我最近做的实验需要把都是图片的数据集转成numpy形式存储,然后放入模型训练。
首先要有一个.csv文件,这个文件存放了训练集中所有图片的名字和所属类别,共两列,这个文件在下载某些数据集的时候会自带或者有处理好的让你下载,但也可以自己生成,可以看
这里(要点三)
import pandas as pd
import cv2
import numpy as np
#读取存有图片名和对应类别名的.csv文件
train = pd.read_csv('train_new.csv')
#print(train)
#创建一个空的列表,后面用来存放训练集中的每张图片
train_image = []
'''
csv文件总共两列,一列图片名,一列对应类别名,这里就是遍历图片名,总共2408张
'''
for i in range(train.shape[0]):#2408
#加载图像,这里进入文件夹下,遍历csv文件中列名为'image'的列,即图片名,进而读取图片
img_cv2 = cv2.imread('train_1_50/'+train['image'][i])
#将目标大小设置为(224,224,3)
image = cv2.resize(img_cv2,(224,224),interpolation=cv2.INTER_AREA)
#像素值归一化
img = image / 255
#把图像加入train_image列表
train_image.append(img)
# 将列表转为numpy数组
X = np.array(train_image)#train_image中有2408张图片,都是numpy格式
# 查看数组的大小
print(X.shape)
# 查看数组
print(X)参考博文里大佬加载图像和设置图片大小是一行代码完成的,但用image.load_img读取的只是图片,然后再转成numpy形式,而cv2.imread可以一步完成。(我为什么要换呢,因为大佬的方式在我这里一直报错,我解决不了,私信大佬也不理我,555.。。)
# 加载图像,并将目标大小设置为(224,224,3)
img = image.load_img('train_1/'+train['image'][i], target_size=(224,224,3))
# 将其转换为数组
img = image.img_to_array(img)
看下效果:
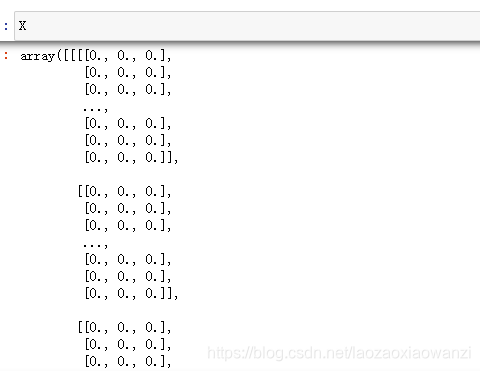
这里好多0是因为我的图片都是从视频中提取出来的,提取的有些图片正好上一帧下一帧的切换,故是黑色的,没有值,再加上数组显示不完全。
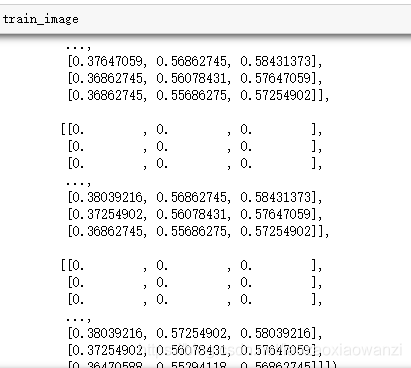
查看列表,就全部显示出来了。。。
版权声明:本文为laozaoxiaowanzi原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。