协方差矩阵在统计学和机器学习中随处可见,一般而言,可视作
方差
和
协方差
两部分组成,即方差构成了对角线上的元素,协方差构成了非对角线上的元素。本文旨在从几何角度介绍我们所熟知的协方差矩阵。
文章结构
- 方差和协方差的定义
- 从方差/协方差到协方差矩阵
- 多元正态分布与线性变换
- 协方差矩阵的特征值分解
1. 方差和协方差的定义
在统计学中,
方差
是用来度量
单个随机变量
的
离散程度
,而协方差则一般用来刻画
两个随机变量
的
相似程度
,其中,
方差
的计算公式为
其中,
表示样本量,符号
表示观测样本的均值,这个定义在初中阶段就已经开始接触了。
在此基础上,
协方差
的计算公式被定义为
在公式中,符号
分别表示两个随机变量所对应的观测样本均值,据此,我们发现:方差
可视作随机变量
关于其自身的协方差
.
2. 从方差/协方差到协方差矩阵
根据方差的定义,给定
个随机变量
,则这些
随机变量的方差
为
其中,为方便书写,
表示随机变量
中的第
个观测样本,
表示样本量,每个随机变量所对应的观测样本数量均为
。
对于这些随机变量,我们还可以根据协方差的定义,求出
两两之间的协方差
,即
因此,
协方差矩阵
为
其中,对角线上的元素为各个随机变量的方差,非对角线上的元素为两两随机变量之间的协方差,根据协方差的定义,我们可以认定:矩阵
为
对称矩阵
(symmetric matrix),其大小为
。
3. 多元正态分布与线性变换
假设一个向量
服从均值向量为
、协方差矩阵为
的多元正态分布(multi-variate Gaussian distribution),则
![[公式]](https://www.zhihu.com/equation?tex=p%5Cleft%28%5Cboldsymbol%7Bx%7D%5Cright%29%3D%5Cleft%7C2%5Cpi%5CSigma%5Cright%7C%5E%7B-1%2F2%7D%5Cexp%5Cleft%28-%5Cfrac%7B1%7D%7B2%7D%5Cleft%28%5Cboldsymbol%7Bx%7D-%5Cboldsymbol%7B%5Cmu%7D%5Cright%29%5ET%5CSigma%5E%7B-1%7D%5Cleft%28%5Cboldsymbol%7Bx%7D-%5Cboldsymbol%7B%5Cmu%7D%5Cright%29%5Cright%29)
令该分布的均值向量为
,由于指数项外面的系数
通常作为常数,故可将多元正态分布简化为
再令
,包含两个随机变量
和
,则协方差矩阵可写成如下形式:
用
单位矩阵
(identity matrix)
作为协方差矩阵,随机变量
和
的
方差均为1
,则生成如干个随机数如图1所示。
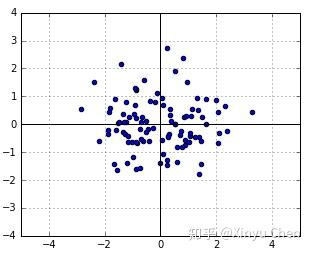
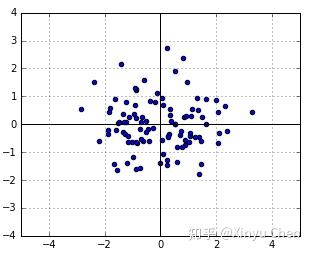
在生成的若干个随机数中,每个点的似然为
对图1中的所有点考虑一个
线性变换
(linear transformation):
,我们能够得到图2.
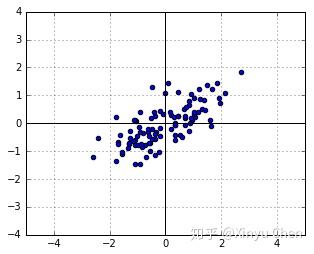
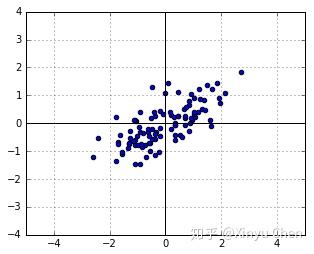
在线性变换中,矩阵
被称为
变换矩阵
(transformation matrix),为了将图1中的点经过线性变换得到我们想要的图2,其实我们需要构造两个矩阵:
-
尺度矩阵
(scaling matrix):
-
旋转矩阵
(rotation matrix)
其中,
为
顺时针旋转的度数
。
变换矩阵、尺度矩阵和旋转矩阵三者的关系式:
![[公式]](https://www.zhihu.com/equation?tex=A%3DRS)
在这个例子中,尺度矩阵为
,旋转矩阵为
,故变换矩阵为
.
另外,需要考虑的是,经过了线性变换,
的分布是什么样子呢
?
将
带入前面给出的似然
,有
由此可以得到,多元正态分布的协方差矩阵为
.
4. 协方差矩阵的特征值分解
回到我们已经学过的线性代数内容,对于任意对称矩阵
,存在一个
特征值分解(eigenvalue decomposition, EVD)
:
其中,
的每一列都是相互正交的特征向量,且是单位向量,满足
,
对角线上的元素是从大到小排列的特征值,非对角线上的元素均为0。
当然,这条公式在这里也可以很容易地写成如下形式:
其中,
,因此,通俗地说,
任意一个协方差矩阵都可以视为线性变换的结果
。
在上面的例子中,
特征向量构成的矩阵
为
.
特征值构成的矩阵
为
.
到这里,我们发现:多元正态分布的概率密度是由
协方差矩阵的特征向量控制旋转(rotation)
,
特征值控制尺度(scale)
,除了协方差矩阵,
均值向量会控制概率密度的位置
,在图1和图2中,均值向量为
,因此,概率密度的中心位于坐标原点。
相关参考:
Understanding the Covariance Matrix

What is the Covariance Matrix?
