1. 背景
curl 是一个非常实用的、用来与服务器之间传输数据的工具。
curl支持的协议很多,包括 DICT, FILE, FTP, FTPS, GOPHER, HTTP, HTTPS, IMAP, IMAPS, LDAP, LDAPS, POP3, POP3S, RTMP, RTSP, SCP, SFTP, SMTP, SMTPS, TELNET and TFTP。curl设计为无用户交互下完成工作。
curl提供了一大堆非常有用的功能,包括代理访问、用户认证、ftp上传下载、HTTP POST、SSL连接、cookie支持、断点续传等等
使用curl的时候掌握一些小技巧可以加速工作速度。这里总结了几个技巧。
2.浏览器提取url至curl
f12- network,选择url右击,选择copy、Copy as cURL,即可复制为curl命令。
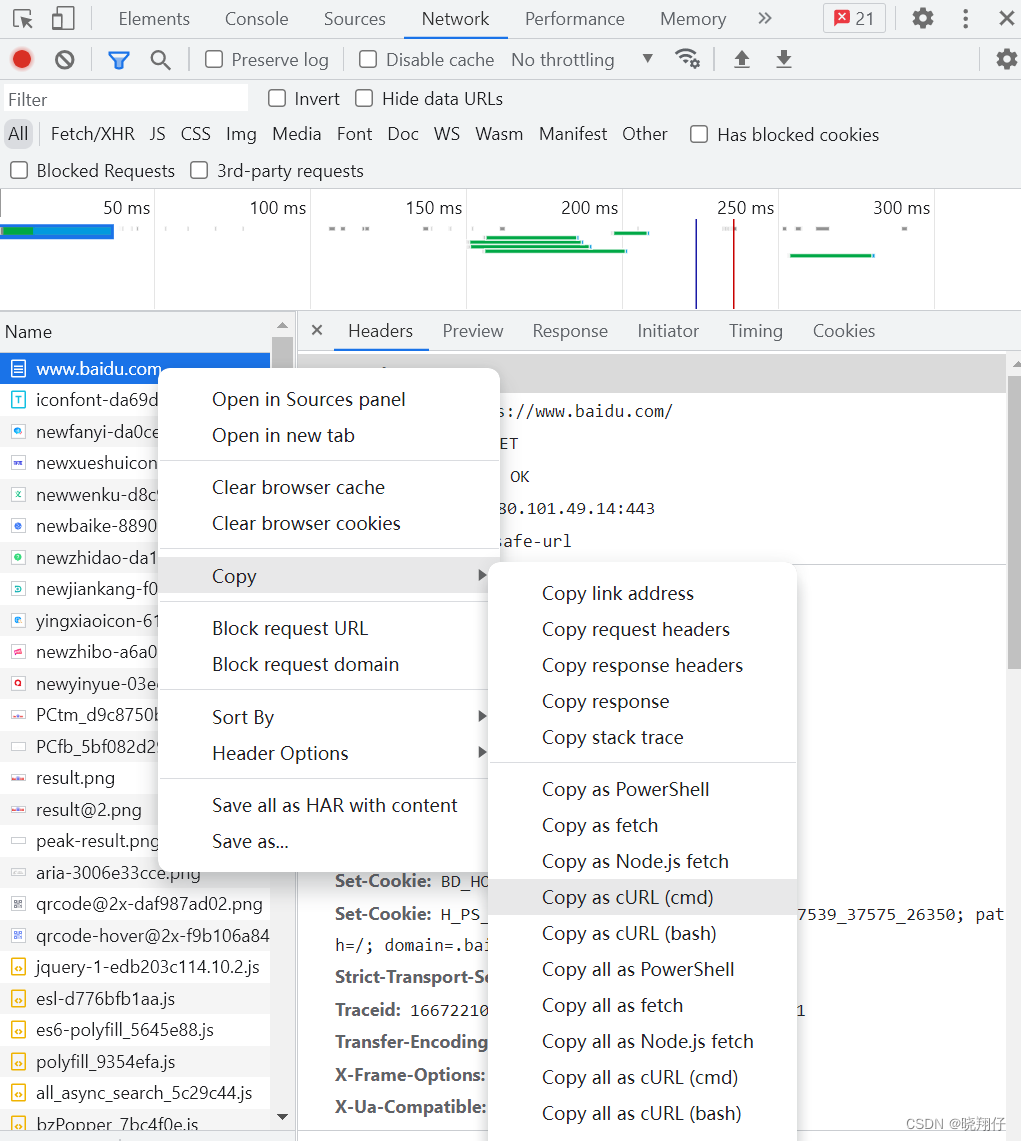
复制出来的curl命令如下:
curl "https://www.baidu.com/" ^
-H "Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9" ^
-H "Accept-Language: zh-CN,zh;q=0.9" ^
-H "Connection: keep-alive" ^
-H "Cookie: BIDUPSID=61EDAD335605FB5CA64D805B2003AD64; PSTM=1667138050; BAIDUID=61EDAD335605FB5C14F509C2EB71B594:FG=1; BD_UPN=12314753; BA_HECTOR=2la4a18k2581ah8k800kecvf1hlt0g21b; BAIDUID_BFESS=61EDAD335605FB5C14F509C2EB71B594:FG=1; ZFY=EsI6H59hbOhALYJbTN0ArAY0MCXO0ON2meAufYBBPjg:C; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; COOKIE_SESSION=73907_0_0_0_3_0_1_0_0_0_0_0_73908_0_2_0_1667211968_0_1667211966^%^7C2^%^230_0_1667211966^%^7C1; BD_HOME=1; H_PS_PSSID=36546_37584_36885_36789_37539_37575_26350; delPer=0; BD_CK_SAM=1; PSINO=2; H_PS_645EC=ef46AWOvUKTVSL89g^%^2FMxUiCAJn5hW2VO53FKWV0jrkHNjitkOGn7I1Ty5x0; baikeVisitId=fb52826b-9f53-43ce-8656-eaaa3d5bbe5b; shifen^[1674610128_57943^]=1667218702; BCLID=9341060554169253781; BCLID_BFESS=9341060554169253781; BDSFRCVID=mEuOJeCmHRh4nBOjVz8WhdmKOeKK0gOTHlln3wqXrK95vw0VJeC6EG0Ptf8g0KubFTPRogKK0gOTH6KF_2uxOjjg8UtVJeC6EG0Ptf8g0M5; BDSFRCVID_BFESS=mEuOJeCmHRh4nBOjVz8WhdmKOeKK0gOTHlln3wqXrK95vw0VJeC6EG0Ptf8g0KubFTPRogKK0gOTH6KF_2uxOjjg8UtVJeC6EG0Ptf8g0M5; H_BDCLCKID_SF=tJkD_I_hJKt3fP36q6_a2-F_2xQ0etJXfKj4Ll7F5lOVOModj-TIXPIZ2G7UaP3LW2O-ahkM5h7xObR1h6bbKqkXyNut-J-jQeQ-5KQN3KJmfbL9bT3v5tDz3b3N2-biWbRM2MbdJqvP_IoG2Mn8M4bb3qOpBtQmJeTxoUJ25DnJhhCGe4bK-TrLjGtHqUK; H_BDCLCKID_SF_BFESS=tJkD_I_hJKt3fP36q6_a2-F_2xQ0etJXfKj4Ll7F5lOVOModj-TIXPIZ2G7UaP3LW2O-ahkM5h7xObR1h6bbKqkXyNut-J-jQeQ-5KQN3KJmfbL9bT3v5tDz3b3N2-biWbRM2MbdJqvP_IoG2Mn8M4bb3qOpBtQmJeTxoUJ25DnJhhCGe4bK-TrLjGtHqUK; Hm_lvt_aec699bb6442ba076c8981c6dc490771=1667218705; Hm_lpvt_aec699bb6442ba076c8981c6dc490771=1667218705; WWW_ST=1667221069080" ^
-H "Referer: https://www.baidu.com/" ^
-H "Sec-Fetch-Dest: document" ^
-H "Sec-Fetch-Mode: navigate" ^
-H "Sec-Fetch-Site: same-origin" ^
-H "Sec-Fetch-User: ?1" ^
-H "Upgrade-Insecure-Requests: 1" ^
-H "User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36" ^
-H "sec-ch-ua: ^\^"Google Chrome^\^";v=^\^"107^\^", ^\^"Chromium^\^";v=^\^"107^\^", ^\^"Not=A?Brand^\^";v=^\^"24^\^"" ^
-H "sec-ch-ua-mobile: ?0" ^
-H "sec-ch-ua-platform: ^\^"Windows^\^"" ^
--compressed
3. curl命令转为python request
推荐一个在线转换的网址
直接输入curl命令就可以转换成功

4. python request转为curl命令
从pyhthon导入一个叫curlify的库,可以完成转化
import curlify
import requests
data = {
"wd": "hello"
}
url = 'http://www.baidu.com/s'
response = requests.get(url=url, data=data, headers={
'Accept': 'text/html,application/xhtml+xml',
})
print(curlify.to_curl(response.request))
执行结果
$ python3 a.py
curl -X GET -H 'Accept: text/html,application/xhtml+xml' -H 'Accept-Encoding: gzip, deflate' -H 'Connection: keep-alive' -H 'Content-Length: 8' -H 'Content-Type: application/x-www-form-urlencoded' -H 'User-Agent: python-requests/2.25.1' -d wd=hello http://www.baidu.com/s
5.最后
本文讲了浏览器提取url至Curl,Curl请求与Python request之间的转化的方法,如果你想知道很多curl命令有关的信息可以查看以下资料
版权声明:本文为qq_33163046原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。