
文章来源:SIGAI
本文共
9400字,
建议阅读
10+分钟。
本文将和大家一起回顾人脸检测算法的整个发展历史。
[导读]
人脸检测是目前所有目标检测子方向中被研究的最充分的问题之一,它在安防监控,人证比对,人机交互,社交和娱乐等方面有很强的应用价值,也是整个人脸识别算法的第一步。
问题描述
人脸检测的目标是找出图像中所有的人脸对应的位置,算法的输出是人脸外接矩形在图像中的坐标,可能还包括姿态如倾斜角度等信息。下面是一张图像的人脸检测结果:

虽然人脸的结构是确定的,由眉毛、眼睛、鼻子和嘴等部位组成,近似是一个刚体,但由于姿态和表情的变化,不同人的外观差异,光照,遮挡的影响,准确的检测处于各种条件下的人脸是一件相对困难的事情。
人脸检测算法要解决以下几个核心问题:
-
人脸可能出现在图像中的任何一个位置
-
人脸可能有不同的大小
-
人脸在图像中可能有不同的视角和姿态
-
人脸可能部分被遮挡
评价一个人脸检测算法好坏的指标是
检测率
和
误报率
。
我们将检测率定义为:

误报率定义为:

算法要在检测率和误报率之间做平衡,理想的情况是有高检测率,低误报率。
经典的人脸检测算法流程是这样的:用大量的人脸和非人脸样本图像进行训练,得到一个解决2类分类问题的分类器,也称为人脸检测模板。这个分类器接受固定大小的输入图片,判断这个输入图片是否为人脸,即解决是和否的问题。人脸二分类器的原理如下图所示:
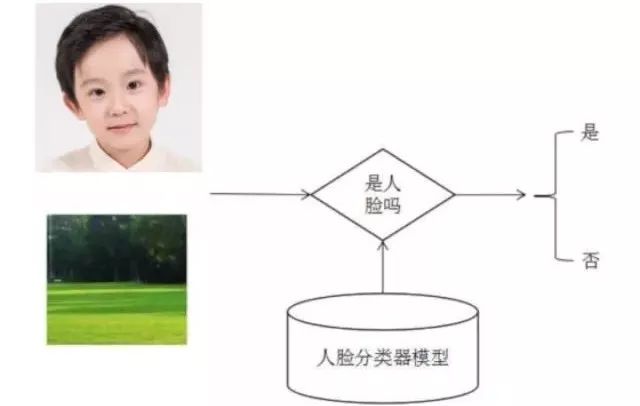
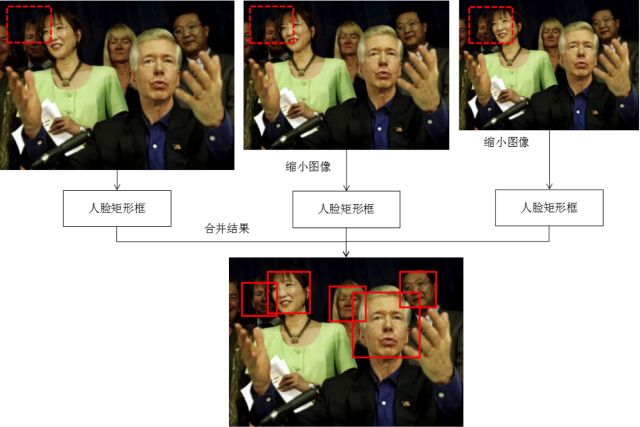
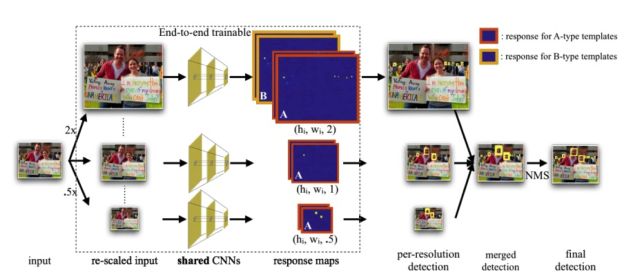
由于人脸可能出现在图像的任何位置,在检测时用固定大小的窗口对图像从上到下、从左到右扫描,判断窗口里的子图像是否为人脸,这称为滑动窗口技术(sliding window)。为了检测不同大小的人脸,还需要对图像进行放大或者缩小构造图像金字塔,对每张缩放后的图像都用上面的方法进行扫描。由于采用了滑动窗口扫描技术,并且要对图像进行反复缩放然后扫描,因此整个检测过程会非常耗时。
由于一个人脸附件可能会检测出多个候选位置框,还需要将检测结果进行合并去重,这称为非极大值抑制(NMS)。多尺度滑动窗口技术的原理如下图所示:
以512×512大小的图像为例,假设分类器窗口为24×24,滑动窗口的步长为1,则总共需要扫描的窗口数为:
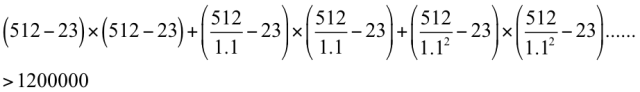
即要检测一张图片需要扫描大于120万个窗口!!!计算量惊人,因此有必要采取某种措施提高效率,具体解决方案本文会给出。
典型应用
人脸检测是机器视觉领域被深入研究的经典问题,在安防监控、人证比对、人机交互、社交等领域都有重要的应用价值。数码相机、智能手机等端上的设备已经大量使用人脸检测技术实现成像时对人脸的对焦、图集整理分类等功能,各种虚拟美颜相机也需要人脸检测技术定位人脸,然后才能根据人脸对齐的技术确定人脸皮肤、五官的范围然后进行美颜。在
人脸识别的流程中
,人脸检测是整个人脸识别算法的第一步。
早期算法
我们将整个人脸检测算法分为3个阶段,分别是早期算法,AdaBoost框架,以及深度学习时代,在接下来将分这几部分进行介绍。
早期的人脸检测算法使用了模板匹配技术,即用一个人脸模板图像与被检测图像中的各个位置进行匹配,确定这个位置处是否有人脸;此后机器学习算法被用于该问题,包括神经网络,支持向量机等。以上都是针对图像中某个区域进行人脸-非人脸二分类的判别。
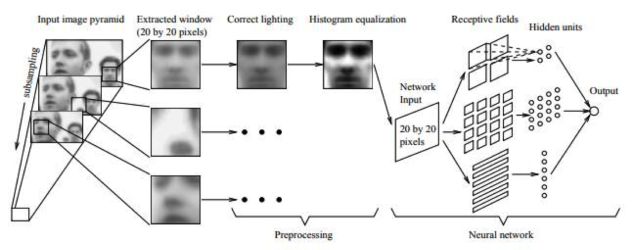
早期有代表性的成果是Rowley等人提出的方法[1][2]。他们用神经网络进行人脸检测,用20×20的人脸和非人脸图像训练了一个多层感知器模型。文献[1]的方法用于解决近似正面的人脸检测问题,原理如下图所示:
文献[2]的方法解决多角度人脸检测问题,整个系统由两个神经网络构成,第一个网络用于估计人脸的角度,第二个用于判断是否为人脸。角度估计器输出一个旋转角度,然后用整个角度对检测窗进行旋转,然后用第二个网络对旋转后的图像进行判断,确定是否为人脸。系统结构如下图所示:
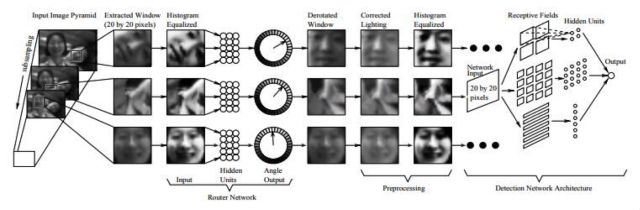
Rowley的方法有不错的精度,由于分类器的设计相对复杂而且采用的是密集滑动窗口进行采样分类导致其速度太慢。
AdaBoost框架
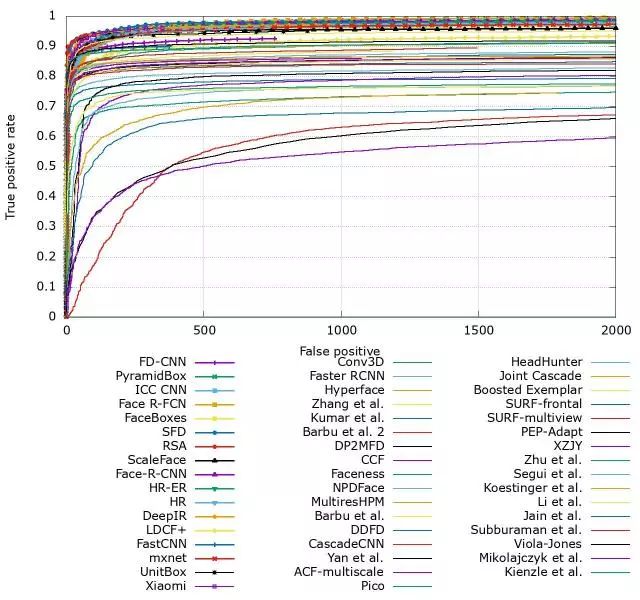
接下来介绍AdaBoost框架之后的方法,boost算法是基于PAC学习理论(probably approximately correct)而建立的一套集成学习算法(ensemble learning)。其根本思想在于通过多个简单的弱分类器,构建出准确率很高的强分类器,PAC学习理论证实了这一方法的可行性,感谢大神Leslie-Valiant!!我们首先来看FDDB上各种检测算法的ROC曲线,接下来的介绍将按照这些ROC曲线上的算法进行展开。
在2001年Viola和Jones设计了一种人脸检测算法[10]。它使用简单的Haar-like特征和级联的AdaBoost分类器构造检测器,检测速度较之前的方法有2个数量级的提高,并且保持了很好的精度,我们称这种方法为VJ框架。VJ框架是人脸检测历史上第一个最具有里程碑意义的一个成果,奠定了基于AdaBoost目标检测框架的基础,所以作为重点和大家唠唠。
用级联AdaBoost分类器进行目标检测的思想是:用多个AdaBoost分类器合作完成对候选框的分类,这些分类器组成一个流水线,对滑动窗口中的候选框图像进行判定,确定它是人脸还是非人脸。
在这一系列AdaBoost分类器中,前面的强分类器设计很简单,包含的弱分类器很少,可以快速排除掉大量的不是人脸的窗口,但也可能会把一些不是人脸的图像判定为人脸。如果一个候选框通过了第一级分类器的筛选即被判定为人脸,则送入下一级分类器中进行判定,以此类推。如果一个待检测窗口通过了所有的强分类器,则认为是人脸,否则是非人脸。下图是分类器级联进行判断的示意图:
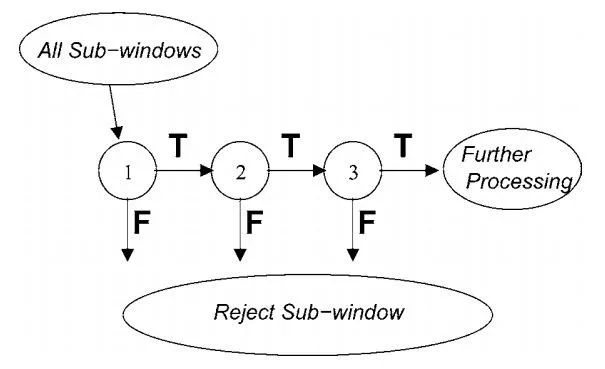
这种思想的精髓在于用简单的强分类器在初期快速排除掉大量的非人脸窗口,同时保证高的召回率,使得最终能通过所有级强分类器的样本数很少。这样做的依据是在待检测图像中,绝大部分都不是人脸而是背景,即人脸是一个稀疏事件,如果能快速的把非人脸样本排除掉,则能大大提高目标检测的效率。
出于性能考虑,弱分类器使用了简单的Haar-like特征,这种特征源自于小波分析中的Haar小波变换,Haar小波是最简单的小波函数,用于对信号进行均值、细节分解。这里的Haar-like特征定义为图像中相邻矩形区域像素之和的差值。下图是基本Haar-like特征的示意图:

Haar-like特征是白色矩形框内的像素值之和,减去黑色区域内的像素值之和。以图像中第一个特征为例,它的计算方法如下:首先计算左边白色矩形区域里所有像素值的和,接下来计算右边黑色矩形区域内所有像素的和,最后得到的Haar-like特征值为左边的和减右边的和。
这种特征捕捉图像的边缘、变化等信息,各种特征描述在各个方向上的图像变化信息。人脸的五官有各自的亮度信息,很符合Haar-like特征的特点。
为了实现快速计算,使用了一种称为积分图(Integral Image)的机制。通过积分图可以快速计算出图像中任何一个矩形区域的像素之和,从而计算出各种类型的Haar-like特征。假设有一张图像,其第i行第j列处的像素值为
![]()
,积分图定义为:
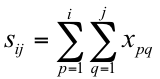
即原始图像在任何一点处的左上角元素之和。在构造出积分图之后,借助于它可以快速计算出任何一个矩形区域内的像素之和,以下图中的矩形框为例:
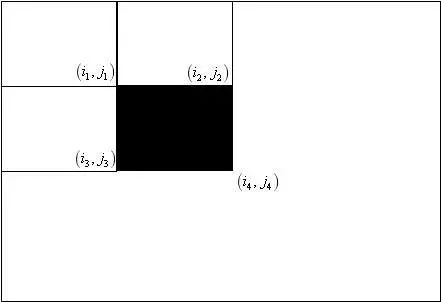
在上图中,要计算黑色矩形框内的像素值之和。假设上面四个矩形的右下角的坐标分别为
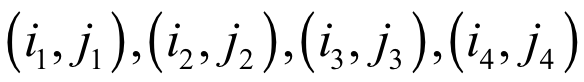
黑色色矩形框内的像素值之和为:
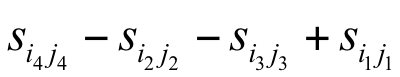
之所以这样,是因为黑色区域内的像素值之和等于这4个矩形框内的像素值之和,减去上面两个矩形框的像素值之和,再减去左边两个矩形框的像素值之和,这样做的话,左上角的矩形框被减了两遍,因此要加一遍回来。在计算出任何一个矩形区域的像素值之和后,可以方便的计算出上面任何一种Haar-like特征。下图是通过AdaBoost算法自动筛选出来的对区分人脸和非人脸有用的Haar-like特征,基本符合人类的直观感受:

弱分类器采用最简单的深度很小的决策树,甚至只有一个内部节点。决策树的训练算法此处不做详细的阐述,需要注意的是这里的特征向量是稀疏的,即每一棵决策树只接受少量特征分量的输入,根据它们来做决策。
强分类器和前面讲述的是一样的,不同的是这里的强分类器加上了一个调节阈值:
其中
![]()
为阈值,它通过训练得到。每一级强分类器在训练时使用所有的人脸样本作为正样本,并用上一级强分类器对负样本图像进行扫描,把找到的虚警中被判定为人脸的区域截取出来作为下一级强分类器的负样本。
假设第i级强分类器的检测率和误报率分别为
![]()
和
![]()
,由于要通过了所有强分类器才被判定为正样本,因此级联分类器的误报率为:
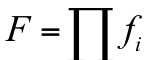
上式表明增加分类器的级数可以降低误报率,类似的级联分类器的检测率为:
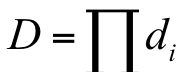
这个式子表明增加分类器的级数会降低检测率。对于前者,可以理解为一个负样本被每一级分类器都判定为正样本的概率;对于后者,可以理解为一个正样本被所有分类器都判定为正样本的概率。
在VJ算法问世之后,较好的解决了近似正面人脸的检测问题。此后出现了大量改进方案,在深度学习技术出现之前,一直是人脸检测算法的主流框架。这些方案的改进主要在以下几个方面:
新的特征,包括扩展的Haar特征[4],ACF特征[15]等,它们比标准的Haar-like特征有更强的描述能力,同时计算成本也很低。
使用其他类型的AdaBoost分类器。VJ框架中采用的是离散型的AdaBoost算法,除此之外,还有实数型,Logit型,Gentle型等各种方案。实数型、Logit型和Gentle型AdaBoost算法不仅能输出分类标签值,还能给出置信度,有更高的精度。
分类器级联结构,如Soft Cascade,将VJ方法的多个强分类器改成一个强分类器(该算法后面会有介绍)。另外,检测处于各种角度和姿态的人脸是研究另一个重点,VJ方法的分类器级联只有一条路径,是瀑布模型,改进的方案有树状级联,金字塔级联等,篇幅所限这里不做过多解释,各种级联方案如下图所示:
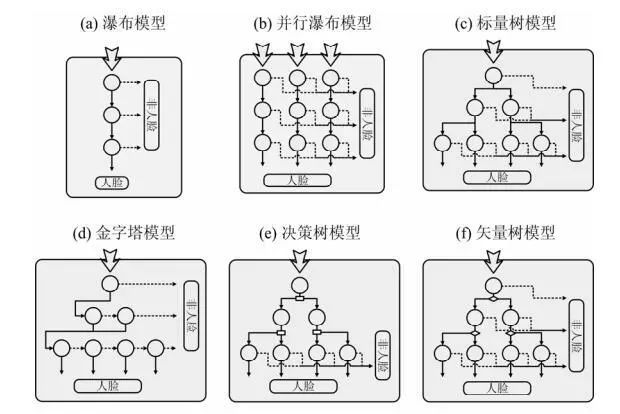
在深度学习出现以前工业界的方案都是基于VJ算法。但VJ算法仍存在一些问题:
1.
Haar-like特征是一种相对简单的特征,其稳定性较低;
2.
弱分类器采用简单的决策树,容易过拟合。因此,该算法对于解决正面的 人脸效果好,对于人脸的遮挡,姿态,表情等特殊且复杂的情况,处理效果不理想(虽然有了一些改进方案,但还是不够彻底!!)。
3.
基于VJ-cascade的分类器设计,进入下一个stage后,之前的信息都丢弃了,分类器评价一个样本不会基于它在之前stage的表现—-这样的分类器鲁棒性差。
4.
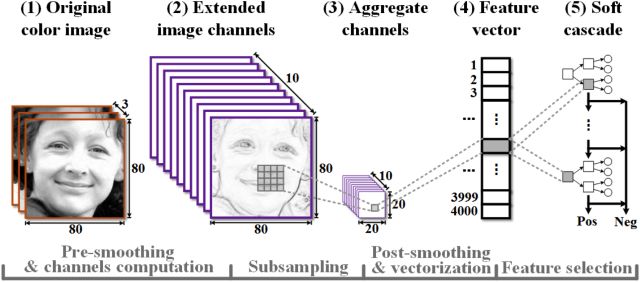
ACF[15](Aggregate Channel Features for Multi-view Face Detection)是一种为分类提供足够多的特征选择的方法。在对原图进行处理后,得到多通道的图像,这些通道可以是RGB的通道,可以是平滑滤波得到的,可以是x方向y方向的梯度图等等。将这些通道合起来,在此基础上提取特征向量后续采用Soft-Cascade分类器进行分类。
相较于VJ-cascade的设计,Soft-Cascade采用几个改进的方案:
1.
每个stage的决策函数不是二值而是标量值(scalar-valued) ,且与该样本有多”容易”通过这个stage以及在这个stage的相对重要性成比例。
2.
生成的决策函数是需要通过之前每个阶段的值而不单单是本阶段来判定。
3.
文中把检测器的运行时间-准确率权衡通过一个叫ROC surface的3维曲面清楚的展示出来,方便调节参数,可以明确的知道动了哪个参数会对这个检测器的性能会有些什么影响。
DMP模型
DPM(Deformable Part Model),正如其名称所述,可变形的组件模型,是一种基于组件的检测算法,其所见即其意。该模型由Felzenszwalb在2008年提出,并发表了一系列的CVPR,NIPS会议。并且还拿下了2010年,PASCAL VOC的“终身成就奖”。
由于DPM算法[16]本身是一种基于组件的检测算法,所以对扭曲,性别,多姿态,多角度等的人脸都具有非常好的检测效果(人脸通常不会有大的形变,可以近似为刚体,基于DMP的方法可以很好地处理人脸检测问题)。

DPM的方法采用的是FHOG进行特征的提取,作者对HOG进行了很大的改动,没有直接采用4*9=36维向量,而是对每个8×8的cell提取18+9+4=31维特征向量。作者还讨论了依据PCA(Principle Component Analysis)可视化的结果选9+4维特征,能达到HOG 4*9维特征的效果。基于DPM的方法在户外人脸集上都取得了比Viola-Jones更好的效果,但是由于该模型过于复杂,判断时计算复杂,很难满足实时性的要求。后续有了一些列改进的流程,比如加入级联分类器,针对特征计算采用了积分图的方法等,但都还没有达到VJ方法的效率。
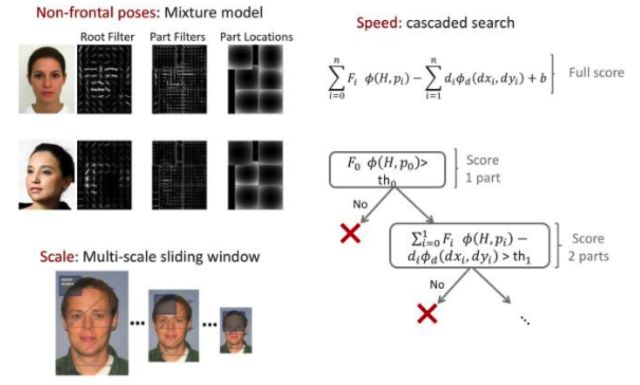
DPM模型一个大的问题是速度太慢,因此在工程中很少使用,一般采用的是AdaBoost框架的算法。
基于经典的人工设计特征本身稳定性并不稳定,容易受外界环境的影响(光照、角度、遮挡等),所以在复杂场景下的人脸检测性能很难的到保证,只能应用到受限的场景中。深度学习出现以后,DCNN(深度卷积神经网络)能很好的学习到图像中目标物各个层级的特征,对外界的抗干扰能力更强,后序的人脸检测方法基本都基于DCNN的特征来优化了。
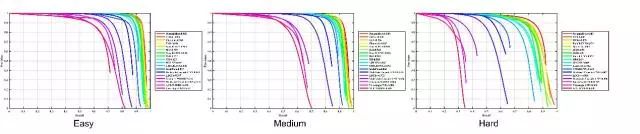
基于深度学习的方法在FDDB上基本饱和了,是时候抛出一个新的benchmark了!!!
WIDERFace测试集上各种算法的性能:
深度学习框架
卷积神经网络在图像分类问题上取得成功之后很快被用于人脸检测问题,在精度上大幅度超越之前的AdaBoost框架,当前已经有一些高精度、高效的算法。直接用滑动窗口加卷积网络对窗口图像进行分类的方案计算量太大很难达到实时,使用卷积网络进行人脸检测的方法采用各种手段解决或者避免这个问题。
-
Cascade CNN
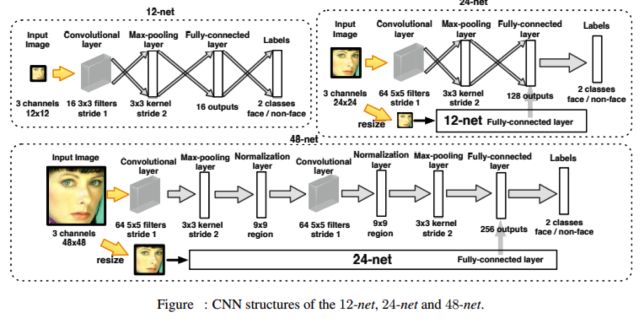
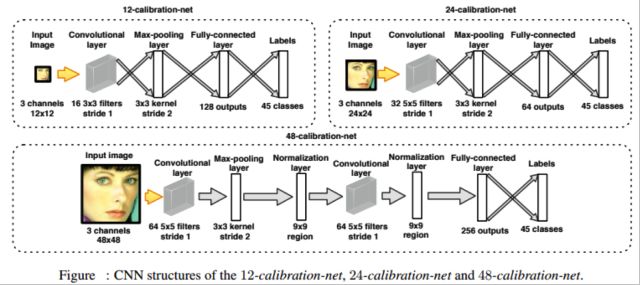
Cascade CNN[17]可以认为是传统技术和深度网络相结合的一个代表,和VJ人脸检测器一样,其包含了多个分类器,这些分类器采用级联结构进行组织,然而不同的地方在于,Cascade CNN采用卷积网络作为每一级的分类器。
构建多尺度的人脸图像金字塔,12-net将密集的扫描这整幅图像(不同的尺寸),快速的剔除掉超过90%的检测窗口,剩下来的检测窗口送入12-calibration-net调整它的尺寸和位置,让它更接近潜在的人脸图像的附近。
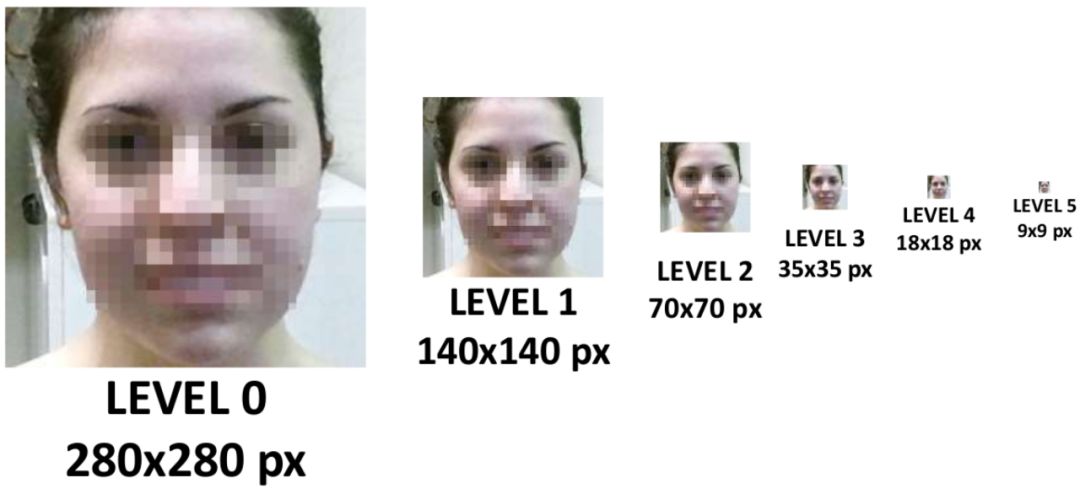
采用非极大值抑制(NMS)合并高度重叠的检测窗口,保留下来的候选检测窗口将会被归一化到24×24作为24-net的输入,这将进一步剔除掉剩下来的将近90%的检测窗口。和之前的过程一样,通过24-calibration-net矫正检测窗口,并应用NMS进一步合并减少检测窗口的数量。
将通过之前所有层级的检测窗口对应的图像区域归一化到48×48送入48-net进行分类得到进一步过滤的人脸候选窗口。然后利用NMS进行窗口合并,送入48-calibration-net矫正检测窗口作为最后的输出。

12×12,24×24,48×48尺寸作为输入的分类CNN网络结构,其中输出为2类-人脸和非人脸。
12×12,24×24,48×48尺寸作为输入的矫正(calibration)CNN网络结构。其中输出为45中种矫正模式的类别。
文中影响区域位置和大小的因素有三种:尺度、X方向偏移、Y方向偏移。总共构成了5x3x3=45种模式。

上一级检测网络输出的人脸位置(x,y,w,h)通过以下公式进行校正:
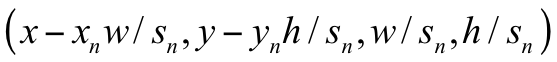
校正网络的结构如下图所示:
Cascade CNN一定程度上解决了传统方法在开放场景中对光照、角度等敏感的问题,但是该框架的第一级还是基于密集滑动窗口的方式进行窗口过滤,在高分辨率存在大量小人脸(tiny face)的图片上限制了算法的性能上限。
-
DenseBox
文献[18]提出了一种称为DenseBox的目标检测算法,适合人脸这类小目标的检测。这种方法使用全卷积网络,在同一个网络中直接预测目标矩形框和目标类别置信度。通过在检测的同时进行关键点定位,进一步提高了检测精度。
检测时的流程如下:
1.
对待检测图像进行缩放,将各种尺度的图像送入卷积网络中处理,以检测不同大小的目标。
2.
经过多次卷积和池化操作之后,对特征图像进行上采样然后再进行卷积,得到最终的输出图像,这张图像包含了每个位置出现目标的概率,以及目标的位置、大小信息。
3.
由输出图像得到目标矩形框。
4.
非最大抑制,得到最终的检测结果。
在检测时卷积网络接受
![]()
的输入图像,产生5个通道的
![]()
输出图像。假设目标矩形左上角
![]()
的坐标为
![]()
,右下角
![]()
的坐标为
![]()
。输出图像中位于点
![]()
处的像素用5维向量描述了一个目标的矩形框和置信度信息:
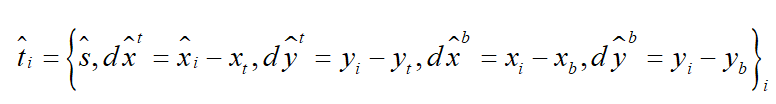
第一个分量是候选框是一个目标的置信度,后面4项分别为本像素的位置与矩形框左上角、右下角的距离。每个像素都转化成一个矩形框和置信度值,然后对置信度值大于指定阈值的矩形框进行非最大抑制,得到最终检测结果。
backbone从VGG 19网络改进得到,包含16个卷积层。前12个卷积层用VGG 19的模型进行初始化。卷积层conv4_4的的输出被送入4个 的卷积层中。第一组的两个卷积层产生1通道的输出图像作为置信度得分;第二组的两个卷积层产生4通道的输出图像作为矩形框的4个坐标。网络的输出有两个并列的分支,分别表示置信度和矩形框位置预测值。整个网络的结构如下图所示:
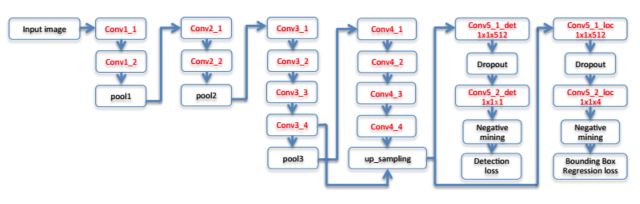
DenseBox的网络结构
为了提高检测精度,采用了多尺度融合的策略。将conv3_4和conv_4_4的卷积结果拼接起来送入后面处理。由于两个层的输出图像大小不同,在这里用了上采样和线性插值对小的图像进行放大,将两种图像尺寸变为相等。
由于输出层有两个并列分支,损失函数由两部分组成。第一部分输出值为分类置信度即本位置是一个目标的概率,用
![]()
表示。真实的类别标签值为
![]()
,取值为0或者1,分别表示是背景和目标。分类损失函数定义为:
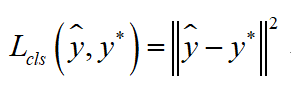
损失函数的第二部分是矩形框预测误差,假设预测值为
![]()
,真实值为
![]()
,它们的4个分量均为当前像素与矩形框左上角和右下角的距离。定位损失函数定义为:
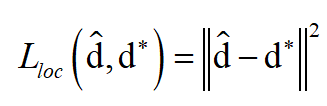
总损失函数为这两部分加权求和。训练时样本标注方案如下:对于任何一个位置,如果它和真实目标矩形框的重叠比大于指定阈值,则标注为1,否则标注为0;对位置的标注根据每个像素与目标矩形框4条边的距离计算。
-
Faceness-Net
Faceness-Net[19]是一个典型的由粗到精的工作流,借助了多个基于DCNN网络的facial parts分类器对人脸进行打分,然后根据每个部件的得分进行规则分析得到Proposal的人脸区域,最后通过一个Refine的网络得到最终的人脸检测结果。整体流程如图 Faceness(b)。

Faceness(a)
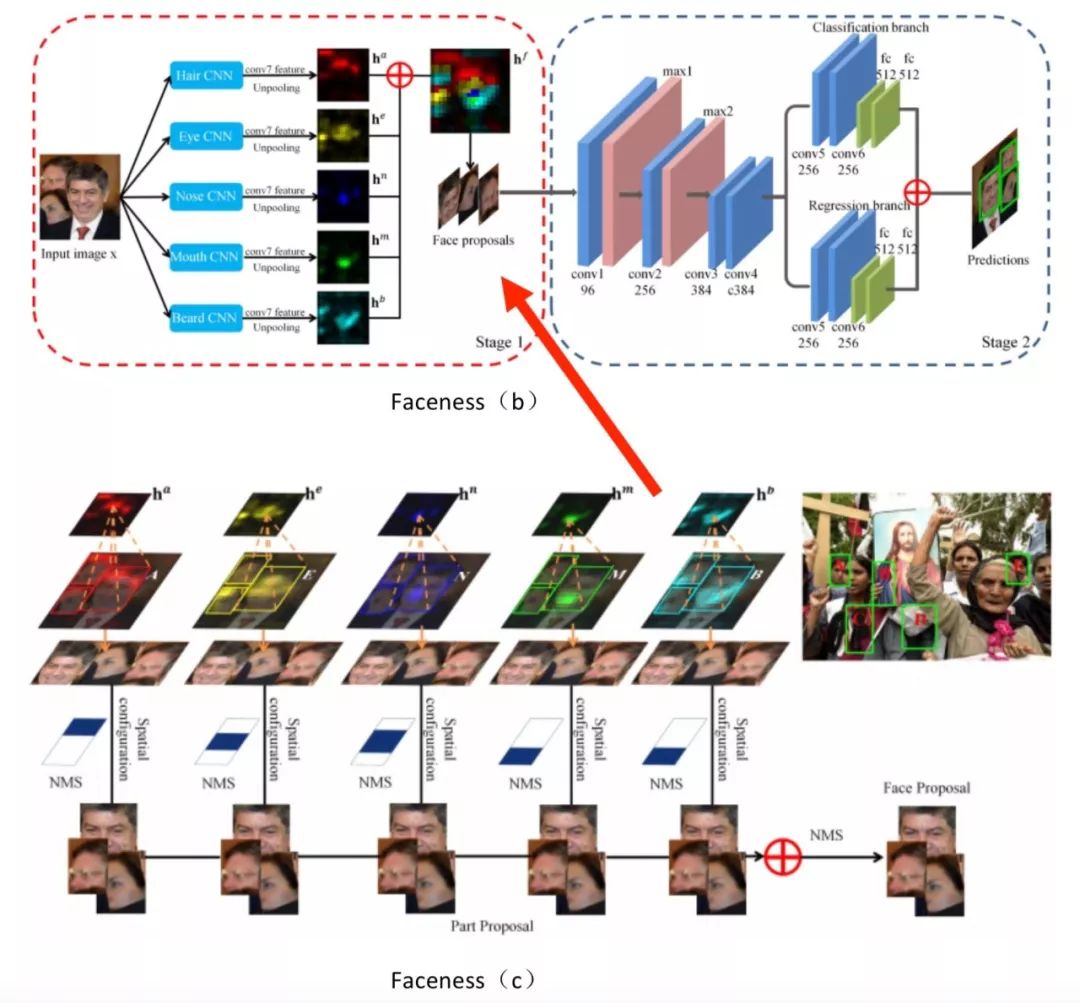
Faceness(b&c)
系统主要包含了2个阶段:
第1阶段:
生成partness map,由局部推理出人脸候选区域。
根据attribute-aware深度网络生成人脸部件map图(partness map),如上图Faceness(a)中的颜色图,文章共使用了5个部件:hair,eye,nose,mouth,beard. 通过part的结合计算人脸的score.部件与部件之间是有相对位置关系的,比如头发在眼睛上方,嘴巴在鼻子下方,因此利用部件的spatial arrangement可以计算face likeliness. 通过这个打分对原始的人脸proposal进行重排序. 如图Faceness(b)。
第2阶段:
Refining the face hypotheses。
上一阶段proposal生成的候选框已经有较高的召回率,通过训练一个人脸分类和边界回归的CNN可以进一步提升其效果。
Faceness的整体性能在当时看来非常令人兴奋。此前学术界在FDDB上取得的最好检测精度是在100个误检时达到84%的检测率,Faceness在100个误检时,检测率接近88%,提升了几乎4个百分点;除了算法本身的精度有很大提升,作者还做了很多工程上的优化比如:通过多个网络共享参数,降低网络参数量 83%;采用多任务的训练方式同一网络实现不同任务等。
-
MTCNN
MTCNN[20]顾名思义是多任务的一个方法,它将人脸区域检测和人脸关键点检测放在了一起,同Cascade CNN一样也是基于cascade的框架,但是整体思路更加巧妙合理,MTCNN总体来说分为三个部分:PNet、RNet和ONet,如下图所示:
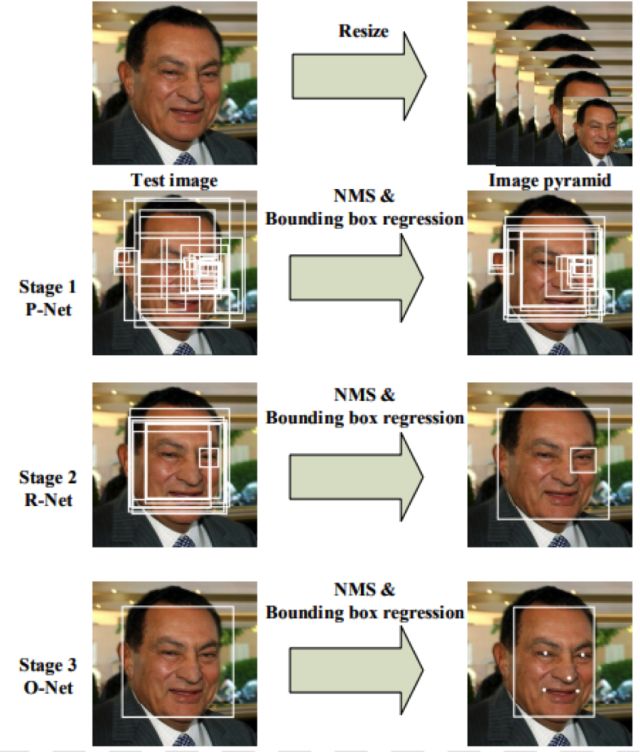
Cascade CNN第一级的12-net需要在整张图片上做密集窗口采样进行分类,缺陷非常明显;MTCNN在测试第一阶段的PNet是全卷积网络(FCN),全卷积网络的优点在于可以输入任意尺寸的图像,同时使用卷积运算代替了滑动窗口运算,大幅提高了效率。下图为不同尺度图像经过PNet的密集分类响应图,亮度越高代表该区域是人脸的概率越大(dense prediction response map)。
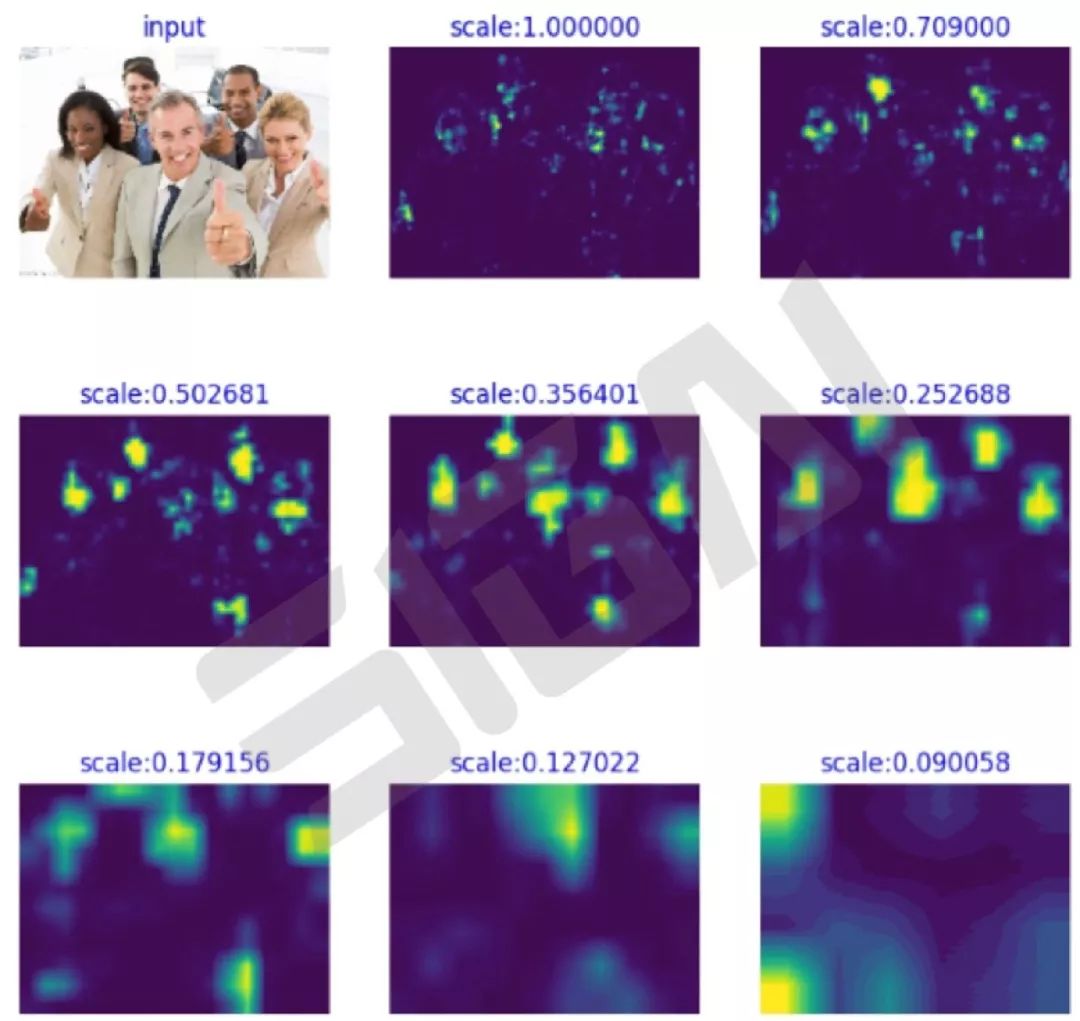
除了增加人脸5个关键点的回归任务,另外在calibration阶段采用了直接回归真实位置坐标的偏移量的思路替代了Cascade CNN中的固定模式分类方式,整个思路更为合理。
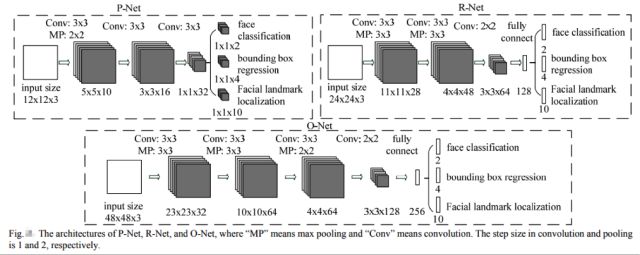
MTCNN的整体设计思路很好,将人脸检测和人脸对齐集成到了一个框架中实现,另外整体的复杂度得到了很好的控制,可以在中端手机上跑20~30FPS。该方法目前在很多工业级场景中得到了应用。
先抛出一张据说是目前世界上人数最多的合照吓吓大家。一眼望过去能估计下有多少人吗?因为本文对小目标人脸检测有很多独到的理解,我们下面会多花点笔墨去分析!

-
HR
之前我们讲过的一些方法都没有针对小目标去分析,小目标检测依然是检测领域的一个难题,[21]本文作者提出的检测器通过利用尺度,分辨率和上下文多种信息融合来检测小目标,在上图的总共1000个人脸中成功检测到约800个,检测器的置信度由右侧的色标表示。
针对小目标人脸检测,作者主要从三个方面做了研究:尺度不变,图像分辨率和上下文,作者的算法在FDDB和WIDERFace取得了当时最好的效果。
作者分析了小目标人脸检测的三个问题:
问题1:
Multi-task modeling of scales
一方面,我们想要一个可以检测小人脸的小模板;另一方面,我们想要一个可以利用详细特征(即面部)的大模板来提高准确性。取代“一刀切”的方法,作者针对不同的尺度(和纵横比)分别训练了检测器。虽然这样的策略提升了大目标检测的准确率,但是检测小目标仍然具有挑战性。
问题2:
How to generalize pre-trained networks?
关于小目标检测的问题,作者提出了两个见解。
如何从预训练的深度网络中最佳地提取尺度不变的特征。
虽然许多应用于“多分辨率”的识别系统都是处理一个图像金字塔,但我们发现在插值金字塔的最底层对于检测小目标尤为重要。
因此,作者的最终方法是:通过尺度不变方式,来处理图像金字塔以捕获大规模变化,并采用特定尺度混合检测器,如下图:

(a)单一尺度模板和图像金字塔
(b)不同尺度模板和单一图像
(c)粗略尺度模板和粗略图像金字塔,(a)和(b)的结合
(d)含有上下文信息的固定大小多尺度模板和粗略图像金字塔
(e)定义了从深度模型的多个层中提取的特征模板,也就是foveal descriptors
问题3:
How best to encode context?
作者证明从多个层中提取的卷积深度特征(也称为 “hypercolumn” features)是有效的“ foveal”描述符,其能捕获大感受野上的高分辨率细节和粗略的低分辨率线索。
从输入图像开始,首先创建一个图像金字塔(2x插值)。然后我们将缩放的输入图像输入到CNN中,获得不同分辨率下人脸预测响应图(后续用于检测和回归)。最后将在不同尺度上得到的候选区域映射回原始分辨率图像上,应用非极大值抑制(NMS)来获得最终检测结果。
-
Face R-CNN
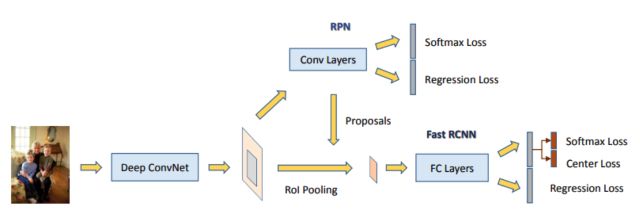
[22]该方法基于Faster R-CNN框架做人脸检测,针对人脸检测的特殊性做了优化。
对于最后的二分类,在softmax的基础上增加了center loss。通过加入center loss使得类内的特征差异更小(起到聚类的作用),提高正负样本在特征空间的差异性从而提升分类器的性能。
加入在线困难样本挖掘(OHEM),每次从正负样本中各选出loss最大的N个样本加入下次训练,提高对困难样本的的分类能力。
多尺度训练,为了适应不同尺度影响(或者更好地检测小目标),训练阶段图片会经过不同尺度缩放。
-
SSH
[23] SSH最大的特色就是尺度不相关性(scale-invariant),比如MTCNN这样的方法在预测的时候,是对不同尺度的图片分别进行预测,而SSH只需要处以一个尺度的图片就可以搞定。实现方式就是对VGG网络不同level的卷积层输出做了3个分支(M1,M2,M3),每个分支都使用类似的流程进行检测和分类,通过针对不同尺度特征图进行分析,变相的实现了多尺度的人脸检测。
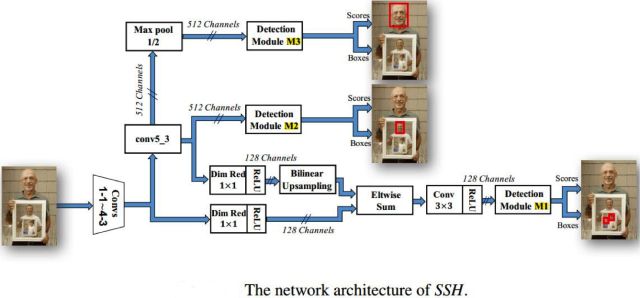
M1和M2,M3区别有点大,首先,M1的通道数为128,M2,M3的通道数为512,这里,作者使用了1*1卷积核进行了降维操作。其次,将conv4_3卷积层输出和conv5_3卷积层输出的特征进行了融合(elementwise sum),由于conv5_3卷积层输出的大小和conv4_3卷积层输出的大小不一样,作者对conv5_3卷积层的输出做了双线性插值进行上采样。
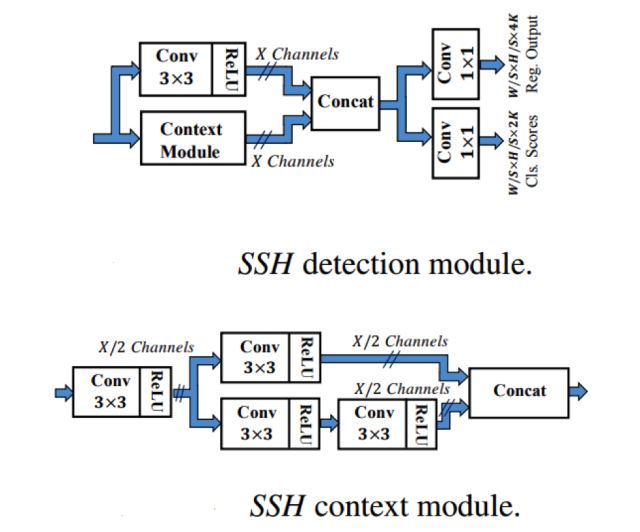
其中,M模块如上图所示,包含了分类和回归2个任务,其中Context Module的为了获得更多的上下文信息,更大的感受野,对该模块使用了等价的5*5和7*7的卷积分别进行操作,然后进行特征的concat最终形成了上图的Context Module。(由于大的卷积核效率问题,根据INCEPTION的思想,使用2个3*3的卷积核替代一个5*5的卷积核,使用3个3*3的卷积核替换1个7*7的卷积核)。
-
PyramidBox
这张图又出现了!!!这一次是百度的“PyramidBox”[24]跑出来的结果。880个人脸!!!

PyramidBox从论文看主要是已有技术的组合应用,但是作者对不同技术有自己很好的理解,所以能组合的很有效,把性能刷的非常高。
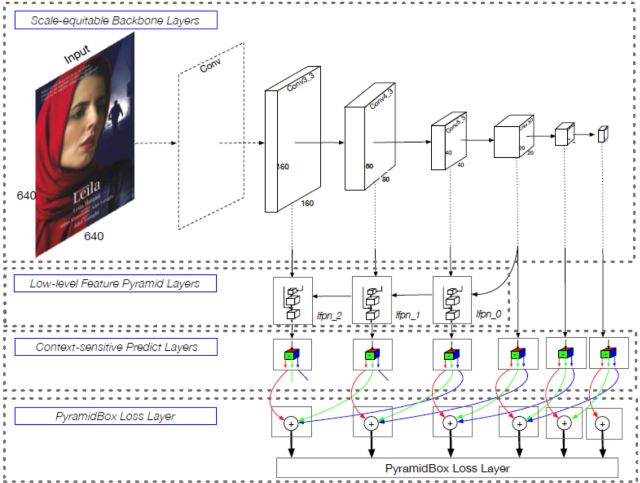
Architecture of PyramidBox
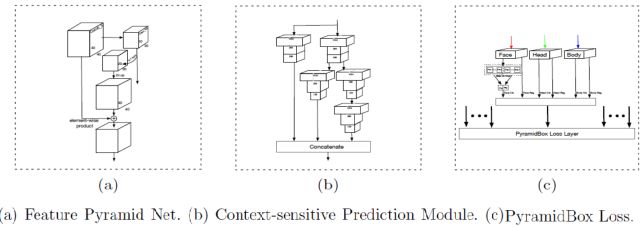
针对之前方法对上下文信息的利用不够充分的问题,作者提出了自己的优化方案:
第一
点
:
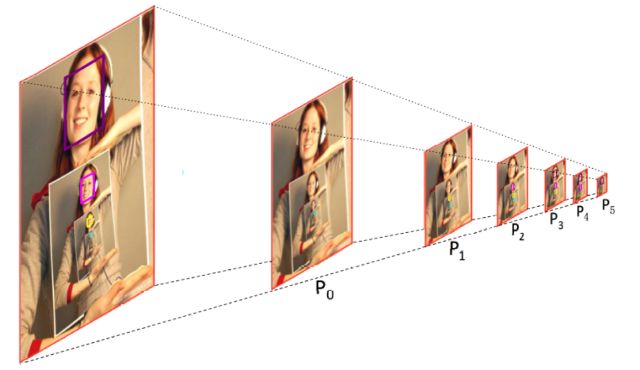
提出了一种基于 anchor 的上下文信息辅助方法PyramidAnchors,从而可以引入监督信息来学习较小的、模糊的和部分遮挡的人脸的上下文特征(下图中紫色的人脸框为例可以看到P3,P4,P5的层中框选的区域分别对应face、head、body)。
第二
点
:
设计了低层特征金字塔网络 ( Low-level Feature Pyramid Networks ) 来更好地融合上下文特征和面部特征,该方法在一次前向过程中(in a single shot)可以很好地处理不同尺度的人脸。
第三点:
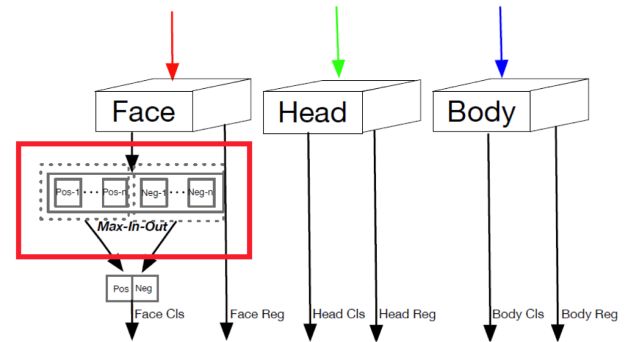
文中提出了一种上下文敏感的预测模块,该模块由一个混合网络结构和max-in-out层组成,该模块可以从融合特征中学习到更准确的定位信息和分类信息(文中对正样本和负样本都采用了该策略,针对不同层级的预测模块为了提高召回率对正负样本设置了不同的参数)。max-in-out参考的maxout激活函数来自GAN模型发明人Ian J,Goodfellow,它对上一层的多个feature map跨通道取最大值作为输出,在cifar10和cifar100上相较于ReLU取得了更好的效果。
第四点:
文中提出了尺度敏感的Data-anchor-采样策略,改变训练样本的分布,重点关注了较小的人脸。
结束语
人脸做为计算机视觉的一个大的研究方向,很多科研人员在上面投入了大量精力,每年出来上百篇相关论文,本文中不一一列举,文中讲述分析如有不妥之处请多包涵指正!
参考文献
[1] Henry A Rowley, Shumeet Baluja, Takeo Kanade. Neural network-based face detection. 1998, IEEE Transactions on Pattern Analysis and Machine Intelligence.
[2] Henry A Rowley, Shumeet Baluja, Takeo Kanade. Rotation invariant neural network-based face detection. 1998, computer vision and pattern recognition.
[3] P.Viola and M.Jones. Rapid object detection using a boosted cascade of simple features. In Proceedings IEEE Conf. on Computer Vision and Pattern Recognition, 2001
[4] Rainer Lienhart, Jochen Maydt. An extended set of Haar-like features for rapid object detection. 2002, international conference on image processing.
[5] Lubomir Bourdev, Jonathan Brandt. Robust Object Detection Via Soft Cascade. CVPR 2005.
[6] Bo Wu, Haizhou Ai, Chang Huang, Shihong Lao. Fast rotation invariant multi-view face detection based on real Adaboost. 2004, IEEE international conference on automatic face and gesture recognition.
[7] M.Jones, P.Viola. Fast Multi-View Face Detection. Mitsubishi Electric Research Laboratories, Technical Report: MERL-2003-96, July 2003.
[8] Y.Ma, X.Q.Ding. Real-time rotation invariant face detection based on cost-sensitive AdaBoost. In: Proceedings of the IEEE International Conference on Image Processing. Barcelona, Spain: IEEE Computer Society, 2003. 921-924.
[9] Y.Ma, X.Q.Ding. Robust multi-view face detection and pose estimation based on cost-sensitive AdaBoost. In: Proceedings of the 6-th Asian Conference on Computer Vision. Jeju, Korea: Springer, 2004.
[10] S.Z.Li, L.Zhu, Z.Q.Zhang, A.Blake, H.J.Zhang, H.Y.Shum. Statistical learning of multi-view face detection. In: Proceedings of the 7-th European Conference on Computer Vision. Copenhagen, Denmark: Springer, 2002.67-81.
[11] S.Z.Li, Z.Q.Zhang, H.Y.Shum, H.J.Zhang. FloatBoost learning for classification. In: Proceedings of the 16-th Annual Conference on Neural Information Processing Systems. Vancouver, Canada: MIT Press, 2002. 993-1000.
[12] S.Z.Li, L.Zhu, Z.Q.Zhang, H.J.Zhang. Learning to detect multi-view faces in real-time. In: Proceedings of the 2-nd International Conference on Development and Learning. Cambridge, MA, USA: IEEE Computer Society, 2002. 172-177.
[13] S.Z.Li, Z.Q.Zhang. FloatBoost Learning and Statistical Face Detection. In: IEEE Transactions on Pattern Analysis and Machine Intelligence, 2004.
[14] B.Wu, H.Z.Ai, C.Huang, S.H.Lao. Fast rotation invariant multi-view face detection based on real adaboost. In: Proc. 6th Int’l Conf. Automatic Face and Gesture Recognition, 2004, 79-84.
[15] B. Yang, J. Yan, Z. Lei and S. Z. Li. Aggregate channel features for multi-view face detection.. International Joint Conference on Biometrics, 2014.
[16] M. Mathias, R. Benenson, M. Pedersoli and L. Van Gool. Face detection without bells and whistles. ECCV 2014.
[17] Haoxiang Li, Zhe Lin, Xiaohui Shen, Jonathan Brandt, Gang Hua. A convolutional neural network cascade for face detection. 2015, computer vision and pattern recognition
[18] Lichao Huang, Yi Yang, Yafeng Deng, Yinan Yu. DenseBox: Unifying Landmark Localization with End to End Object Detection. 2015, arXiv: Computer Vision and Pattern Recognition
[19] Shuo Yang, Ping Luo, Chen Change Loy, Xiaoou Tang. Faceness-Net: Face Detection through Deep Facial Part Responses.
[20] Kaipeng Zhan, Zhanpeng Zhang, Zhifeng L, Yu Qiao. Joint Face Detection and Alignment Using Multitask Cascaded Convolutional Networks. 2016, IEEE Signal Processing Letters.
[21] HR – P. Hu, D. Ramanan. Finding Tiny Faces. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
[22] Face R-CNN – H. Wang, Z. Li, X. Ji, Y. Wang. Face R-CNN. arXiv preprint arXiv:1706.01061, 2017.
[23] SSH – M. Najibi, P. Samangouei, R. Chellappa, L. Davis. SSH: Single Stage Headless Face Detector. IEEE International Conference on Computer Vision (ICCV), 2017.
[24] PyramidBox – X. Tang, Daniel K. Du, Z. He, J. Liu PyramidBox: A Context-assisted Single Shot Face Detector. arXiv preprint arXiv:1803.07737, 2018.
授权声明
本图文海报所采用图片经THE YIAN STUDIO授权。
