本篇文章着重写的是系统中栈的工作原理,以及函数调用过程中栈帧的产生与释放的过程,有可能名字过大,如果不合适我可以换一个名字,希望大家能够指正,小丁虚心求教!如果有哪里写的不清楚的或者错误的地方请及时更正,小丁再次谢过了。文章里面有错别字,也可能会有好友说寄存器的32、16位的区别其实我感觉这里主要讲的还是些原理性的东西,后续会将文章图片错别字进行调整.(图片里面的posh改为push)
根据不同的操作系统,一个进程可能被分配到不同的内存区域去执行。但是不管什么样的操作系统、什么样的计算机架构,进程使用的内存都可以按照功能大致分为以下4个部分:
(1)代码区:这个区域存储着被装入执行的二进制机器代码,处理器会到这个区域取指并执行。
(2)数据区:用于存储全局变量等。
(3)堆区:进程可以在堆区动态地请求一定大小的内存,并在用完之后归还给堆区。动态分配和回收是堆区的特点。
(4)栈区:用于动态地存储函数之间的关系,以保证被调用函数在返回时恢复到母函数中继续执行。
在Windows平台下,高级语言写出的程序经过编译链接,最终会变成PE文件。当PE文件被装载运行后,就成了所谓的进程。
PE文件代码段中包含的二进制级别的机器代码会被装入内存的代码区(.text),处理器将到内存的这个区域一条一条地取出指令和操作数,并送入运算逻辑单元进行运算;如果代码中请求开辟动态内存,则会在内存的堆区分配一块大小合适的区域返回给代码区的代码使用;当函数调用发生时,函数的调用关系等信息会动态地保存在内存的栈区,以供处理器在执行完被调用函数的代码时,返回母函数。
如果把计算机看成一个有条不紊的工厂,我们可以得到如下类比:
< CPU是完成工作的工人。
< 数据区、堆区、栈区等则是用来存放原料、半成品、成品等各种东西的场所。
< 存放在代码区的指令则告诉CPU要做什么,怎么做,到哪里去领原材料,用什么工具来做,做完以后把成品放到哪个货仓去。
< 值得一提的是,栈除了扮演存放原料、半成品的仓库之外,它还是车间调度主任的办公室。
从计算机科学的角度来看,栈指的是一种数据结构,是一种先进后出的数据表。栈的最常见操作有两种:压栈(PUSH)、弹栈(POP);
用于标识栈的属性也有两个:栈顶(TOP)、栈底(BASE)。
栈在内存中的存放是高地址是栈底(Base),低地址是栈顶(Top)。
下面来演示下栈的工作原理:
首先我们先以这段汇编指令来进行操作:
mov ax,0123H push ax mov bx 2244H push bx pop ax pop bx
首先我们先将10000H-1000FH这段内存空间来当做栈来使用,首先执行的操作是push ax,会将0123H压入到栈中,SP=SP-2,SS:SP指向当前栈顶当前的单元,以当前的单元为新的栈顶,将ax的数据送到SS:SP指向的内存单元中,SS:SP此时指向新的栈顶。此时ax的数值是0123H;详细请见下图
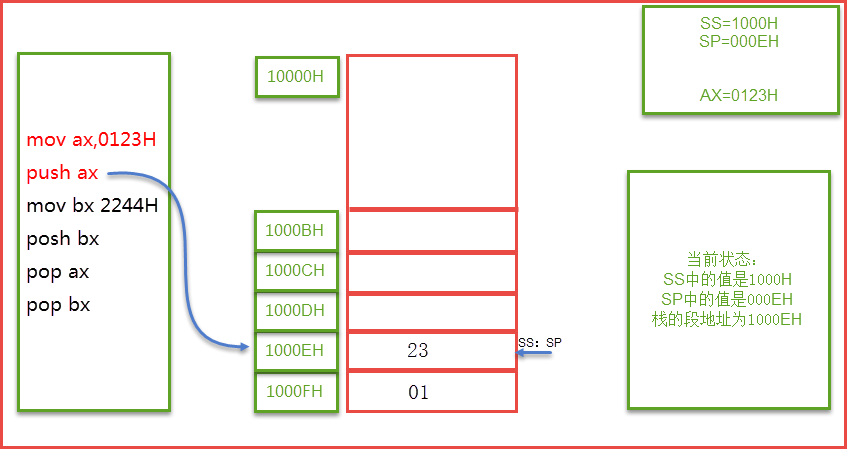
接来下进行第二部操作:push bx,操作同上;

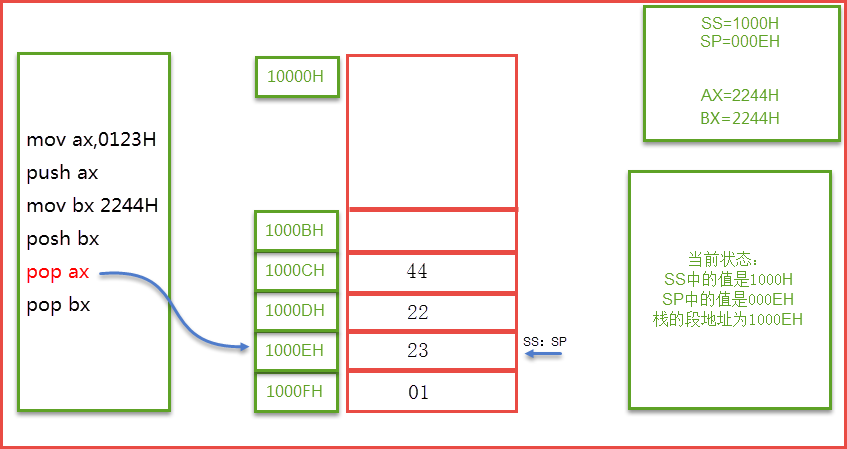
接下来我们要演示的是pop操作,请注意pop操作的细节,比如到了栈底的时候指针是在哪里?这些都是要进行关注的。
CPU执行pop ax时,SP=SP+2,SS:SP指向1000EH,pop操作栈顶元素,1000CH处的2266H依然存在,但是它在栈中不存在了,当再次push等入栈指令后,SS:SP移至1000CH,并在里面写入新的数据,将其覆盖。详细看下图操作:
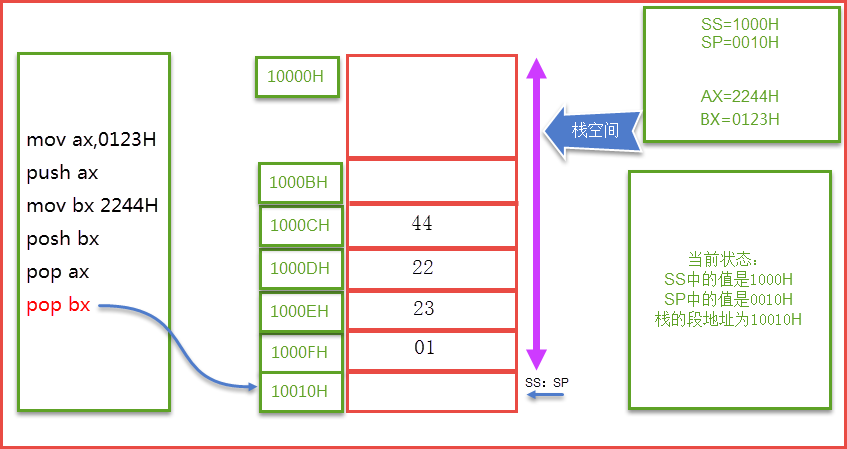
当再次进行pop给bx时,这是SP=SP+2,这时候指针就超出了栈底,就变成了SP=10H,所以我们得出一个结论就是当栈为空时,SS=1000H,SP=10H。详细看下面操作:
内存的栈区实际上指的就是系统栈。系统栈由系统自动维护,它用于实现高级语言中函数的调用。对于类似C语言这样的高级语言,系统栈的PUSH、POP等堆栈平衡细节是透明的。一般说来,只有在使用汇编语言开发程序的时候,才需要和它直接打交道。
函数调用约定描述了函数传递参数方式和栈帧同工作的技术细节。不同的操作系统、不同的语言、不同的编译器在实现函数调用时的原理虽然基本相同,但具体的调用约定还是有差别的。这包括参数传递方式,参数入栈顺序是从右向左还是从左向右,函数返回时恢复堆栈平衡的操作在子函数中进行还是在母函数中进行。
调用方式之间的差异
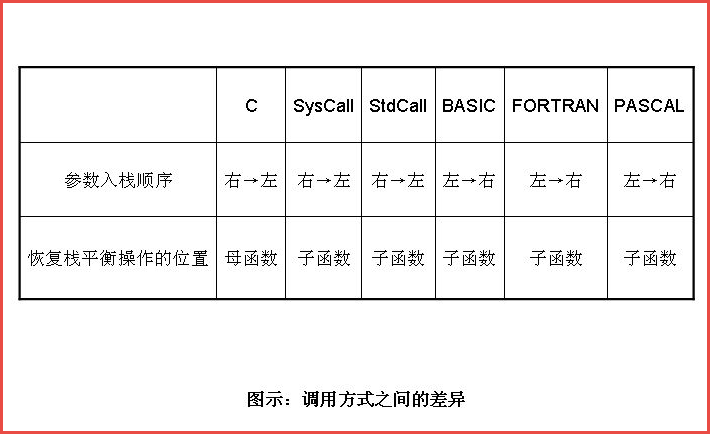
具体的,对于Visual C++来说,可支持以下3种函数调用约定:
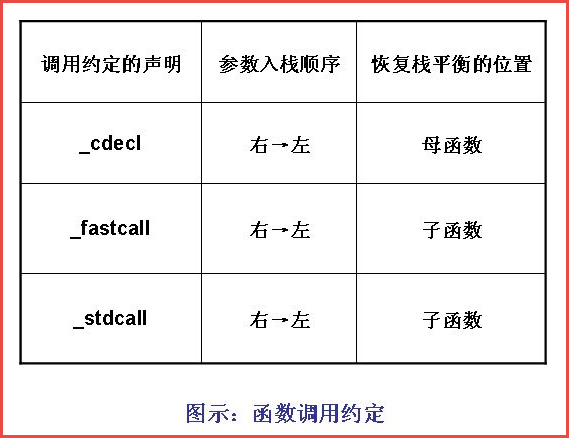
如果要明确使用某一种调用约定,只需要在函数前加上调用约定的声明即可,否则默认情况下,VC会使用_stdcall的调用方式。 除了参数入栈方向和恢复栈平衡操作位置的不同之外,参数传递有时也会有所不同。例如,每一个C++类成员函数都有一个this指针,在Windows平台中,这个指针一般是用ECX寄存器来传递的,但如果用GCC编译器来编译,这个指针会作为最后一个参数压入栈中。
注意:同一段代码用不同的编译选项、不同的编译器编译链接后,得到的可执行文件会有很多不同。
函数调用大概包括以下几个步骤:
(1)参数入栈:将参数从右向左依次压入系统栈中。
(2)返回地址入栈:将当前代码区调用指令的下一条指令地址压入栈中,供函数返回时继续执行。
(3)代码区跳转:处理器从当前代码区跳转到被调用函数的入口处。
(4)栈帧调整:具体包括:
<1>保存当前栈帧状态值,已备后面恢复本栈帧时使用(EBP入栈)。
<2>将当前栈帧切换到新栈帧(将ESP值装入EBP,更新栈帧底部)。
<3>给新栈帧分配空间(把ESP减去所需空间的大小,抬高栈顶)。
<4>对于_stdcall调用约定,函数调用时用到的指令序列大致如下:
push 参数3 ;假设该函数有3个参数,将从右向做依次入栈
push 参数2
push 参数1
call 函数地址 ;call指令将同时完成两项工作:a)向栈中压入当前指令地址的下一个指令地址,即保存返回地址。 b)跳转到所调用函数的入口处。
push ebp ;保存旧栈帧的底部
mov ebp,esp ;设置新栈帧的底部 (栈帧切换)
sub esp,xxx ;设置新栈帧的顶部 (抬高栈顶,为新栈帧开辟空间)
函数返回的步骤如下:
<1>保存返回值,通常将函数的返回值保存在寄存器EAX中。
<2>弹出当前帧,恢复上一个栈帧。具体包括:
(1)在堆栈平衡的基础上,给ESP加上栈帧的大小,降低栈顶,回收当前栈帧的空间。
(2)将当前栈帧底部保存的前栈帧EBP值弹入EBP寄存器,恢复出上一个栈帧。
(3)将函数返回地址弹给EIP寄存器。
<3>跳转:按照函数返回地址跳回母函数中继续执行。
还是以C语言和Win32平台为例,函数返回时的相关的指令序列如下:
add esp,xxx ;降低栈顶,回收当前的栈帧
pop ebp ;将上一个栈帧底部位置恢复到ebp
retn ;a)弹出当前栈顶元素,即弹出栈帧中的返回地址,至此,栈帧恢复到上一个栈帧工作完成。b)让处理器跳转到弹出的返回地址,恢复调用前代码区
每一个函数独占自己的栈帧空间。当前正在运行的函数的栈帧总是在栈顶。Win32系统提供两个特殊的寄存器用于标识位于系统栈顶端的栈帧。
(1)ESP:栈指针寄存器(extended stack pointer),其内存放着一个指针,该指针永远指向系统栈最上面一个栈帧的栈顶。
(2)EBP:基址指针寄存器(extended base pointer),其内存放着一个指针,该指针永远指向系统栈最上面一个栈帧的底部。
【寄存器对栈的标识作用见(图1)】

函数栈帧:ESP和EBP之间的内存空间为当前栈帧,EBP标识了当前栈帧的底部,ESP标识了当前栈帧的顶部。
在函数栈帧中,一般包含以下几类重要信息。
(1)局部变量:为函数局部变量开辟的内存空间。
(2)栈帧状态值:保存前栈帧的顶部和底部(实际上只保存前栈帧的底部,前栈帧的顶部可以通过栈帧平衡计算得到),用于在本栈被弹出后恢复出上一个栈帧。
(3)函数返回地址:保存当前函数调用前的“断点”信息,也就是函数调用前的指令位置,以便在函数返回时能够恢复到函数被调用前的代码区中继续执行指令。
注:函数栈帧的大小并不固定,一般与其对应函数的局部变量多少有关。函数运行过程中,其栈帧大小也是在不停变化的。除了与栈相关的寄存器外,我们还需要记住另一个至关重要的寄存器。
EIP:指令寄存器(extended instruction pointer),其内存放着一个指针,该指针永远指向下一条等待执行的指令地址。 可以说如果控制了EIP寄存器的内容,就控制了进程——我们让EIP指向哪里,CPU就会去执行哪里的指令。这里不多说EIP的作用,我个人认为王爽老是的汇编里面讲EIP讲的已经是挺好的了~这里不想多写关于EIP的事情。
本文是针对上面两篇文章的一个基础性的补充~希望大家能够喜欢和指正其中的不足之处,小丁虚心学习于请教~不知道名字叫啥~
内容参考:0day安全:软件漏洞分析技术(第2版)
转载于:https://www.cnblogs.com/dwlsxj/p/Stack.html