系列文章目录
文章目录
前言
可以先看下上文的基础知识——为什么分库分表
本文是借鉴小傅哥的笔记 整理的自己学习笔记 仅作学习使用 如有侵权请联系
本文是对分库分表组件的具体实现:我们要实现的也是水平拆分的路由设计,如图
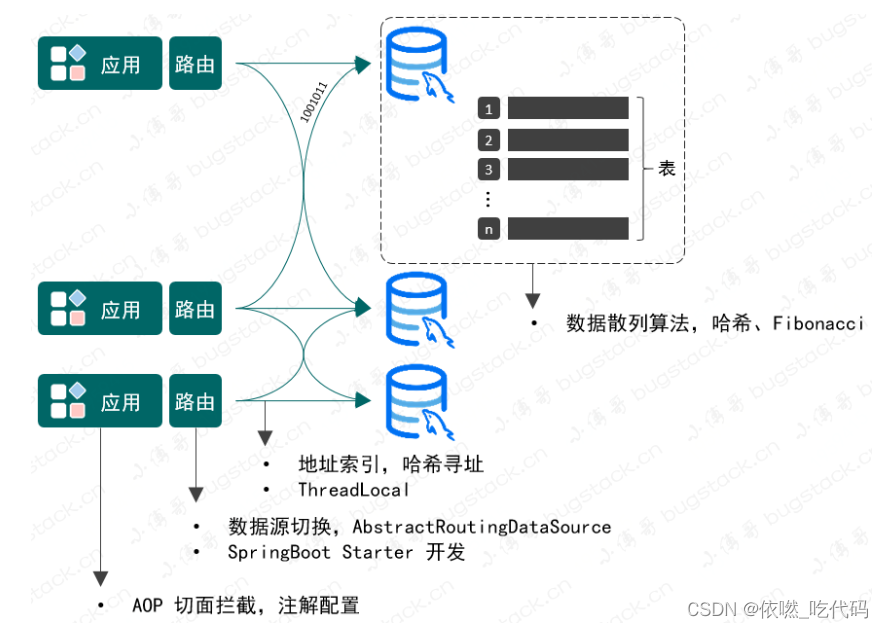
一、所需技术
- 是关于 AOP 切面拦截的使用,这是因为需要给使用数据库路由的方法做上标记,便于处理分库分表逻辑。
- 数据源的切换操作,既然有分库那么就会涉及在多个数据源间进行链接切换,以便把数据分配给不同的数据库。
- 数据库表寻址操作,一条数据分配到哪个数据库,哪张表,都需要进行索引计算。在方法调用的过程中最终通过 ThreadLocal 记录。
- 为了能让数据均匀的分配到不同的库表中去,还需要考虑如何进行数据散列的操作,不能分库分表后,让数据都集中在某个库的某个表,这样就失去了分库分表的意义。
综上,可以看到在数据库和表的数据结构下完成数据存放,我需要用到的技术包括:AOP、数据源切换、散列算法、哈希寻址、ThreadLocal以及SpringBoot的Starter开发方式等技术。而像哈希散列、寻址、数据存放,其实这样的技术与 HashMap 有太多相似之处
二、技术总结
1. ThreadLocal

@Test
public void test_idx() {
int hashCode = 0;
for (int i = 0; i < 16; i++) {
hashCode = i * 0x61c88647 + 0x61c88647;
int idx = hashCode & 15;
System.out.println("斐波那契散列:" + idx + " 普通散列:" + (String.valueOf(i).hashCode() & 15));
}
}
斐波那契散列:7 普通散列:0
斐波那契散列:14 普通散列:1
斐波那契散列:5 普通散列:2
斐波那契散列:12 普通散列:3
斐波那契散列:3 普通散列:4
斐波那契散列:10 普通散列:5
斐波那契散列:1 普通散列:6
斐波那契散列:8 普通散列:7
斐波那契散列:15 普通散列:8
斐波那契散列:6 普通散列:9
斐波那契散列:13 普通散列:15
斐波那契散列:4 普通散列:0
斐波那契散列:11 普通散列:1
斐波那契散列:2 普通散列:2
斐波那契散列:9 普通散列:3
斐波那契散列:0 普通散列:4
2.HashMap
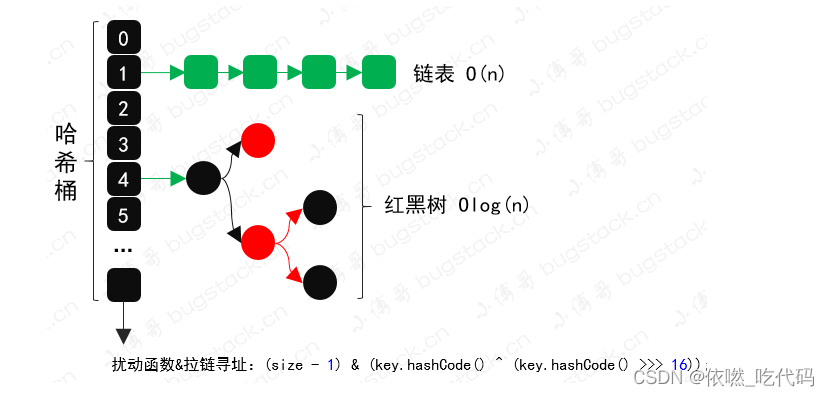
public static int disturbHashIdx(String key, int size) {
return (size - 1) & (key.hashCode() ^ (key.hashCode() >>> 16));
}
三、实现
1、定义路由注解
自定义注解
- 概念:说明程序的。给计算机看的
注释:用文字描述程序的。给程序员看的
定义:注解(Annotation),也叫元数据。一种代码级别的说明。它是JDK1.5及以后版本引入的一个特性,与类、接口、枚举是在同一个层次。它可以声明在包、类、字段、方法、局部变量、方法参数等的前面,用来对这些元素进行说明,注释。概念描述:JDK1.5之后的新特性 说明程序的
使用注解:@注解名称
格式
元注解 public @interface 注解名称{ 属性列表; }
注解本质上就是一个接口,该接口默认继承Annotation接口
public interface MyAnno extends java.lang.annotation.Annotation {}
接口中可能有抽象方法
要求
1、属性的返回值类型有下列取值:基本数据类型、String、枚举、注解以上类型的数组
2、定义了属性,在使用时需要给属性赋值
3、如果定义属性时,使用default关键字给属性默认初始化值,则使用注解时,可以不进行属性的赋值。
4、如果只有一个属性需要赋值,并且属性的名称是value,则value可以省略,直接定义值即可。
数组赋值时,值使用{}包裹。如果数组中只有一个值,则{}可以省略
定义:
public @interface MyAnno {
int value();
Person per();
MyAnno2 anno2();
String[] strs();
}
public enum Person {
P1,P2;
}
使用:
@MyAnno(value=12,per = Person.P1,anno2 = @MyAnno2,strs="bbb")
public class Worker {
}
元注解: 用于描述注解的注解
@Target:描述注解能够作用的位置
ElementType取值:
TYPE:可以作用于类上
METHOD:可以作用于方法上
FIELD:可以作用于成员变量上
@Retention:描述注解被保留的阶段
@Retention(RetentionPolicy.RUNTIME):当前被描述的注解,会保留到class字节码文件中,并被JVM读取到,自定义注解一般用这个。
@Documented:描述注解是否被抽取到api文档中
@Inherited:描述注解是否被子类继承
在程序使用(解析)注解:获取注解中定义的属性值
之前反射的范例
/**
前提:不能改变该类的任何代码。可以创建任意类的对象,可以执行任意方法
*/
//1.加载配置文件
//1.1创建Properties对象
Properties pro = new Properties();
//1.2加载配置文件,转换为一个集合
//1.2.1获取class目录下的配置文件
ClassLoader classLoader = ReflectTest.class.getClassLoader();
InputStream is = classLoader.getResourceAsStream("pro.properties");
pro.load(is);
//2.获取配置文件中定义的数据
String className = pro.getProperty("className");
String methodName = pro.getProperty("methodName");
//3.加载该类进内存
Class cls = Class.forName(className);
//4.创建对象
Object obj = cls.newInstance();
//5.获取方法对象
Method method = cls.getMethod(methodName);
//6.执行方法
method.invoke(obj);
在反射中有通过读取配置文件来创建任意类的对象,执行任意方法。
我们可以通过注解替换上述读取配置文件相关操作。具体代码如下: 注解定义如下:
/**
* 描述需要执行的类名,和方法名
* @author ymj
*/
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
public @interface Pro {
String className();
String methodName();
}
通过解析注解配置,执行相关对象创建和执行对象方法。
- 获取注解定义的位置的对象 (Class,Method,Field)
- 获取指定的注解
- 调用注解中的抽象方法获取配置的属性值
代码如下:
@Pro(className = "com.zjq.javabase.base25.annotation.Demo1",methodName = "show")
public class ReflectTest {
public static void main(String[] args) throws Exception {
/**
* 前提:不能改变该类的任何代码。可以创建任意类的对象,可以执行任意方法
*/
//1.解析注解
//1.1获取该类的字节码文件对象
Class<ReflectTest> reflectTestClass = ReflectTest.class;
//2.获取上边的注解对象
//其实就是在内存中生成了一个该注解接口的子类实现对象
/*
public class ProImpl implements Pro{
public String className(){
return "com.zjq.javabase.base25.annotation.Demo1";
}
public String methodName(){
return "show";
}
}
*/
Pro an = reflectTestClass.getAnnotation(Pro.class);
//3.调用注解对象中定义的抽象方法,获取返回值
String className = an.className();
String methodName = an.methodName();
System.out.println(className);
System.out.println(methodName);
//4.加载该类进内存
Class cls = Class.forName(className);
//5.创建对象
Object obj = cls.newInstance();
//6.获取方法对象
Method method = cls.getMethod(methodName);
//7.执行方法
method.invoke(obj);
}
}
小例子:注解定义一个简单的测试框架
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface Check {
}
定义一个计算器工具类,并在方法上使用@Check注解
/**
* 定义的计算器类
* @author ymj
*/
public class Calculator {
//加法
@Check
public void add(){
String str = null;
str.toString();
System.out.println("1 + 0 =" + (1 + 0));
}
//减法
@Check
public void sub(){
System.out.println("1 - 0 =" + (1 - 0));
}
//乘法
@Check
public void mul(){
System.out.println("1 * 0 =" + (1 * 0));
}
//除法
@Check
public void div(){
System.out.println("1 / 0 =" + (1 / 0));
}
public void show(){
System.out.println("永无bug...");
}
}
定义测试框架类并执行测试,把测试异常记录到bug.txt文件中,代码如下:
/**
* 简单的测试框架
* 当主方法执行后,会自动自行被检测的所有方法(加了Check注解的方法),判断方法是否有异常,
* 记录到文件中
*
* @author ymj
*/
public class TestCheck {
public static void main(String[] args) throws IOException {
//1.创建计算器对象
Calculator c = new Calculator();
//2.获取字节码文件对象
Class cls = c.getClass();
//3.获取所有方法
Method[] methods = cls.getMethods();
int number = 0;//出现异常的次数
BufferedWriter bw = new BufferedWriter(new FileWriter("bug.txt"));
for (Method method : methods) {
//4.判断方法上是否有Check注解
if (method.isAnnotationPresent(Check.class)) {
//5.有,执行
try {
method.invoke(c);
} catch (Exception e) {
//6.捕获异常
//记录到文件中
number++;
bw.write(method.getName() + " 方法出异常了");
bw.newLine();
bw.write("异常的名称:" + e.getCause().getClass().getSimpleName());
bw.newLine();
bw.write("异常的原因:" + e.getCause().getMessage());
bw.newLine();
bw.write("--------------------------");
bw.newLine();
}
}
}
bw.write("本次测试一共出现 " + number + " 次异常");
bw.flush();
bw.close();
}
}
执行测试后可以在src同级目录查看到bug.txt文件内容如下:
add 方法出异常了
异常的名称:NullPointerException
异常的原因:null
div 方法出异常了
异常的名称:ArithmeticException
异常的原因:/ by zero
实战写法
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.TYPE, ElementType.METHOD})
public @interface DBRouter {
String key() default "";
}
小总结
大多数时候,我们只是使用注解,而不是自定义注解。
注解给谁用?
- 编译器
- 给解析程序用
注解不是程序的一部分,可以理解为注解就是一个标签。
@Mapper
public interface IUserDao {
@DBRouter(key = "userId")
User queryUserInfoByUserId(User req);
@DBRouter(key = "userId")
void insertUser(User req);
}
- 首先我们需要自定义一个注解,用于放置在需要被数据库路由的方法上。
- 它的使用方式是通过方法配置注解,就可以被我们指定的 AOP 切面进行拦截,拦截后进行相应的数据库路由计算和判断,并切换到相应的操作数据源上。
2、解析路由配置
这篇文章也写的不错
点这里!!!!!
路由配置的话 需要设置分库分表的 要在 自己的application.yml中定义多数据源配置
配置三个库的信息
- 以上就是我们实现完数据库路由组件后的一个数据源配置,在分库分表下的数据源使用中,都需要支持多数据源的信息配置,这样才能满足不同需求的扩展。
- 对于这种自定义较大的信息配置,就需要使用到
org.springframework.context.EnvironmentAware接口,来获取配置文件并提取需要的配置信息。
获取配置的话 需要实现上面这个接口 然后重写setEnvironment的方法
咱们这里介绍凡是被spring管理的类,实现接口 EnvironmentAware 重写方法 setEnvironment 可以在工程启动时,获取到系统环境变量和application配置文件中的变量。
范例:
package com.kfit.environment;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.boot.bind.RelaxedPropertyResolver;
import org.springframework.context.EnvironmentAware;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.env.Environment;
/**
* 主要是@Configuration,实现接口:EnvironmentAware就能获取到系统环境信息;
*
*
*/
@Configuration
public class MyEnvironmentAware implements EnvironmentAware{
//注入application.properties的属性到指定变量中.
@Value ( "${spring.datasource.url}" )
private String myUrl;
/**
*注意重写的方法 setEnvironment 是在系统启动的时候被执行。
*/
@Override
public void setEnvironment(Environment environment) {
//打印注入的属性信息.
System.out.println( "myUrl=" +myUrl);
//通过 environment 获取到系统属性.
System.out.println(environment.getProperty( "JAVA_HOME" ));
//通过 environment 同样能获取到application.properties配置的属性.
System.out.println(environment.getProperty( "spring.datasource.url" ));
//获取到前缀是"spring.datasource." 的属性列表值.
RelaxedPropertyResolver relaxedPropertyResolver = new RelaxedPropertyResolver(environment, "spring.datasource." );
System.out.println( "spring.datasource.url=" +relaxedPropertyResolver.getProperty( "url" ));
System.out.println( "spring.datasource.driverClassName=" +relaxedPropertyResolver.getProperty( "driverClassName" ));
}
}
其中application.properties文件信息是:
########################################################
###datasource
########################################################
spring.datasource.url = jdbc:mysql: //localhost:3306/test
spring.datasource.username = root
spring.datasource.password = root
spring.datasource.driverClassName = com.mysql.jdbc.Driver
spring.datasource.max-active= 20
spring.datasource.max-idle= 8
spring.datasource.min-idle= 8
spring.datasource.initial-size= 10
@Override
public void setEnvironment(Environment environment) {
String prefix = "router.jdbc.datasource.";
//prefix,是数据源配置的开头信息,你可以自定义需要的开头内容。
//dbCount 分库数量、tbCount 分表数量、dataSources 数据源、dataSourceProps ,
//都是对配置信息的提取,并存放到 dataSourceMap (数据源配置组)中便于后续使用。
dbCount = Integer.valueOf(environment.getProperty(prefix + "dbCount"));
tbCount = Integer.valueOf(environment.getProperty(prefix + "tbCount"));
String dataSources = environment.getProperty(prefix + "list");
for (String dbInfo : dataSources.split(",")) {
Map<String, Object> dataSourceProps = PropertyUtil.handle(environment, prefix + dbInfo, Map.class);
dataSourceMap.put(dbInfo, dataSourceProps);
}
}
当然 这里面的PropertyUtil是自己定义的读取配置文件操作工具类 工具类中通过反射的原理 handle 函数(根据springboot version的版本)跳转到自己的v1和v2方法 类似上面的自定义注解的配置解析
3. 数据源切换
在结合 SpringBoot 开发的 Starter 中,需要提供一个 DataSource 的实例化对象,那么这个对象我们就放在 DataSourceAutoConfig 来实现,并且这里提供的数据源是可以动态变换的,也就是支持动态切换数据源。
这里说明一下
两个注解的作用
Spring Boot 推荐使用 java 配置完全代替 XML 配置,java 配置是通过 @Configration 和 @Bean 注解实现的。二者作用如下:
- @Configration 注解:声明当前类是一个配置类,相当于 Spring 中的一个 XML 文件
- @Bean 注解:作用在方法上,声明当前方法的返回值是一个 Bean
不懂的话 详情请点击 这里!!!!!!!
同时也要把@Component 和 @Bean 的区别 看好
数据源的创建
@Bean
public DataSource dataSource() {
// 创建数据源
Map<Object, Object> targetDataSources = new HashMap<>();
for (String dbInfo : dataSourceMap.keySet()) {
Map<String, Object> objMap = dataSourceMap.get(dbInfo);
//new 了一个构造器
targetDataSources.put(dbInfo, new DriverManagerDataSource(objMap.get("url").toString(), objMap.get("username").toString(), objMap.get("password").toString()));
}
// 设置数据源
DynamicDataSource dynamicDataSource = new DynamicDataSource();
//targetDataSources:保存多个数据源的map
//defaultTargetDataSource:指默认的数据源
dynamicDataSource.setTargetDataSources(targetDataSources);
dynamicDataSource.setDefaultTargetDataSource(new DriverManagerDataSource(defaultDataSourceConfig.get("url").toString(), defaultDataSourceConfig.get("username").toString(), defaultDataSourceConfig.get("password").toString()));
return dynamicDataSource;
}
这里是一个简化的创建案例,把基于从配置信息中读取到的数据源信息,进行实例化创建。
由于是多库 不止一个 所以用DynamicDataSource
而这个库DriverManagerDataSource
只是连接数据库的一种方式
数据源创建完成后存放到 DynamicDataSource 中,DynamicDataSource这个类 在本文中是自定义的一个类 它是一个继承了 AbstractRoutingDataSource 的实现类,这个类里可以存放和读取相应的具体调用的数据源信息。
参考文章:这里!!!!
targetDataSources:保存多个数据源的map
defaultTargetDataSource:指默认的数据源
下面的是好文章 首先targetDataSources是一个map,根据key保存不同的数据源,源码里面看到targetDataSources会转换成另一个map的变量resolvedDataSources,而defaultTargetDataSource转换成resolvedDefaultDataSource
4. 切面拦截
在 AOP 的切面拦截中需要完成;数据库路由计算、扰动函数加强散列、计算库表索引、设置到 ThreadLocal 传递数据源,整体案例代码如下:
这个开头切面的代码是加入了一个Pointcut这个切入点的集合
Pointcut里面加入@annotation:用于匹配当前执行方法持有指定注解的方法
@annotation(注解类型):匹配被调用的方法上有指定的注解。
案例
定义一个注解,可以用在方法上
package com.javacode2018.aop.demo9.test12;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface Ann12 {
}
定义2个类
S12Parent为父类,内部定义了2个方法,2个方法上都有@Ann12注解
S12是代理的目标类,也是S12Parent的子类,内部重写了m2方法,重写之后m2方法上并没有@Ann12注解,S12内部还定义2个方法m3和m4,而m3上面有注解@Ann12
package com.javacode2018.aop.demo9.test12;
class S12Parent {
@Ann12
public void m1() {
System.out.println("我是S12Parent.m1()方法");
}
@Ann12
public void m2() {
System.out.println("我是S12Parent.m2()方法");
}
}
public class S12 extends S12Parent {
@Override
public void m2() {
System.out.println("我是S12.m2()方法");
}
@Ann12
public void m3() {
System.out.println("我是S12.m3()方法");
}
public void m4() {
System.out.println("我是S12.m4()方法");
}
}
来个Aspect类
当被调用的目标方法上有@Ann12注解的时,会被beforeAdvice处理。
package com.javacode2018.aop.demo9.test12;
import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
import org.aspectj.lang.annotation.Pointcut;
@Aspect
public class AspectTest12 {
@Pointcut("@annotation(com.javacode2018.aop.demo9.test12.Ann12)")
public void pc() {
}
@Before("pc()")
public void beforeAdvice(JoinPoint joinPoint) {
System.out.println(joinPoint);
}
}
测试用例
S12作为目标对象,创建代理,然后分别调用4个方法
@Test
public void test12() {
S12 target = new S12();
AspectJProxyFactory proxyFactory = new AspectJProxyFactory();
proxyFactory.setTarget(target);
proxyFactory.addAspect(AspectTest12.class);
S12 proxy = proxyFactory.getProxy();
proxy.m1();
proxy.m2();
proxy.m3();
proxy.m4();
}
运行输出
execution(void com.javacode2018.aop.demo9.test12.S12Parent.m1())
我是S12Parent.m1()方法
我是S12.m2()方法
execution(void com.javacode2018.aop.demo9.test12.S12.m3())
我是S12.m3()方法
我是S12.m4()方法
分析结果
m1方法位于S12Parent中,上面有@Ann12注解,被连接了,m3方法上有@Ann12注解,被拦截了,而m4上没有@Ann12注解,没有被拦截,这3个方法的执行结果都很容易理解。
重点在于m2方法的执行结果,没有被拦截,m2方法虽然在S12Parent中定义的时候也有@Ann12注解标注,但是这个方法被S1给重写了,在S1中定义的时候并没有@Ann12注解,代码中实际上调用的是S1中的m2方法,发现这个方法上并没有@Ann12注解,所以没有被拦截。
针对这个切入点的集合用法详情 点这里!!!!
@Around("aopPoint() && @annotation(dbRouter)")
public Object doRouter(ProceedingJoinPoint jp, DBRouter dbRouter) throws Throwable {
String dbKey = dbRouter.key();
//StringUtils类与String类的区别在于:此类是null安全的,
//即如果输入参数String为null,则不会抛出NullPointerException异常,代码更健壮。
if (StringUtils.isBlank(dbKey)) throw new RuntimeException("annotation DBRouter key is null!");
// 计算路由
String dbKeyAttr = getAttrValue(dbKey, jp.getArgs());
int size = dbRouterConfig.getDbCount() * dbRouterConfig.getTbCount();
// 扰动函数
int idx = (size - 1) & (dbKeyAttr.hashCode() ^ (dbKeyAttr.hashCode() >>> 16));
// 库表索引
int dbIdx = idx / dbRouterConfig.getTbCount() + 1;
int tbIdx = idx - dbRouterConfig.getTbCount() * (dbIdx - 1);
// 设置到 ThreadLocal
DBContextHolder.setDBKey(String.format("%02d", dbIdx));
DBContextHolder.setTBKey(String.format("%02d", tbIdx));
logger.info("数据库路由 method:{} dbIdx:{} tbIdx:{}", getMethod(jp).getName(), dbIdx, tbIdx);
// 返回结果
try {
return jp.proceed();
} finally {
DBContextHolder.clearDBKey();
DBContextHolder.clearTBKey();
}
}
DBContextHolder这个自己定义是数据源是上下文 里面是两个ThreaLocal类型的dbKey 和tbKey
定义了set和get方法 还有clearDBKey()的方法 里面的dbKey.remove();
- 简化的核心逻辑实现代码如上,首先我们提取了库表乘积的数量,把它当成 HashMap 一样的长度进行使用。
- 接下来使用和 HashMap 一样的扰动函数逻辑,让数据分散的更加散列。
- 当计算完总长度上的一个索引位置后,还需要把这个位置折算到库表中,看看总体长度的索引因为落到哪个库哪个表。
- 最后是把这个计算的索引信息存放到 ThreadLocal 中,用于传递在方法调用过程中可以提取到索引信息。
5. Mybatis 拦截器处理分表
这块内容属于Mybatis源码系列的内容了 mybatis:基于mybatis拦截器分表实现。
- 最开始考虑直接在Mybatis对应的表 INSERT INTO user_strategy_export_${tbIdx} 添加字段的方式处理分表。但这样看上去并不优雅,不过也并不排除这种使用方式,仍然是可以使用的。
- 那么我们可以基于 Mybatis 拦截器进行处理,通过拦截 SQL 语句动态修改添加分表信息,再设置回 Mybatis 执行 SQL 中。
- 此外再完善一些分库分表路由的操作,比如配置默认的分库分表字段以及单字段入参时默认取此字段作为路由字段。
- Java中Pattern.compile函数的用法
@Intercepts({@Signature(type = StatementHandler.class, method = "prepare", args = {Connection.class, Integer.class})})
public class DynamicMybatisPlugin implements Interceptor {
private Pattern pattern = Pattern.compile("(from|into|update)[\\s]{1,}(\\w{1,})", Pattern.CASE_INSENSITIVE);
@Override
public Object intercept(Invocation invocation) throws Throwable {
// 获取StatementHandler
//先拦截到RoutingStatementHandler,
//里面有个StatementHandler类型的delegate变量,
//其实现类是BaseStatementHandler,然后就到BaseStatementHandler的成员变量mappedStatement
StatementHandler statementHandler = (StatementHandler) invocation.getTarget();
MetaObject metaObject = MetaObject.forObject(statementHandler, SystemMetaObject.DEFAULT_OBJECT_FACTORY, SystemMetaObject.DEFAULT_OBJECT_WRAPPER_FACTORY, new DefaultReflectorFactory());
MappedStatement mappedStatement = (MappedStatement) metaObject.getValue("delegate.mappedStatement");
// 获取自定义注解判断是否进行分表操作
String id = mappedStatement.getId();
String className = id.substring(0, id.lastIndexOf("."));
Class<?> clazz = Class.forName(className);
DBRouterStrategy dbRouterStrategy = clazz.getAnnotation(DBRouterStrategy.class);
if (null == dbRouterStrategy || !dbRouterStrategy.splitTable()){
// 传递给下一个拦截器处理
return invocation.proceed();
}
// 获取SQL
BoundSql boundSql = statementHandler.getBoundSql();
String sql = boundSql.getSql();
// 替换SQL表名 USER 为 USER_03
Matcher matcher = pattern.matcher(sql);
String tableName = null;
if (matcher.find()) {
tableName = matcher.group().trim();
}
assert null != tableName;
String replaceSql = matcher.replaceAll(tableName + "_" + DBContextHolder.getTBKey());
// 通过反射修改SQL语句
Field field = boundSql.getClass().getDeclaredField("sql");
field.setAccessible(true);
field.set(boundSql, replaceSql);
return invocation.proceed();
}
}
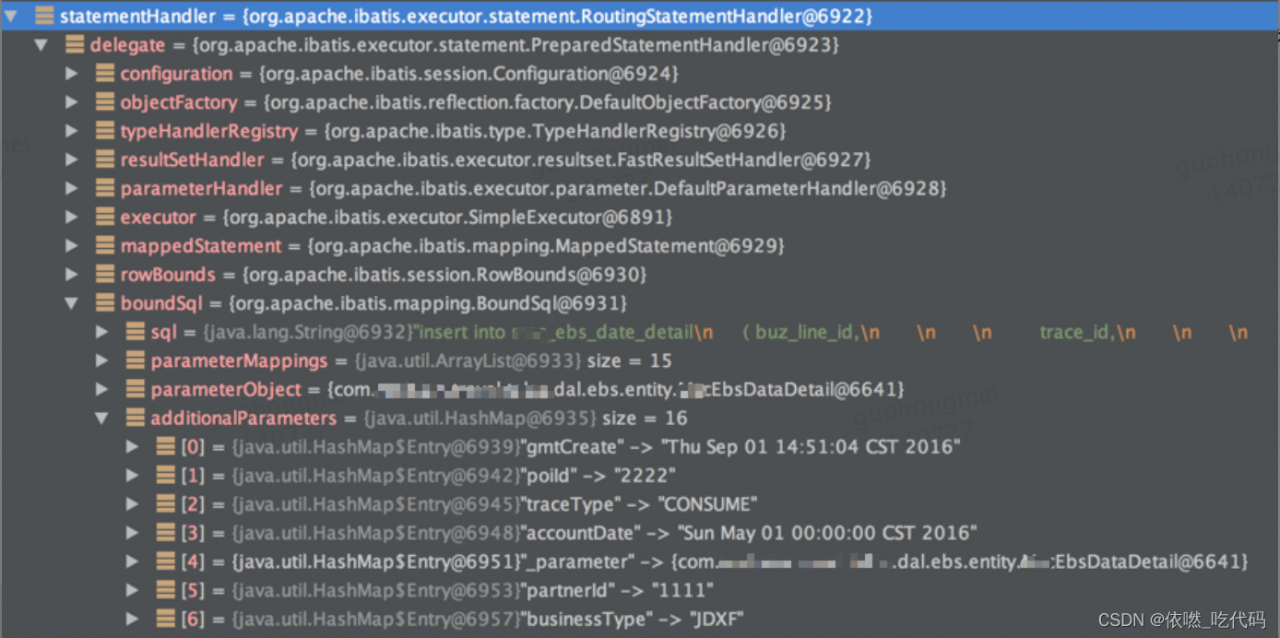
- 实现 Interceptor 接口的 intercept 方法,获取StatementHandler、通过自定义注解判断是否进行分表操作、获取SQL并替换SQL表名 USER 为 USER_03、最后通过反射修改SQL语句
- 此处会用到正则表达式拦截出匹配的sql,(from|into|update)[\s]{1,}(\w{1,})
最后
接下来就是验证环节了 验证分库与分表
- 打包 db-router-spring-boot-starter
- 引入 pom 文件
<dependency>
<groupId>cn.bugstack.middleware</groupId>
<artifactId>db-router-spring-boot-starter</artifactId>
<version>1.0.0-SNAPSHOT</version>
</dependency>
- 在需要使用数据库路由的DAO方法上加入注解
cn.itedus.lottery.infrastructure.dao.IUserTakeActivityDao
@Mapper
public interface IUserTakeActivityDao {
/**
* 插入用户领取活动信息
*
* @param userTakeActivity 入参
*/
@DBRouter(key = "uId")
void insert(UserTakeActivity userTakeActivity);
}
@DBRouter(key = “uId”) key 是入参对象中的属性,用于提取作为分库分表路由字段使用