RDD 的持久化
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
/**
* RDD 的持久化
*/
public class Persion_9 {
public static void main(String[] args) {
SparkConf conf = new SparkConf()
.setAppName("Persist_9")
.setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
// cache()或者persist()的使用,是有规则的
// 必须在transformation或者textFile等创建了一个RDD之后,直接连续调用cache()或persist()才可以
// 如果你先创建一个RDD,然后单独另起一行执行cache()或persist()方法,是没有用的
// 而且,会报错,大量的文件会丢失
JavaRDD<String> lines = sc.textFile("D:\\eclipse\\wc\\scalaworid\\spark.txt")
.cache();
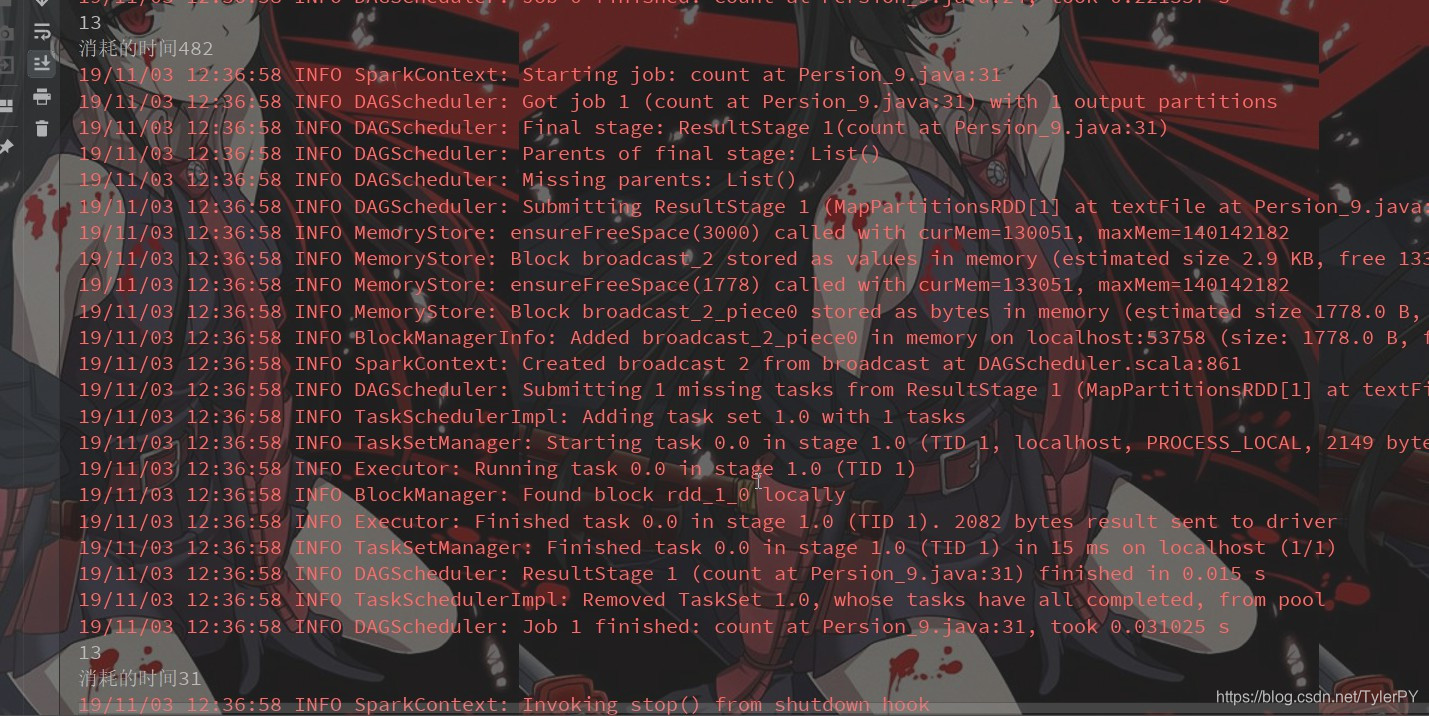
long beginTime = System.currentTimeMillis();
long count = lines.count();
System.out.println(count);
long endTime = System.currentTimeMillis();
System.out.println("消耗的时间" + (endTime - beginTime));
beginTime = System.currentTimeMillis();
count = lines.count();
System.out.println(count);
endTime = System.currentTimeMillis();
System.out.println("消耗的时间" + (endTime - beginTime));
}
}
1、对文本文件内的每个单词都统计出其出现的次数。
2、按照每个单词出现次数的数量,降序排序。
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.*;
import org.apache.spark.sql.sources.In;
import scala.Tuple2;
import java.util.Arrays;
/**
* 1、对文本文件内的每个单词都统计出其出现的次数。
* 2、按照每个单词出现次数的数量,降序排序.
*/
public class SortWorldCount {
public static void main(String[] args) {
SparkConf conf = new SparkConf()
.setAppName("SortWorldCount")
.setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> stringJavaRDD = sc.textFile("D:\\eclipse\\wc\\scalaworid\\spark.txt");
JavaRDD<String> objectJavaRDD = stringJavaRDD.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterable<String> call(String s) throws Exception {
return Arrays.asList(s.split(" "));
}
});
JavaPairRDD<String, Integer> worldAndOne = objectJavaRDD.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String s) throws Exception {
return new Tuple2<String, Integer>(s, 1);
}
});
JavaPairRDD<String, Integer> stringIntegerJavaPairRDD = worldAndOne.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer integer, Integer integer2) throws Exception {
return integer + integer2;
}
});
//到这里为止就得到了每个单词出现的次数,但是我们的新需求是,按照每个单词出现的次数降序排列
//wAndC DRR内的元素是什么?应该是这样的格式:(hello,2)(word,3)
//我们需要将RDD中转换为(3,word)的格式,才能根据单词出现的次数进行排序
// 进行key-value的反转
JavaPairRDD<Integer, String> pairRDD = stringIntegerJavaPairRDD.mapToPair(new PairFunction<Tuple2<String, Integer>, Integer, String>() {
@Override
public Tuple2<Integer, String> call(Tuple2<String, Integer> tuple2) throws Exception {
return new Tuple2<Integer, String>(tuple2._2,tuple2._1);
}
});
//按照key排序
JavaPairRDD<Integer, String> sortByKey = pairRDD.sortByKey(false);
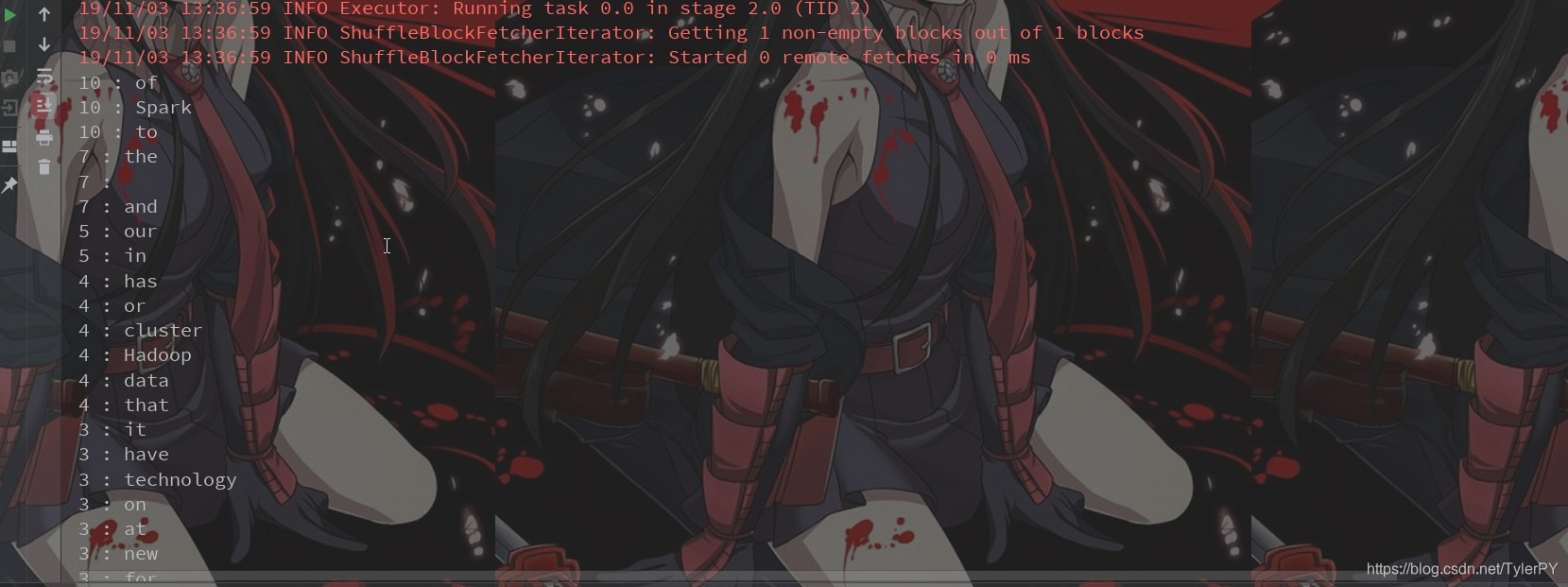
sortByKey.foreach(new VoidFunction<Tuple2<Integer, String>>() {
@Override
public void call(Tuple2<Integer, String> tuple2) throws Exception {
System.out.println(tuple2._1 + " : "+ tuple2._2);
}
});
}
}
1、按照文件中的第一列排序。
2、如果第一列相同,则按照第二列排序。
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import scala.Int;
import scala.Tuple2;
/**
* 二次排序
* 1.实现自定义的key,要实现Ordered接口和Serializable接口,在key自己对多个列的排序算法
* 2.将包含文本的RDD,映射称key为自定义key,value为文本的JavaPairRDD
* 3.使用sortedByKey算子,按照自定义的key进行排列
* 4.再次映射,剔除自定义的key,只保留value元文本行
*
*/
public class SecondarySort {
public static void main(String[] args) {
SparkConf conf = new SparkConf()
.setMaster("local")
.setAppName("SecondarySort_12");
JavaSparkContext sc = new JavaSparkContext(conf);
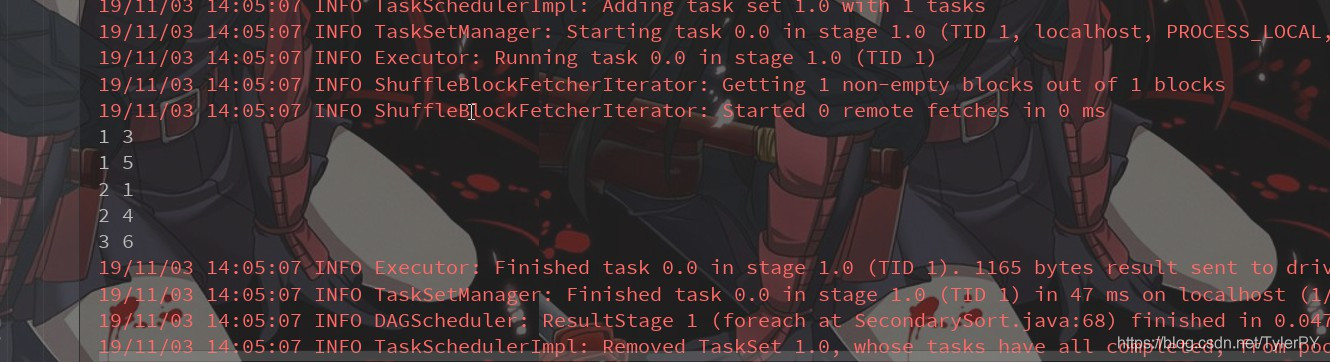
JavaRDD<String> lines = sc.textFile("D:\\eclipse\\wc\\input\\sort.txt");
/**
* 1 5
* 2 4
* 3 6
* 1 3
* 2 1
*/
JavaPairRDD<SecondarySortKey, String> pair = lines.mapToPair(new PairFunction<String, SecondarySortKey, String>() {
@Override
public Tuple2<SecondarySortKey, String> call(String s) throws Exception {
String[] split = s.split(" ");
SecondarySortKey key = new SecondarySortKey(Integer.parseInt(split[0]), Integer.parseInt(split[1]));
//(1,5:1 5)
//(2,4:2 4)
//(3,6:3 6)
//(1,3:1 3)
//(2,1:2 1)
return new Tuple2<SecondarySortKey, String>(key, s);
}
});
//(1,3:1 3)
//(1,5:1 5)
//(2,1:2 1)
//(2,4:2 4)
//(3,6:3 6)
JavaPairRDD<SecondarySortKey, String> sorted = pair.sortByKey();
final JavaRDD<String> sorteded = sorted.map(new Function<Tuple2<SecondarySortKey, String>, String>() {
@Override
public String call(Tuple2<SecondarySortKey, String> tuple2) throws Exception {
return tuple2._2;
}
});
sorteded.foreach(new VoidFunction<String>() {
@Override
public void call(String s) throws Exception {
System.out.println(s);
}
});
sc.close();
}
}
SecondarySortKey类
import scala.math.Ordered;
import java.io.Serializable;
public class SecondarySortKey implements Ordered<SecondarySortKey>, Serializable {
//首先在自定义的key里面,定义需要进行排序的列
private int first;
private int second;
// 为要进行排序的多个列提供getter和setter方法,以及hashcode和equals和构造方法方法
public SecondarySortKey(int first, int second) {
this.first = first;
this.second = second;
}
public int getFirst() {
return first;
}
public int getSecond() {
return second;
}
public void setFirst(int first) {
this.first = first;
}
public void setSecond(int second) {
this.second = second;
}
@Override
public int compare(SecondarySortKey that) {
if(this.getFirst() - that.getFirst() !=0){
return this.getFirst() - that.getFirst();
}else
return this.getSecond() - that.getSecond();
}
//小于
@Override
public boolean $less(SecondarySortKey that) {
if(this.getFirst() < that.getFirst()){
return true;
}else if (this.getFirst() == that.getFirst() && that.getSecond() < that.getSecond()){
return true;
}
return false;
}
//大于
@Override
public boolean $greater(SecondarySortKey that) {
if(this.getFirst() > that.getFirst()){
return true;
}else if (this.getFirst() == that.getFirst() && this.getSecond() > that.getSecond()){
return true;
}
return false;
}
//小于等于
@Override
public boolean $less$eq(SecondarySortKey that) {
if(this.getFirst() < that.getFirst()){
return true;
}else if (this.getFirst() == that.getFirst() && that.getSecond() == that.getSecond()){
return true;
}
return false;
}
//大于等于
@Override
public boolean $greater$eq(SecondarySortKey that) {
if(this.getFirst() > (that.getFirst())){
return true;
}else if (this.first == that.getFirst() && this.second == this.getSecond()){
return true;
}
return false;
}
@Override
public int compareTo(SecondarySortKey that) {
if (this.getFirst() - that.getFirst() !=0){
return this.getFirst() - that.getFirst();
}else
return this.getSecond() - that.getSecond();
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
SecondarySortKey that = (SecondarySortKey) o;
if (first != that.first) return false;
return second == that.second;
}
@Override
public int hashCode() {
int result = first;
result = 31 * result + second;
return result;
}
}
版权声明:本文为TylerPY原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。