一 Ray是什么,优势
Spark则是一个面向数据处理的产品,RDD则是以数据作为抽象对象的,你关心的应该是数据如何处理,而不是去如何拆解任务,关心资源如何被分配,这其中涉及的概念比如Job,Stage,task你最好都不要管,RDD自己来决定。
Ray 是一个任务级别分配的分布式框架, Ray的系统层是以Task为抽象粒度的,用户可以在代码里任意生成和组合task,比如拆分成多个Stage,每个Task执行什么逻辑,每个task需要多少资源,非常自由,对资源把控力很强
Ray 可以用来在多个核心或机器上扩展 Python 应用。它有几个主要的优点,包括:
简单性:你可以扩展你的 Python 应用,而不需要重写,同样的代码可以在一台机器或多台机器上运行。
稳健性:应用程序可以优雅地处理机器故障和进程抢占。
性能:任务以毫秒级的延迟运行,可扩展到数万个内核,并以最小的序列化开销处理数值数据。
架构图
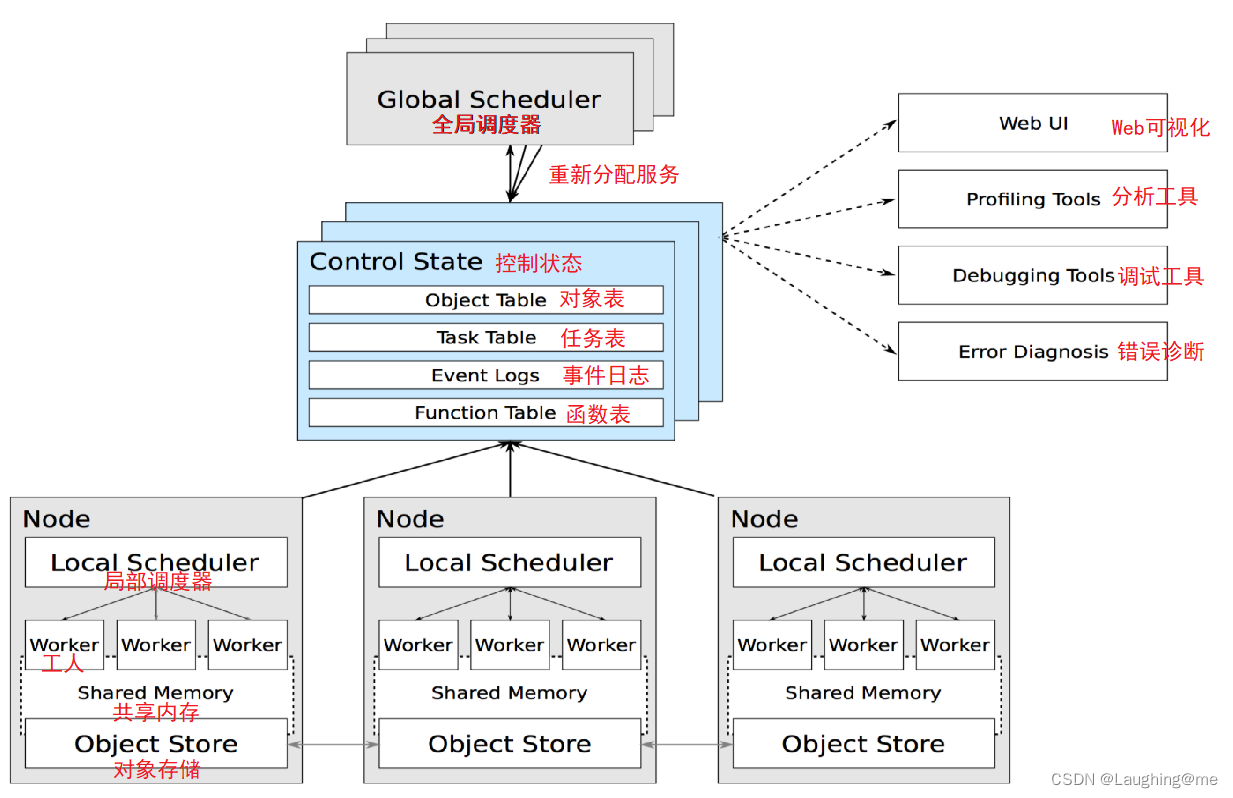
GlobalScheduler(全局调度器)— Master上启动一个全局调度器用于接收本地调度器提交的任务;并将任务分发给合适的本地任务调度器执行。
RedisServer Master(重新分配任务)— 启动一到多个RedisServer用于保存分布式任务的状态信息(Control State),包括对象机器的映射、任务描述、任务debug信息等。
LocalScheduler(局部调度器)— 每个Slave上启动一个本地调度器,用于提交任务到全局调度器,以及分配任务给当前机器的Worker进程。
Worker(工人)— 每个Slave上可以启动多个Worker进程执行分布式任务;并将计算结果存储到ObjectStore。
ObjectStore(对象存储)— 每个Slave上启动一个ObjectStore存储只读数据对象;Worker可以通过共享内存的方式访问这些对象数据;这样可以有效地减少内存拷贝和对象序列化成本,ObjectStore底层由Apache Arrow实现。
Plasma — 每个Slave上的ObjectStore都由一个名为Plasma的对象管理器进行管理;它可以在Worker访问本地ObjectStore上不存在的远程数据对象时主动拉取其它Slave上的对象数据到当前机器。
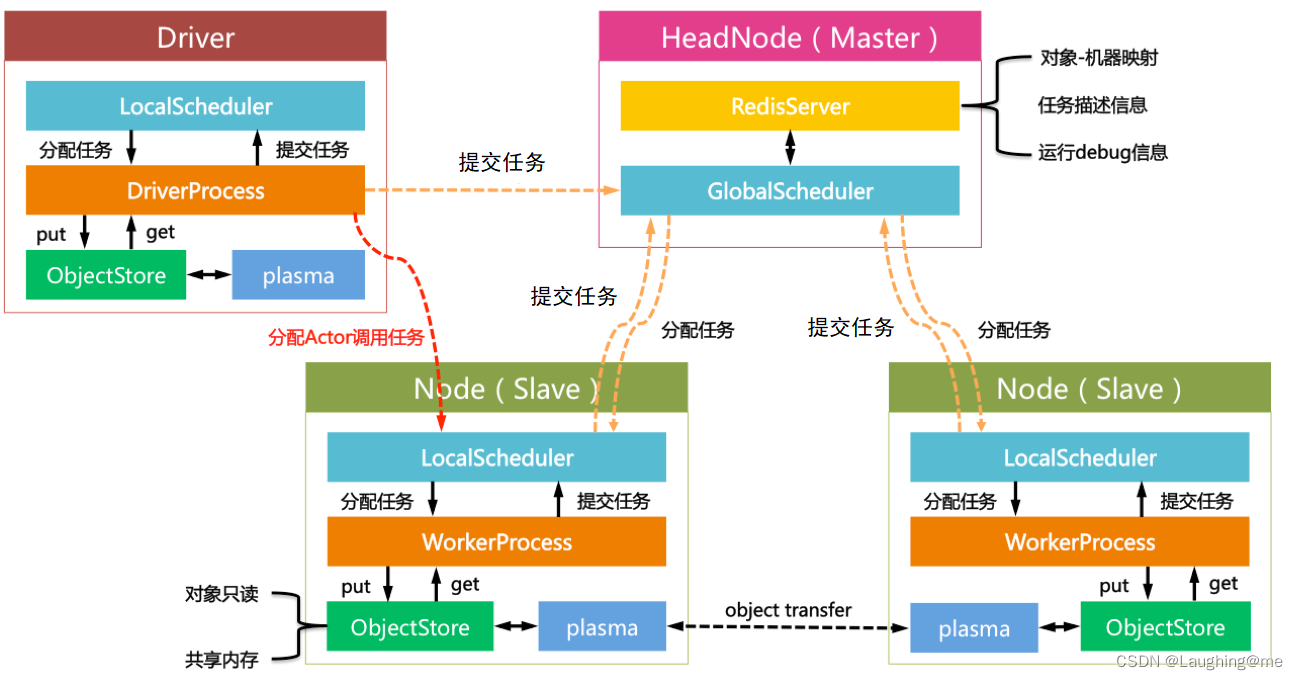
Ray的Driver节点和和Slave节点启动的组件几乎相同;不过却有以下区别:
Driver上的工作进程DriverProcess一般只有一个,即用户启动的PythonShell;Slave可以根据需要创建多个WorkerProcess。
Driver只能提交任务却不能来自全局调度器分配的任务。Slave可以提交任务也可以接收全局调度器分配的任务。
Driver可以主动绕过全局调度器给Slave发送Actor调用任务(此处设计是否合理尚不讨论);Slave只能接收全局调度器分配的计算任务。
二 Ray高效实现使用
- 无状态任务并行,同时发送多个square函数,此函数会异步提交到ray 服务中,并行执行任务,并返回task id并不会直接返回值,相当于指针一样,只有调用ray.get(futures) 可以得到原始值
import ray
ray.init()
# Define the square task.
@ray.remote
def square(x):
return x * x
# Launch four parallel square tasks.
futures = [square.remote(i) for i in range(400)]
# Retrieve results.
print(ray.get(futures))
# -> [0, 1, 4, 9]
- 有状态actor 类调用
增加remote装饰器,此类会在共享内存中实例化,其中类方法调用可以异步执行,类属性可以共享存在
import ray
ray.init()
# Define the Counter actor.
@ray.remote
class Counter:
def __init__(self):
self.i = 0
def get(self):
return self.i
def incr(self, value):
self.i += value
# Create a Counter actor.
c = Counter.remote()
# Submit calls to the actor. These calls run asynchronously but in
# submission order on the remote actor process.
for _ in range(10):
c.incr.remote(1)
# Retrieve final actor state.
print(ray.get(c.get.remote()))
# -> 10
- ray版本paillier 加密,比单核版本快10倍以上,当然数据分流级别比分任务稍快一些
import ray
import time
from phe import paillier
ray.init(address="10.10.10.241:9937")
class Test:
def gen_pubk(self):
pubk, prik = paillier.generate_paillier_keypair(n_length=1024)
return pubk, prik
@staticmethod
@ray.remote
def encrypt(pubk, num):
return pubk.encrypt(num)
@staticmethod
@ray.remote
def encrypt_batch(pubk, num):
lis = []
for i in range(num):
lis.append(pubk.encrypt(i))
return lis
class Run(object):
def encrypt_test(self):
t = Test()
pubk, prik = t.gen_pubk()
task = []
t0 = time.time()
for i in range(10000):
task.append(t.encrypt.remote(pubk=pubk, num=i))
ray.get(task)
print("encrypt_test func time is {}".format(time.time() - t0))
# 9s
def encrypt_batch(self):
t = Test()
pubk, prik = t.gen_pubk()
t0 = time.time()
task = []
for i in range(20):
task.append(t.encrypt_batch.remote(pubk=pubk, num=500))
ray.get(task)
print("encrypt_test func time is {}".format(time.time() - t0))
# 8.3s
if __name__ == '__main__':
r = Run()
r.encrypt_test()
- Map
# 单线程map
items = list(range(100))
map_func = lambda i : i*2
output = [map_func(i) for i in items]
# ray map func
@ray.remote
def map(obj, f):
return f(obj)
items = list(range(100))
map_func = lambda i : i*2
output = ray.get([map.remote(i, map_func) for i in items])
- reduce
# 单线程reduce
items = list(range(100))
map_func = lambda i : i*2
output = sum([map_func(i) for i in items])
# ray reduce
@ray.remote
def map(obj, f):
return f(obj)
@ray.remote
def sum_results(*elements):
return np.sum(elements)
items = list(range(100))
map_func = lambda i : i*2
remote_elements = [map.remote(i, map_func) for i in items]
# simple reduce
remote_final_sum = sum_results.remote(*remote_elements)
result = ray.get(remote_final_sum)
- cal pi example
import ray
import math
import time
import random
ray.init(address="10.10.10.241:9937")
@ray.remote
class ProgressActor:
def __init__(self, total_num_samples: int):
self.total_num_samples = total_num_samples
self.num_samples_completed_per_task = {}
def report_progress(self, task_id: int, num_samples_completed: int) -> None:
self.num_samples_completed_per_task[task_id] = num_samples_completed
def get_progress(self) -> float:
return (
sum(self.num_samples_completed_per_task.values()) / self.total_num_samples
)
@ray.remote
def sampling_task(num_samples: int, task_id: int,
progress_actor: ray.actor.ActorHandle) -> int:
num_inside = 0
for i in range(num_samples):
x, y = random.uniform(-1, 1), random.uniform(-1, 1)
if math.hypot(x, y) <= 1:
num_inside += 1
# Report progress every 1 million samples.
if (i + 1) % 1_000_000 == 0:
# This is async.
progress_actor.report_progress.remote(task_id, i + 1)
# Report the final progress.
progress_actor.report_progress.remote(task_id, num_samples)
return num_inside
# Change this to match your cluster scale.
NUM_SAMPLING_TASKS = 24
NUM_SAMPLES_PER_TASK = 10_000_000
TOTAL_NUM_SAMPLES = NUM_SAMPLING_TASKS * NUM_SAMPLES_PER_TASK
# Create the progress actor.
progress_actor = ProgressActor.remote(TOTAL_NUM_SAMPLES)
results = [
sampling_task.remote(NUM_SAMPLES_PER_TASK, i, progress_actor)
for i in range(NUM_SAMPLING_TASKS)
]
# Query progress periodically.
while True:
progress = ray.get(progress_actor.get_progress.remote())
print(f"Progress: {int(progress * 100)}%")
if progress == 1:
break
time.sleep(1)
# Get all the sampling tasks results.
"""
Monte Carlo 方法估计 π 的值,该方法 通过在 2x2 正方形内随机采样点来工作。
我们可以使用以原点为中心的单位圆内包含的点的比例来估计圆的面积与正方形面积的比值
。鉴于我们知道真实比率为 π/4,我们可以将估计的比率乘以 4 来近似 π 的值。我们为计算该近似值而采样的点越多,该值应该越接近 π 的真实值。
"""
total_num_inside = sum(ray.get(results))
pi = (total_num_inside * 4) / TOTAL_NUM_SAMPLES
print(f"Estimated value of π is: {pi}")
三 Ray数据
https://docs.ray.io/en/latest/data/dataset.html
object
在 Ray 中,任务和参与者在对象上创建和计算。我们将这些对象称为远程对象,因为它们可以存储在 Ray 集群中的任何位置,并且我们使用对象引用来引用它们。远程对象缓存在 Ray 的分布式共享内存 对象库中,集群中的每个节点都有一个对象库。对象 ref本质上是一个指针或唯一 ID,可用于在不查看其值的情况下引用远程对象。如果您熟悉期货,Ray 对象引用在概念上是相似的。
进程或者任务之间通信,可以通过对象的引用进行传递,避免了内存的拷贝
# !/usr/bin/python
# -*- coding: UTF-8 -*-
"""
Ray 将任务和参与者调用结果存储在其分布式对象存储中,返回可以稍后检索的对象引用。
对象引用也可以通过显式创建ray.put,并且对象引用可以作为参数值的替代物传递给任务:
"""
import ray
import numpy as np
ray.init()
# Define a task that sums the values in a matrix.
@ray.remote
def sum_matrix(matrix):
return np.sum(matrix)
# Call the task with a literal argument value.
print(ray.get(sum_matrix.remote(np.ones((100, 100)))))
# -> 10000.0
# Put a large array into the object store.
matrix_ref = ray.put(np.ones((1000, 1000)))
# Call the task with the object reference as an argument.
print(ray.get(sum_matrix.remote(matrix_ref)))
# -> 1000000.0
分布式data
import ray
import pandas as pd
# create data 将数据拆分成10块
ds = ray.data.range(10000)
ds = ds.repartition(10)
print("take ", ds.take(5))
csv数据处理
import ray
import pandas as pd
# read csv
ds = ray.data.read_csv("/Users/tian/Projects/python-BasicUsage/算法/data/my_data_guest.csv")
# 将数据拆分为10个partition
ds = ds.repartition(10)
def pandas_transform(df: pd.DataFrame) -> pd.DataFrame:
# Filter rows.
print("df is ", df.count())
return df
# 设置batch_size ,会根据100一批并行的运行
ds.map_batches(pandas_transform, batch_size=100)
四 部署
安装:
直接安装”pip install ‘ray” 会缺失一些package,资源监控,其他依赖的包等, ‘ray[default]’ 会默认安全所有功能的包
pip install 'ray[default]' -i https://mirrors.aliyun.com/pypi/simple --no-cache-dir
启动主节点
ray start --head --node-ip-address="10.10.10.123" --port="9937" --temp-dir="/data"
ray status 查看节点是否启动成功,目前存在两个节点,一个是主节点启动的节点,另外一个为父节点加入集群的节点
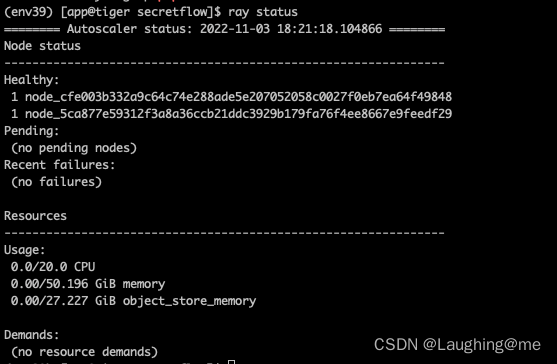
启动子节点:
输入主节点的IP 及 GCS服务端口,子节点会自动加入主节点作为集群一部分
ray start --address="10.10.10.123:9937" --temp-dir="/data"
额外常用的一些参数:
https://docs.ray.io/en/latest/ray-core/configure.html
--num-cpus="10" # 限制节点CPU可用数量
--object-store-memory="10737418240" # 限制对象存储量10G
--memory="10737418240" # 限制堆内存量
--dashboard-port="8265" # 设置监控端口
--dashboard-host='0.0.0.0' # 绑定所有ip,任何都可以访问
--temp-dir="/data" # 设置临时路径,各个服务日志都会保存在此
--system-config='{"object_spilling_config":"{\"type\":\"filesystem\",\"params\":{\"directory_path\":\"/tmp/spill\"}}"}' # 内存占满时,磁盘移除路径设置
Ray worker测试:
启动3个节点
ray start --head --node-ip-address="127.0.0.1" --port="9937" --resources='{"bob": 5}' --num-cpus="5"
ray start --address="127.0.0.1:9937" --resources='{"alice": 2}' --num-cpus="2"
ray start --address="127.0.0.1:9937" --resources='{"ming1": 1,"ming2":1}' --num-cpus="2"
{“bob”: 1} 设置bob 最多可运行一个worker,默认一个worker使用一个cpu资源,远程算法调用时,option可指定使用那个worker
经过测试发现:
将计算密集型的函数分发给bob,注意{“bob”:1} ;
- bob=5时,会分散worker计算cpu数,相当于函数同时提交给5worker对应1cpu,计算反而变慢, 5个worker去处理任务,反而会形成串行。
-
我们使用bob:1 时,相当于将函数提交给这1worker去处理,再提交任务也是任意挑选一个worker去处理,这样并行度能达到5
全局actor 可以分配给alice去单独运行。
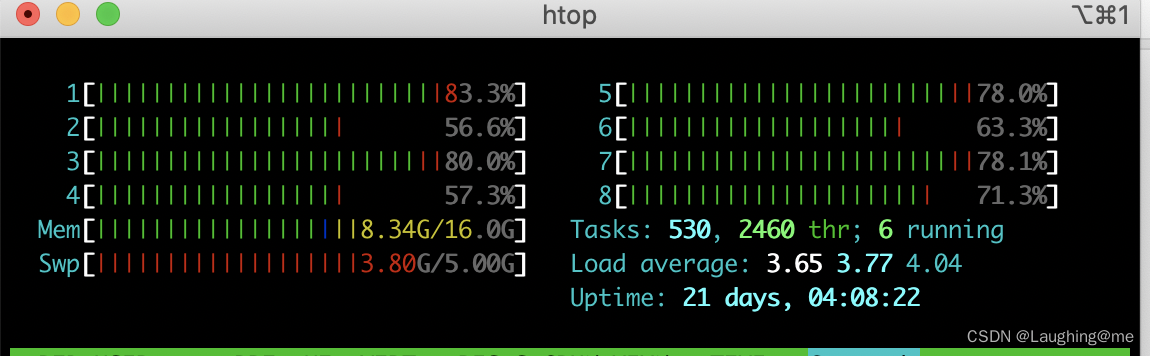
容器集群启动
首先保证服务器网络是可以互相访问的
yum install telnet -y
telnet ip port
容器以host模式启动容器,所有的端口都会与宿主机共享;或者一些主服务节点,在容器中暴漏出来
docker run --net=host -itd docker_image # 推荐这种,ray服务端口会比较多,逐一映射定义会有些麻烦
docker run -p port:port -itd docker_image
Dashboard 服务无法运行:
https://www.jianshu.com/p/40ff76cbf8ca
集群模式容器内启动:
# 主节点启动
ray start --head --node-ip-address="10.10.10.123" --port="9937" --num-cpus="20" --resources='{"bob": 20}' --include-dashboard=False --disable-usage-stats
# 子节点1
ray start --address="10.10.10.123:9937" --num-cpus="20" --resources='{"alice": 20}' --disable-usage-stats
# 子节点2
ray start --address="10.10.10.123:9937" --num-cpus="20" --resources='{"alice2": 20}' --disable-usage-stats
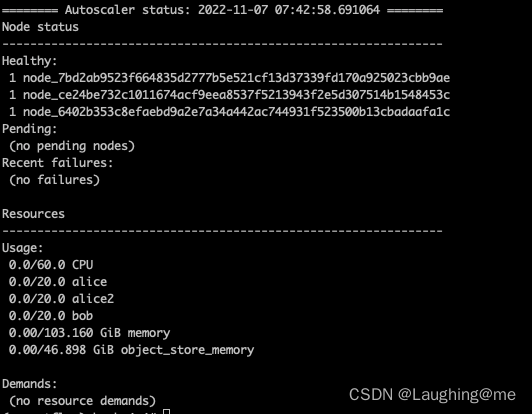
此时有三个节点存在,提交一个并行任务
import ray
import random
import time
import math
from fractions import Fraction
# Let's start Ray
ray.init(address='127.0.0.1:9937')
# 圆中点的个数/正方形点的个数 = math.pi / 4
# pi = 4 * 圆中点的个数/正方形点的个数
@ray.remote
def pi4_sample(sample_count):
"""pi4_sample runs sample_count experiments, and returns the
fraction of time it was inside the circle.
"""
in_count = 0
for i in range(sample_count):
x = random.random()
y = random.random()
if x * x + y * y <= 1:
in_count += 1
return Fraction(in_count, sample_count)
# 单核
SAMPLE_COUNT = 1000 * 1000
start = time.time()
# future = pi4_sample.remote(sample_count=SAMPLE_COUNT)
# pi4 = ray.get(future)
# print(float(pi4 * 4))
# 多核
FULL_SAMPLE_COUNT = 60 * 10 * 1000 * 1000 # 100 billion samples!
BATCHES = int(FULL_SAMPLE_COUNT / SAMPLE_COUNT)
print(f'Doing {BATCHES} batches')
results = []
for _ in range(BATCHES):
results.append(pi4_sample.remote(sample_count=SAMPLE_COUNT))
# results.append(pi4_sample.options(resources={"alice": 1}).remote(sample_count=SAMPLE_COUNT))
output = ray.get(results)
pi = sum(output) * 4 / len(output)
print(float(pi), " ", abs(pi - math.pi) / pi)
end = time.time()
dur = end - start
print(f'Running {SAMPLE_COUNT} tests took {dur} seconds')
此时会有60 core同时运行

如果只需要某一台机器运行,或者空闲的机器运行只需要指定对应的resources即可, 此处是函数提交时,一个worker去处理
results.append(pi4_sample.options(resources={"alice": 1}).remote(sample_count=SAMPLE_COUNT))
只有alice对应的机器才会运行任务
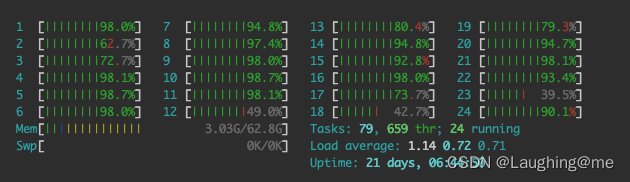
使用ray.get会获得最终的计算结果