前言
数据挖掘中我们经常会遇到高维数据,特别是当我们的特征工程做得比较复杂时,这些特征可能会让我们的模型过拟合,或者很多特征是没有意义,对模型的优化起不到作用,反而会降低模型的运行效率和精度,所以我们需要对我们的特征变量进行筛选,去除掉无意义的特征,尽可能保留少而强的特征。
下面是我用得最多的几个方法,也是我个人觉得最实用方法,其他特征筛选方法大家可以自行查阅资料,这里不多介绍。
代码中data代表所有特征变量(自变量),label代表标签(因变量)
。
方差选择
方差选择法对于数值变量(连续型变量)的筛选来说是一个不错的选择。方差选择很好理解,
一个特征变量的方差可以反映该特征取值的发散性
,如果一个特征取值全部一样,那么这个特征其实就是没有任何意义的,那么方差就为0,相反,方差越大,就越能说明取值具有差异性。所有,我们可以设定一个阈值,只要有特征方差小于该阈值,就抛弃掉,选择大于我们设定阈值的特征作为模型的输入。
实现代码如下:
from sklearn.feature_selection import VarianceThreshold
#返回选择后的特征
select_feature=VarianceThreshold(threshold=1).fit_transform(data)#threshold为设定的阈值,默认为0
上面可以看到我们sklearn库已经封装好了实现代码,所有不需要我们自己去写代码,直接调用函数接口就行了。
卡方检验
卡方检验的公式(其中A为实际的频数,E为期望频数):
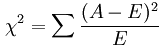
这里公式不用过多介绍,有想详细了解的可以参考
卡方检验
,计算出卡方值之后,我们还需要计算自由度和置信度,然后根据相应的区间的值进行合理判断。如果实在看不懂的也没关系,我们只需要知道一点,
卡方检验可以反映自变量和因变量之间的相关性
,知道这一点就足够了。但是这里要注意一个非常重要的问题,我们也可以通过上面的公式看出来,
卡方检验只能用于分类问题,因为我们的类别都是离散值,所有频数都是某个类别产生的频数,对于连续性变量不可行(如果有误,请指正!)
。
我们来看代码:
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
select_feature=SelectKBest(chi2,k=5).fit_transform(data,label)#保留K个相关性最好的特征,返回选择特征后特征
同样是封装好了的代码,只需要简单调用接口即可。
相关系数
相关系数一般都是指皮尔森系数,它是两个变量协方差和两个变量标准差乘积的比值
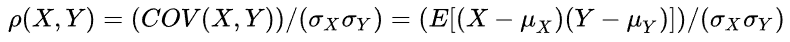
它可以
衡量变量之间的线性相关性
,结果的取值区间为[-1,1],-1表示完全的负相关,+1表示完全的正相关,0表示没有线性相关。所以我们可以通过计算特征与目标变量之间的相关性强弱进行对特征的筛选。
from sklearn.feature_selection import SelectKBest
from scipy.stats import pearsonr
select_feature=SelectKBest(lambda X, Y: np.array(list(map(lambda x:pearsonr(x, Y), X.T))).T[0], k=10).fit_transform(data,label) #参数k为保留特征的数量
皮尔森系数有一个缺点就是不能计算出非线性的相关性,就算自变量和因变量存在一一对应的关系,但是是非线性的,皮尔森系数仍然趋近于0,所以对于非线性关系的映射皮尔森系数不可信,我们需要对数据进行可视化分析得出结果。
当然,我们分析相关性也可以通过其他系数,比如前面我画热力图那篇博客就是通过
斯皮尔曼相关性系数
计算得到的,大家也可以自行进行尝试。
递归特征消除(RFE)
RFE很好理解,首先,预测模型在原始特征上训练,每个特征指定一个权重。之后,那些拥有最小绝对值权重的特征被踢出特征集。如此往复递归,直至剩余的特征数量达到所需的特征数量。
from sklearn.feature_selection import RFE
from sklearn.linear_model import Ridge
#选择Ridge为基模型
select_feature=RFE(estimator=Ridge(),n_features_to_select=5).fit_transform(data,label)#保留5个特征
从RFE的流程我们可以看出一个最大的问题就是计算资源和时间的庞大,如果我们的数据和模型都比较复杂的情况下,这种方法会耗费大量计算时间,所以在面对相对简单的业务环境下可以采取这种方式。
其他方法
我们还有很多筛选特征的方法,比如经典的互信息筛选,比如GBDT等树模型采取的信息增益排序,还可以用正则项进行特征筛选等等,在不同的业务环境下可以采取多种措施,这里不再一一介绍,我只介绍了我用得最多的几种方法,其他方法大家可以自行尝试!
写在最后
我们的特征筛选往往都不局限于使用一种方法,因为每种方法都有各自的优缺点,更多的是结合多种方法进行特征筛选,取长补短,这样最终达到的效果应该才是最好的。
本人才疏学浅,如果有错误或者理解不到位的地方请指正!