基础IO操作–文件夹以及文件的复制(一)
文件内容的读写
我们存储文件有很多种方式:
- 变量:只能存储一份
- 数组 存储好多了 类型统一
-
集合 存储好多个 存储后个数还能改变 范型—数据类型统一
如上三个都是java中的类型(对象–>内存)
都存储在内存中 程序执行完毕 虚拟机停止的时候 内存空间会被回收 数据都是临时性存储的
-
文件 存储好多信息
文件是存储在硬盘上的—>永久性保存
数据虽然是安全了,文件毕竟不在内存中,通过IO操作文件
在此我们主要是归纳了字节型文件流的基本操作与方法
对于不同的类型的字节流,其基本操作都大致相同,因此我们在此只归纳了有关字节型的文件流。
字节型输入流—>FileInputStream
-
有三种构造器,我们主要是其中两种构造器:
调用一个带file类型的构造方法
调用一个带string类型的构造方法 -
输入流的常用方法:

从官方所给的文档我们可以看出,输入流的方法并不多,其中最重要的方法也说了三遍—->read
read()方法返回为int型,它表示的是你读取的字节的大小,从重载的方法我们可以看出,read()方法允许接受一个byte数组,这到底是为了什么呢?
我们知道,字节型输入流默认的是我们从文件中每次读取一个字节的内容。
举个例子来说,加入你正在吃午饭,你的文件就是整个锅里的米饭,而你使用字节型输入流时,默认的read()方法就是指你每次只能一粒一粒的从锅里盛取米饭。如果该文件特别大,那就是说你所花费的时间特别多,因此当我给你一个byte[]数组时,就相当于给了你一个铲子,这个铲子的大小你自己可以选择(通常在1kb~8kb之间),那么很容易理解,你每次产出的米粒个数就和你的铲子的大小有关了。
//首先创建文件对象
File file = new File("path");//若对文件不熟悉的可以先稍微了解下
//我们传入字节型输入流的参数有两种:--File file --String filename
FileInputStream fis = new FileInputStream(file);
int v = fis.read();
System.out.println(v);
上述代码是我们的一般步骤,但是在实际操作时我们需要注意代码的健壮性:
- 文件是否存在?
- 文件是否关闭?
因此我们在实际操作时,我们需要注意相关的一些小细节。
下面我们看一下实际运行时的问题:
public void InwithoutByte(){
File file = new File("C:\\Users\\hust\\Desktop\\java\\IO\\src\\Test.txt");
FileInputStream fis = null;
try {
fis = new FileInputStream(file);
int value = fis.read();
while (value!= -1){
System.out.print(value + " ");
System.out.println((char) value);
value = fis.read();
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
其中Test.txt文件如下所示:

那么我们的输出是什么呢?
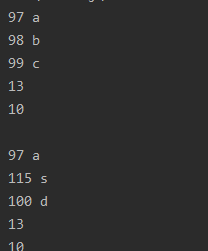
我们可以发现这并不是我们想要的结果 多出来的13 10到底是什么呢?
可以看到我们的文件其实每一行都多出来了 一个回车与换行(\r, \n)
这导致了我们每次输出的value值都多出来了两个字节。
那么我们再看一下用数组处理输入流的代码:
public void InwithByte(){
File file = new File("C:\\Users\\hust\\Desktop\\java\\IO\\src\\Test.txt");
FileInputStream fis = null;
try {
fis = new FileInputStream(file);
byte[] bytes = new byte[1024];//我们选取1kb作为我们的铲子
int value = fis.read(bytes);//此时返回的是有效字节个数
while (value!= -1){
System.out.print(value + " ");
System.out.println((char) value);
System.out.println(new String(bytes));
value = fis.read(bytes);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
需要注意的是,这次我们返回的value不再是一个字节,而是字节的个数,你可以使用循环输出每一个字节,也可以直接入上述代码一样将其输出。
输出结果为:
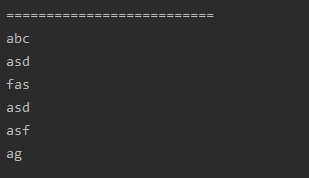
我们的主函数为:
public static void main(String[] args){
new 类名.InwithoutByte()
sout("=====================")
new 类名.InwithByte()
}
我们可以看到云用数组相对于更加符合实际,但是如果我们把数组的大小改为4又会发生什么呢?
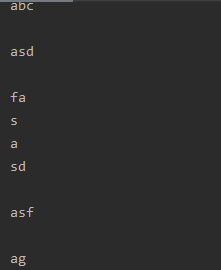
造成这样的原因是什么呢?
谢谢!如果有不好的地方请提出