机了,在zookeeper上面的那个临时节点就会消失,此时所有的broker,又会去zookeeper上注册临时结点。
-
broker宕机会发生什么情况?
这个 kafka broker controller 会读取该宕机broker上所有的partition在zookeeper上的状态,并选取ISR列表中的一个replica作为partition leader。如果ISR列表中的replica全挂,选一个幸存的replica作为leader;如果该partition的所有的replica都宕机了,则将新的leader设置为-1,等待恢复,等待ISR中的任一个Replica“活”过来,并且选它作为Leader;或选择第一个“活”过来的 Replica(不一定是ISR中的)作为Leader。这个broker宕机的事情,kafka controller也会通知zookeeper,zookeeper会通知其他的kafka broker。
20、ActiveMQ 如果数据提交不成功怎么办?
Activemq 有两种通信方式,点到点形式和发布订阅模式。
- 1、如果是点到点模式的话,如果消息发送不成功此消息默认会保存到 activemq 服务端知道有消费者将其消费,所以此时消息是不会丢失的。
- 2、如果是发布订阅模式的通信方式,默认情况下只通知一次,如果接收不到此消息就没有了。这种场景只适用于对消息送达率要求不高的情况。
- 如果要求消息必须送达不可以丢失的话,需要配置持久订阅。每个订阅端定义一个id,在订阅是向 activemq 注册。发布消息和接收消息时需要配置发送模式为持久化。此时如果客户端接收不到消息,消息会持久化到服务端,直到客户端正常接收后为止。
21、ActiveMQ消息是被顺序接受的吗?如果不是,如何确保它具有顺序的消息?如何保证消息的有序性?20181222
不能。所以我们应该用zookeeper来选主,让主去消费队列,并且队列要设置成exclusive。这样我们就保证队列中的消息是被顺序消费的
22、MQ集群部署?
ActiveMQ集群部署
- 高可用的方案主要是基于Master-Slave模式实现的冷备方案,较为常用的包括基于共享文件系统的master-slave架构和基于共享数据库的master-slave架构(某个表的排它锁)。当master启动时,他会获得共享文件系统的排它锁,而其他slave则stand-by,不对外提供服务,同时等待获取master的排它锁。假如master连接中断或者发生异常,那么他的排它锁会立即四方,此时便会有另外一个slave能够争夺到master的排它锁,从而成为master,对外提供服务。之前故障的master重新连接到共享文件系统系统时,他将作为slave等待,直到master再一次发生异常。
客户端使用failover来容错(失败自动切换,当出现失败,重试其它服务器)
RocketMQ集群搭建
- producer:消息的发送方,举例:发信人
- consumer:消息的接收方,举例:收信人
- broker:暂存和传输消息,举例:邮局
- NameServer:管理broker,举例:各个邮局的管理机构
- topic:区分消息的种类,一个发送者可以发送消息给一个或多个topic,一个接受者可以订阅一个或多个topic消息
- message queue:相当于topic的分区,用于并行发送或接受消息
集群特点:
- 1、nameserver 是一个几乎无状态节点,可集群部署,节点之间无任何信息同步;
- 2、broker部署相对复杂,broker分为master和slave,一个master可以对应多个slave,但是一个slave只能对应一个master;
- 3、producer与namespace集群中的其中一个节点(随机选择)建立长连接,定期从nameserver取topic路由信息,并向提供topic服务的master发送心跳。producer完全无状态,可集群部署。
- 4、consumer与nameserver集群中的其中一个节点(随机选择)建立长连接,定期从nameserver取topic路由信息,并向提供topic服务的master,slave建立长连接,且定时向master,slave发送心跳,consumer既可以从master订阅消息,也可以从slave订阅消息,订阅规则由broker配置决定。
23、MQ的持久化存储方案(被政采云问到了)
ActiveMQ接收到Message后需要借助持久化方案来完成消息存储。可以通过多种介质完成存储:磁盘文件系统、ActiveMQ内置数据库或第三方关系型数据库
1、 使用自带的db KahaDB (默认的持久化存储方案)
KahaDB 文件所在位置是您的 ActiveMQ 安装路径下的/data/KahaDB 子目录下(没看到)
官方认为 KahaDB 使用了更少的文件描述符,设计目标是支持事务日志、可靠、可扩展、速度快等
2、 AMQ
不依赖于第三方数据库,用户能够快速启动和运行
在此方案下消息以日志的形式实现持久化,存放在 Data Log 里。
3、JDBC
支持使用关系型数据库进行持久化存储–通过JDBC实现的数据库连接。可以支持的关系型数据库包括:db2,mysql,oracle,sqlserver,sybase等
许多企业使用关系数据库作为存储,是因为他们更愿意充分利用这些数据库资源,比如已有的热备和负载方案
4、内存存储
内存消息存储器将所有持久消息保存在内存中。在仅存储有限数量message的情况下,内存消息存储会很有用,因为message通常会被快速消耗。
一般用于实时消息的缓存,只针对非持久订阅的消费者提供了5种订阅恢复策略,可以极大程度增强非持久订阅的可用性。
24、RocketMq的存储机制?(消息的存储和发送)
- 1、使用顺序写,保证消息存储的速度
-
2、MapppedByteBuffer 零拷贝技术(省略了内核态到用户态的复制过程) 默认commitLog的大小是 1g (
为了保证使用零拷贝
)- commitLog:存储消息的元数据
- consumerQueue:存储消息在commitLog的索引
- indexFile:为了消息查询提供了一种通过key或时间区间来查询消息的方法,这种通过indexFile来查询消息的方法不影响发送与消费消息的主流程。
- 刷盘机制:同步刷盘(可靠性高)和异步刷盘(吞吐量高 推荐)
- 高可用机制:broker双主双从保证高可用性(采用同步复制方式),name server通过集群保证高可用性
25、RabbitMQ 由Erlang语言开发 端口号5672 (out)
1、rabbitMQ基本概念
- 1、broker:就是消息队列服务器实体
- 2、producer:生产者,就是投递消息的程序
- 3、consumer:消费者,就是接受消息的程序
- 4、exchange:消息交换机,他指定消息按什么规则,路由到哪个队列
- 5、routing key:路由关键字,由生产者封装在消息头中,exchange根据这个关键字进行消息投递
- 6、message queue:消息队列载体,每个消息都会被投入到一个或多个队列
- 7、binding:绑定,他的作用就是把exchange和Queue按照路由规则绑定起来
- 8、binding key:message queue对接受消息的限制条件,有消费者在binding时指定
2、消息的分发流程
- 1、productor发送消息
- 2、exchangge接受Message,解析消息头得到routing key
- 3、exchange 有exchange type决定routingkey和bindingkey匹配方式,或是否互虐routingkey,广播发送
- 4、exchange决策完成后将消息发送给满足条件的队列
- 5、监听该队列的Consumer读取消息
3、Exchange 类型
它是Exchange在路由消息时的分发策略,目前RabbitQueue常见的类型有三种:Direct Exchange,Fanout Exchange,Topic Exchange,
实际项目中会根据业务特点进行选型
-
1、direct exchange
简单的直接匹配,通过routingkey和bindingkey匹配,匹配不上所有routingkey的消息被丢弃 -
2、Fanout Exchange
不使用routingkey匹配,当向所有消费者广播消息时,只要绑定到exchange的队列都可以接受消息。 -
3、topic exchange:
在 Direct Exchange 基础上增加了模糊匹配,BindingKey 可以使用
和#通配符,而RoutingKey 中的多个单词用“.”隔开。
通配符“
”代表匹配一个单词,“#”代表匹配零个或多个单词。
4、rabbitMQ知识点
- 1、rabbitMQ是一个由Erlang语言开发的基于AMQP标准的开源框架
-
2、特点:
1、保证可靠性:持久化、传输确认、发布确认
2、灵活的路由功能:在消息进入队列之前,是通过Exchange来路由消息的
3、支持消息集群
4、具有高可用性
5、提供跟踪机制:如消息异常
5、JMS和AMQP的区别?
JMS AMQP
1、定义 java api 网络线级协议
2、跨语言 否 是
3、跨平台 否 是
4、model 提供两种消息模式p2p pub/sub 提供了五种消息模型 direct交换机/fanout交换机/topic交换机/headers交换机/system交换机,本质上,后4中与jms的pub/sub模型没有太大区别
5、支持消息类型 多种消息类型textMessage/MapMessage/BytesMessage/StreamMessage/ObjectMessage byte[] 当实际应用时,有复杂的消息,可以将消息序列化后发送
6、综合评价 jms定义了javaapi层面的标准,在java体系中,多个client均可以通过jms进行交互,不需要修改代码,但是其对跨平台的支持较差;
AMQP定义wire-level层的协议标准,天然具有跨平台、跨语言特性。
26、Rocketmq的事务消息,问了TCC?
TCC编程模式(两阶段提交的变形)将业务逻辑分为三块:try预留业务资源(类似DML锁定资源),confirm确认执行业务操作(类似commit),cancel取消执行业务操作(类似rollback)以下单为例:try阶段会扣除库存,confirm阶段更新订单状态,如果更新订单失败,会进入cancel阶段,恢复库存。TCC开源框架:tcc-transaction (补偿性分布式事务框架)
后续补充该知识点
27、列举一个常用的消息中间件,如果消息要
保序
如何实现? 政采云问到了
activeMQ的幂等
接收端一定要控制消息的幂等性(某一消息的多次执行的结果与一次执行的结果没有差别,即是幂等)
保序的解决方案:
就是让订阅端先保存消息,之后再处理
后续补充该知识点
28、Mq的持久化机制
消息发送:发送同步消息,发送异步消息,单向发送消息
消费消息:负载均衡模式,广播模式
导入mq客户端依赖
<dependency>
<groupId>org.apache.rocketmq </groupId>
<aritfactId>rocketmq-client</aritfactId>
<version>4.4.0</version>
</dependency>
消息发送者步骤分析
1、创建消息生产者producer,并制定生产者组名
2、指定nameserver地址
3、启动producer
4、创建消息对象,指定主题topic,tag和消息体
5、发送消息,
6、关闭生产者producer
消息消费者步骤分析
1、创建消费者consumer,制定消费者组名;
2、制定namespace地址;
3、启动producer;
4、创建消息对象,指定主题topic,tag和消息体;
5、发送消息;
6、关闭生产者producer。
单向发送消息
消息重试
消息重试配置方式
普通消息
单向发送消息:不用关心发送结果的场景,例如:日志发送
消费消息:
1、负载均衡模式
多个消费者共同消费队列消息,每个消费者处理的消息不同
2、广播模式
每个消费者消费的消息都是相同的
(无序消息)普通,定时,延时,事务消息
默认允许每条消息最多重试16次(时间:4小时46分钟)
messageID不会被改变
想重试,三种方式:
1、返回Action.ReconsumeLater(推荐)
2、返回NUll
3、抛出异常
不想重试:
Action.CommitMessage
顺序消息
保证的是局部顺序,业务相关的消息放在一个队列,然后消费者针对一个队列的消息使用单线程来处理。
(顺序消息)不断进行消息重试,每次间隔1s,会出现消息消费被阻塞的情况 关注
死信队列
超过最大重试次数后还未被正常消费,进入死信队列(3天之内处理)
处理方式:排查造成死信队列的原因后,在消息队列RocketMq控制台重新发送该消息,让消费者重新消费
延时消息
RocketMQ并不支持任意时间的延迟,需要设置几个固定的延时等级(1s到2h)
技巧
:使用system.in.read()可以保持线程处于运行状态,让子线程能正常运行
批量消息
批量发送消息能显著提高传递小消息的性能,限制是这些批量消息应该有相同的topic,相同的waitStoreMsgOK,而且不能是延时消息。
总大小不应超过4MB,超过4MB时,最好把消息进行分割
过滤消息
1、由tag过滤
2、根据sql过滤
事务消息
事务消息的流程:
正常事务消息的发送和提交,
1、发送消息(half消息)
2、服务端响应消息写入结果,
3、根据发送结果执行本地事务(如果写入失败,此时half消息对业务不可见,本地逻辑不执行)
4、根据本地事务状态执行commit或者rollback(commit操作生成消息索引,消息对消费者可见)
事务消息的补偿流程
1、对没有commit,rollback的事务消息(pending状态的消息,从服务端发起一次”回查“)
2、producer收到回查消息,检查回查消息对应的本地事务的状态
3、根据本地事务状态,重新commit或者rollback
补偿阶段用于解决消息commit或rollback发生超时或失败的情况。
事务消息状态
transactionStatus.commitTransaction:提交事务,它允许消费者消费此消息
transactionStatus.rollbackTransaction 回滚事务,它代表该消息将被删除,不允许被消费
transactionStatus.unknown:中间状态,它代表需要检查消息队列来确定状态
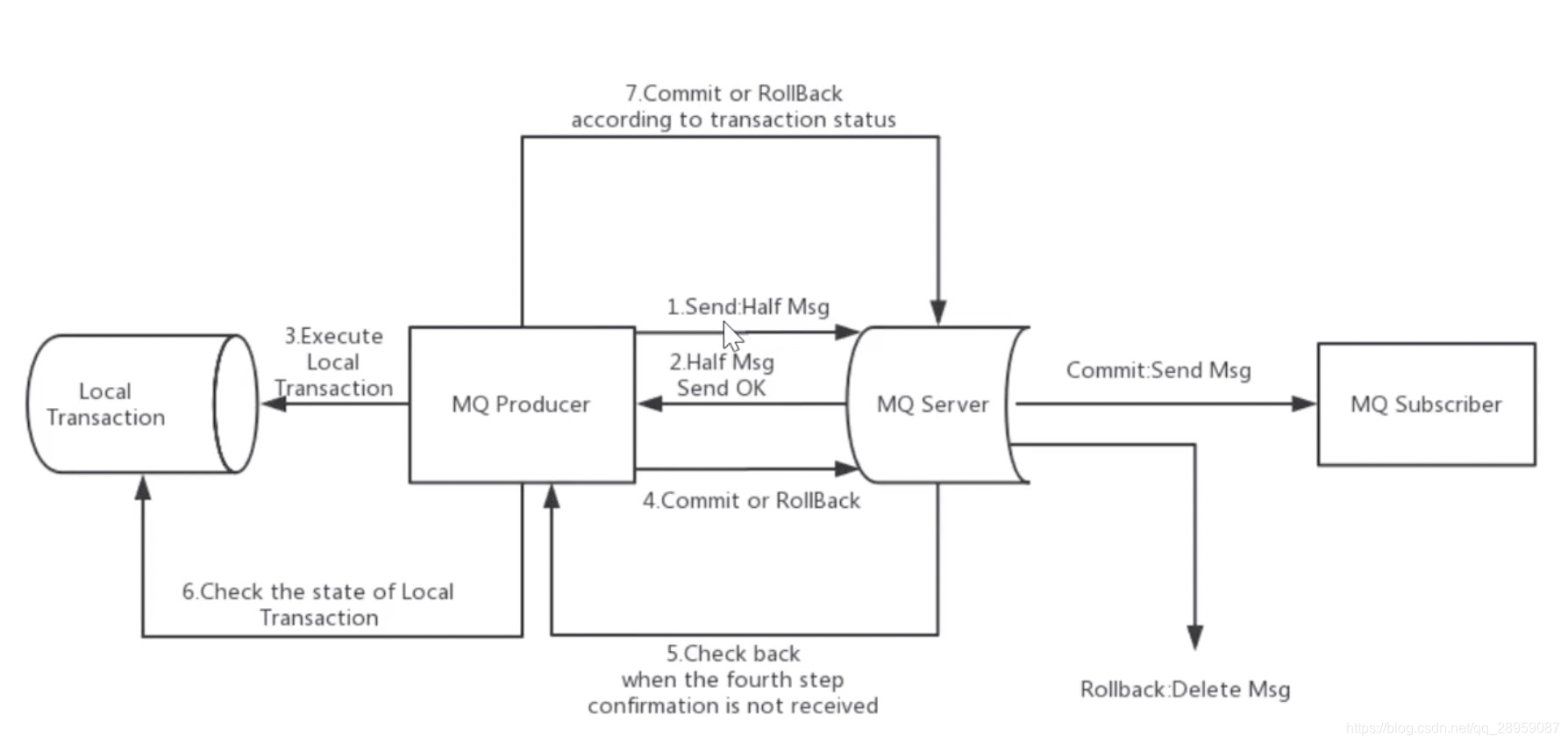
事务消息核心流程如上图所示。
事务消息的使用限制:
- 1、不支持延时消息和批量消息
- 2、为了避免单个消息被检查太多次而导致半队列消息累积,我们默认将单个消息的检查次数限制为15次,但是用户可以通过broker配置文件的transactionCheckMax参数来修改此限制,如果已经检查某条消息超过N次的话,则broker将丢弃此消息。
- 3、事务消息将在broker配置文件中的参数transactionMsgTimeout这样的特定时间长度之后被检查,当发送事务消息后,用户还可以通过设置用户属性check_IMMUNITY_IN_SECONDS来改变这个限制,该参数优先于transactionMSGtimeout 参数
- 4、事务性消息可能不止一次被检查或消费。
- 5、提交给用户的目标主题消息可能会失效。
- 6、事务消息的生产者ID不能与其他类型消息的ID共享。与其他类型消息不同,事务消息允许反向查询,MQ服务器能通过他们的生产者ID查询到消费者。
29、RocketMQ项目实战
在这里插入代码片
在这里插入代码片
项目实战(下单,支付)(使用技术:dubbo,RocketMQ,zookeeper,Springboot,MySql)
springboot整合rocketMQ
1、消息生产者
添加依赖
配置文件
启动类
测试类
rocketMQTemplate.convertAndSend(“springboot-rocketmq”,”hello springboot”,111);
2、消息消费者
消息监听器
@RocketMQMessageListener(topic=“springboot-mq”,consumerGoup= “”)
Public class Consumer implements RocketMQListener<String>{}
3 ZMQ调试技巧
-
1、通过该链接 http://ipaas.cai-inc.com/zmq/#/msg_query 按topic查询消息体,如
{“shopName”:“韦德测试供应商0126”,“userName”:“gys0125”,“userId”:10007398824,“orgId”:147381903370240}
- 2、点击消息发送填充topic,tag,消息体,然后发送消息
-
3、在程序中将provider的version改为自己独有的版本号,以免影响其他人测试,然后启动应用
以test环境为例,启动参数为:-Denv=FAT -Dapollo.cluster=test -Drebel.spring_plugin=true -Dapollo.meta=http://172.16.101.16:8080 - 4、打断点调试,各个分支,各种数据流转都需要考虑清楚,确保万无一失。
30、高级功能和源码分析
后续补充
31、Kafka消息中间件+Flink实时计算框架
1、Kafka如何保证消息队列的高可用?
Kafka 一个最基本的架构认识:由多个 broker 组成,每个 broker 是一个节点;你创建一个 topic,这个 topic 可以划分为多个 partition,每个 partition 可以存在于不同的 broker 上,每个 partition 就放一部分数据。
这就是天然的分布式消息队列,就是说一个 topic 的数据,是分散放在多个机器上的,每个机器就放一部分数据。
实际上 RabbmitMQ 之类的,并不是分布式消息队列,它就是传统的消息队列,只不过提供了一些集群、HA(High Availability, 高可用性) 的机制而已,因为无论怎么玩儿,RabbitMQ 一个 queue 的数据都是放在一个节点里的,镜像集群下,也是每个节点都放这个 queue 的完整数据。
Kafka 0.8 以前,是没有 HA 机制的,就是任何一个 broker 宕机了,那个 broker 上的 partition 就废了,没法写也没法读,没有什么高可用性可言。比如说,我们假设创建了一个 topic,指定其 partition 数量是 3 个,分别在三台机器上。但是,如果第二台机器宕机了,会导致这个 topic 的 1/3 的数据就丢了,因此这个是做不到高可用的。
Kafka 0.8 以后,提供了 HA 机制,就是 replica(复制品) 副本机制。每个 partition 的数据都会同步到其它机器上,形成自己的多个 replica 副本。
所有 replica 会选举一个 leader 出来,那么生产和消费都跟这个 leader 打交道,然后其他 replica 就是 follower
。写的时候,leader 会负责把数据同步到所有 follower 上去,读的时候就直接读 leader 上的数据即可。只能读写 leader?很简单,要是你可以随意读写每个 follower,那么就要 care 数据一致性的问题,系统复杂度太高,很容易出问题。Kafka 会均匀地将一个 partition 的所有 replica 分布在不同的机器上,这样才可以提高容错性。
这么搞,就有所谓的高可用性了
,因为如果某个 broker 宕机了,没事儿,那个 broker上面的 partition 在其他机器上都有副本的。如果这个宕机的 broker 上面有某个 partition 的 leader,那么此时会从 follower 中重新选举一个新的 leader 出来,大家继续读写那个新的 leader 即可。这就有所谓的高可用性了。
写数据的时候
,生产者就写 leader,然后 leader 将数据落地写本地磁盘,接着其他 follower 自己主动从 leader 来 pull 数据。一旦所有 follower 同步好数据了,就会发送 ack 给 leader,leader 收到所有 follower 的 ack 之后,就会返回写成功的消息给生产者。(当然,这只是其中一种模式,还可以适当调整这个行为)
消费的时候
,只会从 leader 去读,但是只有当一个消息已经被所有 follower 都同步成功返回 ack 的时候,这个消息才会被消费者读到。
2、Kafka如何保证消息不重复消费(幂等性)?
所有的消息队列都会有这样重复消费的问题,因为这是不MQ来保证,而是我们自己开发保证的,我们使用Kakfa来讨论是如何实现的。
-
Kakfa有个offset的概念,就是每个消息写进去都会有一个
offset
值,代表消费的序号,然后consumer消费了数据之后,默认每隔一段时间会把自己消费过的消息的offset值提交,表示我已经消费过了,下次要是我重启啥的,就让我从当前提交的offset处来继续消费。
但是凡事总有意外,比如我们之前生产经常遇到的,就是你有时候重启系统,看你怎么重启了,如果碰到点着急的,直接 kill 进程了,再重启。
这会导致 consumer 有些消息处理了,但是没来得及提交 offset,尴尬了。重启之后,少数消息会再次消费一次
。
其实重复消费不可怕,可怕的是你没考虑到重复消费之后,怎么保证幂等性。
举个例子吧。假设你有个系统,消费一条消息就往数据库里插入一条数据,要是你一个消息重复两次,你不就插入了两条,这数据不就错了?但是你要是消费到第二次的时候,自己判断一下是否已经消费过了,若是就直接扔了,这样不就保留了一条数据,从而保证了数据的正确性。一条数据重复出现两次,数据库里就只有一条数据,这就保证了系统的幂等性。
幂等性,通俗点说,就一个数据,或者一个请求,给你重复来多次,你得确保对应的数据是不会改变的,不能出错。
所以第二个问题来了,怎么保证消息队列消费的幂等性?
其实还是得结合业务来思考,这里给几个思路:
- 比如你拿个数据要写库,你先根据主键查一下,如果这数据都有了,你就别插入了,update 一下好吧。
- 比如你是写 Redis,那没问题了,反正每次都是 set,天然幂等性。
- 比如你不是上面两个场景,那做的稍微复杂一点,你需要让生产者发送每条数据的时候,里面加一个全局唯一的 id,类似订单 id 之类的东西,然后你这里消费到了之后,先根据这个 id 去比如 Redis 里查一下,之前消费过吗?如果没有消费过,你就处理,然后这个 id 写 Redis。如果消费过了,那你就别处理了,保证别重复处理相同的消息即可。
-
比如基于数据库的唯一键来保证重复数据不会重复插入多条。因为有唯一键约束了,重复数据插入只会报错,不会导致数据库中出现脏数据。
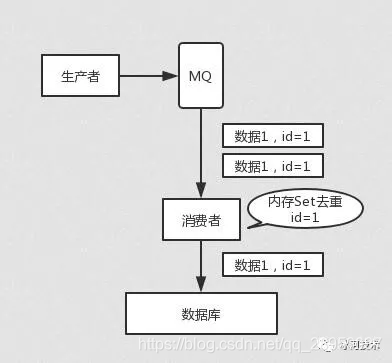
当然,如何保证 MQ 的消费是幂等性的,需要结合具体的业务来看。
3、如何保证消息的可靠传输(不丢失)?
MQ的基本原则就是数据不能多一条,也不能少一条,不能多其实就是我们前面重复消费的问题。不能少,就是数据不能丢,像计费,扣费的一些信息,是肯定不能丢失的。
数据的丢失问题,可能出现在生产者、MQ、消费者中。
消费者丢数据
-
唯一可能导致消费者弄丢数据的情况,就是说,你消费到了这个消息,然后消费者那边自动提交了 offset,让 Kafka 以为你已经消费好了这个消息,但其实你才刚准备处理这个消息,你还没处理,你自己就挂了,此时这条消息就丢咯。
-
这不是跟 RabbitMQ 差不多吗,大家都知道 Kafka 会自动提交 offset,那么只要关闭自动提交 offset,在处理完之后自己手动提交 offset,就可以保证数据不会丢。但是此时确实还是可能会有重复消费,比如你刚处理完,还没提交 offset,结果自己挂了,此时肯定会重复消费一次,自己保证幂等性就好了。
-
生产环境碰到的一个问题,就是说我们的 Kafka 消费者消费到了数据之后是写到一个内存的 queue 里先缓冲一下,结果有的时候,你刚把消息写入内存 queue,然后消费者会自动提交 offset。然后此时我们重启了系统,就会导致内存 queue 里还没来得及处理的数据就丢失了。
Kafka丢数据
-
这块比较常见的一个场景,就是 Kafka 某个 broker 宕机,然后重新选举 partition 的 leader。大家想想,要是此时其他的 follower 刚好还有些数据没有同步,结果此时 leader 挂了,然后选举某个 follower 成 leader 之后,不就少了一些数据?这就丢了一些数据啊。
生产环境也遇到过,我们也是,之前 Kafka 的 leader 机器宕机了,将 follower 切换为 leader 之后,就会发现说这个数据就丢了。
所以此时一般是要求起码设置如下 4 个参数:
我们生产环境就是按照上述要求配置的,这样配置之后,至少在 Kafka broker 端就可以保证在 leader 所在 broker 发生故障,进行 leader 切换时,数据不会丢失。
给 topic 设置
replication.factor
参数:这个值必须大于 1,要求每个 partition 必须有至少 2 个副本。
在 Kafka 服务端设置
min.insync.replicas
参数:这个值必须大于 1,这个是要求一个 leader 至少感知到有至少一个 follower 还跟自己保持联系,没掉队,这样才能确保 leader 挂了还有一个 follower 吧。
在 producer 端设置
acks=all
:这个是要求每条数据,必须是写入所有 replica 之后,才能认为是写成功了。
在 producer 端设置
retries=MAX
(很大很大很大的一个值,无限次重试的意思):这个是要求一旦写入失败,就无限重试,卡在这里了。
生产者丢数据
如果按照上述的思路设置了 acks=all,一定不会丢,要求是,你的 leader 接收到消息,所有的 follower 都同步到了消息之后,才认为本次写成功了。如果没满足这个条件,生产者会自动不断的重试,重试无限次。
4、如何保证消息的顺序性?
我举个例子,我们以前做过一个 mysql binlog 同步的系统,压力还是非常大的,日同步数据要达到上亿,就是说数据从一个 mysql 库原封不动地同步到另一个 mysql 库里面去(mysql -> mysql)。常见的一点在于说比如大数据 team,就需要同步一个 mysql 库过来,对公司的业务系统的数据做各种复杂的操作。
你在 mysql 里增删改一条数据,对应出来了增删改 3 条 binlog 日志,接着这三条 binlog 发送到 MQ 里面,再消费出来依次执行,起码得保证人家是按照顺序来的吧?不然本来是:增加、修改、删除;你楞是换了顺序给执行成删除、修改、增加,不全错了么。
本来这个数据同步过来,应该最后这个数据被删除了;结果你搞错了这个顺序,最后这个数据保留下来了,数据同步就出错了。
Kafka:比如说我们建了一个 topic,有三个 partition。生产者在写的时候,其实可以指定一个 key,比如说我们指定了某个订单 id 作为 key,那么这个订单相关的数据,一定会被分发到同一个 partition 中去,而且这个 partition 中的数据一定是有顺序的。消费者从 partition 中取出来数据的时候,也一定是有顺序的。到这里,顺序还是 ok 的,没有错乱。接着,我们在消费者里可能会搞多个线程来并发处理消息。因为如果消费者是单线程消费处理,而处理比较耗时的话,比如处理一条消息耗时几十 ms,那么 1 秒钟只能处理几十条消息,这吞吐量太低了。而多个线程并发跑的话,顺序可能就乱掉了。
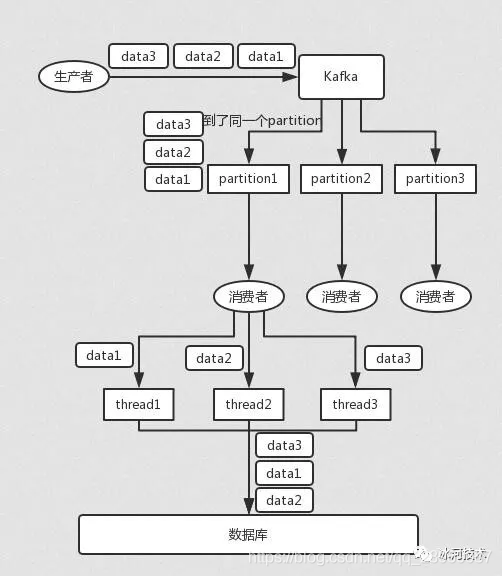
Kafka解决方案
一个 topic,一个 partition,一个 consumer,内部单线程消费,单线程吞吐量太低,一般不会用这个。
写 N 个内存 queue,具有相同 key 的数据都到同一个内存 queue;然后对于 N 个线程,每个线程分别消费一个内存 queue 即可,这样就能保证顺序性。
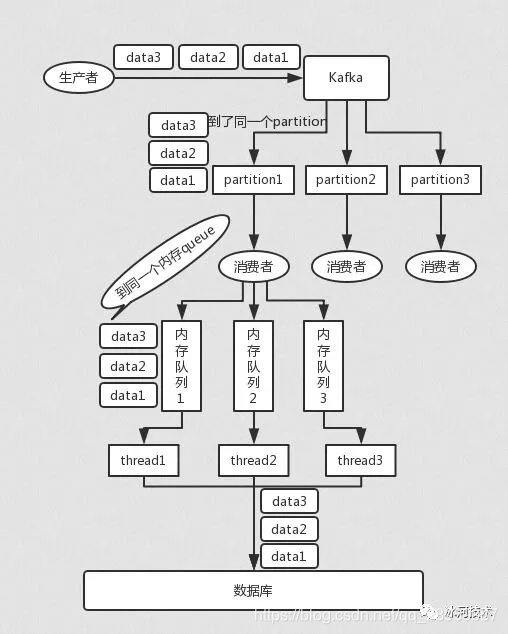
5、如何处理消息推积?
大量消息在 mq 里积压了几个小时了还没解决
一个消费者一秒是 1000 条,一秒 3 个消费者是 3000 条,一分钟就是 18 万条。所以如果你积压了几百万到上千万的数据,即使消费者恢复了,也需要大概 1 小时的时间才能恢复过来。
一般这个时候,只能临时紧急扩容了,具体操作步骤和思路如下:
- 先修复 consumer 的问题,确保其恢复消费速度,然后将现有 consumer 都停掉。
- 新建一个 topic,partition 是原来的 10 倍,临时建立好原先 10 倍的 queue 数量。
- 然后写一个临时的分发数据的 consumer 程序,这个程序部署上去消费积压的数据,消费之后不做耗时的处理,直接均匀轮询写入临时建立好的 10 倍数量的 queue。
- 接着临时征用 10 倍的机器来部署 consumer,每一批 consumer 消费一个临时 queue 的数据。这种做法相当于是临时将 queue 资源和 consumer 资源扩大 10 倍,以正常的 10 倍速度来消费数据。
- 等快速消费完积压数据之后,得恢复原先部署的架构,重新用原先的 consumer 机器来消费消息。
6、mq 中的消息过期失效了
假设你用的是 RabbitMQ,RabbtiMQ 是可以设置过期时间的,也就是 TTL。如果消息在 queue 中积压超过一定的时间就会被 RabbitMQ 给清理掉,这个数据就没了。那这就是第二个坑了。这就不是说数据会大量积压在 mq 里,而是大量的数据会直接搞丢。
这个情况下,就不是说要增加 consumer 消费积压的消息,因为实际上没啥积压,而是丢了大量的消息。我们可以采取一个方案,就是批量重导,这个我们之前线上也有类似的场景干过。就是大量积压的时候,我们当时就直接丢弃数据了,然后等过了高峰期以后,比如大家一起喝咖啡熬夜到晚上12点以后,用户都睡觉了。这个时候我们就开始写程序,将丢失的那批数据,写个临时程序,一点一点的查出来,然后重新灌入 mq 里面去,把白天丢的数据给他补回来。也只能是这样了。
假设 1 万个订单积压在 mq 里面,没有处理,其中 1000 个订单都丢了,你只能手动写程序把那 1000 个订单给查出来,手动发到 mq 里去再补一次。
7、mq 都快写满了
如果消息积压在 mq 里,你很长时间都没有处理掉,此时导致 mq 都快写满了,咋办?这个还有别的办法吗?没有,谁让你第一个方案执行的太慢了,你临时写程序,接入数据来消费,消费一个丢弃一个,都不要了,快速消费掉所有的消息。然后走第二个方案,到了晚上再补数据吧。
8、kafka的持久化机制 kafka down掉会不会丢数据
写数据:过内存S大小(S可设置)的数据后,直接刷进磁盘,追加写入文件;
读数据:根据offset读取位置之后S大小的数据,进内存;
删数据:直接删磁盘文件(segment file),先删老文件(可设置)。
9、有哪几种持久化机制?区别
32、RocketMQ常见面试题
1、在RocketMQ中,消息丢失问题
- 当你系统需要保证百分百消息不丢失,你可以使用生产者每发送一个消息,Broker 同步返回一个消息发送成功的反馈消息
- 即每发送一个消息,同步落盘后才返回生产者消息发送成功,这样只要生产者得到了消息发送生成的返回,事后除了硬盘损坏,都可以保证不会消息丢失
2 同步落盘怎么才能快?
- 使用 FileChannel + DirectBuffer 池,使用堆外内存,加快内存拷贝
- 使用数据和索引分离,当消息需要写入时,使用 commitlog 文件顺序写,当需要定位某个消息时,查询index 文件来定位,从而减少文件IO随机读写的性能损耗
3 消息堆积的问题
- 后台定时任务每隔72小时,删除旧的没有使用过的消息信息
- 根据不同的业务实现不同的丢弃任务,具体参考线程池的 AbortPolicy,例如FIFO/LRU等(RocketMQ没有此策略)
- 消息定时转移,或者对某些重要的 TAG 型(支付型)消息真正落库
4 定时消息的实现
- 实际 RocketMQ 没有实现任意精度的定时消息,它只支持某些特定的时间精度的定时消息
- 实现定时消息的原理是:创建特定时间精度的 MessageQueue,例如生产者需要定时1s之后被消费者消费,你只需要将此消息发送到特定的 Topic,例如:MessageQueue-1 表示这个 MessageQueue 里面的消息都会延迟一秒被消费,然后 Broker 会在 1s 后发送到消费者消费此消息,使用 newSingleThreadScheduledExecutor 实现
5 顺序消息的实现
- 与定时消息同原理,生产者生产消息时指定特定的 MessageQueue ,消费者消费消息时,消费特定的 MessageQueue,其实单机版的消息中心在一个 MessageQueue 就天然支持了顺序消息
-
注意:同一个 MessageQueue 保证里面的消息是顺序消费的前提是:消费者是串行的消费该 MessageQueue,因为就算 MessageQueue 是顺序的,但是当并行消费时,还是会有顺序问题,但是串行消费也同时引入了两个问题:
- 引入锁来实现串行
- 前一个消费阻塞时后面都会被阻塞
6 分布式消息的实现(事务消息)
- 需要前置知识:2PC
- RocketMQ4.3 起支持,原理为2PC,即两阶段提交,prepared->commit/rollback
-
生产者发送事务消息,假设该事务消息 Topic 为 Topic1-Trans,Broker 得到后首先更改该消息的 Topic 为 Topic1-Prepared,该 Topic1-Prepared 对消费者不可见。然后定时回调生产者的本地事务A执行状态,根据本地事务A执行状态,来是否将该消息修改为 Topic1-Commit 或 Topic1-Rollback,消费者就可以正常找到该事务消息或者不执行等
注意,就算是事务消息最后回滚了也不会物理删除,只会逻辑删除该消息
8 消息重复发送的避免
- RocketMQ 会出现消息重复发送的问题,因为在网络延迟的情况下,这种问题不可避免的发生,如果非要实现消息不可重复发送,那基本太难,因为网络环境无法预知,还会使程序复杂度加大,因此默认允许消息重复发送
- RocketMQ 让使用者在消费者端去解决该问题,即需要消费者端在消费消息时支持幂等性的去消费消息
- 最简单的解决方案是每条消费记录有个消费状态字段,根据这个消费状态字段来是否消费或者使用一个集中式的表,来存储所有消息的消费状态,从而避免重复消费
- 具体实现可以查询关于消息幂等消费的解决方案
9 RocketMQ 不使用 ZooKeeper 作为注册中心的原因,以及自制的 NameServer 优缺点?
- ZooKeeper 作为支持顺序一致性的中间件,在某些情况下,它为了满足一致性,会丢失一定时间内的可用性,RocketMQ 需要注册中心只是为了发现组件地址,在某些情况下,RocketMQ 的注册中心可以出现数据不一致性,这同时也是 NameServer 的缺点,因为 NameServer 集群间互不通信,它们之间的注册信息可能会不一致
- 另外,当有新的服务器加入时,NameServer 并不会立马通知到 Produer,而是由 Produer 定时去请求 NameServer 获取最新的 Broker/Consumer 信息(这种情况是通过 Producer 发送消息时,负载均衡解决)
10 加分项咯
-
包括组件通信间使用 Netty 的自定义协议
-
消息重试负载均衡策略(具体参考 Dubbo 负载均衡策略)
-
消息过滤器(Producer发送消息到 Broker,Broker 存储消息信息,Consumer消费时请求 Broker 端从磁盘文件查询消息文件时, 在 Broker 端就使用过滤服务器进行过滤)
- RocketMQ分布式消息队列的消息过滤方式有别于其它MQ中间件,是在Consumer端订阅消息时再做消息过滤的。RocketMQ这么做是在于其Producer端写入消息和Consumer端订阅消息采用分离存储的机制来实现的,Consumer端订阅消息是需要通过ConsumeQueue这个消息消费的逻辑队列拿到一个索引,然后再从CommitLog里面读取真正的消息实体内容,所以说到底也是还绕不开其存储结构。
- 其ConsumeQueue的存储结构,可以看到其中有8个字节存储的Message Tag的哈希值,基于Tag的消息过滤正式基于这个字段值的。
- Tag过滤方式:Consumer端在订阅消息时除了指定Topic还可以指定TAG,如果一个消息有多个TAG,可以用||分隔。
- SQL92的过滤方式:这种方式的大致做法和上面的Tag过滤方式一样,只是在Store层的具体过滤过程不太一样
-
Broker 同步双写和异步双写中 Master 和 Slave 的交互
-
Broker 在 4.5.0 版本更新中引入了基于 Raft 协议的多副本选举,之前这是商业版才有的特性 ISSUE-1046
11 关于消息队列其他一些常见的问题展望(
后续补充
)
- 引入消息队列之后如何保证高可用性?
- 如何保证消息不被重复消费呢?
- 如何保证消息的可靠性传输(如何处理消息丢失的问题)?
- 我该怎么保证从消息队列里拿到的数据按顺序执行?
- 如何解决消息队列的延时以及过期失效问题?消息队列满了以后该怎么处理?有几百万消息持续积压几小时,说说怎么解决?
- 如果让你来开发一个消息队列中间件,你会怎么设计架构?
33、MQ踩坑review
1、如果MQ消费失败,尽可能不要设置为稍后重试,因为重试一般没法解决问题 202103补
首先看看消息消费后发送的枚举
public enum ConsumeConcurrentlyStatus {
/*** Success consumption*/
CONSUME_SUCCESS,
/*** Failure consumption,later try to consume*/
RECONSUME_LATER;
}
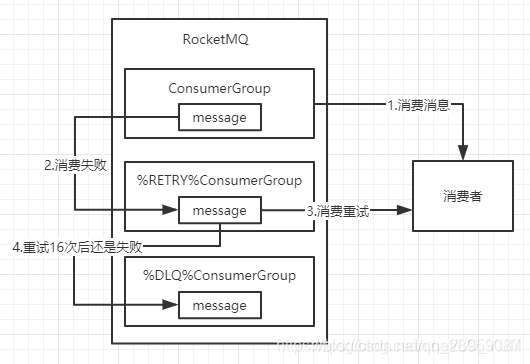
- 如果无法返回CONSUME_SUCCESS状态,那么就返回RECONSUME_LATER,过一会再尝试消费即可。那么第二个问题来了,既然这条消息消费失败了,总不能一直卡着后面的消息也等着吧,那么消费失败的消息肯定需要放到另一个Topic中,让它一个人等着被再次消费。
- 所以这时会有一个重试队列,用于暂时保存因为各种异常而导致Consumer端无法消费的消息,重试队列的名称是在原队列的名称前加上%RETRY%(这个Topic的重试队列是针对消费组,而不是针对每个Topic设置的)
-
RocketMQ对于重试消息的处理是先保存至Topic名称为“SCHEDULE_TOPIC_XXXX”的延迟队列中,后台定时任务按照对应的时间进行Delay后重新保存至“%RETRY%+consumerGroup”的重试队列中
在RocketMQ的console控制台上可以看到重试队列的信息

现在我们已经知道消费失败的消息会进入重试队列,那么多久重试一次呢?能进行多少次的重试呢?
- 考虑到异常恢复起来需要一些时间,会为重试队列设置多个重试级别,每个重试级别都有与之对应的重新投递延时间,重试次数越多投递延时就越大。有一个参数messageDelayLevel,这个参数是在服务器端的Broker上配置的,默认是
messageDelayLevel=1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h
默认是最多可以重试16次
-
如果重试了16次之后,这条消息还是没有被成功消费,那么就认为这条消息是抢救不过来了,此时,
消息队列不会立刻将消息丢弃,于是它被放入了死信队列中
,上面重试队列的图中你也可以看到死信队列,死信队列的名称是在原队列名称前加%DLQ%。
如果你还是不死心的话,觉得这条消息还能抢救一下,可以开启一个后台线程不断扫描死信队列然后继续重试,也可以通过使用console控制台对死信队列中的消息进行重发来使得消费者实例再次进行消费
整个消费失败流程如图所示
推荐的使用方法
- 如果消息消费失败,记录失败日志,并返回消费成功。根据日志排查消费失败的原因,修改好后,在控制台中重新投递消息即可。
34、MQ 开发规范
待补充
《寒山子诗集》:寒山与拾得两位大师是佛教史上著名的诗僧。唐代天台山国清寺隐僧寒山与拾得,行迹怪诞,相传是文殊菩萨与普贤菩萨的化身。寒山问曰:“世间有人谤我、欺我、辱我、笑我、轻我、贱我、恶我、骗我,该如何处之乎?”拾得答曰:“只需忍他、让他、由他、避他、耐他、敬他、不要理他、再待几年,你且看他。”这个绝妙的问答,蕴含了面对人我是非的处世之道,因此虽经一千多年,至今仍然脍炙人口。