一。impala架构
Impala是Cloudera在受到Google的Dremel启发下开发的实时交互SQL大数据查询工具,Impala没有再使用缓慢的Hive+MapReduce批处理,而是通过使用与商用并行关系数据库中类似的分布式查询引擎(由Query Planner、Query Coordinator和Query Exec Engine三部分组成),可以直接从HDFS或HBase中用SELECT、JOIN和统计函数查询数据,从而大大降低了延迟。
impala架构图:
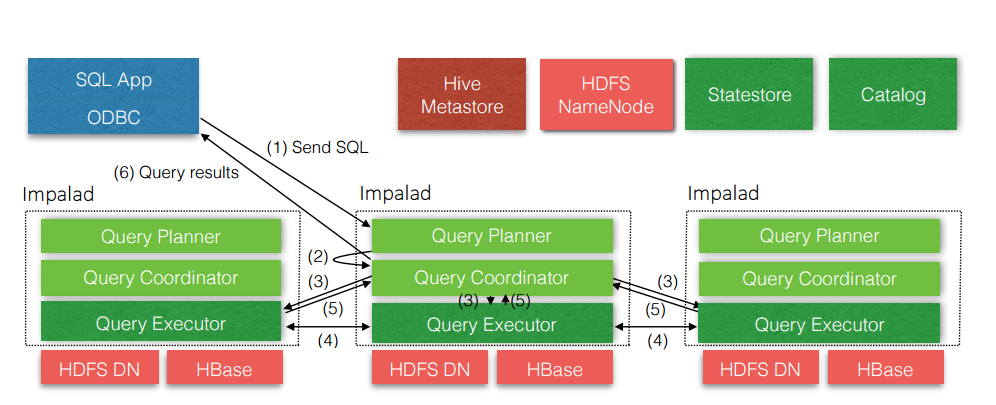
Impala由三个服务组成:impalad, statestored, catalogd。
-
Impalad
: 与DataNode运行在同一节点上,由Impalad进程表示,一个datanode对应一个impalad,它接收客户端的查询请求(接收查询请求的Impalad为Coordinator,Coordinator通过JNI调用java前端解释SQL查询语句,生成查询计划树,再通过调度器把执行计划分发给具有相应数据的其它Impalad进行执行),读写数据,并行执行查询,并把结果通过网络流式的传送回给Coordinator,由Coordinator返回给客户端。同时Impalad也与State Store保持连接,用于确定哪个Impalad是健康和可以接受新的工作。在Impalad中启动三个ThriftServer: beeswax_server(连接客户端),hs2_server(借用Hive元数据), be_server(Impalad内部使用)和一个ImpalaServer服务。
-
Impala State Store
: 跟踪集群中的Impalad的健康状态及位置信息,由statestored进程表示,它通过创建多个线程来处理Impalad的注册订阅和与各Impalad保持心跳连接,各Impalad都会缓存一份State Store中的信息,当State Store离线后(Impalad发现State Store处于离线时,会进入recovery模式,反复注册,当State Store重新加入集群后,自动恢复正常,更新缓存数据)因为Impalad有State Store的缓存仍然可以工作,但会因为有些Impalad失效了,而已缓存数据无法更新,导致把执行计划分配给了失效的Impalad,导致查询失败。
-
Catalogd
作为metadata访问网关,从Hive Metastore等外部catalog中获取元数据信息,放到impala自己的catalog结构中。impalad执行ddl命令时通过catalogd由其代为执行,该更新则由statestored广播。
-
CLI:
提供给用户查询使用的命令行工具(Impala Shell使用python实现),同时Impala还提供了Hue,JDBC, ODBC使用接口。
执行计划:
Impala: 通过词法分析生成执行计划,执行计划表现为一棵完整的执行计划树,可以更自然地分发执行计划到各个Impalad执行查询,在分发执行计划后,Impala使用拉式获取数据的方式获取结果,把结果数据组成按执行树流式传递汇集,减少的了把中间结果写入磁盘的步骤,再从磁盘读取数据的开销。
impala的前端负责将sql转化成执行计划(java),包含两个阶段:单节点计划生成、并行化和分段。第一阶段对sql进行解析、分析、优化(RBO和CBO,统计信息目前只有表大小和列的NDV,无histogram),第二阶段生成分布式的执行计划,确定是否要加exchange节点(是否存在partitioned join或hash aggregation),选择join strategy(partitioned join or broadcast join)等,最后以exchange为边界将计划分段(fragment),作为impala的基本运行单元。
impala相对于hive优缺点:
优点:
- 支持SQL查询,快速查询大数据。
- 可以对已有数据进行查询,减少数据的加载,转换。
- 多种存储格式可以选择(Parquet, Text, Avro, RCFile, SequeenceFile)。
- 可以与Hive配合使用。
缺点:
- 不支持用户定义函数UDF。
- 不支持text域的全文搜索。
- 不支持Transforms。
- 不支持查询期的容错。
- 对内存要求高。
官网 :http://impala.apache.org/overview.html
二。impala 安装
使用cdh安装 参考之前环境(https://blog.csdn.net/liaomin416100569/article/details/80045833) 确保安装之前 先
安装了hadoop和hive
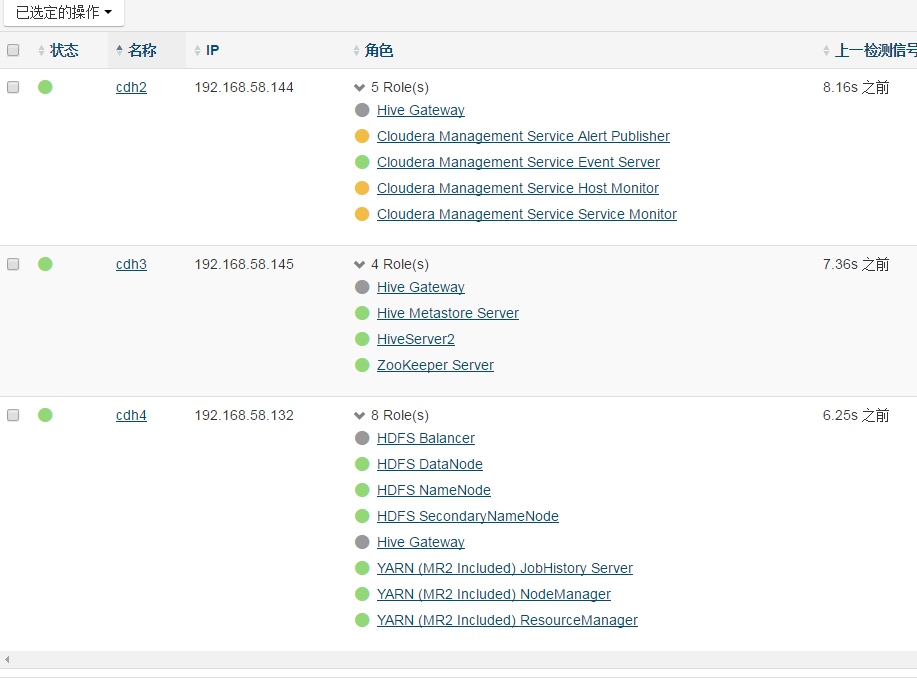
cdh集群 添加服务
因为之前hadoop位于cdh4(单机版)
hive 安装于 cdh3(单机)
catalogserver和statestore安装在 cdh3
impala daemon 必须安装数据节点cdh4上
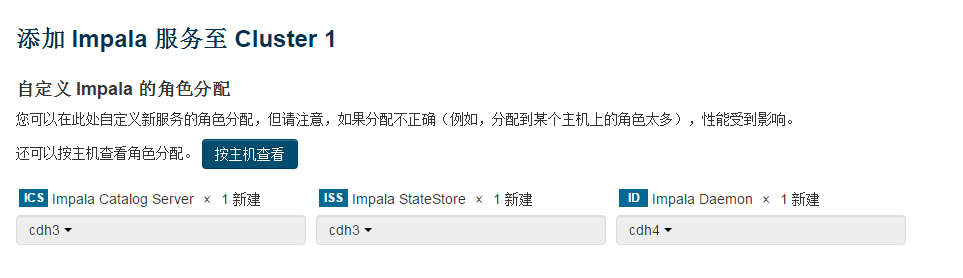
安装完成 安装路径时/opt/cloudera/parcels/CDH/lib/impala
注意一般如果出错 可以 查看 /var/log对应目录的日志信息
服务 启动impala
三。impala shell和sql
在任意的cdh节点上 运行命令 impala-shell 即可操作impala 只有 cdh4上有impalad进程 他可以直接登录 其他机器
[root@cdh2 impala]# impala-shell -i cdh4
Starting Impala Shell without Kerberos authentication
Connected to cdh4:21000
Server version: impalad version 2.5.0-cdh5.7.6 RELEASE (build ecbba4f4e6d5eec6c33c1e02412621b8b9c71b6a)
***********************************************************************************
Welcome to the Impala shell. Copyright (c) 2015 Cloudera, Inc. All rights reserved.
(Impala Shell v2.5.0-cdh5.7.6 (ecbba4f) built on Tue Feb 21 14:54:50 PST 2017)
After running a query, type SUMMARY to see a summary of where time was spent.
***********************************************************************************
[cdh4:21000] > 该命令的一些可选项 解释
root@cdh4 ~]# impala-shell --help
Usage: impala_shell.py [options]
Options:
-i IMPALAD, --impalad=IMPALAD
<host:port> 连接到对应的impalad的服务器
[默认是: cdh4:21000]
-q QUERY, --query=QUERY
直接可以在命令行执行一个查询的sql语句
-f QUERY_FILE, --query_file=QUERY_FILE
执行查询文件的查询sql语句, 多条使用 ; 隔开
[default: none]
-o OUTPUT_FILE, --output_file=OUTPUT_FILE
设置将查询结构输出到文件中
--print_header 查询时是否打印表头 [default: False]
--output_delimiter=OUTPUT_DELIMITER
输出内容的行的列的分隔符 默认是\t
[default: \t]
-r, --refresh_after_connect
连接之后刷新 Impala catalog 自动从hive的metastore同步数据库及表结构信息等元数据
[default: False]
-d DEFAULT_DB, --database=DEFAULT_DB
指定默认使用的数据库名称 等价于 use 数据库名
[default: none]
-u USER, --user=USER 授权登录的用[default: root]
进入命令内部后 可以使用的常用命令 如下:
connect
ip:端口 连接到其他的impalad进程
invalidate metadata
从hive中同步元数据
refresh
表名 同步指定表的元数据 尽量使用 这个而不要用invalidate metadata
其他命令同mysql
SQL语句(基本等同hive 参考地址http://impala.apache.org/docs/build/html/topics/impala_langref.html)
1 。创建数据库(http://impala.apache.org/docs/build/html/topics/impala_create_database.html#create_database)
[cdh4:21000] > create database myimpala;
Query: create database myimpala 默认使用hive创建 目录位于hive的 /user/hive/warehouse下 查看
[root@cdh4 ~]# hdfs dfs -ls /user/hive/warehouse
Found 1 items
drwxrwxrwt - impala hive 0 2018-04-24 16:54 /user/hive/warehouse/myimpala.db
2。表操作(http://impala.apache.org/docs/build/html/topics/impala_tables.html)
内表表示元数据和文件数据被
hive
内部经常管理 删除内表数据 所有数据都会被删除 默认表都是内表
外表
表示文件数据被外部管理
删除外表
外表数据不会被删除
比如多个表引用同一份数据时
适用于使用外表
创建表语法(支持类型,支持row分割格式,支持文件存储格式等) 参考:
http://impala.apache.org/docs/build/html/topics/impala_create_table.html#create_table
支持文件格式
几种压缩方式对比
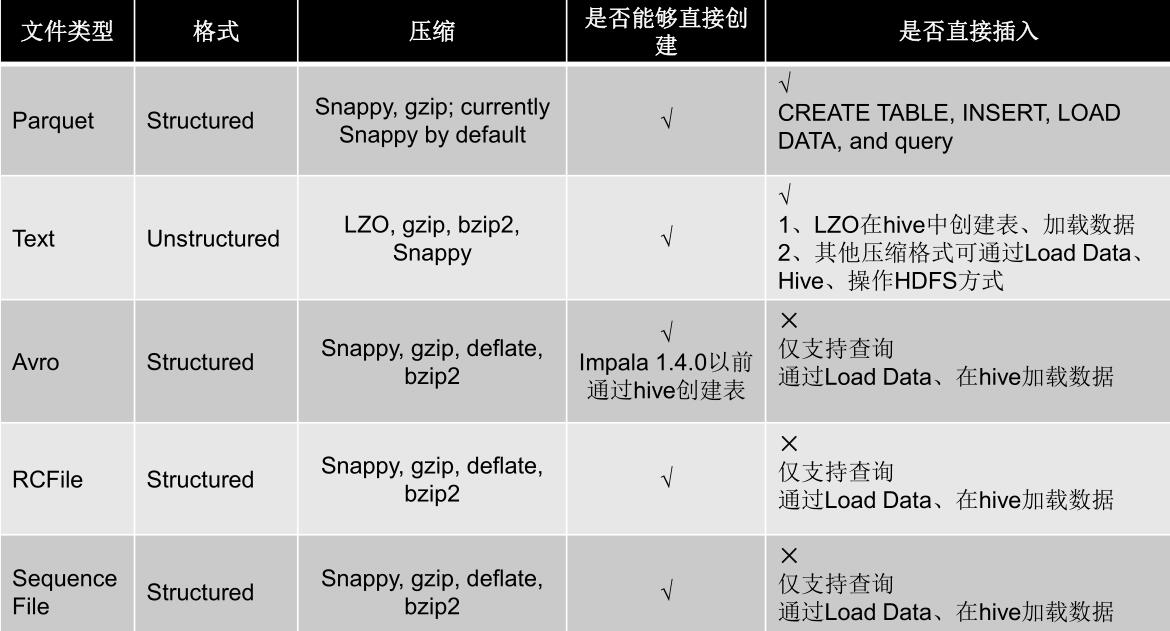

这里演示简单例子 同hive一样
创建表
CREATE TABLE page_view(
viewTime INT,
userid BIGINT,
page_url STRING,
referrer_url STRING,
ip STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE; /soft目录下 a.txt 内容
[root@cdh4 soft]# more a.txt
2015-12-13 11:56:20,1,www.baidu.com,www.qq.com,192.168.99.0
2015-12-13 10:56:20,1,www.baidu.com,www.qq.com,192.168.99.1
2015-12-13 9:56:20,1,www.baidu.com,www.qq.com,192.168.99.2
2015-12-13 11:56:20,1,www.baidu.com,www.qq.com,192.168.99.3
2015-12-13 44:56:20,1,www.baidu.com,www.qq.com,192.168.99.4 将文件传送到hdfs上
hdfs dfs -mkdir /im
hdfs dfs -put -f a.txt /im
执行load时报错
[cdh4:21000] > LOAD DATA INPATH '/im/a.txt' INTO TABLE page_view ;
Query: load DATA INPATH '/a.txt' INTO TABLE page_view
ERROR: AnalysisException: Unable to LOAD DATA from hdfs://cdh4:8020/a.txt because Impala does not have WRITE permissions on its parent directory hdfs://cdh4:8020/ 因为Impala使用impala用户操作hdfs 所以没有权限 (hadoop操作用户是使用 hdfs 通过 hdfs dfs -ls / 查看)
系统使用hdfs超级用户登录修改/im目录的拥有者是 impala
[root@cdh4 soft]# hadoop fs -chown -R impala:supergroup /im
chown: changing ownership of '/im': Non-super user cannot change owner
[root@cdh4 soft]# su - hdfs
[hdfs@cdh4 ~]$ hadoop fs -chown -R impala:supergroup /im 再次尝试shell导入 查看数据
[cdh4:21000] > select * from page_view;
Query: select * from page_view
+----------+--------+---------------+--------------+--------------+
| viewtime | userid | page_url | referrer_url | ip |
+----------+--------+---------------+--------------+--------------+
| NULL | 1 | www.baidu.com | www.qq.com | 192.168.99.0 |
| NULL | 1 | www.baidu.com | www.qq.com | 192.168.99.1 |
| NULL | 1 | www.baidu.com | www.qq.com | 192.168.99.2 |
| NULL | 1 | www.baidu.com | www.qq.com | 192.168.99.3 |
| NULL | 1 | www.baidu.com | www.qq.com | 192.168.99.4 |
+----------+--------+---------------+--------------+--------------+
WARNINGS: Error converting column: 0 TO INT (Data is: 2015-12-13 11:56:20)
file: hdfs://cdh4:8020/user/hive/warehouse/myimpala.db/page_view/a.txt
record: 2015-12-13 11:56:20,1,www.baidu.com,www.qq.com,192.168.99.0
Error converting column: 0 TO INT (Data is: 2015-12-13 10:56:20)
file: hdfs://cdh4:8020/user/hive/warehouse/myimpala.db/page_view/a.txt
record: 2015-12-13 10:56:20,1,www.baidu.com,www.qq.com,192.168.99.1
Error converting column: 0 TO INT (Data is: 2015-12-13 9:56:20)
file: hdfs://cdh4:8020/user/hive/warehouse/myimpala.db/page_view/a.txt
record: 2015-12-13 9:56:20,1,www.baidu.com,www.qq.com,192.168.99.2
Error converting column: 0 TO INT (Data is: 2015-12-13 11:56:20)
file: hdfs://cdh4:8020/user/hive/warehouse/myimpala.db/page_view/a.txt
record: 2015-12-13 11:56:20,1,www.baidu.com,www.qq.com,192.168.99.3
Error converting column: 0 TO INT (Data is: 2015-12-13 44:56:20)
file: hdfs://cdh4:8020/user/hive/warehouse/myimpala.db/page_view/a.txt
record: 2015-12-13 44:56:20,1,www.baidu.com,www.qq.com,192.168.99.4
Fetched 5 row(s) in 1.37s viewtime 定义成了int类型 所有无法导入 修改表
alter table page_view change viewTime viewTime STRING再次查看
[cdh4:21000] > select * from page_view;
Query: select * from page_view
+---------------------+--------+---------------+--------------+--------------+
| viewtime | userid | page_url | referrer_url | ip |
+---------------------+--------+---------------+--------------+--------------+
| 2015-12-13 11:56:20 | 1 | www.baidu.com | www.qq.com | 192.168.99.0 |
| 2015-12-13 10:56:20 | 1 | www.baidu.com | www.qq.com | 192.168.99.1 |
| 2015-12-13 9:56:20 | 1 | www.baidu.com | www.qq.com | 192.168.99.2 |
| 2015-12-13 11:56:20 | 1 | www.baidu.com | www.qq.com | 192.168.99.3 |
| 2015-12-13 44:56:20 | 1 | www.baidu.com | www.qq.com | 192.168.99.4 |
+---------------------+--------+---------------+--------------+--------------+
Fetched 5 row(s) in 1.40s
3。表分区(http://impala.apache.org/docs/build/html/topics/impala_tables.html)
还是之前的数据 创建一个parquet格式 并且是分区数据 创建表
CREATE TABLE page_view_parquet(
viewTime STRING,
userid BIGINT,
page_url STRING,
referrer_url STRING,
ip STRING
)
PARTITIONED BY(dt STRING, country STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS PARQUET; 因为我们上传的的文本文件 /im/a,txt是文本文件所以不能直接load data会格式错误 可以直接插入数据 所有分区实例先添加
实际上就是创建一个dt=’2015-12-13’/country=’CHINA’目录 之后数据文件就放在该目录下
alter table page_view_parquet add partition (dt='2015-12-13', country='CHINA'); 插入数据测试
[cdh4:21000] > insert into page_view_parquet partition (dt='2015-12-13', country='CHINA') values('2015-12-13 11:56:20',1,'www.baidu.com','www.baidu.com','192.168.7.7');
Query: insert into page_view_parquet partition (dt='2015-12-13', country='CHINA') values('2015-12-13 11:56:20',1,'www.baidu.com','www.baidu.com','192.168.7.7')
Inserted 1 row(s) in 0.80s
[cdh4:21000] > select * from page_view_parquet;
Query: select * from page_view_parquet
+---------------------+--------+---------------+---------------+-------------+------------+---------+
| viewtime | userid | page_url | referrer_url | ip | dt | country |
+---------------------+--------+---------------+---------------+-------------+------------+---------+
| 2015-12-13 11:56:20 | 1 | www.baidu.com | www.baidu.com | 192.168.7.7 | 2015-12-13 | CHINA |
+---------------------+--------+---------------+---------------+-------------+------------+---------+
Fetched 1 row(s) in 0.15s 将之前page_view数据转换到page_view_parquet表 从 TEXTFILE格式转换成 PARQUET
注意定义了分区就要指定分区 insert into是插入追加 insert OVERWRITE是覆盖
[cdh4:21000] > insert into table page_view_parquet select * from page_view;
Query: insert into table page_view_parquet select * from page_view
ERROR: AnalysisException: Not enough partition columns mentioned in query. Missing columns are: dt, country
[cdh4:21000] > insert into table page_view_parquet partition (dt='2015-12-13', country='CHINA') select * from page_view;
Query: insert into table page_view_parquet partition (dt='2015-12-13', country='CHINA') select * from page_view
Inserted 5 row(s) in 1.49s
[cdh4:21000] > select * from page_view_parquet;
Query: select * from page_view_parquet
+---------------------+--------+---------------+---------------+--------------+------------+---------+
| viewtime | userid | page_url | referrer_url | ip | dt | country |
+---------------------+--------+---------------+---------------+--------------+------------+---------+
| 2015-12-13 11:56:20 | 1 | www.baidu.com | www.baidu.com | 192.168.7.7 | 2015-12-13 | CHINA |
| 2015-12-13 11:56:20 | 1 | www.baidu.com | www.qq.com | 192.168.99.0 | 2015-12-13 | CHINA |
| 2015-12-13 10:56:20 | 1 | www.baidu.com | www.qq.com | 192.168.99.1 | 2015-12-13 | CHINA |
| 2015-12-13 9:56:20 | 1 | www.baidu.com | www.qq.com | 192.168.99.2 | 2015-12-13 | CHINA |
| 2015-12-13 11:56:20 | 1 | www.baidu.com | www.qq.com | 192.168.99.3 | 2015-12-13 | CHINA |
| 2015-12-13 44:56:20 | 1 | www.baidu.com | www.qq.com | 192.168.99.4 | 2015-12-13 | CHINA |
+---------------------+--------+---------------+---------------+--------------+------------+---------+
Fetched 6 row(s) in 0.32s 通过cdh控制台 点击hdfs进入 点击namenode web ui 查看 hdfs具体创建的文件
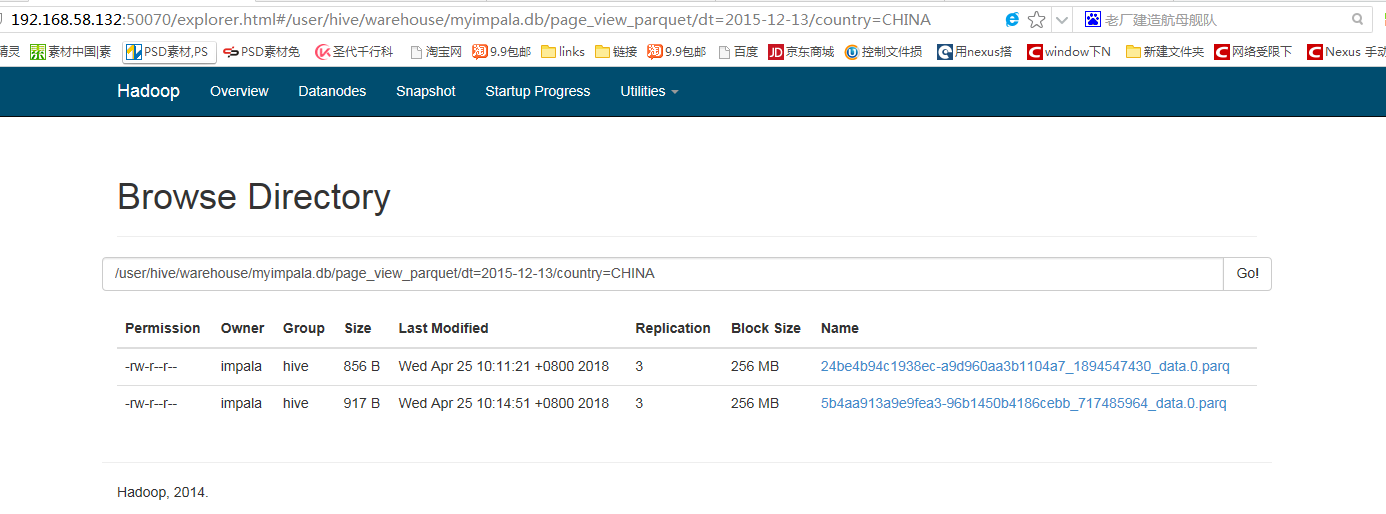
转载于:https://www.cnblogs.com/liaomin416100569/p/9331133.html