1
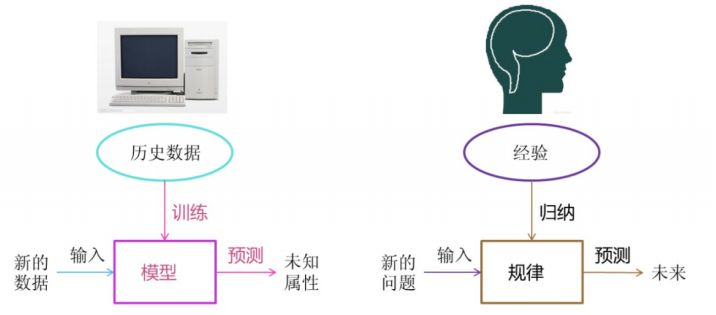
什么是机器学习
机器学习是从数据中自动分析获得模型,并利用模型对未知数据进行预测。
2
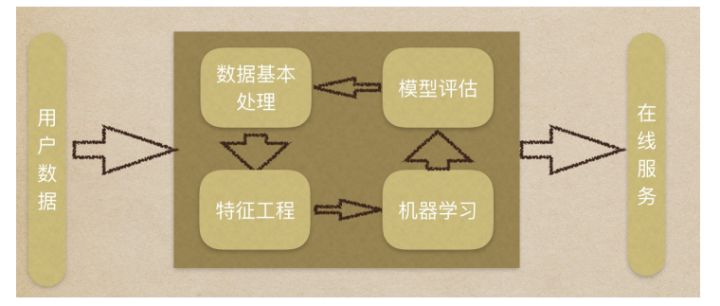
机器学习工作流程
-
1.
获取数据 -
2.
数据基本处理 -
3.
特征工程 -
4.
机器学习
(
模型训练
)
-
5.
模型评估
结果达到要求,上线服务
没有达到要求,重新上面步骤
2.1
获取到的数据集介绍

数据简介
在数据集中一般:
- 一行数据我们称为一个样本
- 一列数据我们成为一个特征
- 有些数据有目标值(标签值),有些数据没有目标值(如上表中,电影类型就是这个数据集的目标值)
数据类型构成:
- 数据类型一:特征值+目标值(目标值是连续的和离散的)
- 数据类型二:只有特征值,没有目标值
数据分割:
机器学习一般的数据集会划分为两个部分:
-
训练数据:用于训练,构
建模
型 - 测试数据:在模型检验时使用,用于评估模型是否有效
划分比例:
- 训练集:70% 80% 75%
- 测试集:30% 20% 25%
2.2
数据基本处理
即对数据进行缺失值、去除异常值等处理
2.3
特征工程
2.3.1什么是特征工程
特征工程是使用专业背景知识和技巧处理数据,使得特征能在机器学习算法上发挥更好的作用的过程。
- 意义:会直接影响机器学习的效果
2.3.2 为什么需要特征工程(Feature Engineering)
机器学习领域的大神Andrew Ng(吴恩达)老师说“Coming up with features is difficult, time-consuming, requires expert knowledge.
“Applied machine learning” is basically feature engineering. ”
注:业界广泛流传:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。
2.3.3 特征工程包含内容
- 特征提取
- 特征预处理
- 特征降维
2.3.4 各概念具体解释
- 特征提取
将任意数据(如文本或图像)转换为可用于机器学习的数字特征

- 特征预处理
通过一些转换函数将特征数据转换成更加适合算法模型的特征数据过程

- 特征降维
指在某些限定条件下,降低随机变量
(
特征
)
个数,得到一组
“
不相关
”
主变量的过程
2.4 机器学习
选择合适的算法对模型进行训练
2.5 模型评估
对训练好的模型进行评估
3 机器学习算法分类
根据数据集组成不同,可以把机器学习算法分为:
- 监督学习
- 无监督学习
- 半监督学习
- 强化学习
3.1 监督学习
定义:
输入数据是由输入特征值和目标值所组成。函数的输出可以是一个连续的值(称为回归),或是输出是有限个离散值(称作分类)。
3.1.1 回归问题
例如:预测房价,根据样本集拟合出一条连续曲线。

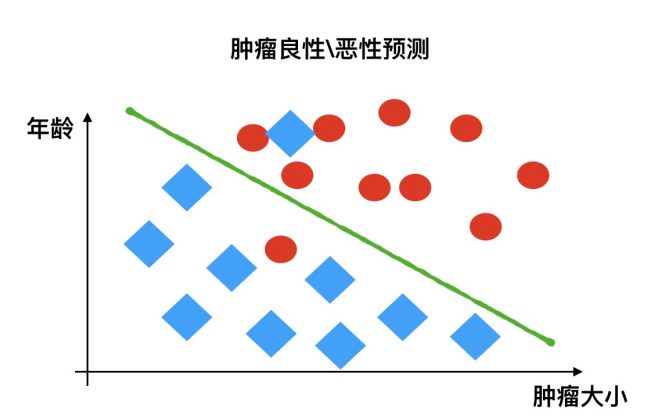
3.1.2 分类问题
例如:根据肿瘤特征判断良性还是恶性,得到的是结果是“良性”或者“恶性”,是离散的。
3.2 无监督学习
定义:
输入数据是由输入特征值组成,没有目标值
- 输入数据没有被标记,也没有确定的结果。样本数据类别未知;
- 需要根据样本间的相似性对样本集进行类别划分。
举例:

有监督,无监督算法对比:

3.3 半监督学习
定义:训练集同时包含有标记样本数据和未标记样本数据。
举例:
-
监督学习训练方式:
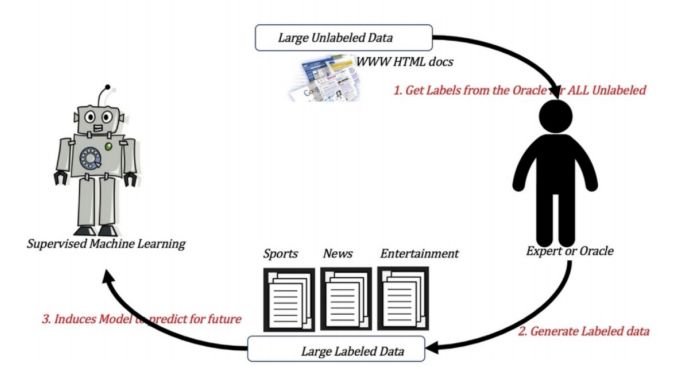
-
半监督学习训练方式
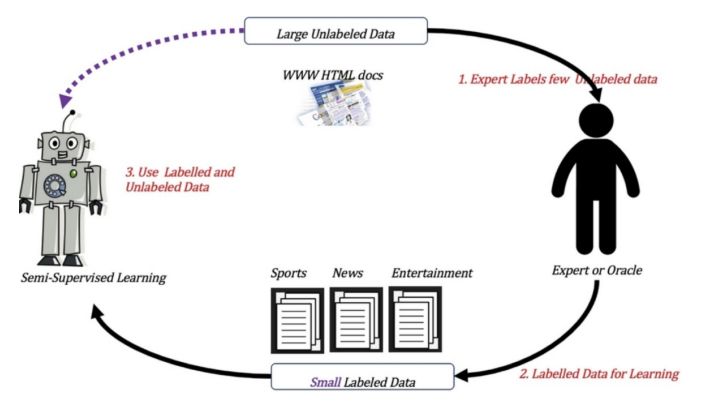
3.4 强化学习
定义:实质是make decisions 问题,即自动进行决策,并且可以做连续决策。
举例:小孩想要走路,但在这之前,他需要先站起来,站起来之后还要保持平衡,接下来还要先迈出一条腿,是左腿还是右腿,迈出一步后还要迈出下一步。
小孩就是 agent,他试图通过采取行动(即行走)来操纵环境(行走的表面),并且从一个状态转变到另一个状态(即他走的每一步),当他
完成任务的子任务(即走了几步)时,孩子得到奖励(给巧克力吃),并且当他不能走路时,就不会给巧克力。
主要包含五个元素:agent, action, reward, environment, observation;
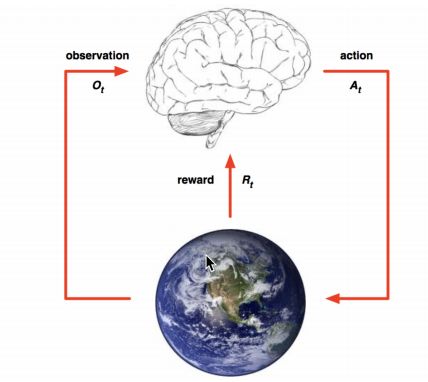
强化学习的目标就是获得最多的累计奖励。
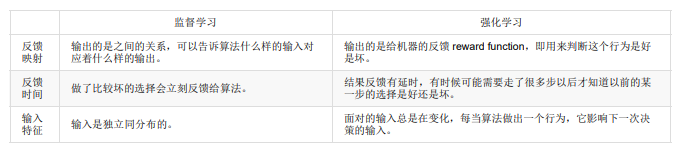
监督学习和强化学习的对比:
拓展概念:什么是独立同分布:
独立同分布概念
拓展阅读:Alphago进化史 漫画告诉你Zero为什么这么牛:
4 模型评估
4.1
分类模型评估

准确率
- 预测正确的数占样本总数的比例。
其他评价指标:精确率、召回率、
F1-score
、
AUC
指标等
4.2
回归模型评估
均方根误差(
Root Mean Squared Error
,
RMSE
)
- RMSE是一个衡量回归模型误差率的常用公式。 不过,它仅能比较误差是相同单位的模型。
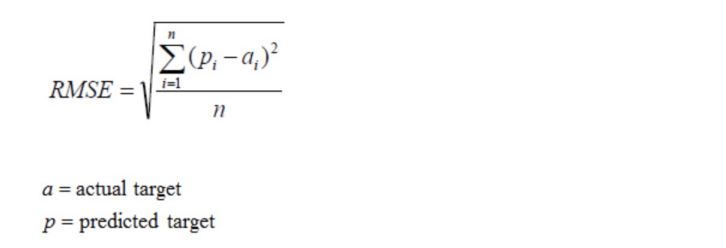
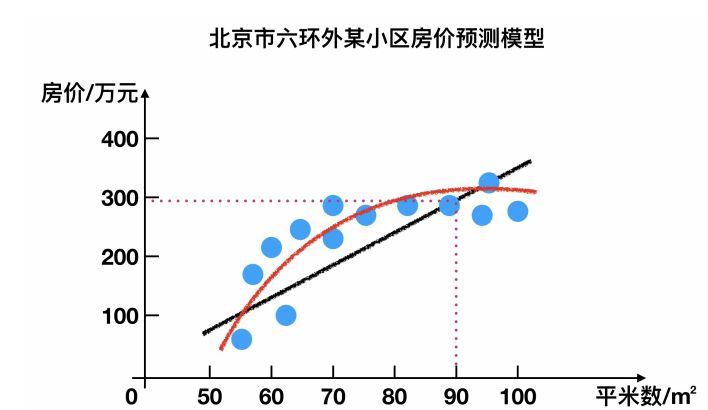
举例:
假设上面的房价预测,只有五个样本,对应的
真实值为:100,120,125,230,400
预测值为:105,119,120,230,410那么使用均方根误差求解得

其他评价指标:相对平方误差(
Relative Squared Error
,
RSE
)、平均绝对误差(
Mean Absolute Error
,
MAE)
、相对绝对误差 (
Relative Absolute Error
,
RAE)
4.3
拟合
模型评估用于评价训练好的的模型的表现效果,其表现效果大致可以分为两类:过拟合、欠拟合。
在训练过程中,你可能会遇到如下问题:
训练数据训练的很好啊,误差也不大,为什么在测试集上面有问题呢?
当算法在某个数据集当中出现这种情况,可能就出现了拟合问题。
4.3.1 欠拟合
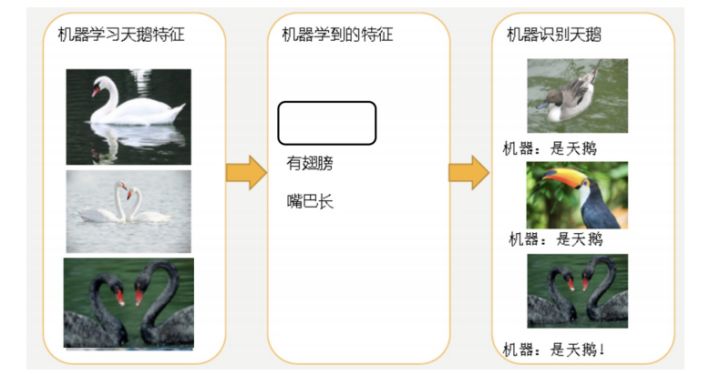
因为机器学习到的天鹅特征太少了,导致区分标准太粗糙,不能准确识别出天鹅。
欠拟合(
under-fitting
):模型学习的太过粗糙,连训练集中的样本数据特征关系都没有学出来。
4.3.2 过拟合

机器已经基本能区别天鹅和其他动物了。然后,很不巧已有的天鹅图片全是白天鹅的,于是机器经过学习后,会认为天鹅的羽毛都是白的,以后看到羽毛是黑的天鹅就会认为那不是天鹅。
过拟合(over-fitting):所建的机器学习模型或者是深度学习模型在训练样本中表现得过于优越,导致在测试数据集中表现不佳.
- 上问题解答:
训练数据训练的很好啊,误差也不大,为什么在测试集上面有问题呢?
5
Azure
机器学习模型搭建实验
Azure
平台简介
Azure Machine Learning(简称“AML”)是微软在其公有云Azure上推出的基于Web使用的一项机器学习服务,机器学习属人工智能的一个分支,它技术借助算法让电脑对大量流动数据集进行识别。这种方式能够通过历史数据来预测未来事件和行为,其实现方式明显优于传统的商业智能形式。
微软的目标是简化使用机器学习的过程,以便于开发人员、业务分析师和数据科学家进行广泛、便捷地应用。
这款服务的目的在于“将机器学习动力与云计算的简单性相结合”。
AML目前在微软的Global Azure云服务平台提供服务,用户可以通过站点:
https://studio.azureml.net/
申请免费试用。

-
Azure
机器学习实验
实验目的:了解机器学习从数据到建模并最终评估预测的整个流程。
书籍推荐:
- 《Python机器学习实践指南》 结合了机器学习和Python 语言两个热门的领域,通过利用两种核心的机器学习算法来用Python 做数据分析。
- 《Python机器学习——预测分析核心算法》 从算法和Python语言实现的角度,认识机器学习。
- 《机器学习实践应用》阿里机器学习专家力作,实战经验分享,基于阿里云机器学习平台,针对7个具体的业务场景,搭建了完整的解决方案。
- 《NLTK基础教程——用NLTK和Python库构建机器学习应用》绍如何通过NLTK库与一些Python库的结合从而实现复杂的NLP任务和机器学习应用。