PyTorch常用激活函数
在深度学习中,经常会见到各种各样的激活函数。为了更好的学习,总结下我经常用的激活函数。具体信息
可见官网
sigmoid


import torch.nn.functional as F
y=F.sigmoid(x) #x则是输入
所有的输出会被放缩在0到1之间
缺点:
- 会导致梯度消失的问题,网络只有微小的更新,无法有效学习
整流线性单元ReLU
表达式:ReLU(x)=max(0,x)

import torch.nn.functional as F
y=F.relu(x) #x则是输入
优点:
- 相比于 sigmoid,由于稀疏性,时间和空间复杂度更低;不涉及成本更高的指数运算;
- 能避免梯度消失问题
缺点:
- 引入了死亡 ReLU 问题,即网络的大部分分量都永远不会更新。但这有时候也是一个优势;
- ReLU 不能避免梯度爆炸问题
指数线性单元 ELU


优点:
- 能避免死亡 ReLU 问题;
- 能得到负值输出,这能帮助网络向正确的方向推动权重和偏置变化;
- 在计算梯度时能得到激活,而不是让它们等于 0;
缺点:
- 由于包含指数运算,所以计算时间更长;神经网络不学习 α 值。
渗漏型整流线性单元激活函数(Leaky ReLU)
渗漏型整流线性单元激活函数也有一个 α 值,通常取值在 0.1 到 0.3 之间。


import torch.nn.functional as F
y=F.leaky_relu((x),negative_slope=0.2) #x则是输入
优点:
- 类似 ELU,Leaky ReLU 也能避免死亡 ReLU 问题,因为其在计算导数时允许较小的梯度;
- 由于不包含指数运算,所以计算速度比 ELU 快。
缺点:
- 无法避免梯度爆炸问题;神经网络不学习 α 值。
Tanh
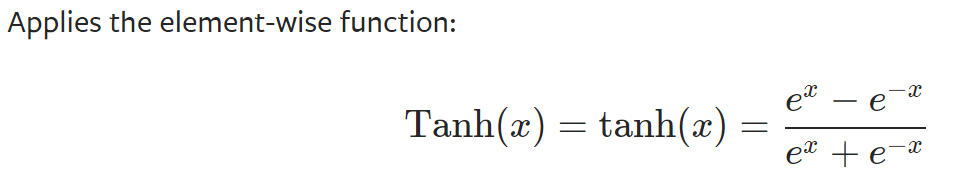

参考
https://mp.weixin.qq.com/s/np_QPpaBS63CXzbWBiXq5Q
版权声明:本文为Orientliu96原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。