对于某些字符串
S
,我们将执行一些替换操作,用新的字母组替换原有的字母组(不一定大小相同)。
每个替换操作具有 3 个参数:起始索引
i
,源字
x
和目标字
y
。规则是如果
x
从原始字符串
S
中的位置
i
开始,那么我们将用
y
替换出现的
x
。如果没有,我们什么都不做。
举个例子,如果我们有
S = “abcd”
并且我们有一些替换操作
i = 2,x = “cd”,y = “ffff”
,那么因为
“cd”
从原始字符串
S
中的位置
2
开始,我们将用
“ffff”
替换它。
再来看
S = “abcd”
上的另一个例子,如果我们有替换操作
i = 0,x = “ab”,y = “eee”
,以及另一个替换操作
i = 2,x = “ec”,y = “ffff”
,那么第二个操作将不执行任何操作,因为原始字符串中
S[2] = 'c'
,与
x[0] = 'e'
不匹配。
所有这些操作同时发生。保证在替换时不会有任何重叠:
S = "abc", indexes = [0, 1], sources = ["ab","bc"]
不是有效的测试用例。
示例 1:
输入:S = "abcd", indexes = [0,2], sources = ["a","cd"], targets = ["eee","ffff"] 输出:"eeebffff" 解释: "a" 从 S 中的索引 0 开始,所以它被替换为 "eee"。 "cd" 从 S 中的索引 2 开始,所以它被替换为 "ffff"。
示例 2:
输入:S = "abcd", indexes = [0,2], sources = ["ab","ec"], targets = ["eee","ffff"] 输出:"eeecd" 解释: "ab" 从 S 中的索引 0 开始,所以它被替换为 "eee"。 "ec" 没有从原始的 S 中的索引 2 开始,所以它没有被替换。
提示:
-
0 <= indexes.length = sources.length = targets.length <= 100
-
0 < indexes[i] < S.length <= 1000
- 给定输入中的所有字符都是小写字母。
解题思路见
https://www.cnblogs.com/grandyang/p/10352323.html
,这个是我借鉴上面这个博主的解法实现的自己的答案。
下面是自己的答案:Python3
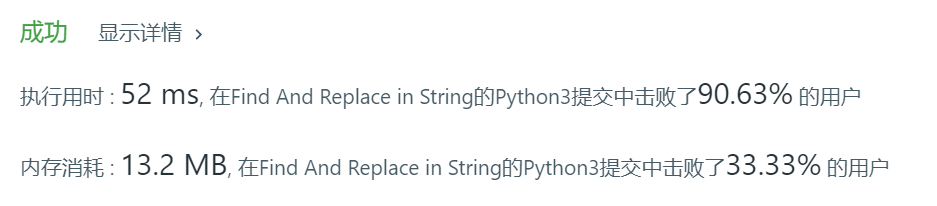
class Solution: def findReplaceString(self, S, indexes,sources, targets): result = '' if len(indexes) == 0: return S data = {} for index in range(0,len(indexes)): data[index] = indexes[index] data = sorted(data.items(),key=lambda item:item[1],reverse= True) print(data) for item in data: if S[item[1]:item[1]+ len(sources[item[0]])] == sources[item[0]]: S = S[:item[1]] + targets[item[0]] + S[item[1]+len(sources[item[0]]):] return S
运行的结果是:
主要学习和借鉴的地方:
1.将indexes排序,利用二元组的结构保存indexes中的各项和该项对应的下标(和sources和targets相对应)
2.利用倒序的修改S的值,每次都跟新S。
转载于:https://www.cnblogs.com/andingding-blog/p/10910574.html