这几年,不知道是什么原因,就像当年的团购一样,出现了各种各样的数据库,令人应接不暇。其中有基于传统路线的,以MySQL,Oracle,PG为基础的;有走新理论的,基于Aurora,Spanner等;有面向应用场景的,比如工业数据库,时序,图等。无论是因为国家政策推动自主可控能力的提高,还是随着信息技术的飞速发展。数据库百花齐放的情形,对于我们在数据库领域实力的增强,都是一件利好的事情。
同时,对于刚刚缓过神,逐渐转型的传统企业来说,就显得多少有些茫然了。IOE体系不仅仅承担了绝大部分业务应用,企业或者机构的IT技术能力也形成了定势。对于数据库从业人员来说,更是心惊胆战,一方面是越来越多没有听过的数据库发布;另一方面还有各种自动化,云服务,智能体系的出现。在刚刚过去的几年,面向数据库的运维职位DBA还是供不应求的情况,使得培训行业兴起。而如今,对DBA的要求越来越多,不再是简单的安装部署,监控,备份恢复。而是在选型,架构,优化,自动化等方向有了要求。同样,对于那些加入到这个潮流的数据库厂商来说,眼前是一片蓝海,潜在市场无比巨大;在繁忙的拜访过程中,最后发现成单率出奇的低,到底是哪里不对?国内华为,阿里,腾讯也纷纷推出了数据库全家桶,在这个未知的蓝海中,谁主沉浮?
恰巧,我就是从一个数据库厂商到了一家传统企业的数据库从业者。庆幸的在做DBA时就在不断地思考数据库在自动化,平台化,云化的发展趋势。最近疫情突袭,可以在家静静思考,于是乎,既然看不清未来,就回头看看历史。所以会先简单聊一聊数据库的历史,这一块已经有很多优秀的文章了;再者大胆畅想一下数据库的未来。

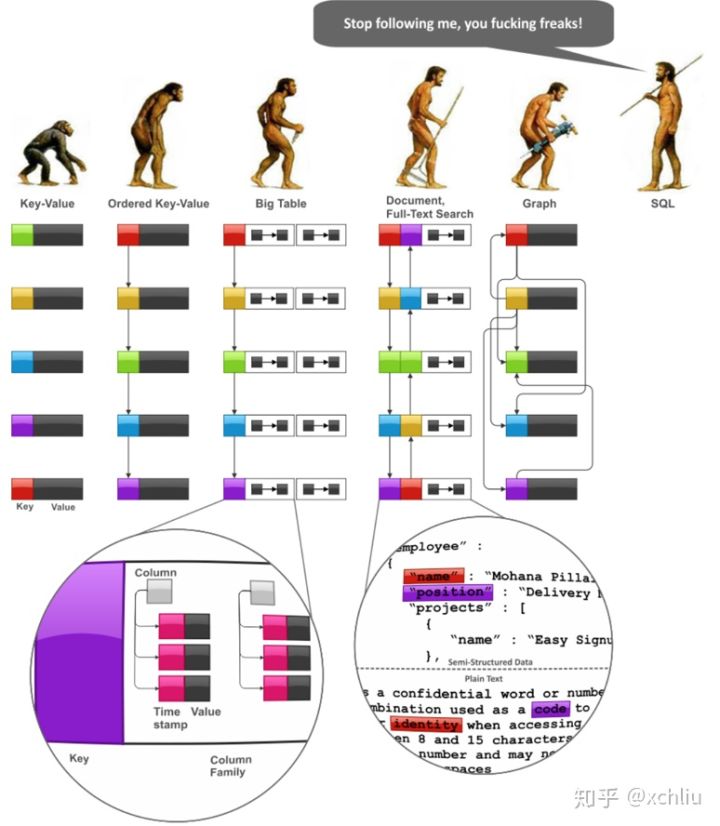
图片来自网络
如上图。数据库已经经历了半个世纪的发展,从概念的提出到早期的数据库,再到流行至今的关系型数据库,可谓是发展迅猛。从这条时间线来看,数据库的发展好像是井然有序的,是什么原因导致了大量的数据库出现,是理论的突破?还是市场的需求?或者两者皆有。
首先,不容置疑的是,数据模型是数据库的核心和理论基础。我们在划分数据库的时候,仍然会按照其基于的数据模型来分类。从一开始的层面模型,网状模型,关系模型,到对象模型,对象关系模型,半结构化等等。对于每一种模型这里就不展开说明了,推荐阅读《What Goes Around Comes Around》,大神的论文把数据库的历代发展成就分析得很透彻。作为鼻祖级人物,Michael Stonebraker 参与了众多数据库的系统设计和实现。
不难发现的是现在百家争鸣的数据库产品中,均是已有的数据模型来作为理论基础。可以肯定是,基础理论没有得到突破,或说有待突破。关系型模型刚提出的一段时间里,学术界发生了CODASYL的有向图模型和关系模型的辩论。有向图的复杂,使得数据库的技术门槛太高,而关系模型扎实的数学理论支撑以及更好的逻辑独立性赢得了市场的认可。从此关系模型一统江湖。到如今,新出的各类数据库,依然是关系模型。从MongoDB,Redis,Hbase,KV一路发展过来,最终在DB-Enginess的统计中,Oracle 带着小弟MySQL还有微软的SQL Server常年一路领跑,后面的追赶者连尾灯都看不到;而且关系模型在分类中仍然占据了很大的比例。概念也从SQL到NOSQL到NEWSQL,到最近的HATP,每一次都有推翻传统数据库的统治,迎接新时代的感觉。
还有一个阵营,是关于技术结合方面的。比如这两年最火的分布式数据库,不夸张的说能把教科书里面的MPP给笑醒。特别是各种光环加持,仿佛是黑暗中的一座灯塔。分布式数据库,并行数据库,多媒体数据库,主动数据库都是数据库技术和某个计算技术结合的产物,类似于嫁接。这类系统的特点就是通过两个技术体系的融合,可以满足特定的市场需求。比如分布式数据库,云计算普及的时候,弹性可伸缩变成了刚需。所以传统数据库不那么优雅分库分表显得不那么云原生。将数据库和分布式系统结合,显然就高大上了。这一点上,亚马逊务实一些,Aurora 基于MySQL做计算存储分离,去掉多余的交互逻辑,充分利用云环境的弹性能力,无论是扩展性还是性能都满足了市场需求。不得不说的是,计算存储分离,又成了家家必备的特性,如果我没理解错的话,DRDB,Oracle的RAC都是可以是计算存储分离吧。小时候,有个同学每天都很早都起来读书,但是他成绩总是倒数,因为他不知道自己在读什么。也许是市场需求误导了技术发展,或者是技术误导了市场需求。技术结合的数据库系统是非常有价值的,在特定市场里面可以发挥很大的作用,当然,他不会是通用型系统。
另一种则是场景结合。比如面向工程,面向地图系统,面向设计类等特定的领域。这一类数据库会对业务场景进行深入理解,分析其中的数据模型,特性,数据流的梳理特点,从而定制形成专属的更符合业务场景的,在性能,交互,事务处理方面更好表现的数据库。这一类数据库依然不是通用的,但是有价值的,还好,数据库网红界目前还有染指这块领域。
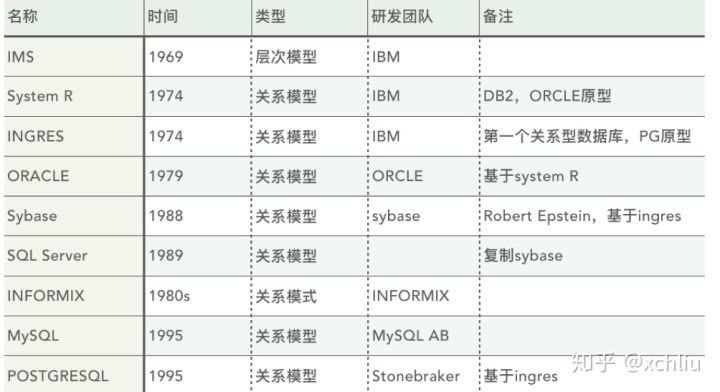
再看看早期的一些数据库,第一波抓住商业机会的,现在依然是行业领先。比如成为众矢之的的Oracle,比如不需要市场推广的SQLServer。而最值得尊重是INGRES,既是第一个关系型数据库原型,对很多数据库都树立了标杆。包括大家都觉得不错,而市场占比不太理想的PG。从这个角度来看,市场对产品的发展壮大起着至关重要的作用。再看看接下里的数据库产品。

这里的图片是某个大学课程里面的图片,所以没有统计到国内的厂商。但是依然已经很多了,没有听过的,见过没用过的,用过没上生产的。显然,这里就终于明白了,并不是忽然出现了一大堆的数据库厂商,就和当年的互联网一样,处于一个爆发期。而最终在这场战役中活下来的,将成为巨头。
那么数据库未来会如何发展?首先不能抛开市场因素,也就是信息系统的对数据的需求;企业对数据库在安全,性能,扩展性,易用性方面的要求;特定场景,业务类型,数据特征对数据库的依赖。这些外部需求会在未来某个时间,对市面上的数据库进行筛选和对比。而在数据库内部,会不会出现产生下一个“关系模型”?,比如XML会不会成为主流模型?数据库的结构定义会不会动态变化甚至取消?我们不用再先建表再写入数据,数据库随着数据的写入动态适配数据类型,动态适配索引,动态适配查询计划?越来越多的算法代码将内置到数据库中,比如对AI算法的支持,比如对搜索算法的支持;主动数据库会不会成为主流,应用程序从查询改为订阅的模式,数据库主动推送数据的变化?。。。。
当数据和代码之间的距离越来越近,应用程序就可以和数据直接对话了。
最后列举一些个人观点:
1.HATP是个需求,不是特性。
2.会产生新的数据模型,来缩短系统之间的信息共享路径。
3.微型数据库市场可能会更大。(已知的是sqlite 安装量全球第一)
4.最终存活下来的厂商,不是因为产品好或则理论先进,而是因为有市场。
附上一张网络图,可谓是色香味俱全。