1. 使用@Scheduled实现定时任务
比如:我需要定时地发送一些短信、邮件之类的操作,也可能会定时地检查和监控一些标志、参数等。
创建定时任务
在Spring Boot中编写定时任务是非常简单的事,下面通过实例介绍如何在Spring Boot中创建定时任务,实现每过5秒输出一下当前时间。
开启注解
-
在Spring Boot的主类中加入
@EnableScheduling
注解,启用定时任务的配置
@SpringBootApplication
@EnableScheduling
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
- 创建定时任务实现类
具体的实现类
@Component
public class ScheduledTasks {
private static final SimpleDateFormat dateFormat = new SimpleDateFormat("HH:mm:ss");
@Scheduled(fixedRate = 5000)
public void reportCurrentTime() {
log.info("现在时间:" + dateFormat.format(new Date()));
}
}
- 运行程序,控制台中可以看到类似如下输出,定时任务开始正常运作了。
@Scheduled
详解
@Scheduled
在上面的入门例子中,使用了
@Scheduled(fixedRate = 5000)
注解来定义每过5秒执行的任务。对于
@Scheduled
的使用,我们从源码里看看有哪些配置:
@Target({ElementType.METHOD, ElementType.ANNOTATION_TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Repeatable(Schedules.class)
public @interface Scheduled {
String CRON_DISABLED = ScheduledTaskRegistrar.CRON_DISABLED;
String cron() default "";
String zone() default "";
long fixedDelay() default -1;
String fixedDelayString() default "";
long fixedRate() default -1;
String fixedRateString() default "";
long initialDelay() default -1;
String initialDelayString() default "";
}
这些具体配置信息的含义如下:
-
cron:通过cron表达式来配置执行规则
-
zone:cron表达式解析时使用的时区
-
fixedDelay:上一次执行结束到 下一次执行开始的间隔时间(单位:ms)
-
fixedDelayString:上一次任务执行结束到 下一次执行开始的间隔时间,使用java.time.Duration#parse解析
-
fixedRate:以固定间隔执行任务,即上一次任务执行开始到下一次执行开始的间隔时间(单位:ms),若在调度任务执行时,上一次任务还未执行完毕,会加入worker队列,等待上一次执行完成后立即执行下一次任务
-
fixedRateString:与fixedRate逻辑一致,只是使用java.time.Duration#parse解析
-
initialDelay:首次任务执行的延迟时间
-
initialDelayString:首次任务执行的延迟时间,使用java.time.Duration#parse解析
-
每7秒执行一次(定时任务没5秒一次,真实需要7秒,下次任务会在 worker队列卡着,等7秒后上次执行完毕,直接执行)
@Scheduled(fixedRate = 5000)
public void reportCurrentTime() {
try {
Thread.sleep(7000L);
} catch (Exception e) {
}
}
思考与进阶
这种模式实现的定时任务缺少在集群环境下的协调机制。
什么意思呢?假设,我们要实现一个定时任务,用来每天网上统计某个数据然后累加到原始数据上。我们开发测试的时候不会有问题,因为都是单进程在运行的。
- 但是,当我们把这样的定时任务部署到生产环境时,为了更高的可用性,启动多个实例是必须的。
-
此时,时间一到,所有启动的实例就会同时开始执行这个任务。
- 那么问题也就出现了,因为有累加操作,最终我们的结果就会出现问题。
解决这样问题的方式很多种,比较通用的就是采用分布式锁的方式,
- 让同类任务之前的时候以分布式锁的方式来控制执行顺序,
- 比如:使用Redis、Zookeeper等具备分布式锁功能的中间件配合就能很好的帮助我们来协调这类任务在集群模式下的执行规则。
本文的完整工程可以查看下面仓库中的
chapter7-1
目录:
2. 使用Elastic Job实现定时任务
当在集群环境下的时候,如果任务的执行或操作依赖一些共享资源的话,就会存在竞争关系。如果不引入分布式锁等机制来做调度的话,就可能出现预料之外的执行结果。
所以,
@Scheduled
注解更偏向于使用在单实例自身维护相关的一些定时任务上会更为合理一些,
- 比如:定时清理服务实例某个目录下的文件、定时上传本实例的一些统计数据等。
Elastic Job
Elastic Job的前生是当当开源的一款分布式任务调度框架,而目前已经加入到了Apache基金会。
该项目下有两个分支:ElasticJob-Lite和ElasticJob-Cloud。
- ElasticJob-Lite是一个轻量级的任务管理方案,本文接下来的案例就用这个来实现。
- 而 ElasticJob-Cloud则相对重一些,因为它使用容器来管理任务和隔离资源。
更多关于ElasticJob的介绍,您也可以
点击这里直达官方网站
了解更多信息。
动手试试
引入pom
第二步
:
pom.xml
中添加elasticjob-lite的starter
<dependencies>
<dependency>
<groupId>org.apache.shardingsphere.elasticjob</groupId>
<artifactId>elasticjob-lite-spring-boot-starter</artifactId>
<version>3.0.0</version>
</dependency>
// ...
</dependencies>
创建简单的任务
第三步
:创建一个简单任务
@Slf4j
@Service
public class MySimpleJob implements SimpleJob {
@Override
public void execute(ShardingContext context) {
log.info("MySimpleJob start : didispace.com {}", System.currentTimeMillis());
}
}
配置文件
第四步
:编辑配置文件
elasticjob.reg-center.server-lists=localhost:2181
elasticjob.reg-center.namespace=didispace
elasticjob.jobs.my-simple-job.elastic-job-class=com.didispace.chapter72.MySimpleJob
elasticjob.jobs.my-simple-job.cron=0/5 * * * * ?
elasticjob.jobs.my-simple-job.sharding-total-count=1
这里主要有两个部分:
第一部分:
elasticjob.reg-center
开头的,主要配置elastic job的注册中心和namespace
第二部分:任务配置,以
elasticjob.jobs
开头,
-
这里的
my-simple-job
是任务的名称,根据你的喜好命名即可,但不要重复。 -
任务的下的配置
elastic-job-class
是任务的实现类,
cron
是执行规则表达式, -
sharding-total-count
是任务分片的总数。我们可以通过这个参数来把任务切分,实现并行处理。这里先设置为1,后面我们另外讲分片的使用。
运行与测试
这里需要用到ZooKeeper来协调分布式环境下的任务调度。所以,你需要先在本地安装ZooKeeper,然后启动它。
-
注意:上面
elasticjob.reg-center.server-lists
配置, - 根据你实际使用的ZooKeeper地址和端口做相应修改。
在启动上述Spring Boot应用之后,我们可以看到如下日志输出:
didispace.com 1626766435013
既然是分布式任务调度,那么我们再启动一个(注意,在同一台机器启动的时候,会端口冲突,可以在启动命令中加入
-Dserver.port=8081
来区分端口),在第二个启动的服务日志也打印了类似的内容
此时,在回头看看之前第一个启动的应用,日志输出停止了。由于我们设置了分片总数为1,所以这个任务启动之后,只会有一个实例接管执行。
- 这样就避免了多个进行同时重复的执行相同逻辑而产生问题的情况。
- 同时,这样也支持了任务执行的高可用。比如:可以尝试把第二个启动的应用(正在打印日志的)终止掉。可以发现,第一个启动的应用(之前已经停止输出日志)继续开始打印任务日志了。
在整个实现过程中,我们并没有自己手工的去编写任何的分布式锁等代码去实现任务调度逻辑,只需要关注任务逻辑本身,然后通过配置分片的方式来控制任务的分割,就可以轻松的实现分布式集群环境下的定时任务管理了。是不是在复杂场景下,这种方式实现起来要比
@Scheduled
更方便呢?
本文的完整工程可以查看下面仓库中的
chapter7-2
目录:
3. 使用Elastic Job的分片配置
就是
任务执行速度时间过长
;同时,为了实现定时任务的高可用,还启动了很多任务实例,但
每个任务执行时候就一个实例在跑
,资源利用率不高。
所以,接下来我们就来继续介绍,使用Elastic Job的分片配置,来为任务执行加加速,资源利用抬抬高的目标!
-
结果:每个实例都在跑,只是 分支不同。
提高执行效率
动手试试
建议直接下载文末仓库中的
chapter7-2
工程,然后在这个基础上进行修改。当然,如果你对如何使用Elastic Job还不输入,那么先前往上一篇做个知识铺垫,再继续下面的内容!
第一步
:创建一个分片执行的任务
@Slf4j
@Service
public class MyShardingJob implements SimpleJob {
@Override
public void execute(ShardingContext context) {
switch (context.getShardingItem()) {
case 0:
log.info("分片1:执行任务");
break;
case 1:
log.info("分片2:执行任务");
break;
case 2:
log.info("分片3:执行任务");
break;
}
}
}
这里通过
switch
来判断当前任务上下文的sharding-item值来执行不同的分片任务。
- sharding-item的值取决于后面将要配置的分片总数,但注意是从0开始计数的。
- 这里仅采用了日志打印的方式,来展示分片效果,
-
真正实现业务逻辑的时候,
- 一定记得根据分片数量对执行任务也要做分片操作的设计。
- 比如:你可以根据批量任务的id求摩的方式来区分不同分片处理不同的数据,以避免重复执行而出现问题。
第二步
:在配置文件中,设置配置任务的实现类、执行表达式、以及将要重要测试的分片总数参数
elasticjob.jobs.my-sharding-job.elastic-job-class=com.didispace.chapter73.MyShardingJob
elasticjob.jobs.my-sharding-job.cron=0/5 * * * * ?
elasticjob.jobs.my-sharding-job.sharding-total-count=3
这里设置为3,所以任务会被分为3个分片,每个分片对应第一步中一个switch的分支。
运行与测试
单实例运行
我们可以看到,每间隔5秒,这个实例会打印这样的日志:
分片1:执行任务
2021-07-21 17:42:05.254 INFO 63478 --- [-sharding-job-3] com.didispace.chapter73.MyShardingJob
: 分片3:执行任务
: 分片2:执行任务
: 分片1:执行任务
: 分片2:执行任务
: 分片3:执行任务
每次任务都被拆分成了3个分片任务,就如我上文中所说的,每个分片对应一个switch的分支。由于当前情况下,我们只启动了一个实例,所以3个分片任务都被分配到了这个唯一的实例上。
双实例运行
接下来,我们再启动一个实例(注意使用-Dserver.port来改变不同的端口,不然本地会启动不成功)。此时,两个实例的日志出现了变化:
实例1的日志:
分片2:执行任务
分片2:执行任务
分片2:执行任务
实例2的日志:
分片1:执行任务
分片3:执行任务
分片1:执行任务
分片3:执行任务
随着实例数量的增加,可以看到分片的分配发生了变化。这也就意味着,当一个任务开始执行的时候,两个任务执行实例都被利用了起来,这样我们的任务执行和资源利用的效率就可以得到优化。
你也可以尝试再继续启动实例和关闭实例来观察任务的动态分配,怎么样?这样写定时任务是不是方便多了?
本文的完整工程可以查看下面仓库中的
chapter7-3
目录:
4. 使用Elastic Job的namespace防止任务名冲突
这篇
《使用Elastic Job实现定时任务》
文章编写测试定时任务的时候,报了类似下面的这个错误:
Job conflict with register center. The job 'my-simple-job' in register center's class is 'com.didispace.chapter72.MySimpleJob', your job class is 'com.didispace.chapter74.MySimpleJob'
根据错误消息
Job conflict with register center. The job 'my-simple-job' in register center's
,初步判断是ZooKeeper中存储的任务配置出现冲突:任务名一样,但实现类不同。
经过一番交流,原来他是使用公司测试环境的ZooKeeper来写的例子做测试,同时之前有同事(也是DD的读者)也写过类似的任务,因为配置的任务名称是拷贝的,所以出现了任务名称相对,但实现类不同的情况。
实际上,如果我们在一个大一些的团队做开发的时候,只要存在多系统的话,那么定时任务的重名其实是很有可能发生。比如:很多应用都可能存在一些定时清理某些资源的任务,就很可能起一样的名字,然后注册到同一个ZooKeeper,最后出现冲突。 那么有什么好办法来解决这个问题吗?
方法一:任务创建的统一管理
最原始的处理方法,就是集中的管理任务创建流程,比如:可以开一个Wiki页面,所有任务在这个页面上登记,每个人登记的时候,可以查一下想起的名字是否已经存在。如果存在了就再想一个名字,并做好登记。
这种方法很简单,也很好理解。但存在的问题是,当任务非常非常多的时候,这个页面内容就很大,维护起来也是非常麻烦的。
方法二:namespace属性来隔离
- 巧用Elastic Job的namespace属性来隔离任务名称
回忆一下之前第一篇写定时任务的时候,关于注册中心的配置是不是有下面两项:
elasticjob.reg-center.server-lists=localhost:2181
elasticjob.reg-center.namespace=didispace
第一个
elasticjob.reg-center.server-lists
不多说,就是ZooKeeper的访问地址。这里要重点讲的就是第二个参数
elasticjob.reg-center.namespace
。
其实在ZooKeeper中注册任务的时候,真正冲突的并不纯粹是因为任务名称,
- 而是namespace + 任务名称,全部一样,才会出现问题。
所以,我们只需要把每个应用创建的任务都隔离在自己独立的namespace里,那么是不是就不会和其他应用出现冲突了呢?
最后,我给出了下面这样的建议:
spring.application.name=chapter74
elasticjob.reg-center.server-lists=localhost:2181
elasticjob.reg-center.namespace=${spring.application.name}
即:将定时任务服务的
elasticjob.reg-center.namespace
设置为当前Spring Boot应用的名称一致
spring.application.name
。
通常,我们在规划各个Spring Boot应用的时候,都会做好唯一性的规划,这样未来注册到Eureka、Nacos等注册中心的时候,也可以保证唯一。
利用好这个唯一参数,也可以方便的帮我们把各个应用的定时任务也都隔离出来,也就解决了文章开头,我们所说的场景了。
本文的完整工程可以查看下面仓库中的
chapter7-4
目录:
5. 使用@Async实现异步调用
什么是“异步调用”?“异步调用”对应的是“同步调用”,同步调用指程序按照定义顺序依次执行,每一行程序都必须等待上一行程序执行完成之后才能执行;异步调用指程序在顺序执行时,不等待异步调用的语句返回结果就执行后面的程序。
同步调用
下面通过一个简单示例来直观的理解什么是同步调用:
定义Task类,创建三个处理函数分别模拟三个执行任务的操作,操作消耗时间随机取(10秒内)
@Slf4j
@Component
public class AsyncTasks {
public static Random random = new Random();
public void doTaskOne() throws Exception {
log.info("开始做任务一");
long start = System.currentTimeMillis();
Thread.sleep(random.nextInt(10000));
long end = System.currentTimeMillis();
log.info("完成任务一,耗时:" + (end - start) + "毫秒");
}
public void doTaskTwo() throws Exception {
log.info("开始做任务二");
long start = System.currentTimeMillis();
Thread.sleep(random.nextInt(10000));
long end = System.currentTimeMillis();
log.info("完成任务二,耗时:" + (end - start) + "毫秒");
}
public void doTaskThree() throws Exception {
log.info("开始做任务三");
long start = System.currentTimeMillis();
Thread.sleep(random.nextInt(10000));
long end = System.currentTimeMillis();
log.info("完成任务三,耗时:" + (end - start) + "毫秒");
}
}
在单元测试用例中,注入Task对象,并在测试用例中执行
doTaskOne
、
doTaskTwo
、
doTaskThree
三个函数。
@Slf4j
@SpringBootTest
public class Chapter75ApplicationTests {
@Autowired
private AsyncTasks asyncTasks;
@Test
public void test() throws Exception {
asyncTasks.doTaskOne();
asyncTasks.doTaskTwo();
asyncTasks.doTaskThree();
}
}
执行单元测试,可以看到类似如下输出:
开始做任务一
完成任务一,耗时:4865毫秒
开始做任务二
完成任务二,耗时:7063毫秒
开始做任务三
完成任务三,耗时:2076毫秒
任务一、任务二、任务三顺序的执行完了,换言之doTaskOne、doTaskTwo、doTaskThree三个函数顺序的执行完成。
异步调用
上述的同步调用虽然顺利的执行完了三个任务,但是可以看到执行时间比较长,若这三个任务本身之间不存在依赖关系,可以并发执行的话,同步调用在执行效率方面就比较差,可以考虑通过异步调用的方式来并发执行。
在Spring Boot中,我们只需要通过使用
@Async
注解就能简单的将原来的同步函数变为异步函数,Task类改在为如下模式:
使用@Async
@Slf4j
@Component
public class AsyncTasks {
public static Random random = new Random();
@Async
public void doTaskOne() throws Exception {
}
}
开启异步调用
为了让@Async注解能够生效,还需要在Spring Boot的主程序中配置@EnableAsync,如下所示:
@EnableAsync
@SpringBootApplication
public class Chapter75Application {
public static void main(String[] args) {
SpringApplication.run(Chapter75Application.class, args);
}
}
此时可以反复执行单元测试,您可能会遇到各种不同的结果,比如:
- 没有任何任务相关的输出
- 有部分任务相关的输出
- 乱序的任务相关的输出
-
原因是目前
doTaskOne
、
doTaskTwo
、
doTaskThree
三个函数的时候已经是异步执行了。主程序在异步调用之后,主程序并不会理会这三个函数是否执行完成了,由于没有其他需要执行的内容,所以程序就自动结束了,导致了不完整或是没有输出任务相关内容的情况。
注:
@Async
所修饰的函数不要定义为static类型,这样异步调用不会生效
异步回调
为了让
doTaskOne
、
doTaskTwo
、
doTaskThree
能正常结束,假设我们需要统计一下三个任务并发执行共耗时多少,这就需要等到上述三个函数都完成调动之后记录时间,并计算结果。
那么我们如何判断上述三个异步调用是否已经执行完成呢?我们需要使用
CompletableFuture<T>
来返回异步调用的结果,就像如下方式改造
doTaskOne
函数:
completedFuture方法创建返回
@Async
public CompletableFuture<String> doTaskOne() throws Exception {
log.info("开始做任务一");
long start = System.currentTimeMillis();
Thread.sleep(random.nextInt(10000));
long end = System.currentTimeMillis();
log.info("完成任务一,耗时:" + (end - start) + "毫秒");
return CompletableFuture.completedFuture("任务一完成");
}
按照如上方式改造一下其他两个异步函数之后,下面我们改造一下测试用例,让测试在等待完成三个异步调用之后来做一些其他事情。
join() 方法等待 执行完毕
@Autowired
private AsyncTasks asyncTasks;
@Test
public void test() throws Exception {
long start = System.currentTimeMillis();
CompletableFuture<String> task1 = asyncTasks.doTaskOne();
CompletableFuture<String> task2 = asyncTasks.doTaskTwo();
CompletableFuture<String> task3 = asyncTasks.doTaskThree();
CompletableFuture.allOf(task1, task2, task3).join();
long end = System.currentTimeMillis();
log.info("任务全部完成,总耗时:" + (end - start) + "毫秒");
}
看看我们做了哪些改变:
- 在测试用例一开始记录开始时间
-
在调用三个异步函数的时候,返回
CompletableFuture<String>
类型的结果对象 -
通过
CompletableFuture.allOf(task1, task2, task3).join()
实现三个异步任务都结束之前的阻塞效果 - 三个任务都完成之后,根据结束时间 – 开始时间,计算出三个任务并发执行的总耗时。
执行一下上述的单元测试,可以看到如下结果:
开始做任务三
开始做任务二
开始做任务一
完成任务二,耗时:6312毫秒
完成任务三,耗时:8465毫秒
完成任务一,耗时:8560毫秒
任务全部完成,总耗时:8590毫秒
可以看到,通过异步调用,让任务一、二、三并发执行,有效的减少了程序的总运行时间。
本文的完整工程可以查看下面仓库中
2.x
目录下的
chapter7-5
工程:
6. 配置@Async异步任务的线程池
上一篇我们介绍了
如何使用
@Async
注解来创建异步任务
,我可以用这种方法来实现一些并发操作,以加速任务的执行效率。但是,如果只是如前文那样直接简单的创建来使用,可能还是会碰到一些问题。存在有什么问题呢?先来思考下,下面的这个接口,通过异步任务加速执行的实现,是否存在问题或风险呢?
@RestController
public class HelloController {
@Autowired
private AsyncTasks asyncTasks;
@GetMapping("/hello")
public String hello() {
//如上
}
}
虽然,从单次接口调用来说,是没有问题的。但当接口被客户端频繁调用的时候,异步任务的数量就会大量增长:3 x n(n为请求数量),如果任务处理不够快,就很可能会出现内存溢出的情况。那么为什么会内存溢出呢?根本原因是由于Spring Boot默认用于异步任务的线程池是这样配置的:
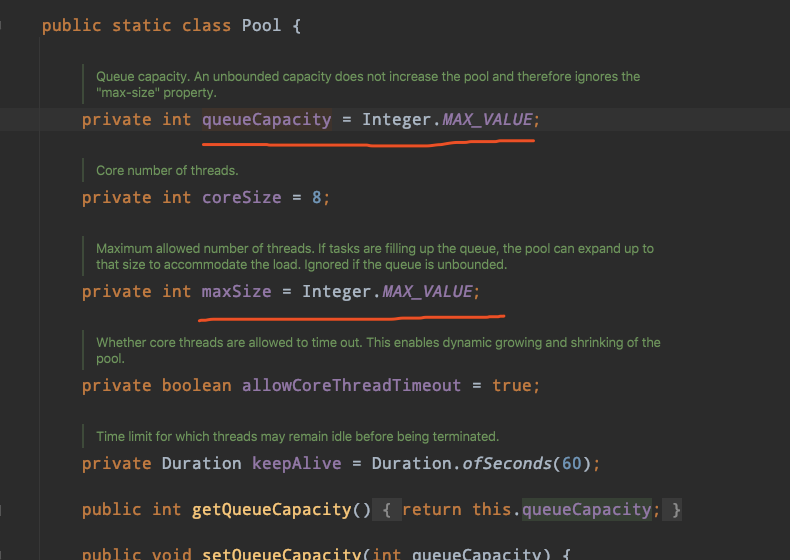
图中我标出的两个重要参数是需要关注的:
-
queueCapacity
:缓冲队列的容量,默认为INT的最大值(2的31次方-1)。 -
maxSize
:允许的最大线程数,默认为INT的最大值(2的31次方-1)。
所以,默认情况下,一般任务队列就可能把内存给堆满了。所以,我们真正使用的时候,还需要对异步任务的执行线程池做一些基础配置,以防止出现内存溢出导致服务不可用的问题。
配置默认线程池
默认线程池的配置很简单,只需要在配置文件中完成即可,主要有以下这些参数:
spring.task.execution.pool.core-size=2 #始化线程数,默认为8
spring.task.execution.pool.max-size=5 #最大线程数,默认为int最大值
spring.task.execution.pool.queue-capacity=10 #缓冲执行任务的队列,默认为int最大值
spring.task.execution.pool.keep-alive=60s #存活60秒 保持空闲的时间
spring.task.execution.pool.allow-core-thread-timeout=true #是否允许核心线程超时
spring.task.execution.shutdown.await-termination=false #是否等待剩余任务完成后才关闭应用
spring.task.execution.shutdown.await-termination-period= #等待剩余任务完成的最大时间
spring.task.execution.thread-name-prefix=task- #线程的前缀
具体配置含义如下:
capacity
英 /kəˈpæsəti/ 美 /kəˈpæsəti/ 全球(英国)
简明 牛津 新牛津 韦氏 柯林斯 例句 百科
n. 能力,才能;容积,容纳能力;职位,职责;功率,容积;生产量,生产能力
adj. 无虚席的,满场的
复数 capacities
termination
英 /ˌtɜːmɪˈneɪʃ(ə)n/ 美 /ˌtɜːrmɪˈneɪʃn/ 全球(英国)
简明 牛津 新牛津 韦氏 例句 百科
n. 人工流产;结束,终止;<美>解聘,解雇;<美>暗杀;词尾(尤指屈折变化或派生词的词尾);<古>结局
period
英 /ˈpɪəriəd/ 美 /ˈpɪriəd/ 全球(美国)
简明 牛津 新牛津 韦氏 柯林斯 例句 百科
n. 一段时间,时期;(人生或国家历史的)阶段,时代;(地质年代划分的)纪;课时,节;(练习、训练或学习的)时段;(体育比赛的)局;<美>句号,句点;(物理)(振动或循环的)周期;(天文)自转(或公转)周期;(数学)(周期函数的)周期;(化学)周期元素;(修辞)完整句;(乐)乐段,乐节
adj. 具有某个时代特征的
adv. <美>到此为止,不再说了
具体配置含义如下:
-
spring.task.execution.pool.core-size
:线程池创建时的初始化线程数,默认为8 -
spring.task.execution.pool.max-size
:线程池的最大线程数,默认为int最大值 -
spring.task.execution.pool.queue-capacity
:用来缓冲执行任务的队列,默认为int最大值 -
spring.task.execution.pool.keep-alive
:线程终止前允许保持空闲的时间 -
spring.task.execution.pool.allow-core-thread-timeout
:是否允许核心线程超时 -
spring.task.execution.shutdown.await-termination
:是否等待剩余任务完成后才关闭应用 -
spring.task.execution.shutdown.await-termination-period
:等待剩余任务完成的最大时间 -
spring.task.execution.thread-name-prefix
:线程名的前缀,设置好了之后可以方便我们在日志中查看处理任务所在的线程池
动手试一试
默认8个线程,同时执行
由于默认线程池的核心线程数是8,所以3个任务会同时开始执行,日志输出是这样的:
开始做任务二
开始做任务三
开始做任务一
完成任务二,耗时:672毫秒
完成任务三,耗时:4677毫秒
完成任务一,耗时:5624毫秒
任务全部完成,总耗时:5653毫秒
核心2个,缓冲10个,每次执行2个
接着,可以尝试在配置文件中增加如下的线程池配置
spring.task.execution.pool.core-size=2
spring.task.execution.pool.max-size=5
spring.task.execution.pool.queue-capacity=10
日志输出的顺序会变成如下的顺序:
开始做任务一
开始做任务二
完成任务一,耗时:2439毫秒
开始做任务三
完成任务二,耗时:5867毫秒
完成任务三,耗时:7894毫秒
任务全部完成,总耗时:10363毫秒
- 任务一和任务二会马上占用核心线程,任务三进入队列等待
- 任务一完成,释放出一个核心线程,任务三从队列中移出,并占用核心线程开始处理
注意:这里可能有的小伙伴会问,最大线程不是5么,为什么任务三是进缓冲队列,不是创建新线程来处理吗?
这里要理解缓冲队列与最大线程间的关系:
- 只有在缓冲队列 满了之后才会 申请超过核心线程数的线程 来进行处理。
- 所以,这里只有缓冲队列中10个任务满了,再来第11个任务的时候,才会在线程池中创建第三个线程来处理。
- 读者可以自己调整下参数,或者调整下单元测试来验证这个逻辑。
本文的完整工程可以查看下面仓库中
2.x
目录下的
chapter7-6
工程:
4个任务 核心2个,只执行2个
如:
spring.task.execution.pool.core-size=2
spring.task.execution.pool.max-size=5
spring.task.execution.pool.queue-capacity=2
#开四个,只能同时执行2个,会有2个排队
CompletableFuture.allOf(task1, task2, task3,task4).join();
开始做任务一
开始做任务二
完成任务一,耗时:598毫秒
开始做任务三
核心满了,触发最大线程数
capacity:用来缓冲执行任务的队列,改为1,能同时执行3个。因为缓冲队列满了,会创建线程(<最大的线程5个)
开始做任务一
开始做任务二
开始做任务四
完成任务四,耗时:1357毫秒
7. 如何隔离@Async异步任务的线程池
过
上一篇:配置@Async异步任务的线程池
的介绍,你应该已经了解到异步任务的执行背后有一个线程池来管理执行任务。为了控制异步任务的并发不影响到应用的正常运作,我们必须要对线程池做好相应的配置,防止资源的过渡使用。除了默认线程池的配置之外,还有一类场景,也是很常见的,那就是多任务情况下的线程池隔离。
什么是线程池的隔离,为什么要隔离
可能有的小伙伴还不太了解
什么是线程池的隔离,为什么要隔离
?。所以,我们先来看看下面的场景案例:
@RestController
public class HelloController {
@Autowired
private AsyncTasks asyncTasks;
@GetMapping("/api-1")
public String taskOne() {
CompletableFuture<String> task1 = asyncTasks.doTaskOne("1");
CompletableFuture<String> task2 = asyncTasks.doTaskOne("2");
CompletableFuture<String> task3 = asyncTasks.doTaskOne("3");
CompletableFuture.allOf(task1, task2, task3).join();
return "";
}
@GetMapping("/api-2")
public String taskTwo() {
CompletableFuture<String> task1 = asyncTasks.doTaskTwo("1");
CompletableFuture<String> task2 = asyncTasks.doTaskTwo("2");
CompletableFuture<String> task3 = asyncTasks.doTaskTwo("3");
CompletableFuture.allOf(task1, task2, task3).join();
return "";
}
上面的代码中,有两个API接口,这两个接口的具体执行逻辑中都会把执行过程拆分为三个异步任务来实现。
好了,思考一分钟,想一下。如果这样实现,会有什么问题吗?
上面这段代码,在API请求并发不高,同时如果每个任务的处理速度也够快的时候,是没有问题的。
但如果并发上来或其中某几个处理过程扯后腿了的时候。这两个提供不相干服务的接口可能会互相影响。
- 比如:假设当前线程池配置的最大线程数有2个,这个时候/api-1接口中task1和task2处理速度很慢,阻塞了;
- 那么此时,当用户调用api-2接口的时候,这个服务也会阻塞!
造成这种现场的原因是:默认情况下,所有用
@Async
创建的异步任务都是共用的一个线程池,
- 所以当有一些异步任务碰到性能问题的时候,是会直接影响其他异步任务的。
为了解决这个问题,我们就需要对异步任务做一定的线程池隔离,让不同的异步任务互不影响。
不同异步任务配置不同线程池
下面,我们就来实际操作一下!
第一步
:初始化多个线程池,比如下面这样:
配置线程池
@EnableAsync
@Configuration
public class TaskPoolConfig {
@Bean
public Executor taskExecutor1() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
//核心 最大 缓冲 存活 线程前缀
executor.setCorePoolSize(2);
executor.setMaxPoolSize(2);
executor.setQueueCapacity(10);
executor.setKeepAliveSeconds(60);
executor.setThreadNamePrefix("executor-1-");
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
return executor;
}
@Bean
public Executor taskExecutor2() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(2);
executor.setMaxPoolSize(2);
executor.setQueueCapacity(10);
executor.setKeepAliveSeconds(60);
executor.setThreadNamePrefix("executor-2-");
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
return executor;
}
}
rejected
英 /rɪˈdʒektɪd/ 美 /rɪˈdʒektɪd/ 全球(美国)
简明 柯林斯 例句 百科
v. 拒绝,驳回;不同意;不录用;不用,不出版;嫌弃,厌弃;排斥(移植器官);不够关心,慢待(reject 的过去式和过去分词)
adj. 被拒绝的
policy
英 /ˈpɒləsi/ 美 /ˈpɑːləsi/ 全球(美国)
n. 政策,方针;(处事) 原则,策略;保险单
注意:这里特地用
executor.setThreadNamePrefix
设置了线程名的前缀,这样可以方便观察后面具体执行的顺序。
第二步
:创建异步任务,并指定要使用的线程池名称
使用线程池
@Slf4j
@Component
public class AsyncTasks {
public static Random random = new Random();
@Async("taskExecutor1")
public CompletableFuture<String> doTaskOne(String taskNo) throws Exception {
log.info("开始任务:{}", taskNo);
long start = System.currentTimeMillis();
Thread.sleep(random.nextInt(10000));
long end = System.currentTimeMillis();
log.info("完成任务:{},耗时:{} 毫秒", taskNo, end - start);
return CompletableFuture.completedFuture("任务完成");
}
@Async("taskExecutor2")
public CompletableFuture<String> doTaskTwo(String taskNo) throws Exception {
log.info("开始任务:{}", taskNo);
long start = System.currentTimeMillis();
Thread.sleep(random.nextInt(10000));
long end = System.currentTimeMillis();
log.info("完成任务:{},耗时:{} 毫秒", taskNo, end - start);
return CompletableFuture.completedFuture("任务完成");
}
}
这里
@Async
注解中定义的
taskExecutor1
和
taskExecutor2
就是线程池的名字。由于在第一步中,我们没有具体写两个线程池Bean的名称,所以默认会使用方法名,也就是
taskExecutor1
和
taskExecutor2
。
第三步
:写个单元测试来验证下,比如下面这样:
编写测试方法
@Slf4j
@SpringBootTest
public class Chapter77ApplicationTests {
@Autowired
private AsyncTasks asyncTasks;
@Test
public void test() throws Exception {
long start = System.currentTimeMillis();
// 线程池1
CompletableFuture<String> task1 = asyncTasks.doTaskOne("1");
CompletableFuture<String> task2 = asyncTasks.doTaskOne("2");
CompletableFuture<String> task3 = asyncTasks.doTaskOne("3");
// 线程池2
CompletableFuture<String> task4 = asyncTasks.doTaskTwo("4");
CompletableFuture<String> task5 = asyncTasks.doTaskTwo("5");
CompletableFuture<String> task6 = asyncTasks.doTaskTwo("6");
// 一起执行
CompletableFuture.allOf(task1, task2, task3, task4, task5, task6).join();
long end = System.currentTimeMillis();
log.info("任务全部完成,总耗时:" + (end - start) + "毫秒");
}
}
在上面的单元测试中,一共启动了6个异步任务,前三个用的是线程池1,后三个用的是线程池2。
先不执行,根据设置的核心线程2和最大线程数2,来分析一下,大概会是怎么样的执行情况?
- 线程池1的三个任务,task1和task2会先获得执行线程,然后task3因为没有可分配线程进入缓冲队列
- 线程池2的三个任务,task4和task5会先获得执行线程,然后task6因为没有可分配线程进入缓冲队列
- 任务task3会在task1或task2完成之后,开始执行
- 任务task6会在task4或task5完成之后,开始执行
[ executor-1-1] com.didispace.chapter77.AsyncTasks : 开始任务:1
[ executor-2-2] com.didispace.chapter77.AsyncTasks : 开始任务:5
[ executor-2-1] com.didispace.chapter77.AsyncTasks : 开始任务:4
[ executor-1-2] com.didispace.chapter77.AsyncTasks : 开始任务:2
[ executor-2-1] com.didispace.chapter77.AsyncTasks : 完成任务:4,耗时:4532 毫秒
[ executor-2-1] com.didispace.chapter77.AsyncTasks : 开始任务:6
[ executor-1-2] com.didispace.chapter77.AsyncTasks : 完成任务:2,耗时:6890 毫秒
[ executor-1-2] com.didispace.chapter77.AsyncTasks : 开始任务:3
[ executor-2-2] com.didispace.chapter77.AsyncTasks : 完成任务:5,耗时:7523 毫秒
[ executor-1-2] com.didispace.chapter77.AsyncTasks : 完成任务:3,耗时:1579 毫秒
[ executor-1-1] com.didispace.chapter77.AsyncTasks : 完成任务:1,耗时:9178 毫秒
[ executor-2-1] com.didispace.chapter77.AsyncTasks : 完成任务:6,耗时:8212 毫秒
[ main] c.d.chapter77.Chapter77ApplicationTests : 任务全部完成,总耗时:12762毫秒
chapter7-7
工程:
8. 配置线程池的拒绝策略
通过之前三篇关于Spring Boot异步任务实现的博文,我们分别学会了
用@Async创建异步任务
、
为异步任务配置线程池
、
使用多个线程池隔离不同的异步任务
。
假设,线程池配置为核心线程数2、最大线程数2、缓冲队列长度2。此时,有5个异步任务同时开始,会发生什么?
场景重现
我们先来把上面的假设用代码实现一下:
第一步
:创建Spring Boot应用,根据上面的假设写好线程池配置。
executor.setCorePoolSize(2);
executor.setMaxPoolSize(2);
executor.setQueueCapacity(2);
executor.setKeepAliveSeconds(60);
executor.setThreadNamePrefix("executor-1-");
第二步
:用
@Async
注解实现一个部分任务
第三步
:编写测试用例
@Slf4j
@SpringBootTest
public class Chapter78ApplicationTests {
@Autowired
private AsyncTasks asyncTasks;
@Test
public void test2() throws Exception {
long start = System.currentTimeMillis();
// 线程池1
CompletableFuture<String> task1 = asyncTasks.doTaskOne("1");
CompletableFuture<String> task2 = asyncTasks.doTaskOne("2");
CompletableFuture<String> task3 = asyncTasks.doTaskOne("3");
CompletableFuture<String> task4 = asyncTasks.doTaskOne("4");
CompletableFuture<String> task5 = asyncTasks.doTaskOne("5");
// 一起执行
CompletableFuture.allOf(task1, task2, task3, task4, task5).join();
long end = System.currentTimeMillis();
log.info("任务全部完成,总耗时:" + (end - start) + "毫秒");
}
}
执行一下,可以类似下面这样的日志信息:
// 线程池配置:core-2,max-2,queue=2,同时有5个任务,出现下面异常:
org.springframework.core.task.TaskRejectedException: Executor [java.util.concurrent.ThreadPoolExecutor@59901c4d[Running, pool size = 2,
active threads = 0, queued tasks = 2, completed tasks = 4]] did not accept task: java.util.concurrent.CompletableFuture$AsyncSupply@408e96d9
可以很明确的知道,第5个任务因为超过了执行线程+缓冲队列长度,而被拒绝了。
所有,默认情况下,线程池的拒绝策略是:当线程池队列满了,会丢弃这个任务,并抛出异常。
配置拒绝策略
虽然线程池有默认的拒绝策略,但实际开发过程中,有些业务场景,直接拒绝的策略往往并不适用,有时候我们可能会选择
- 舍弃最早开始执行而未完成的任务、也可能会选择舍弃刚开始执行而未完成的任务等更贴近业务需要的策略。
- 所以,为线程池配置其他拒绝策略或自定义拒绝策略是很常见的需求,那么这个要怎么实现呢?
下面就来具体说说今天的正题,如何为线程池配置拒绝策略、如何自定义拒绝策略。
看下面这段代码的最后一行,
setRejectedExecutionHandler
方法就是为线程池设置拒绝策略的方法:
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
//...其他线程池配置
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.AbortPolicy());
abort
英 /əˈbɔːt/ 美 /əˈbɔːrt/ 全球(英国)
简明 牛津 新牛津 韦氏 柯林斯 例句 百科
v. (使)流产,堕(胎);(由于问题或故障)中止,使夭折;(胚胎器官,有机体)发育不全,败育
4种拒绝策略
在
ThreadPoolExecutor
中提供了4种线程的策略可以供开发者直接使用,你只需要像下面这样设置即可:
// AbortPolicy策略 线程池队列满了丢掉,抛异常
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.AbortPolicy());
// DiscardPolicy策略 直接丢掉
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.DiscardPolicy());
// DiscardOldestPolicy策略 最早进入队列的任务删掉腾出空间,再尝试 (阻塞队列里面排队着的 第一个任务删除)
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.DiscardOldestPolicy());
// CallerRunsPolicy策略 添加到线程池失败,那么主线程会自己去执行该任务
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
这四个策略对应的含义分别是:
- AbortPolicy策略:默认策略,如果线程池队列满了丢掉这个任务并且抛出RejectedExecutionException异常。
- DiscardPolicy策略:如果线程池队列满了,会直接丢掉这个任务并且不会有任何异常。
- DiscardOldestPolicy策略:如果队列满了,会将最早进入队列的任务删掉腾出空间,再尝试加入队列。
- CallerRunsPolicy策略:如果添加到线程池失败,那么主线程会自己去执行该任务,不会等待线程池中的线程去执行。
而如果你要自定义一个拒绝策略,那么可以这样写:
executor.setRejectedExecutionHandler(new RejectedExecutionHandler() {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
// 拒绝策略的逻辑
}
});
当然如果你喜欢用Lamba表达式,也可以这样写:
executor.setRejectedExecutionHandler((r, executor1) -> {
// 拒绝策略的逻辑
});
chapter7-8
工程:
9. 默认日志管理与Logback配置详解
Spring Boot在所有内部日志中使用
Commons Logging
,但是对底层日志的实现是开放的。
在Spring Boot生态中,为
Java Util Logging
、
Log4J2
和
Logback
这些常见的日志框架都提供了自动化配置组件,每种Logger都可以通过配置在控制台或者文件中输出日志内容。
- 默认情况下,当我们使用各种Starter的时候,会使用Logback来实现日志管理。
如何记日志
在介绍写日志的方式有很多,这里就不对各种方式做罗列了,只讲DD用得最多的方式!
首先,在代码层面,我们不纠结到底用默认的Logback还是Log4j,而是直接用:
Slf4j
。
为什么不用管具体用Logback还是Log4j就可以去写代码呢?这个就是使用Slf4j好处,为什么是Slf4j?
- 英文全称:Simple Logging Facade for Java,即:简单日志门面,它并不是一个具体的日志解决方案,实际工作的还是Logback或Log4j这样的日志框架。
- Slf4j就是23种设计模式中门面模式的典型应用案例。通过Slf4j这样一个门面的抽象存在,让我们在写代码的之后,只依赖这个抽象的日志操作,而具体的实现会在Slf4j门面调用的时候委托给具体的实现。
- 门面模式 外观模式
比如下面的就是一个简单的日志记录例子:
@Slf4j
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
log.error("Hello World");
log.warn("Hello World");
log.info("Hello World");
log.debug("Hello World");
log.trace("Hello World");
}
}
注意:这里我们通过在
pom.xml
中引入了
Lombok
,然后使用
@Slf4j
声明引入Slf4j的
log
日志记录对象,之后就可以轻松的用它来日志了。
而这个日志具体是如何写到控制台或者文件的,则有Spring Boot项目中引入了什么具体的日志框架决定,默认情况下就是Logback。
日志元素
启动任意一个Spring Boot项目,我们都可以在控制台看到很多日志信息,比如下面这样的一条日志:

日志的输出内容中一共有7种元素,具体如下:
- 时间日期:精确到毫秒
- 日志级别:ERROR, WARN, INFO, DEBUG or TRACE
- 进程ID
-
分隔符:
---
标识实际日志的开始 - 线程名:方括号括起来(可能会截断控制台输出)
- Logger名:通常使用源代码的类名
- 日志内容
日志输出
在Spring Boot应用中,日志会默认会输出到控制台中,默认的输出日志级别包含:
ERROR
、
WARN
和
INFO
,我们可以帮上面写的Hello World例子跑起来,就可以验证这样的默认设定:
2021-12-28 17:37:25.578 INFO 65136 --- [ main] com.didispace.chapter81.Application : Started Application in 2.695 seconds (JVM running for 3.957)
2021-12-28 17:37:25.579 ERROR 65136 --- [ main] com.didispace.chapter81.Application : Hello World
2021-12-28 17:37:25.579 WARN 65136 --- [ main] com.didispace.chapter81.Application : Hello World
2021-12-28 17:37:25.579 INFO 65136 --- [ main] com.didispace.chapter81.Application : Hello World
开启DEBUG日志
我们可以通过两种方式切换至
DEBUG
级别:
第一种
:在运行命令后加入
--debug
标志,如:
$ java -jar myapp.jar --debug
第二种
:在配置文件
application.properties
中配置
debug=true
这里开启的DEBUG日志,仅影响核心Logger,包含嵌入式容器、hibernate、spring等这些框架层面的会输出更多内容,
但是你自己应用的日志并不会输出为DEBUG级别,从下面的截图中我们就可以看到,
- 我们自己编写的debug级别的Hello World并没有输出。(Debug 和 trace 没打印)
2022-04-24 09:37:34.755 ERROR 5104 --- [ main] c.d.chapter81.Chapter81Application : Hello World
2022-04-24 09:37:34.755 WARN 5104 --- [ main] c.d.chapter81.Chapter81Application : Hello World
2022-04-24 09:37:34.755 INFO 5104 --- [ main] c.d.chapter81.Chapter81Application : Hello World
日志配置
下面介绍一些常用的日志配置,以帮助我们更好的管理好日志内容。
多彩输出
如果你的终端支持ANSI,设置彩色输出会让日志更具可读性。通过在
application.properties
中设置
spring.output.ansi.enabled
参数来支持,该参数有三个选项:
- NEVER:禁用ANSI-colored输出
- DETECT:会检查终端是否支持ANSI,是的话就采用彩色输出(默认项)
- ALWAYS:总是使用ANSI-colored格式输出,若终端不支持的时候,会有很多干扰信息,不推荐使用
注意:Spring Boot 1.x的时候,默认值为NEVER,2.x之后默认为DETECT,所以看我们上面的截图,默认就已经带有颜色了。所以如果是Spring Boot 2.x版本用户的话,这个基本就不用去修改了。
文件输出
Spring Boot默认配置只会输出到控制台,并不会记录到文件中,但是我们通常生产环境使用时都需要以文件方式记录。
若要增加文件输出,需要在配置文件
application.properties
配置几个参数,比如这样:
logging.file.name=run.log
logging.file.path=./ #当前路径 ,就是和 src一个路径。src下面 会创建run.log
-
logging.file.name
:设置文件名 -
logging.file.path
:设置文件路径
注意:这里跟1.x版本有区别,1.x的时候分别对应的参数为
logging.file
和
logging.path
。
文件滚动
一直把日志输出在一个文件里显然是不合适的,任何一个日志框架都会为此准备日志文件的滚动配置。由于本篇将默认配置,所以就是Logback的配置,具体有这几个:
-
logging.logback.rollingpolicy.file-name-pattern
:用于创建日志档案的文件名模式。 -
logging.logback.rollingpolicy.clean-history-on-start
:应用程序启动时是否对进行日志归档清理,默认为false,不清理 -
logging.logback.rollingpolicy.max-history
:要保留的最大归档日志文件数量,默认为7个 -
logging.logback.rollingpolicy.max-file-size
:归档前日志文件的最大尺寸,默认为10MB -
logging.logback.rollingpolicy.total-size-cap
:日志档案在被删除前的最大容量,默认为0B
logging.logback.rollingpolicy.clean-history-on-start=false
logging.logback.rollingpolicy.file-name-pattern=
logging.logback.rollingpolicy.max-history=7
logging.logback.rollingpolicy.max-file-size=10MB
logging.logback.rollingpolicy.total-size-cap=0B
级别控制
如果要对各个Logger做一些简单的输出级别控制,那么只需要在
application.properties
中进行配置就能完成。
配置格式:
logging.level.*=LEVEL
-
logging.level
:日志级别控制前缀,
*
为包名或Logger名 -
LEVEL
:选项TRACE, DEBUG, INFO, WARN, ERROR, FATAL, OFF
举例:
-
logging.level.com.didispace=DEBUG
:
com.didispace
包下所有class以DEBUG级别输出- 就是:src main java 下的 com.didispace
-
logging.level.root=WARN
:root日志以WARN级别输出- 大概就是 项目中所有的日志 都warn吧
做了这样的配置之后,可以再执行下上面的程序,原本debug级别的Hello World就可以被成功输出了。
自定义日志配置
由于日志服务一般都在ApplicationContext创建前就初始化了,它并不是必须通过Spring的配置文件控制。因此通过系统属性和传统的Spring Boot外部配置文件依然可以很好的支持日志控制和管理。
根据不同的日志系统,你可以按如下规则组织配置文件名,就能被正确加载:
-
Logback:
logback-spring.xml
,
logback-spring.groovy
,
logback.xml
,
logback.groovy
-
Log4j2:
log4j2-spring.xml
,
log4j2.xml
-
JDK (Java Util Logging):
logging.properties
Spring Boot官方推荐优先使用带有
-spring
的文件名作为你的日志配置(如使用
logback-spring.xml
,而不是
logback.xml
)
自定义输出格式
在Spring Boot中可以通过在
application.properties
配置如下参数控制输出格式:
- logging.pattern.console:定义输出到控制台的样式(不支持JDK Logger)
- logging.pattern.file:定义输出到文件的样式(不支持JDK Logger)
chapter8-1
工程:
10. 使用Log4j2记录日志
接下来我们要讲是前段时间爆出核弹漏洞的Log4j2。虽然出了漏洞,让很多小伙伴痛苦了1-2周(加班),但不可否认的是Log4j2依然是目前性能最好的日志框架。所以,当Logback性能上无法支撑的时候,替换使用Log4j2还是最为快速便捷的方法。下面,我们就来学习一下如何在Spring Boot 2.x版本中,替换Logback,使用Log4j2记录日志。
动手试一试
第一步
:在
pom.xml
中引入Log4j2的Starter依赖
spring-boot-starter-log4j2
,同时排除默认引入的
spring-boot-starter-logging
,比如下面这样:
引入pom
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<exclusions>
<exclusion>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-logging</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-log4j2</artifactId>
</dependency>
properties文件 配置
第二步
:在配置文件
application.properties
中,通过
logging.config
配置指定log4j2的配置文件位置,比如下面这样:
logging.config=classpath:log4j2.xml
log4j2.xml
第三步
:在resource目录下新建
log4j2.xml
(这里不绝对,根据第二步中配置的内容来创建),然后加入log4j2的日志配置,比如,下面这样:
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="INFO">
<Appenders>
<Console name="Console" target="SYSTEM_OUT">
<PatternLayout pattern="%d{HH:mm:ss.SSS} [%t] %-5level %logger{36} - %msg%n"/>
</Console>
</Appenders>
<Loggers>
<Root level="INFO">
<AppenderRef ref="Console"/>
</Root>
</Loggers>
</Configuration>
主要是方便大家理解如何把log4j2引入Spring Boot,对于log4j2如何配置这里不做详细介绍,所以这里就放个简单配置让程序跑起来即可。如果想深入了解log4j2的配置,可以
点击这里查看
常见问题
可能有小伙伴会问,之前不是推荐大家用Slf4j来记录日志,隔离了具体实现的日志框架么?那我怎么知道这一顿操作之后,真的已经用上Log4j2了呢?
这个其实很好判断,大家只需要在用到日志的地方,加个端点,Debug跑起来,观察下log对象就可以了,比如:
logback
下面这个是使用默认Logback的情况:
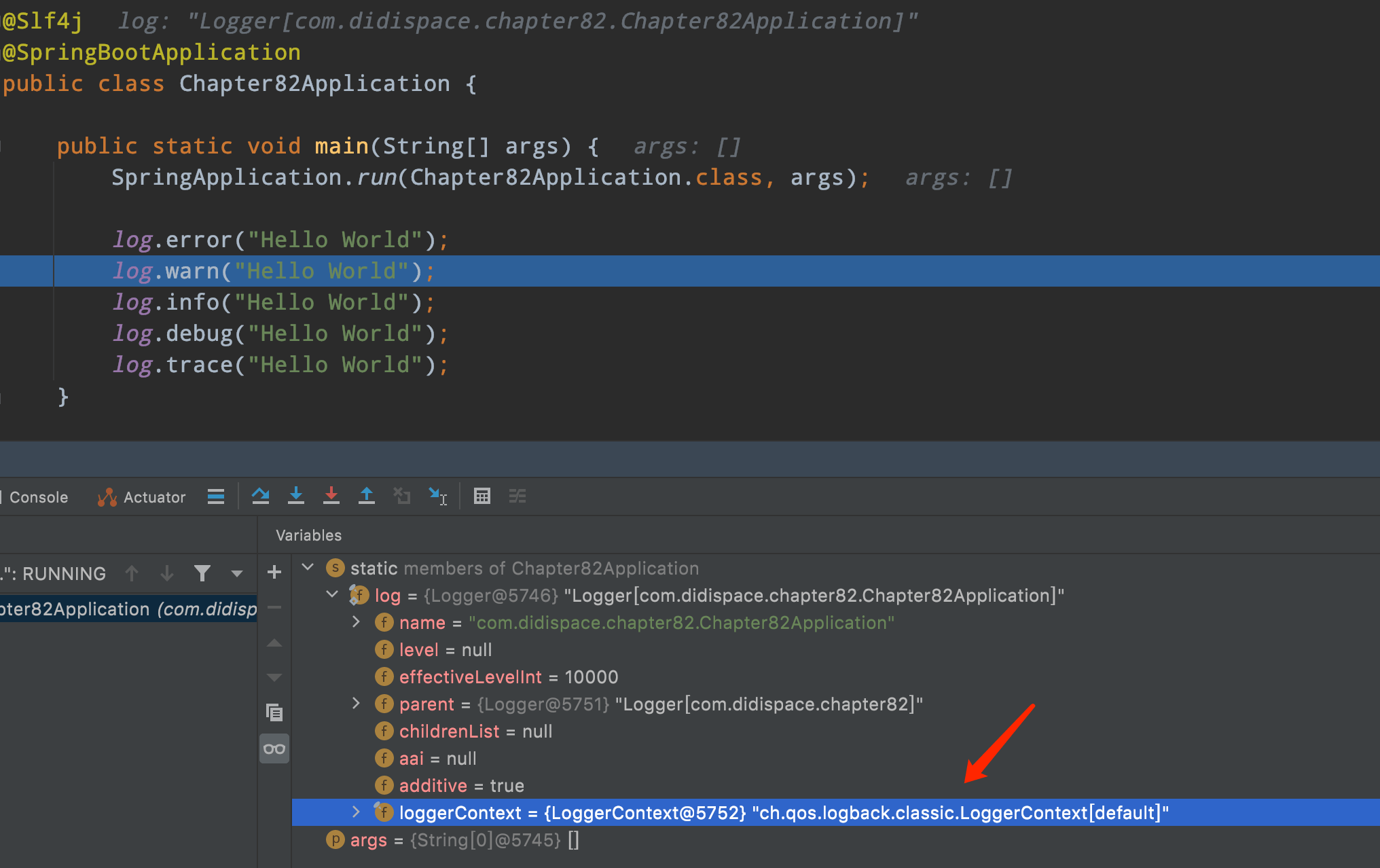
log4j2
下面这个是使用Log4j2的情况
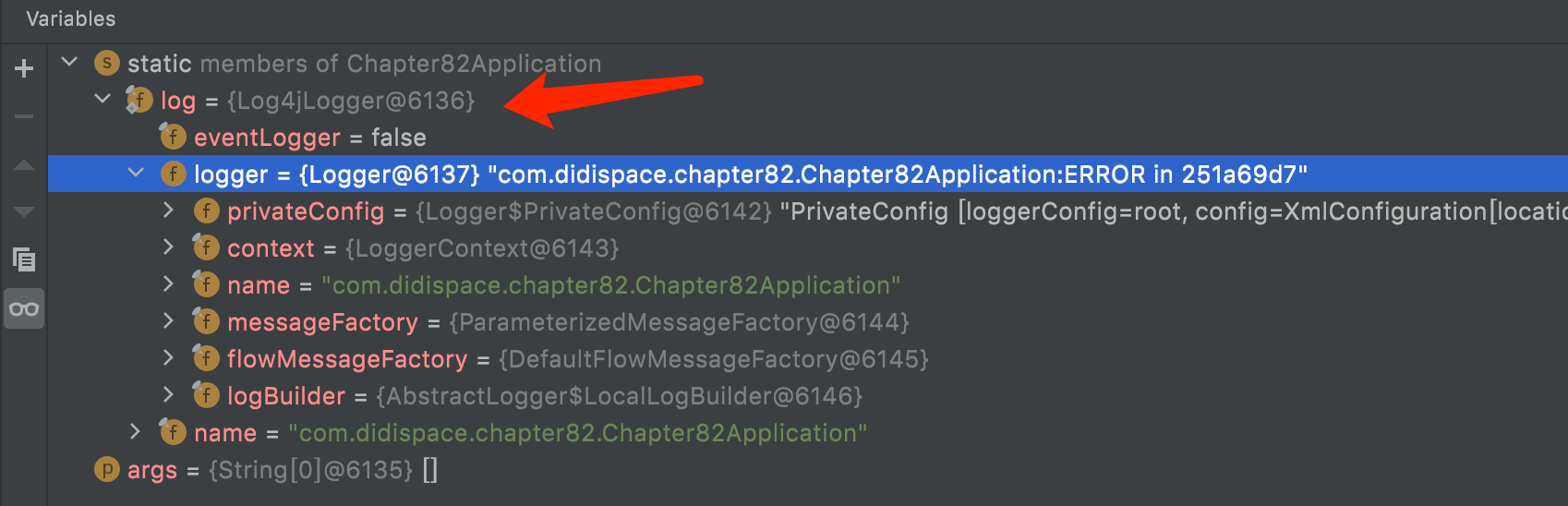
最后,因为之前Log4j2有过很大的漏洞问题,大家一定要用最新版本哦!
安全起见,建议您至少要用2.17.0以上的版本(如果用的Spring Boot 2.6.2+,那已经是2.17.0了,不需要担心)。当然,目前最新已经到2.17.1,您也可以自己升级到2.17.1来使用,如何升级呢?还是按照
这篇文章
介绍的操作即可。
chapter8-2
工程:
11. 使用tinylog记录日志
tinylog
,与其他各种tiny开头的东西一样,是一个轻量级的开源日志解决方案。它本身只包含两个JAR文件(一个用于API,另一个用于实现),没有任何外部依赖关系。两个JAR文件的总大小只有178KB。
虽然是一个轻量级级别方案,但我们常用的基本日志管理功能都非常完备,它拥有与其他热门日志框架类似的API设计、多种可配置的日志输出选项、性能方面也是非常的出彩(这是官方给出的
Benchmark
)。
整合tinylog
通过之前
Spring Boot 2.x基础教程:使用log4j2记录日志
一文的学习,回忆一下,整合其他日志框架,是不是可以总结为这样几步:
- 排除Spring Boot默认日志框架依赖
- 引入要使用的日志框架依赖
- 加入新日志框架的配置文件
好了,我们就按这个步骤来实战一下:
第一步:排除Spring Boot默认日志框架依赖
- 如上
- web下排除:spring-boot-starter-logging
第二步:引入tinylog的依赖
<properties>
<tinylog.version>2.4.1</tinylog.version>
</properties>
<dependencies>
<dependency>
<groupId>org.tinylog</groupId>
<artifactId>tinylog-api</artifactId> api
<version>${tinylog.version}</version>
</dependency>
<dependency>
<groupId>org.tinylog</groupId>
<artifactId>tinylog-impl</artifactId> impl
<version>${tinylog.version}</version>
</dependency>
<dependency>
<groupId>org.tinylog</groupId>
<artifactId>slf4j-tinylog</artifactId> slf4j-tiny
<version>${tinylog.version}</version>
</dependency>
<dependency>
<groupId>org.tinylog</groupId>
<artifactId>jcl-tinylog</artifactId> jcl-tiny
<version>${tinylog.version}</version>
</dependency>
<dependency>
<groupId>org.tinylog</groupId>
<artifactId>log4j1.2-api</artifactId> log4j1.2-api
<version>${tinylog.version}</version>
</dependency>
</dependencies>
测试与验证
到这里,基本整合已经完成了。我们不着急去对tinylog做详细配置,先验证下到这里是否都已经正确。跟之前的日志整合例子一样,写个主类打印下各个级别的日志。
@Slf4j
log.error("Hello World");
这里用了lombok的
@Slf4j
,如果还不了解的建议读一下这篇:
Lombok:让JAVA代码更优雅
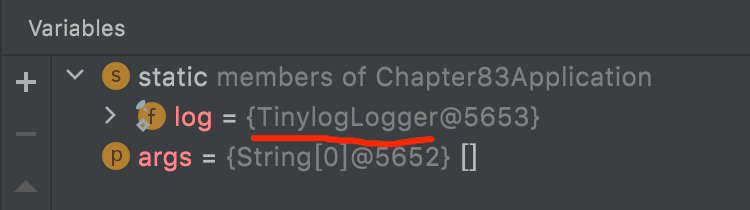
过debug,我们可以看到此时的log已经是
TinylogLogger
了
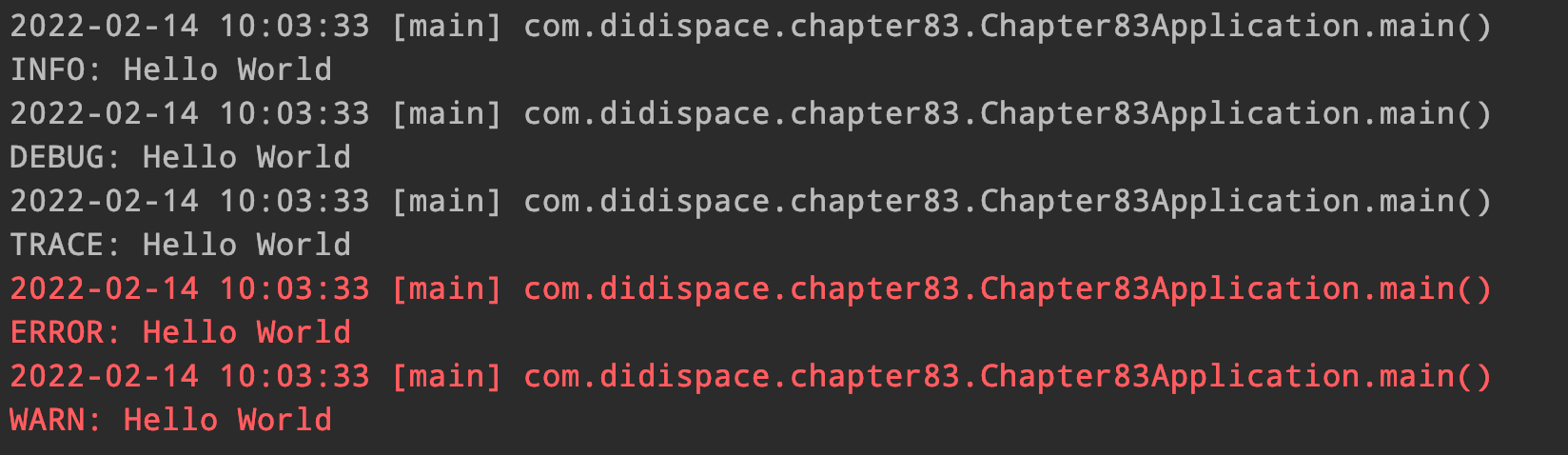
第三步:加入tinylog的配置文件
在resources目录下创建文件:tinylog.properties
加入下面的配置:
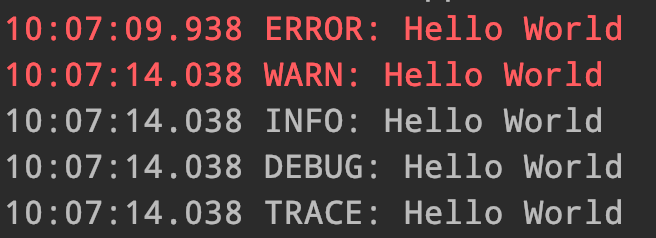
writer=console
writer.format={date: HH:mm:ss.SSS} {level}: {message}
重新运行测试,控制台输出是不是好看一些了
更多配置,比如:文件输出、级别控制等这里就不详细说了,大家可以查看
官方文档
,基本上与其他框架都是类似的,很容易配置。
chapter8-3
工程:
12. Spring Boot自定义Banner
接下来我们就来介绍一下这个轻松愉快的自定义banner功能。实现的方式非常简单,我们只需要在Spring Boot工程的
/src/main/resources
目录下创建一个
banner.txt
文件,然后将ASCII字符画复制进去,就能替换默认的banner了。比如上图中的输出,就采用了下面的
banner.txt
内容:
${AnsiColor.BRIGHT_GREEN}
## ## ### ######## ######## ## ## ## ## ######## ## ## ## ## ######## ### ########
## ## ## ## ## ## ## ## ## ## ### ## ## ## ## ## ## ## ## ## ## ## ##
## ## ## ## ## ## ## ## #### #### ## ## ## ## ## #### ## ## ## ## ##
######### ## ## ######## ######## ## ## ## ## ###### ## ## ## ## ###### ## ## ########
## ## ######### ## ## ## ## #### ## ## ## ## ## ## ######### ## ##
## ## ## ## ## ## ## ## ### ## ## ## ## ## ## ## ## ## ##
## ## ## ## ## ## ## ## ## ######## ### ### ## ######## ## ## ## ##
${AnsiColor.BRIGHT_RED}
Application Version: ${application.version}${application.formatted-version}
Spring Boot Version: ${spring-boot.version}${spring-boot.formatted-version}
从上面的内容中可以看到,还使用了一些属性设置:
-
${AnsiColor.BRIGHT_RED}
:设置控制台中输出内容的颜色 -
${application.version}
:用来获取
MANIFEST.MF
文件中的版本号 -
${application.formatted-version}
:格式化后的
${application.version}
版本信息 -
${spring-boot.version}
:Spring Boot的版本号 -
${spring-boot.formatted-version}
:格式化后的
${spring-boot.version}
版本信息
生成工具
如果让我们手工的来编辑这些字符画,显然是一件非常困难的差事。所以,我们可以借助下面这些工具,轻松地根据文字或图片来生成用于Banner输出的字符画。
-
http://patorjk.com/software/taag
- http://www.network-science.de/ascii/
- http://www.degraeve.com/img2txt.php
13. 使用JavaMailSender发送邮件
相信使用过Spring的众多开发者都知道Spring提供了非常好用的
JavaMailSender
接口实现邮件发送。在Spring Boot的Starter模块中也为此提供了自动化配置。下面通过实例看看如何在Spring Boot中使用
JavaMailSender
发送邮件。
快速入门
在Spring Boot的工程中的
pom.xml
中引入
spring-boot-starter-mail
依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-mail</artifactId>
</dependency>
如其他自动化配置模块一样,在完成了依赖引入之后,只需要在
application.properties
中配置相应的属性内容。
下面我们以QQ邮箱为例,在
application.properties
中加入如下配置(注意替换自己的用户名和密码):
spring.mail.host=smtp.qq.com
spring.mail.username=用户名
spring.mail.password=密码
spring.mail.properties.mail.smtp.auth=true
spring.mail.properties.mail.smtp.starttls.enable=true
spring.mail.properties.mail.smtp.starttls.required=true
通过单元测试来实现一封简单邮件的发送:
@RunWith(SpringJUnit4ClassRunner.class)
@SpringApplicationConfiguration(classes = Application.class)
public class ApplicationTests {
@Autowired
private JavaMailSender mailSender;
@Test
public void sendSimpleMail() throws Exception {
SimpleMailMessage message = new SimpleMailMessage();
message.setFrom("dyc87112@qq.com");
message.setTo("dyc87112@qq.com");
message.setSubject("主题:简单邮件");
message.setText("测试邮件内容");
mailSender.send(message);
}
}
到这里,一个简单的邮件发送就完成了,运行一下该单元测试,看看效果如何?
由于Spring Boot的starter模块提供了自动化配置,所以在引入了
spring-boot-starter-mail
依赖之后,会根据配置文件中的内容去创建
JavaMailSender
实例,因此我们可以直接在需要使用的地方直接
@Autowired
来引入邮件发送对象。
进阶使用
在上例中,我们通过使用
SimpleMailMessage
实现了简单的邮件发送,但是实际使用过程中,我们还可能会带上附件、或是使用邮件模块等。这个时候我们就需要使用
MimeMessage
来设置复杂一些的邮件内容,下面我们就来依次实现一下。
发送附件
在上面单元测试中加入如下测试用例(通过MimeMessageHelper来发送一封带有附件的邮件):
@Test
public void sendAttachmentsMail() throws Exception {
MimeMessage mimeMessage = mailSender.createMimeMessage();
MimeMessageHelper helper = new MimeMessageHelper(mimeMessage, true);
helper.setFrom("dyc87112@qq.com");
helper.setTo("dyc87112@qq.com");
helper.setSubject("主题:有附件");
helper.setText("有附件的邮件");
FileSystemResource file = new FileSystemResource(new File("weixin.jpg"));
helper.addAttachment("附件-1.jpg", file);
helper.addAttachment("附件-2.jpg", file);
mailSender.send(mimeMessage);
}
嵌入静态资源
除了发送附件之外,我们在邮件内容中可能希望通过嵌入图片等静态资源,让邮件获得更好的阅读体验,而不是从附件中查看具体图片,下面的测试用例演示了如何通过
MimeMessageHelper
实现在邮件正文中嵌入静态资源。
@Test
public void sendInlineMail() throws Exception {
MimeMessage mimeMessage = mailSender.createMimeMessage();
MimeMessageHelper helper = new MimeMessageHelper(mimeMessage, true);
helper.setFrom("dyc87112@qq.com");
helper.setTo("dyc87112@qq.com");
helper.setSubject("主题:嵌入静态资源");
helper.setText("<html><body><img src=\"cid:weixin\" ></body></html>", true);
FileSystemResource file = new FileSystemResource(new File("weixin.jpg"));
helper.addInline("weixin", file);
mailSender.send(mimeMessage);
}
这里需要注意的是
addInline
函数中资源名称
weixin
需要与正文中
cid:weixin
对应起来
模板邮件
通常我们使用邮件发送服务的时候,都会有一些固定的场景,比如重置密码、注册确认等,给每个用户发送的内容可能只有小部分是变化的。所以,很多时候我们会使用模板引擎来为各类邮件设置成模板,这样我们只需要在发送时去替换变化部分的参数即可。
在Spring Boot中使用模板引擎来实现模板化的邮件发送也是非常容易的,下面我们以velocity为例实现一下。
引入velocity模块的依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-velocity</artifactId>
</dependency>
在
resources/templates/
下,创建一个模板页面
template.vm
:
<html>
<body>
<h3>你好, ${username}, 这是一封模板邮件!</h3>
</body>
</html>
我们之前在Spring Boot中开发Web应用时,提到过在Spring Boot的自动化配置下,模板默认位于
resources/templates/
目录下
最后,我们在单元测试中加入发送模板邮件的测试用例,具体如下:
@Test
public void sendTemplateMail() throws Exception {
MimeMessage mimeMessage = mailSender.createMimeMessage();
MimeMessageHelper helper = new MimeMessageHelper(mimeMessage, true);
helper.setFrom("dyc87112@qq.com");
helper.setTo("dyc87112@qq.com");
helper.setSubject("主题:模板邮件");
Map<String, Object> model = new HashedMap();
model.put("username", "didi");
String text = VelocityEngineUtils.mergeTemplateIntoString(
velocityEngine, "template.vm", "UTF-8", model);
helper.setText(text, true);
mailSender.send(mimeMessage);
}
尝试运行一下,就可以收到内容为
你好, didi, 这是一封模板邮件!
的邮件。这里,我们通过传入username的参数,在邮件内容中替换了模板中的
${username}
变量。
chapter4-5-1
目录:
14. 使用Spring StateMachine框架实现状态机
Spring StateMachine框架可能对于大部分使用Spring的开发者来说还比较生僻,该框架目前差不多也才刚满一岁多。它的主要功能是帮助开发者简化状态机的开发过程,让状态机结构更加层次化。前几天刚刚发布了它的第三个Release版本1.2.0,其中增加了对Spring Boot的自动化配置,
快速入门
依照之前的风格,我们通过一个简单的示例来对Spring StateMachine有一个初步的认识。假设我们需要实现一个订单的相关流程,其中包括订单创建、订单支付、订单收货三个动作。
下面我们来详细的介绍整个实现过程:
-
创建一个Spring Boot的基础工程,并在
pom.xml
中加入
spring-statemachine-core
的依赖,具体如下:
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.3.7.RELEASE</version>
<relativePath/>
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.statemachine</groupId>
<artifactId>spring-statemachine-core</artifactId>
<version>1.2.0.RELEASE</version>
</dependency>
</dependencies>
-
根据上面所述的订单需求场景定义状态和事件枚举,具体如下:
public enum States { UNPAID, // 待支付 WAITING_FOR_RECEIVE, // 待收货 DONE // 结束 } public enum Events { PAY, // 支付 RECEIVE // 收货 }其中共有三个状态(待支付、待收货、结束)以及两个引起状态迁移的事件(支付、收货),
-
其中支付事件
PAY
会触发状态从 待支付
UNPAID
状态到待收货
WAITING_FOR_RECEIVE
状态的迁移, -
而收货事件
RECEIVE
会触发状态 从待收货
WAITING_FOR_RECEIVE
状态到结束
DONE
状态的迁移。
-
其中支付事件
-
创建状态机配置类:
@Configuration
@EnableStateMachine
public class StateMachineConfig extends EnumStateMachineConfigurerAdapter<States, Events> {
private Logger logger = LoggerFactory.getLogger(getClass());
@Override
public void configure(StateMachineStateConfigurer<States, Events> states)
throws Exception {
states
.withStates()
.initial(States.UNPAID)
.states(EnumSet.allOf(States.class));
}
@Override
public void configure(StateMachineTransitionConfigurer<States, Events> transitions)
throws Exception {
transitions
.withExternal()
.source(States.UNPAID).target(States.WAITING_FOR_RECEIVE)
.event(Events.PAY)
.and()
.withExternal()
.source(States.WAITING_FOR_RECEIVE).target(States.DONE)
.event(Events.RECEIVE);
}
@Override
public void configure(StateMachineConfigurationConfigurer<States, Events> config)
throws Exception {
config
.withConfiguration()
.listener(listener());
}
@Bean
public StateMachineListener<States, Events> listener() {
return new StateMachineListenerAdapter<States, Events>() {
@Override
public void transition(Transition<States, Events> transition) {
if(transition.getTarget().getId() == States.UNPAID) {
logger.info("订单创建,待支付");
return;
}
if(transition.getSource().getId() == States.UNPAID
&& transition.getTarget().getId() == States.WAITING_FOR_RECEIVE) {
logger.info("用户完成支付,待收货");
return;
}
if(transition.getSource().getId() == States.WAITING_FOR_RECEIVE
&& transition.getTarget().getId() == States.DONE) {
logger.info("用户已收货,订单完成");
return;
}
}
};
}
}
在该类中定义了较多配置内容,下面对这些内容一一说明:
-
@EnableStateMachine
注解用来启用Spring StateMachine状态机功能 -
configure(StateMachineStateConfigurer<States, Events> states)
方法用来初始化当前状态机拥有哪些状态,其中
initial(States.UNPAID)
定义了初始状态为
UNPAID
,
states(EnumSet.allOf(States.class))
则指定了使用上一步中定义的所有状态作为该状态机的状态定义。
@Override
public void configure(StateMachineStateConfigurer<States, Events> states)
throws Exception {
// 定义状态机中的状态
states
.withStates()
.initial(States.UNPAID) // 初始状态
.states(EnumSet.allOf(States.class));
}
-
-
configure(StateMachineTransitionConfigurer<States, Events> transitions)
方法用来初始化当前状态机有哪些状态迁移动作,其中命名中我们很容易理解每一个迁移动作,都有来源状态
source
,目标状态
target
以及触发事件
event
。@Override public void configure(StateMachineTransitionConfigurer<States, Events> transitions) throws Exception { transitions .withExternal() .source(States.UNPAID).target(States.WAITING_FOR_RECEIVE)// 指定状态来源和目标 .event(Events.PAY) // 指定触发事件 .and() .withExternal() .source(States.WAITING_FOR_RECEIVE).target(States.DONE) .event(Events.RECEIVE); } -
configure(StateMachineConfigurationConfigurer<States, Events> config)
方法为当前的状态机指定了状态监听器,其中
listener()
则是调用了下一个内容创建的监听器实例,用来处理各个各个发生的状态迁移事件。@Override public void configure(StateMachineConfigurationConfigurer<States, Events> config) throws Exception { config .withConfiguration() .listener(listener()); // 指定状态机的处理监听器 } -
StateMachineListener<States, Events> listener()
方法用来创建
StateMachineListener
状态监听器的实例,在该实例中会定义具体的状态迁移处理逻辑,上面的实现中只是做了一些输出,实际业务场景会会有更负责的逻辑,所以通常情况下,我们可以将该实例的定义放到独立的类定义中,并用注入的方式加载进来。
-
-
创建应用主类来完成整个流程:
@SpringBootApplication public class Application implements CommandLineRunner { public static void main(String[] args) { SpringApplication.run(Application.class, args); } @Autowired private StateMachine<States, Events> stateMachine; @Override public void run(String... args) throws Exception { stateMachine.start(); stateMachine.sendEvent(Events.PAY); stateMachine.sendEvent(Events.RECEIVE); } }在
run
函数中,我们定义了整个流程的处理过程,其中
start()
就是创建这个订单流程,根据之前的定义,该订单会处于待支付状态,然后通过调用
sendEvent(Events.PAY)
执行支付操作,最后通过掉用
sendEvent(Events.RECEIVE)
来完成收货操作。在运行了上述程序之后,我们可以在控制台中获得类似下面的输出内容:INFO 2312 --- [ main] eConfig$$EnhancerBySpringCGLIB$$a05acb3d : 订单创建,待支付 INFO 2312 --- [ main] o.s.s.support.LifecycleObjectSupport : started org.springframework.statemachine.support.DefaultStateMachineExecutor@1d2290ce INFO 2312 --- [ main] o.s.s.support.LifecycleObjectSupport : started DONE UNPAID WAITING_FOR_RECEIVE / UNPAID / uuid=c65ec0aa-59f9-4ffb-a1eb-88ec902369b2 / id=null INFO 2312 --- [ main] eConfig$$EnhancerBySpringCGLIB$$a05acb3d : 用户完成支付,待收货 INFO 2312 --- [ main] eConfig$$EnhancerBySpringCGLIB$$a05acb3d : 用户已收货,订单完成其中包括了状态监听器中对各个状态迁移做出的处理。
通过上面的例子,我们可以对如何使用Spring StateMachine做如下小结:
- 定义状态和事件枚举
- 为状态机定义使用的所有状态以及初始状态
- 为状态机定义状态的迁移动作
- 为状态机指定监听处理器
状态监听器
通过上面的入门示例以及最后的小结,我们可以看到使用Spring StateMachine来实现状态机的时候,代码逻辑变得非常简单并且具有层次化。整个状态的调度逻辑主要依靠配置方式的定义,而所有的业务逻辑操作都被定义在了状态监听器中,其实状态监听器可以实现的功能远不止上面我们所述的内容,它还有更多的事件捕获,我们可以通过查看
StateMachineListener
接口来了解它所有的事件定义:
public interface StateMachineListener<S,E> {
void stateChanged(State<S,E> from, State<S,E> to);
void stateEntered(State<S,E> state);
void stateExited(State<S,E> state);
void eventNotAccepted(Message<E> event);
void transition(Transition<S, E> transition);
void transitionStarted(Transition<S, E> transition);
void transitionEnded(Transition<S, E> transition);
void stateMachineStarted(StateMachine<S, E> stateMachine);
void stateMachineStopped(StateMachine<S, E> stateMachine);
void stateMachineError(StateMachine<S, E> stateMachine, Exception exception);
void extendedStateChanged(Object key, Object value);
void stateContext(StateContext<S, E> stateContext);
}
注解监听器
对于状态监听器,Spring StateMachine还提供了优雅的注解配置实现方式,所有
StateMachineListener
接口中定义的事件都能通过注解的方式来进行配置实现。比如,我们可以将之前实现的状态监听器用注解配置来做进一步的简化:
@WithStateMachine
public class EventConfig {
private Logger logger = LoggerFactory.getLogger(getClass());
@OnTransition(target = "UNPAID")
public void create() {
logger.info("订单创建,待支付");
}
@OnTransition(source = "UNPAID", target = "WAITING_FOR_RECEIVE")
public void pay() {
logger.info("用户完成支付,待收货");
}
@OnTransition(source = "WAITING_FOR_RECEIVE", target = "DONE")
public void receive() {
logger.info("用户已收货,订单完成");
}
}
上述代码实现了与快速入门中定义的
listener()
方法创建的监听器相同的功能,但是由于通过注解的方式配置,省去了原来事件监听器中各种if的判断,使得代码显得更为简洁,拥有了更好的可读性。
本文完整示例:
- 开源中国:http://git.oschina.net/didispace/SpringBoot-Learning/tree/master/Chapter6-1-1
-
GitHub:
https://github.com/dyc87112/SpringCloud-Learning/tree/master/1-Brixton%E7%89%88%E6%95%99%E7%A8%8B%E7%A4%BA%E4%BE%8B/Chapter6-1-1
15. 后台运行配置
Spring Boot应用的几种运行方式:
- 运行Spring Boot的应用主类
-
使用Maven的Spring Boot插件
mvn spring-boot:run
来运行 -
打成jar包后,使用
java -jar
运行
我们在开发的时候,通常会使用前两种,而在部署的时候往往会使用第三种。但是,我们在使用
java -jar
来运行的时候,并非后台运行。
下面我们分别针对Windows和Linux/Unix两种环境:
Windows
Windows下比较简单,我们可以直接使用这款软件:
AlwaysUp
。如下图所示,简单、暴力、好用。
配置方式很简单,我们只需要把Spring Boot应用通过
mvn install
打成jar包,然后编写一个
java -jar yourapp.jar
的bat文件。再打开
AlwaysUp
,点击工具栏的第一个按钮,如下图所示,选择上面编写的bat文件,并填写服务名称。
完成了创建之后,在列表中可以看到我们配置的服务,通过右键选择
Start xxx
就能在后台将该应用启动起来了。
Linux/Unix
下面我们来说说服务器上该如何来配置。实际上,实现的方法有很多种,这里就列两种还比较好用的方式:
nohup和Shell
该方法主要通过使用
nohup
命令来实现,该命令的详细介绍如下:
nohup 命令
用途:不挂断地运行命令。
语法:nohup Command [ Arg … ][ & ]
描述:nohup 命令运行由 Command 参数和任何相关的 Arg 参数指定的命令,忽略所有挂断(SIGHUP)信号。在注销后使用 nohup 命令运行后台中的程序。要运行后台中的 nohup 命令,添加
&
到命令的尾部。
所以,我们只需要使用
nohup java -jar yourapp.jar &
命令,就能让
yourapp.jar
在后台运行了。
- 但是,为了方便管理,我们还可以通过Shell来编写一些用于启动应用的脚本,比如下面几个:
关闭脚本
-
关闭应用的脚本:
stop.sh
#!/bin/bash
PID=$(ps -ef | grep yourapp.jar | grep -v grep | awk '{ print $2 }')
if [ -z "$PID" ]
then
echo Application is already stopped
else
echo kill $PID
kill $PID
fi
1.grep 是查找含有指定文本行的意思,比如grep test 就是查找含有test的文本的行
2.grep -v 是反向查找的意思,比如 grep -v grep 就是查找不含有 grep 字段的行
awk 逐行读取文本,默认以空格或tab键为分隔符进行分隔,
启动脚本
启动应用的脚本:start.sh
#!/bin/bash
nohup java -jar yourapp.jar --server.port=8888 &
-
整合了关闭和启动的脚本:
run.sh
,由于会先执行关闭应用,然后再启动应用,这样不会引起端口冲突等问题,适合在持续集成系统中进行反复调用。
#!/bin/bash
echo stop application #输出 结束进程
source stop.sh #关闭进程
echo start application #输出 开启进程
source start.sh #调用开启脚本
系统服务
在Spring Boot的Maven插件中,还提供了构建完整可执行程序的功能,什么意思呢?就是说,我们可以不用
java -jar
,而是直接运行jar来执行程序。这样我们就可以方便的将其创建成系统服务在后台运行了。主要步骤如下:
-
在
pom.xml
中添加Spring Boot的插件,并注意设置
executable
配置
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<executable>true</executable>
</configuration>
</plugin>
</plugins>
</build>
-
在完成上述配置后,使用
mvn install
进行打包,构建一个可执行的jar包 -
创建软连接到
/etc/init.d/
目录下
sudo ln -s /var/yourapp/yourapp.jar /etc/init.d/yourapp
-
在完成软连接创建之后,我们就可以通过如下命令对
yourapp.jar
应用来控制启动、停止、重启操作了
/etc/init.d/yourapp start|stop|restart
#记得给 yourapp 服务权限。
#因为 未指定端口,默认8080端口访问即可。
16. 找回日志中请求路径列表
为什么在Spring Boot 2.1.x版本中不再打印请求路径列表呢?
主要是由于从该版本开始,将这些日志的打印级别做了调整:从原来的
INFO
调整为
TRACE
。所以,当我们希望在应用启动的时候打印这些信息的话,只需要在配置文件增增加对
RequestMappingHandlerMapping
类的打印级别设置即可,比如在
application.properties
中增加下面这行配置:
logging.level.org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerMapping=trace
在增加了上面的配置之后重启应用,便可以看到如下的日志打印:
2020-02-11 15:36:09.787 TRACE 49215 --- [main] s.w.s.m.m.a.RequestMappingHandlerMapping :
c.d.c.UserController:
{PUT /users/{id}}: putUser(Long,User)
{GET /users/{id}}: getUser(Long)
{POST /users/}: postUser(User)
{GET /users/}: getUserList()
{DELETE /users/{id}}: deleteUser(Long)
2020-02-11 15:36:09.791 TRACE 49215 --- [main] s.w.s.m.m.a.RequestMappingHandlerMapping :
o.s.b.a.w.s.e.BasicErrorController:
{ /error}: error(HttpServletRequest)
{ /error, produces [text/html]}: errorHtml(HttpServletRequest,HttpServletResponse)
2020-02-11 15:36:09.793 DEBUG 49215 --- [main] s.w.s.m.m.a.RequestMappingHandlerMapping : 7 mappings in 'requestMappingHandlerMapping'
可以看到在2.1.x版本之后,除了调整了日志级别之外,对于打印内容也做了调整。现在的打印内容根据接口创建的Controller类做了分类打印,这样更有助于开发者根据自己编写的Controller来查找初始化了那些HTTP接口。
-
可以查看下面仓库中的
chapter2-6
目录:
17. Java 8时间日期API的序列化问题
LocalDate
、
LocalTime
、
LocalDateTime
是Java 8开始提供的时间日期API,主要用来优化Java 8以前对于时间日期的处理操作。
然而,我们在使用Spring Boot或使用Spring Cloud Feign的时候,往往会发现使用请求参数或返回结果中有
LocalDate
、
LocalTime
、
LocalDateTime
的时候会发生各种问题。
问题现象
先来看看症状。比如下面的例子:
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
@RestController
class HelloController {
@PostMapping("/user")
public UserDto user(@RequestBody UserDto userDto) throws Exception {
return userDto;
}
}
@Data
@NoArgsConstructor
@AllArgsConstructor
static class UserDto {
private String userName;
private LocalDate birthday;
}
}
上面的代码构建了一个简单的Spring Boot Web应用,它提供了一个提交用户信息的接口,用户信息中包含了
LocalDate
类型的数据。此时,如果我们使用Feign来调用这个接口的时候,会得到如下错误:
2018-03-13 09:22:58,445 WARN [http-nio-9988-exec-3] org.springframework.web.servlet.mvc.support.DefaultHandlerExceptionResolver - Failed to read HTTP message: org.springframework.http.converter.HttpMessageNotReadableException: JSON parse error: Can not construct instance of java.time.LocalDate: no suitable constructor found, can not deserialize from Object value (missing default constructor or creator, or perhaps need to add/enable type information?); nested exception is com.fasterxml.jackson.databind.JsonMappingException: Can not construct instance of java.time.LocalDate: no suitable constructor found, can not deserialize from Object value (missing default constructor or creator, or perhaps need to add/enable type information?)
at [Source: java.io.PushbackInputStream@67064c65; line: 1, column: 63] (through reference chain: java.util.ArrayList[0]->com.didispace.UserDto["birthday"])
分析解决
对于上面的错误信息
JSON parse error: Can not construct instance of java.time.LocalDate: no suitable constructor found, can not deserialize from Object value
,熟悉Spring MVC的童鞋应该马上就能定位错误与
LocalDate
的反序列化有关。但是,依然会有很多读者会被这段错误信息
java.util.ArrayList[0]->com.didispace.UserDto["birthday"]
所困惑。我们命名提交的
UserDto["birthday"]
是个
LocalDate
对象嘛,跟
ArrayList
列表对象有啥关系呢?
我们不妨通过postman等手工发一个请求看看服务端返回的是什么?比如你可以按下图发起一个请求:
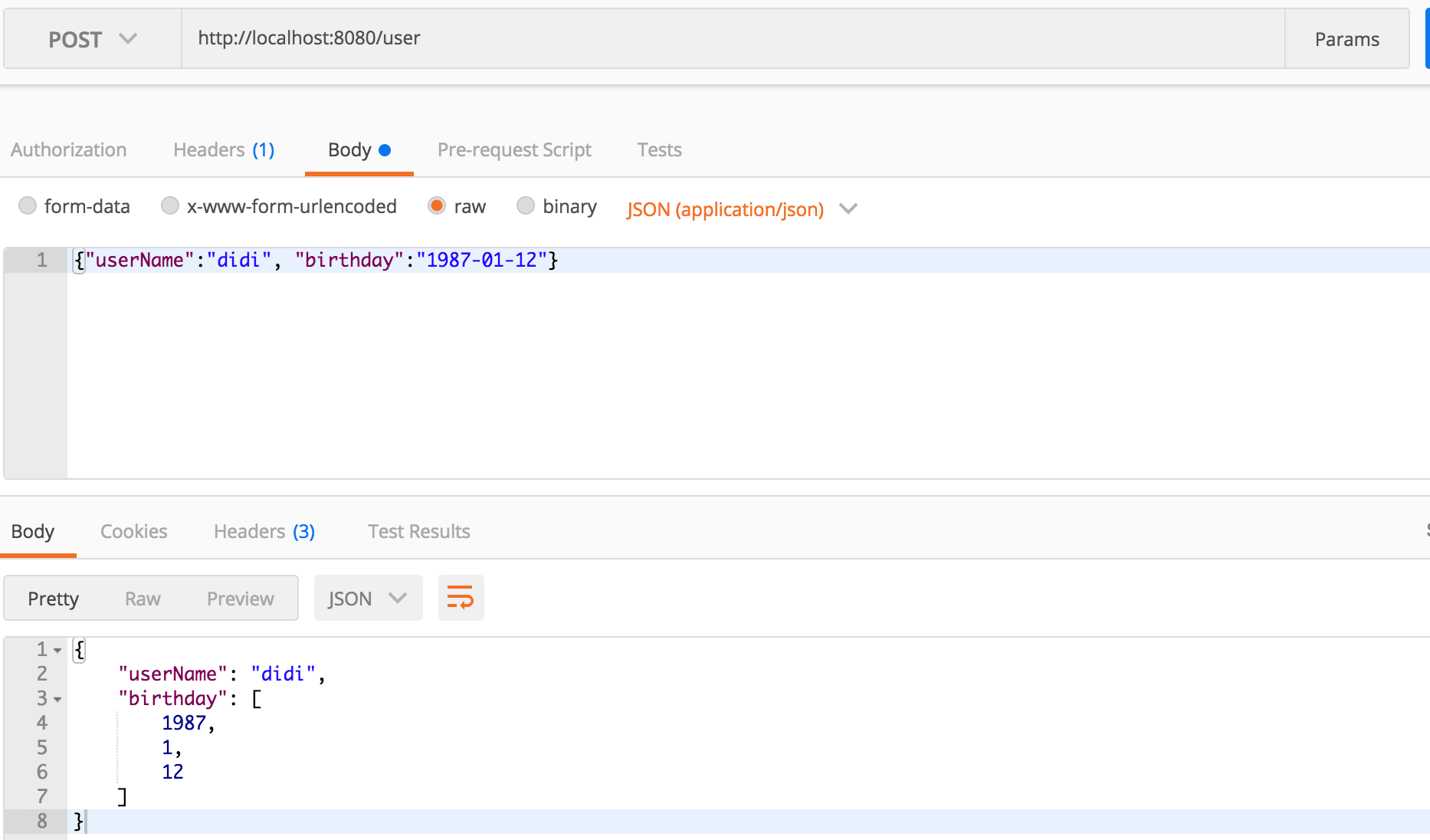
从上图中我们就可以理解上面我所提到的困惑了,实际上默认情况下Spring MVC对于
LocalDate
序列化成了一个数组类型,而Feign在调用的时候,还是按照
ArrayList
来处理,所以自然无法反序列化为
LocalDate
对象了。
解决方法
引入pom
为了解决上面的问题非常简单,因为jackson也为此提供了一整套的序列化方案,我们只需要在
pom.xml
中引入
jackson-datatype-jsr310
依赖,具体如下:
<dependency>
<groupId>com.fasterxml.jackson.datatype</groupId>
<artifactId>jackson-datatype-jsr310</artifactId>
</dependency>
注意:在设置了spring boot的parent的情况下不需要指定具体的版本,也不建议指定某个具体版本
在该模块中封装对Java 8的时间日期API序列化的实现,其具体实现在这个类中:
com.fasterxml.jackson.datatype.jsr310.JavaTimeModule
-
(注意:一些较早版本疯转在这个类中“
com.fasterxml.jackson.datatype.jsr310.JSR310Module
)。 - 在配置了依赖之后,我们只需要在上面的应用主类中增加这个序列化模块,并禁用对日期以时间戳方式输出的特性:
配置序列化
@Bean
public ObjectMapper serializingObjectMapper() {
ObjectMapper objectMapper = new ObjectMapper();
objectMapper.disable(SerializationFeature.WRITE_DATES_AS_TIMESTAMPS);
objectMapper.registerModule(new JavaTimeModule());
return objectMapper;
}
此时,我们在访问刚才的接口,就不再是数组类型了,同时对于Feign客户端的调用也不会再出现上面的错误了。
Chapter3-1-7
目录:
18. Request header is too large
今天看到群里有小伙伴问,这个异常要怎么解决:
java.lang.IllegalArgumentException: Request header is too large
异常原因
根据Exception Message
Request header is too large
,就可以判断这个错误原因是HTTP请求头过大导致的。
如何解决
解决方法主要两个方向:
方向一: 配置应用服务器使其允许的最大值 > 你实用实用的请求头数据大小
如果用Spring Boot的话,只需要在配置文件里配置这个参数即可:
server.max-http-header-size=
方向二:规避请求头过大的情况
虽然上面的配置可以在解决,但是如果无节制的使用header部分,那么这个参数就会变得不可控。
对于请求头部分的数据其实本身并不建议放太大的数据,所以,还是建议把这些数据放到body里更为合理。