ETL,SQL面试高频考点——HIVE开窗函数(基础篇)
目录标题
一,窗口函数介绍
- 窗口函数,也叫OLAP函数(Online Anallytical Processing,联机分析处理),可以对数据库数据进行实时分析处理。
- 窗口函数由开窗函数和分析函数构成,窗口函数就是既要显示聚集前的数据,又要显示聚集后的数据,简单讲,就是你查询的结果上,多出一列值(可以是聚合值或者排序号),所以分析函数可以分为两类:聚合分析函数和排序分析函数
- 基本语法:
<窗口分析函数> over (partition by <用于分组的字段> order by<用于排序的列名>)
二,开窗函数
1,概要
开窗函数就是over()函数,就是限定一个窗口,来显示分析函数的结果
2,开窗函数一般有两种(固定形式,不可更改)
-- 第一种
over(partiton by ... order by ...)
-- 第二种
over(distribute by ... order by ...)
3,区别
- partiton by是一个一个reduce处理数据的,所以使用全局排序order by distribute
- distribute by是多个reduce处理数据的,所以使用局部排序sort by
三,分析函数分类
1,排序分析函数:
- RANK() OVER();
- ROW_NUMBER() OVER();
- DENSE_RANK() OVER();
- NTILE(n) OVER();
实列解析
- 创建一个学生成绩表
create table if not exists sc(name string,score int)
row format delimited fields terminated by '\t';
-
导入数据到HIVE
张三 100
李四 90
王五 80
刘六 100
田七 70
load data local inpath '数据文件本地路径' into table sc
1.使用 RANK() OVER()
- 特点:并列跳跃排序
-
不开窗sql实现rank()
sql语句
SELECT b.name,b.Score,(
select count(a.score)
from sc a
WHERE a.score>b.score) +1 as Ranking
FROM sc b
ORDER BY b.score DESC
-
结果
-
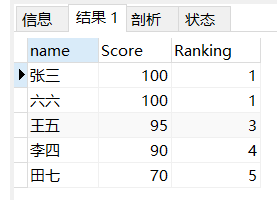
原理总结:
第一部分实现表的降序排序
sql语句
SELECT b.name,b.Score
FROM sc b
ORDER BY b.score DESC
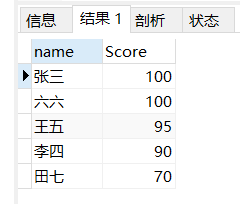
第二部分实现,假设给你一个分数,如何计算出他的Rank排名:
比如图中的王五是95分,大于他的分数有[100,100],count统计个数为2,加1就能得到他的rank排名3,其他如此类推,所以每个同学的rank排名为成绩在他之上的人数+1
sql语句
--计算大于分数的集合个数
(select count(a.score)
from sc a
WHERE a.score>b.score) +1 as Ranking
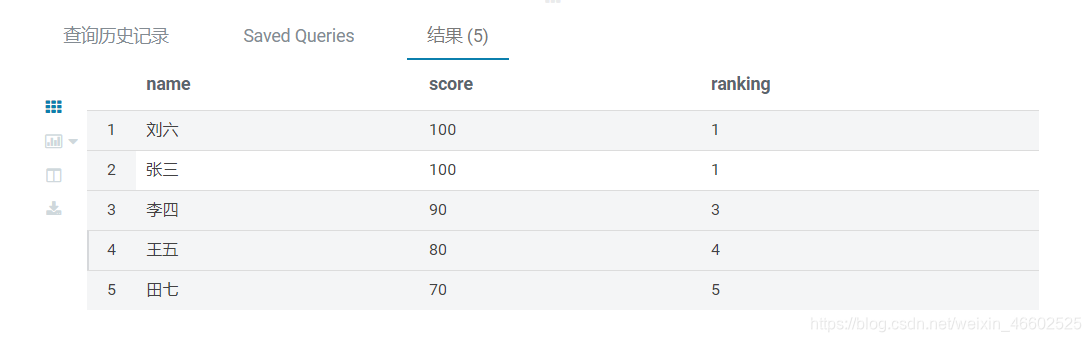
- 使用开窗语句:
FROM sc
SELECT name,score,rank() over(ORDER BY score desc) ranking
-
结果:
2.使用 DENSE_RANK() OVER()
- 特点:并列连续排序
-
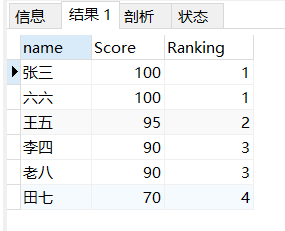
不开窗sql实现dense_rank()
sql语句
SELECT b.name,b.Score
,(select count(DISTINCT(a.score))
from sc a
WHERE a.score>=b.score) as Ranking
FROM sc b
ORDER BY b.score DESC
-
结果
-
原理
这个与上面的函数不同因为是连续的,所以我们需要对获得到的重复的分数进行去重,比如说李四的成绩为90,那大于等于90的集合为[100,100,95,90,90],去重之后集合为[100,95,90],集合的长度就是他对应的连续排名3 -
DENSE_RANK函数
FROM sc
SELECT name,score,dense_rank() OVER(ORDER BY score DESC) ranking
对比总结
通过上面两个函数,我们发现开窗函数能实现普通函数比较难实现或者无法实现的问题,因为聚合函数只能操作分组的字段,这也是聚合函数最大的特点,窗口函数能够操作所有的字段,不受分组的限制。
3.ROW_NUMBER() PERCENT_RANK() NTILE() 概述
-
ROW_NUMBER()
特点:连续排序 -
PERCENT_RANK()
特点:百分比排序 -
NTILE()
特点:将有序集分桶(bucket)
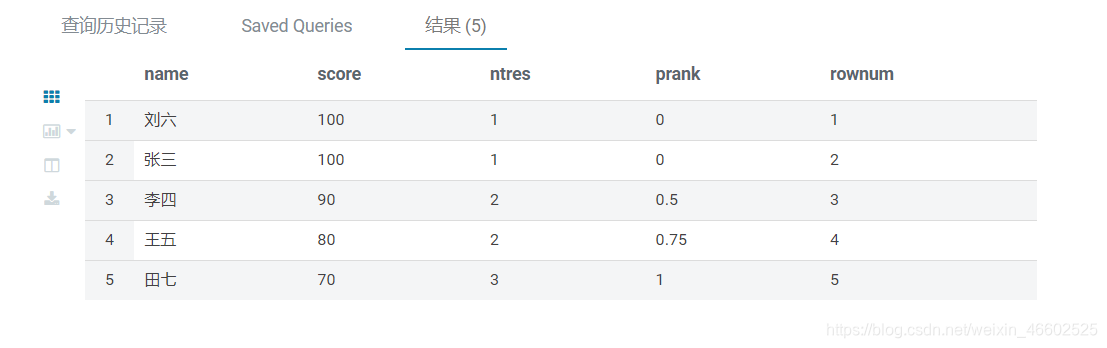
sql语句
FROM sc
SELECT name,score,
ntile(3) OVER(ORDER BY score DESC) ntres,
percent_rank() OVER(ORDER BY score DESC) prank,
row_number() OVER(ORDER BY score DESC) rownum
结果
2.聚合分析函数
| 函数 | 作用 |
|---|---|
| sum | 求和 |
| avg | 求平均数 |
| max | 求最大值 |
| min | 求最小值 |
| count | 计数 |
| first_value | 返回分区中的第一个值 |
| last_value | 返回分区中到当前行的最后一个值 |
| lag(col,n,default) | col指定列,n用于统计窗口内往上第n个值 ,default不指定查找不到默认为NULL |
| lead(col,n,default) | col指定列,n用于统计窗口内往下第n个值,default不指定查找不到默认为NULL |
| cume_dist | 计算某个窗口或分区中某个值的累积分布,值为order by 子句中指定的列的当前行中的值。 |
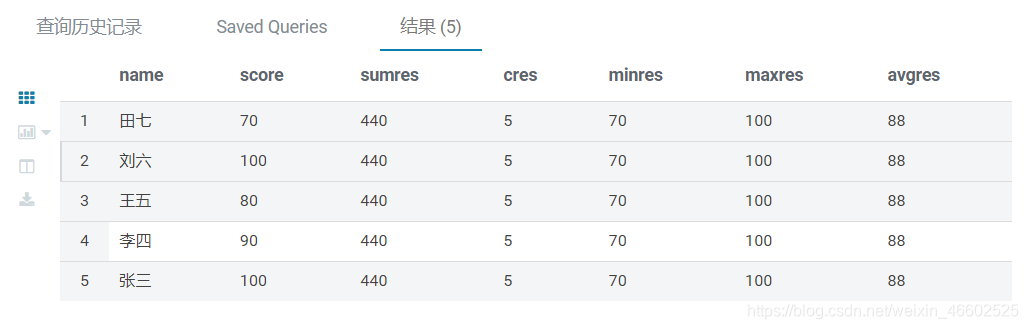
例:sum avg max min count
FROM sc
SELECT name,score,
sum(score) OVER() sumres,
count(score) OVER() cres ,
min(score) OVER() minres,
max(score) OVER() maxres,
avg(score) OVER() avgres
结果
- 下面的函数的使用是根据over()中的参数变化而变化的
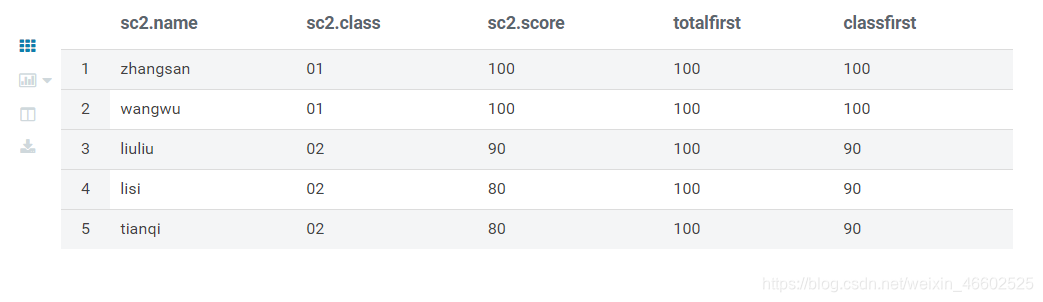
first_value() 函数
- 用法是根据partiton by 的字段进行分区,如果忽略partition by,会根据order by排序后的结果返回第一条数据
- 示例 在每行数据后开窗显示总第一名和每个班的第一名
FROM sc2
SELECT *,first_value(score) OVER(ORDER BY score DESC) as totalFirst,
first_value(score) OVER(PARTITION BY class ORDER BY score DESC) as classFirst
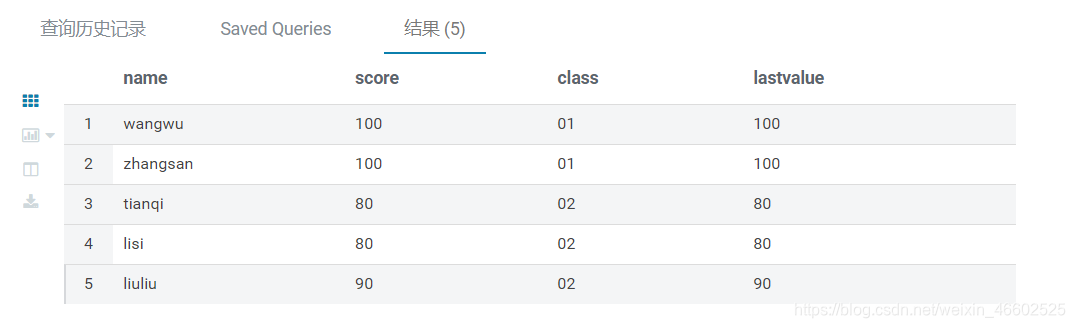
last_value() 函数
- 作用是返回到当前行的最后一条数据
- 示例
FROM SC2
-- 求分区内到当前行的最后一个值
SELECT name,score,class,last_value(score) OVER(PARTITION BY class order by score) lastvalue
lag() 函数
- 用法是用于统计分组内的往上前n个值
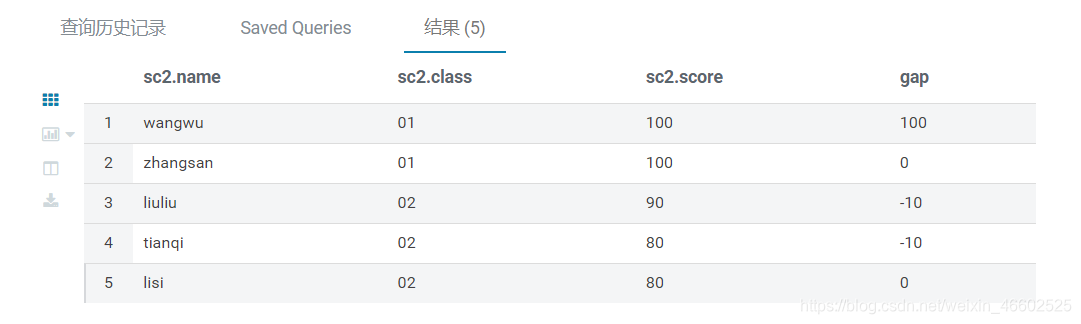
- 示例1 排名并显示每个同学和上一位同学的分差
from sc2
select *,
score-lag(score,1,0) over(order by score desc) as gap
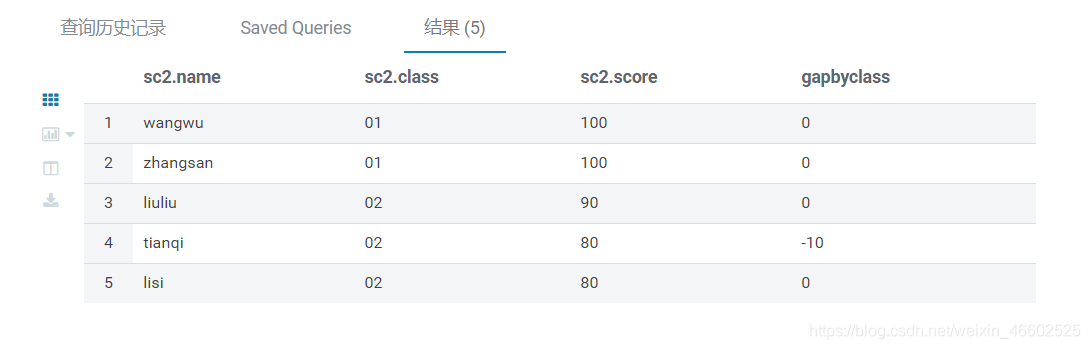
- 示例2 排名并显示同一个班上每个同学和上一位同学的分差
from sc2
select *,
score-lag(score,1,score) over(partition by class order by score desc) as gapByClass
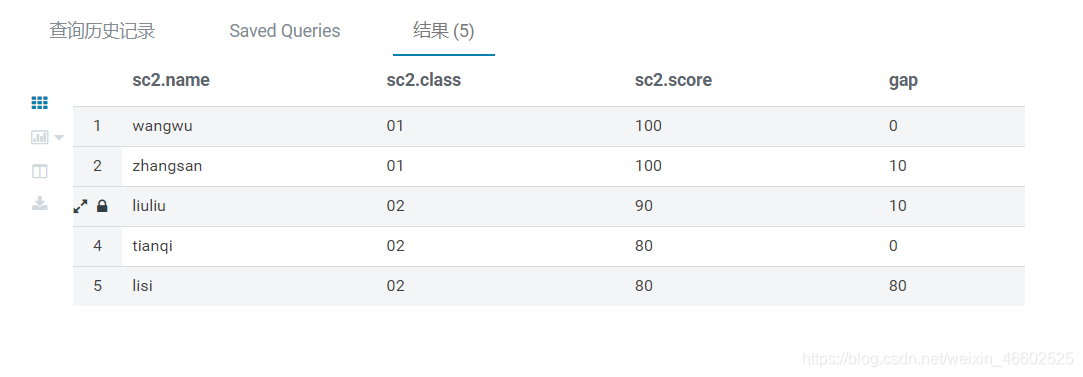
lead() 函数
- 用法是用于统计分组内的往下后n个值
- 示例 排名并显示每个同学和后一名一位同学的分差
from sc2
select *,
score-lead(score,1,0) over(order by score desc) as gap
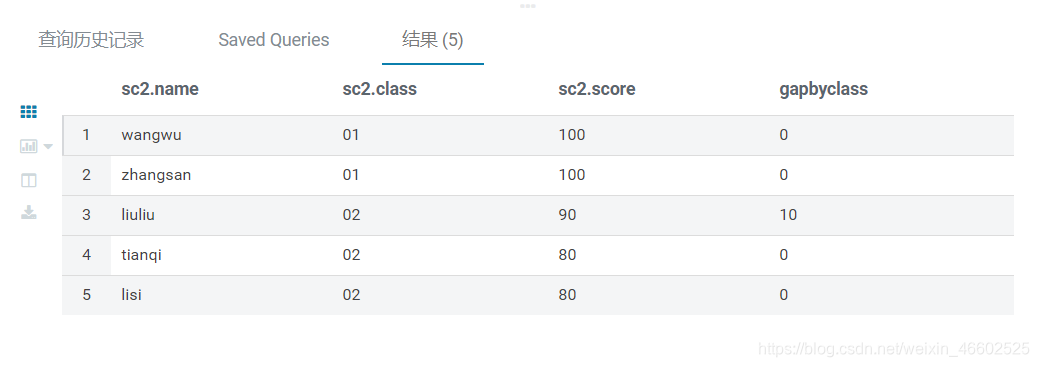
- 示例2 排名并显示同一个班上每个同学和下一位同学的分差
from sc2
select *,
score-lead(score,1,score) over(partition by class order by score desc) as gapByClass
cume_dist() 函数
- 用法是如果按升序排列,则统计:小于等于当前值的行数/总行数(number of rows ≤ current row)/(total number of rows)。如果是降序排列,则统计:大于等于当前值的行数/总行数。
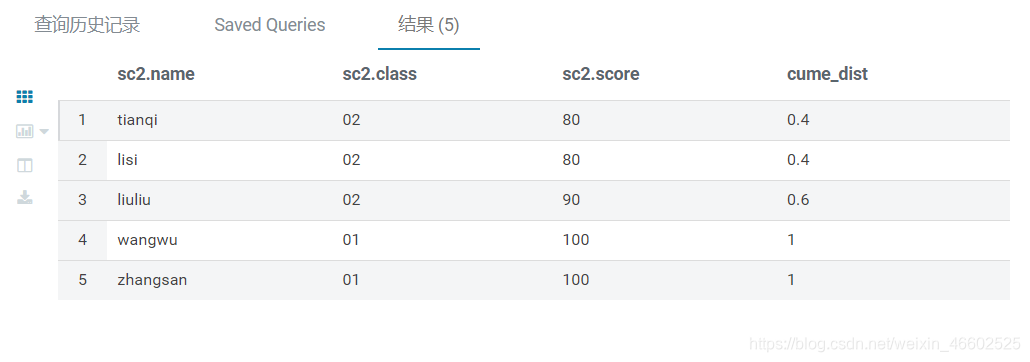
- 示例1 统计小于等于当前分数的人数占比
from sc2
select *,
cume_dist() over(order by score) as cume_dist
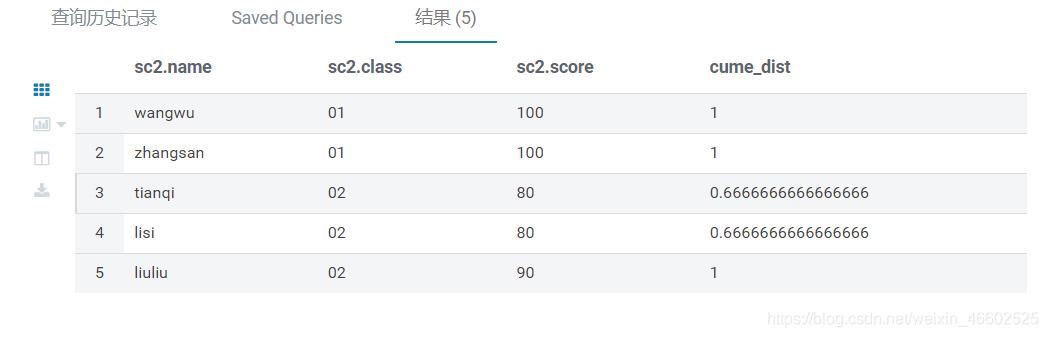
- 示例2 统计每个班小于等于当前分数的人数占比
from sc2
select *,
cume_dist() over(partition by class order by score) as cume_dist
3.用spark 自定义HIVE用户自定义函数
- hive中的表,可以通过如下语句缓存表,提高分析速度
cache table 表名
-
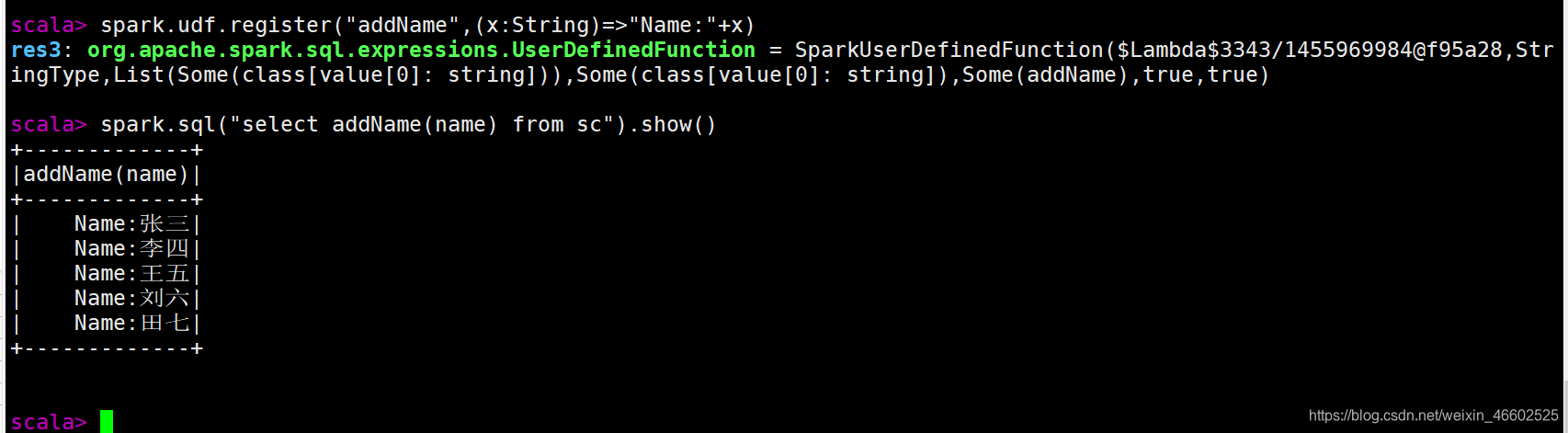
自定义UDF函数,相对比较简单我用的spark-shell
例:addName()函数
-
自定义UDAF函数
需要写一个类继承UserDefinedAggregateFunction.实现抽象方法,注册后使用spark.sql调用
例: 构造一个自定义的MyAvg()函数
import org.apache.spark.SparkConf
import org.apache.spark.sql.{Row, SparkSession}
import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types.{DataType, DoubleType, LongType, StructField, StructType}
object UdadDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("UdAd")
val spark: SparkSession = new SparkSession.Builder().config(conf).enableHiveSupport().getOrCreate()
val avg = new MyAvg
spark.udf.register("myAvg",avg)
spark.sql("select MyAvg(score) from sc").show()
}
}
class MyAvg extends UserDefinedAggregateFunction(){
//输入结构
override def inputSchema: StructType = StructType(Seq(StructField("inputColumn",LongType)))
//结构缓存
override def bufferSchema: StructType ={
StructType{
Seq(StructField("sum",LongType),StructField("count",LongType))
}
}
//返回值类型
override def dataType: DataType = DoubleType
//是否是稳定的
override def deterministic: Boolean = true
//初始化缓存设置0值的位置
override def initialize(buffer: MutableAggregationBuffer): Unit = {
buffer(0)=0L
buffer(1)=0L
}
//更新缓存
override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
buffer(0)=buffer.getLong(0)+input.getLong(0)
buffer(1)=buffer.getLong(1)+1
}
//合并缓存
override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit ={
buffer1(0)=buffer1.getLong(0)+buffer2.getLong(0)
buffer1(1)=buffer1.getLong(1)+buffer2.getLong(1)
}
//计算输出结果
override def evaluate(buffer: Row): Any = {
buffer.getLong(0).toDouble/buffer.getLong(1)
}
}
-
结果:
±—————————————–+
|myavg(CAST(score AS BIGINT))|
±——————————————+
| 88.0|
±——————————————+
后续更新中~