点击上方“Java基基”,选择“设为星标”
做积极的人,而不是积极废人!
每天 14:00 更新文章,每天掉亿点点头发…
源码精品专栏
ES 的集群模式和 kafka 很像,kafka 又和 redis 的集群模式很像。总之就是相互借鉴!
不管你用没用过 ES,今天我们一起聊聊它。就当扩展大家的知识广度了!
认识倒排索引
「正排索引 VS 倒排索引:」
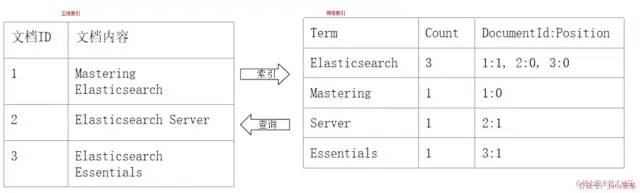
「倒排索引包括两个部分:」
-
单词词典(
Term Dictionary):记录所有文档的单词,记录单词到倒排列表的关联关系❝
单词词典一般比较大,可以通过
B+树 或 哈希拉链法实现,以满足高性能的插入与查询❞
-
倒排列表(
Posting List):记录了单词对应的文档结合,由倒排索引项(Posting)组成: -
-
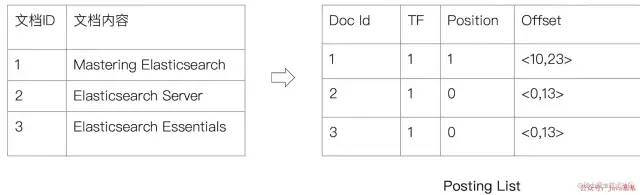
文档
ID
-
-
词频
TF:该单词在文档中出现的次数,用于相关性评分 -
位置(
Position):单词在文档中分词的位置。用于语句搜索(Phrase Query) -
偏移(
Offset):记录单词的开始结束位置,实现高亮显示
「ElasticSearch 的倒排索引:」
-
ElasticSearch的JSON文档中的每个字段,都有自己的倒排索引 -
可以针对某些字段不做索引
-
优点:节省存储空间
-
缺点:字段无法被搜索
-
基于 Spring Boot + MyBatis Plus + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
项目地址:https://github.com/YunaiV/ruoyi-vue-pro
视频教程:https://doc.iocoder.cn/video/
分布式架构原理
「分片 shard:一个索引可以拆分成多个 shard 分片。」
-
主分片
primary shard:每个分片都有一个主分片。 -
备份分片
replica shard:主分片写入数据后,会将数据同步给其他备份分片。
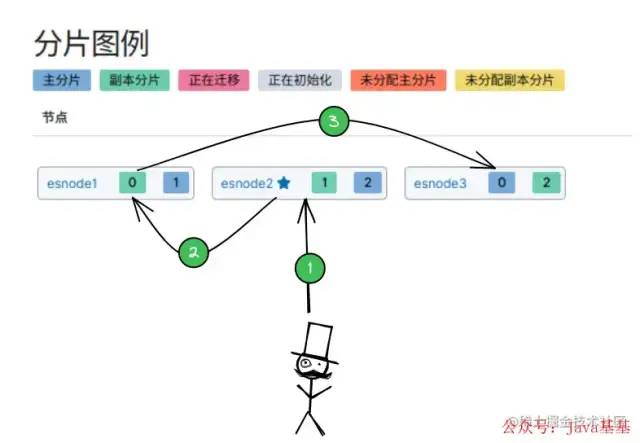
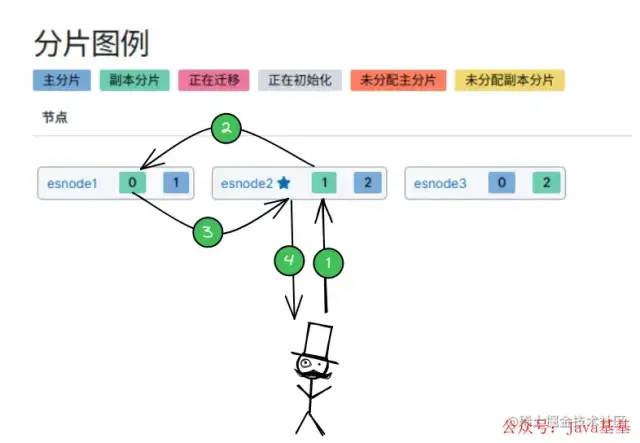
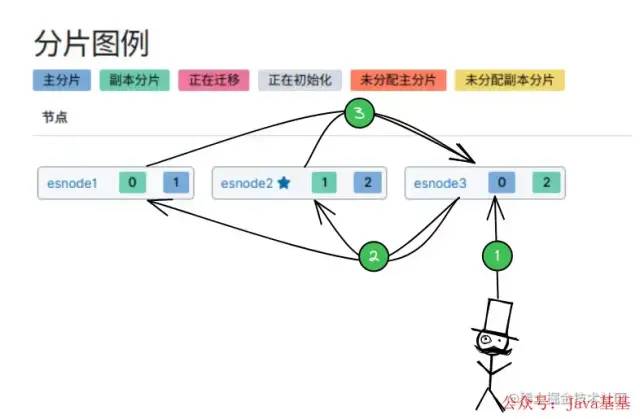
将 ES 集群部署在 3个 机器上(esnode1、esnode2、esnode3):
「创建个索引,分片为 3 个,副本数设置为 1:」
PUT /sku_index/_settings
{
"settings": {
"number_of_shards" : 3,
"number_of_replicas": 1
}
}
响应:
{
"acknowledged" : true
}
「ES 集群中有多个节点,会自动选举一个节点为 master 节点,如上图的 esnode2节点:」
-
主节点(
master):管理工作,维护索引元数据、负责切换主分片和备份分片身份等。 -
从节点(
node):数据存储。
「集群中某节点宕机:」
-
主节点宕机:会重新选举一个节点为 主节点。
-
从节点宕机:由 主节点,将宕机节点上的 主分片身份转移到其他机器上的 备份分片上。
基于 Spring Cloud Alibaba + Gateway + Nacos + RocketMQ + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
项目地址:https://github.com/YunaiV/yudao-cloud
视频教程:https://doc.iocoder.cn/video/
写入数据的工作原理
「写单个文档所需的步骤:」
-
客户端选择一个
Node发送请求,那么这个Node就称为 「协调节点(Coorinating Node)」 。 -
Node使用文档ID来确定文档属于分片 0,通过集群状态中的内容路由表信息获知分片0 的主分片在Node1上,因此将请求转发到Node1上。 -
Node1上的主分片执行写操作。如果写入成功,则将请求并行转发到Node3的副分片上,等待返回结果。当所有的副分片都报告成功,
Node1将向Node(协调节点)报告成功。
「Tips:客户端收到成功响应时,意味着写操作已经在主分片和所有副分片都执行完成。」
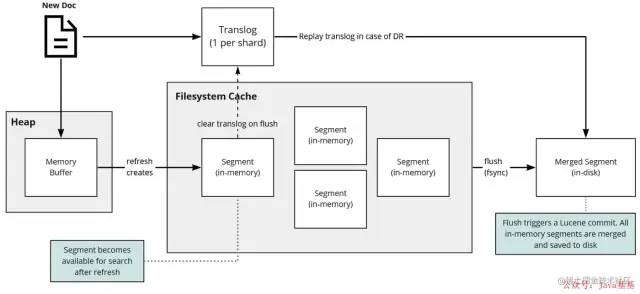
写数据底层原理
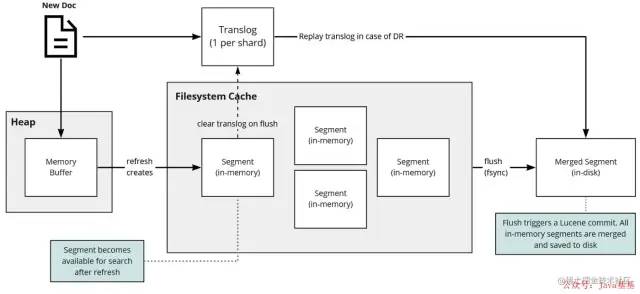
「写操作可分为 3 个主要操作:」
-
写入新文档: 这时候搜索,是搜索不到。
-
将数据写入内存
-
将这操作写入
translog文件中
-
refresh操作: 默认每隔 1s ,将内存中的文档写入文件系统缓存(filesystem cache)构成一个segment❝
这时候搜索,可以搜索到数据。
❞
-
「
1s时间:ES是近实时搜索,即数据写入1s后可以搜索到。」
flush 操作: 默认每隔 30 分钟 或者 translog 文件 512MB ,将文件系统缓存中的 segment 写入磁盘,并将 translog 删除。
「translog 文件:」 来记录两次 flush(fsync) 之间所有的操作,当机器从故障中恢复或者重启,可以根据此还原
-
translog是文件,存在于内存中,如果掉电一样会丢失。 -
「默认每隔 5s 刷一次到磁盘中」
读取数据的工作原理
「读取文档所需的步骤:」
-
客户端选择一个
Node发送请求,那么这个Node就称为 「协调节点(Coorinating Node)」 。 -
Node使用文档ID来确定文档属于分片 0,通过集群状态中的内容路由表信息获知分片0 有 2 个副本数据(一主一副),会使用随机轮询算法选择出一个分片,这里将请求转发到Node1 -
Node1将文档返回给Node,Node将文档返回给客户端。
「在读取时,文档可能已经存在于主分片上,但还没有复制到副分片,这种情况下:」
-
读请求命中副分片时,可能会报告文档不存在。
-
读请求命中主分片时,可能成功返回文档。
搜索工作原理
「搜索数据过程:」
-
客户端选择一个
Node发送请求,那么这个Node就称为 「协调节点(Coorinating Node)」 。 -
Node协调节点将搜索请求转发到所有的 分片(shard):主分片 或 副分片,都可以。 -
「
query阶段」 :每个分片shard将自己的搜索结果(文档ID)返回给协调节点,由协调节点进行数据的合并、排序、分页等操作,产出最终结果。 -
「
fetch阶段」 :由协调节点根据 文档ID去各个节点上拉取实际的文档数据。
举个栗子: 有 3 个分片,查询返回前 10 个匹配度最高的文档
-
每个分片都查询出当前分片的
TOP 10数据 -
「协调节点」 将
3 * 10 = 30的结果再次排序,返回最终TOP 10的结果。
删除/更新数据底层原理
-
「删除操作」 :
commit的时候会生成一个.del文件,里面将某个doc标识为deleted状态,那么搜索的时候根据.del文件就知道这个 doc 是否被删除了。 -
「更新操作」 :就是将原来的
doc标识为deleted状态,然后新写入一条数据。
「底层逻辑是:」
-
Index Buffer每次refresh操作,就会产生一个segment file。(默认情况:1秒1次) -
定制执行
merge操作:将多个segment file合并成一个,同时将标识为deleted的doc「物理删除」 ,将新的segment file写入磁盘,最后打上commit point标识所有新的segment file。
欢迎加入我的知识星球,一起探讨架构,交流源码。加入方式,长按下方二维码噢:

已在知识星球更新源码解析如下:




最近更新《芋道 SpringBoot 2.X 入门》系列,已经 101 余篇,覆盖了 MyBatis、Redis、MongoDB、ES、分库分表、读写分离、SpringMVC、Webflux、权限、WebSocket、Dubbo、RabbitMQ、RocketMQ、Kafka、性能测试等等内容。
提供近 3W 行代码的 SpringBoot 示例,以及超 6W 行代码的电商微服务项目。
获取方式:点“在看”,关注公众号并回复 666 领取,更多内容陆续奉上。
文章有帮助的话,在看,转发吧。
谢谢支持哟 (*^__^*)