文章目录
1.如何判断是否为聚簇索引?
取决于数据和索引是否放在一起,数据和索引放在一起则为聚簇索引,否则为非聚簇索引
2.为什么聚簇索引只有一个?
我们先假设有这么一张表table和数据

2.1首先我们先看MYISAM:只能是非聚簇索引(因为数据和索引是分开存放的)


myisam上面放的是索引(1),下面存放的是实际数据行地址(0x0022)
2.2INNODB:
主键索引就是聚簇索引
,只能有一个聚簇索引,但是可以有很多非聚簇索引

当innodb插入数据的时候,必须要包含一个索引的key值,可以是主键,如果没有主键,那么就是唯一键,如果没有唯一键,那么就是自生成的6字节rowid
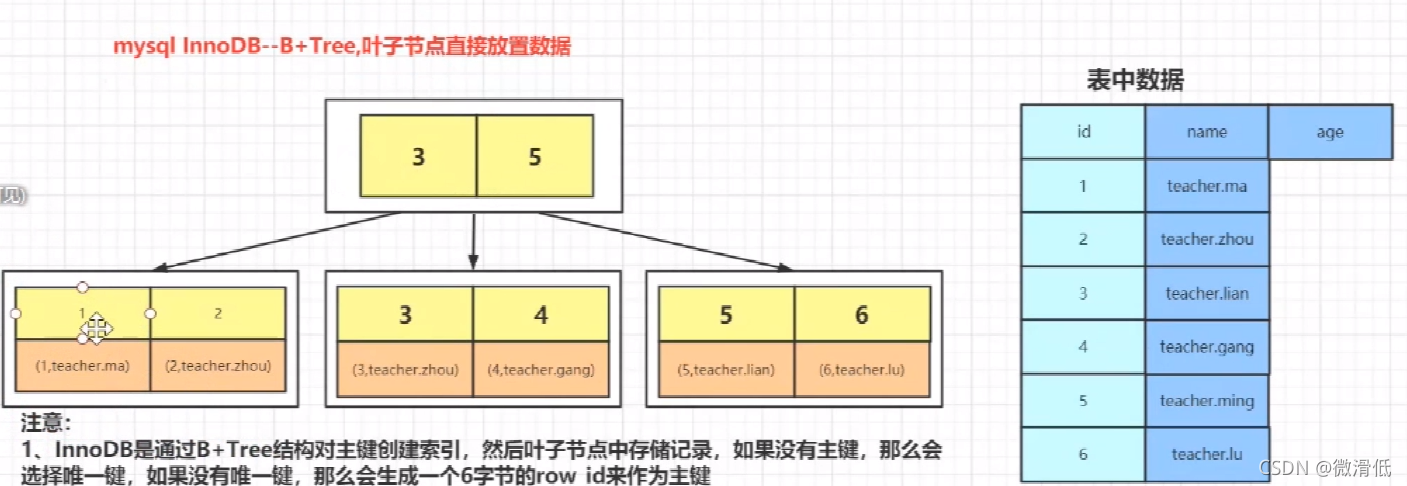
innodb上面放的是索引(1),下面是数据(1,teacher.ma)
因为聚簇索引数据跟索引放到一起,如果有多个聚簇索引就会产生数据冗余
3.假设我们再给name字段加个索引,之前的id已经是主键了,那么存储方式就会演变成下面这种了
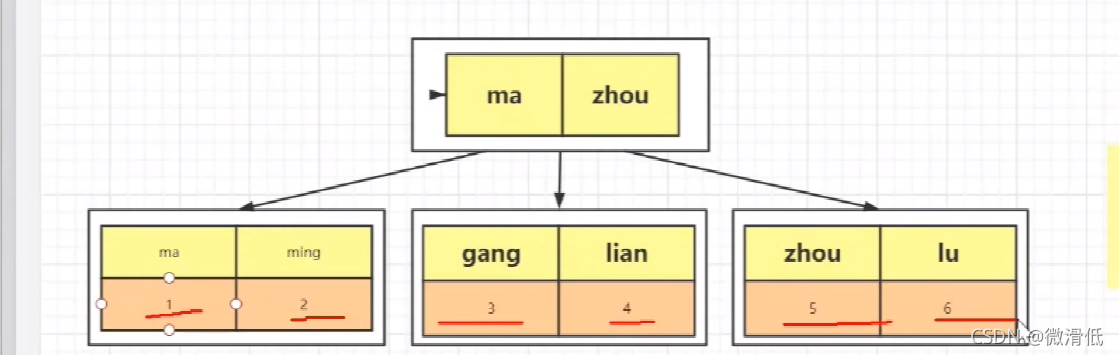
为什么呢?因为我们给name建立了
非聚簇索引
,所以name下面就不能存放数据,因为会造成数据冗余,那应该放什么?
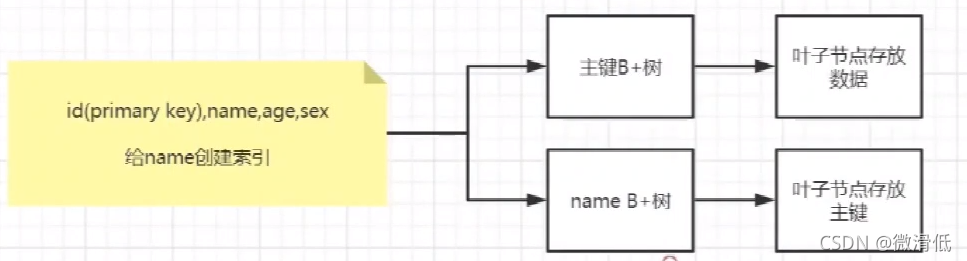
应该放数据所在索引的key的值,所有非聚簇索引都指向聚簇索引,不然找不到数据
4.什么是回表?
还是上面的一张表,我们假设id是主键,name是索引列
select * from table where name = ma
先根据name查询id,再根据id查询整行的记录,走了2颗B+树,此时这种现象叫
回表
回表:当根据普通索引查询到聚簇索引的key值之后,再根据key值聚簇索引中获取所有行记录
5.什么是索引覆盖
select id,name from table where name = ma
根据name可以直接查询id,name两个列的值,直接返回即可,不需要从聚簇索引查询任何数据,此时叫
索引覆盖
6.什么是最左匹配
还是上面那张表,id是主键,name和age是组合索引列,组合索引使用的时候必须先匹配name再匹配age

最左匹配
:
在MySQL建立联合索引时会遵守最左前缀匹配原则,即最左优先,在检索数据时从联合索引的最左边开始匹配
7.什么是索引下推
mysql分为三层架构
select * from table where name=?and age=?
在没有索引下推之前
:先根据name从存储引擎中获取符合规则的数据,然后再server层对age进行过滤
有索引下推之后
:根据name,age两个的条件来从存储引擎中获取对应的数据
索引下推
:
原来在server层做的计算,放到存储引擎中计算了,减少了server层和存储引擎层的数据交互