前提,上次我用selenium写了一个抖音直播评论获取,这次烂活新整,用python发送post请求获取快手的视频评论!
1.首先打开网页版的快手
在网页里面按下F12,打开开发者模式,点击网络,查看Fetch/XHR。看看里面的请求。
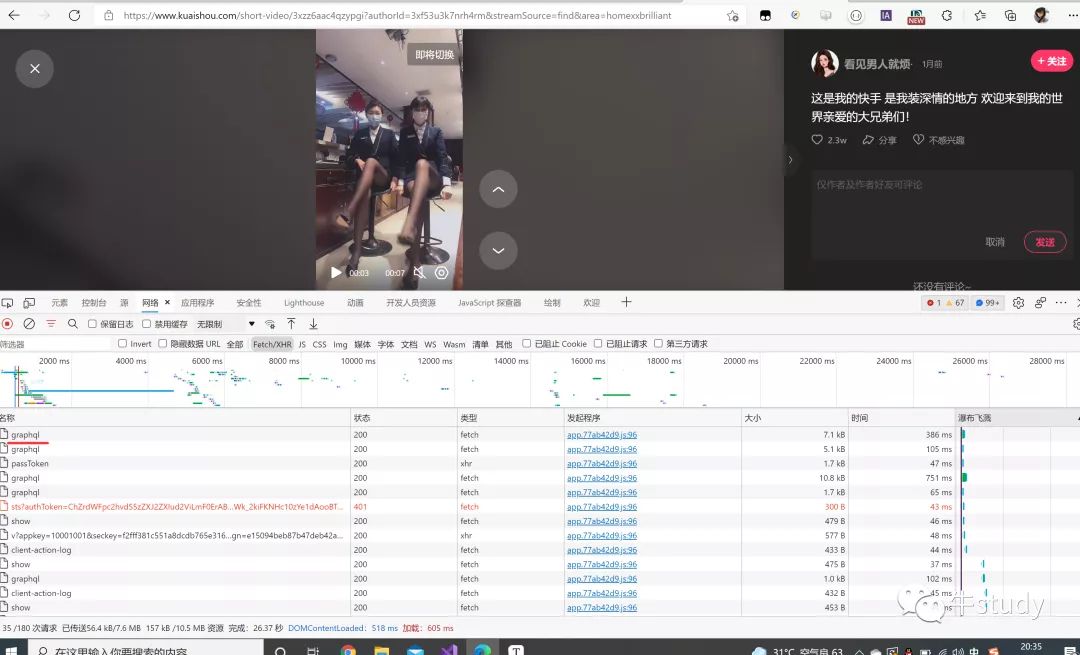
找到一个叫graphql的请求。这个就是评论的请求。我们点击进去,然后查看预览。可以看到如下效果。
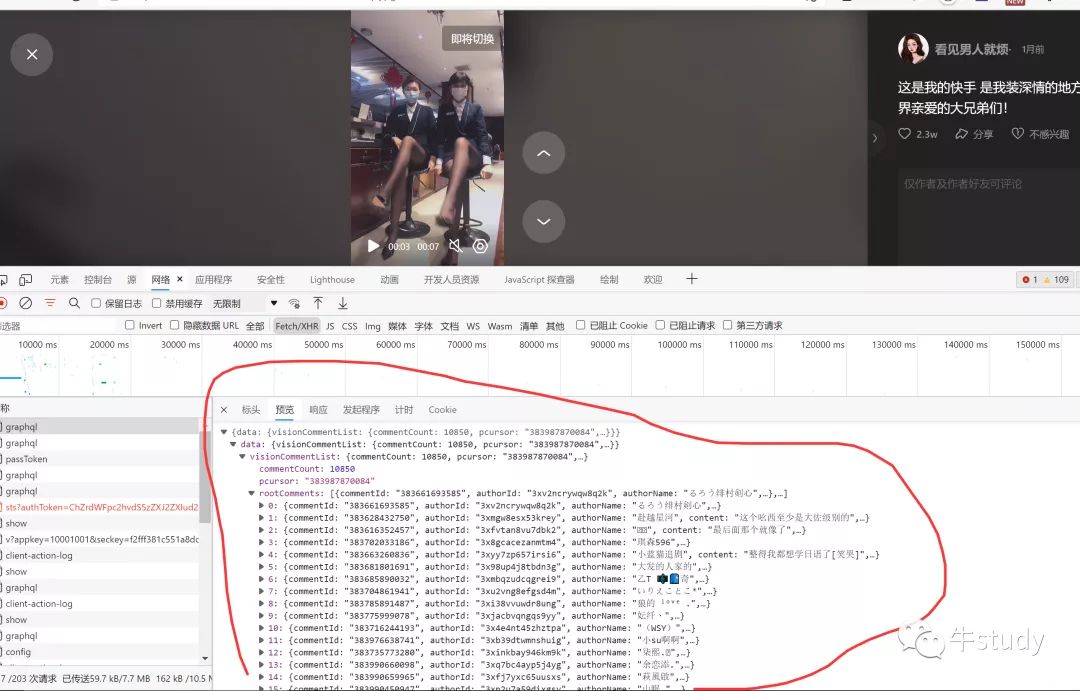
返回的是一个json数据,这下就好办了。我们现在只要模仿浏览器给快手服务器发送请求就行了。
2.发送请求给快手服务器
首先,我们来看一下这个是个什么请求,是个get请求还是post请求。(一般都是post)点击表头。查看请求。
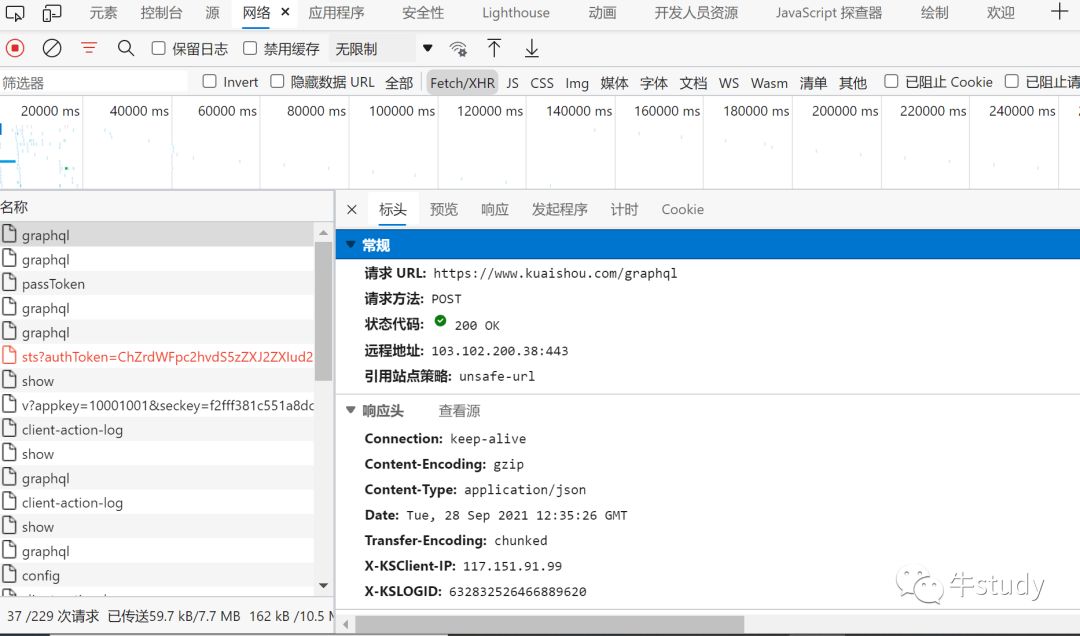
我们可以看到,这是个post请求,请求url是
https://www.kuaishou.com/graphql
,发送post请求都是要带一些表单数据的。
看看表单数据要传输哪些数据
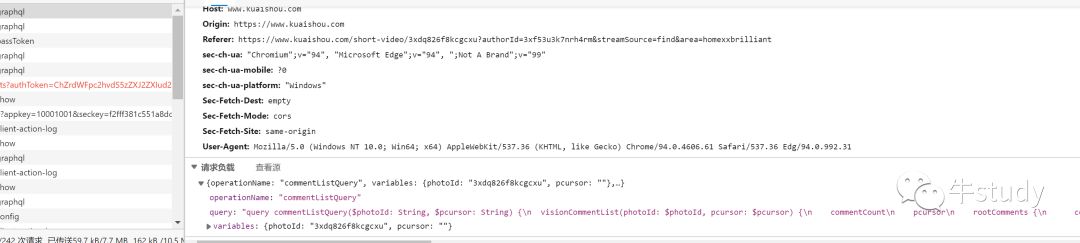
可以看到这个请求负载里的数据就是我们要传输的数据了,这个请求负载不同于Form data的。Form data传输的一个字典,而 Request Payload是一个json数据。这个有所不同,如果你此时还是传入一个dict数据的话,是不会返回数据的。必须传入json数据。那么我现在就可以用python发送请求了。做到这里一切都很顺利!!

3.用python发送请求
import requests
import json
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.61 Safari/537.36 Edg/94.0.992.31',
'Cookie': 'kpf=PC_WEB; kpn=KUAISHOU_VISION; clientid=3; did=web_1e83306028e4691a0acb7f78ecfbf145; didv=1632459485000; client_key=65890b29; Hm_lvt_86a27b7db2c5c0ae37fee4a8a35033ee=1632459683; userId=153866369; kuaishou.server.web_st=ChZrdWFpc2hvdS5zZXJ2ZXIud2ViLnN0EqABSkrOjzdufZa4lBYXxddWpU-Da_CebI6GVHm2vvSBBxRUv9kJ_BKaJ3weX3FWf3acdLw2yy6uCM1MpHB8Pfi7EnJBlcRb0GqyXYMpPlaCdMqKlVo0PI-iY9zN0wdxA89wOXtml-fWR7CFTT54hsd3PZTsTwlWBA7vhJvwim07-A1RaTmwi66PbBkj7eCrkmJX0hdCln9MiFVyA_CL44TScBoSuDcrlwmr6APhXfdZrBO5uo0FIiA8xE-BzwPs3Wp_Q9mI4y5GcZxo1E-B0xr4CkR4zohqJigFMAE; kuaishou.server.web_ph=eeb2272fa742f8d8f79bd635c3e8044ac1f8'}
data = {
"operationName": "commentListQuery",
"variables": {
"photoId": "3xhcrvum26yz3vg",
"pcursor": ''
},
"query": "query commentListQuery($photoId: String, $pcursor: String) {\n visionCommentList(photoId: $photoId, pcursor: $pcursor) {\n commentCount\n pcursor\n rootComments {\n commentId\n authorId\n authorName\n content\n headurl\n timestamp\n likedCount\n realLikedCount\n liked\n status\n subCommentCount\n subCommentsPcursor\n subComments {\n commentId\n authorId\n authorName\n content\n headurl\n timestamp\n likedCount\n realLikedCount\n liked\n status\n replyToUserName\n replyTo\n __typename\n }\n __typename\n }\n __typename\n }\n}\n"
}
conment = requests.post('https://www.kuaishou.com/graphql', headers=headers, json=data)
conments = json.loads(conment.text)
print(conments)此时,就一个成功返回json数据了。
但是,好像有个问题,只有28条,
返回数据不全
,
what,fuck!
,看来是遇到问题了。

没关系,我又重新运行了几次,还是不行。我又回到快手页面。又打开开发者模式。开始找问题。突然我发现,有好多个叫graphql的请求。此时,我就猜想,是不是这个是动态加载的,你将评论往下滑,它才会加载。取好几个graphql的请求数据进行对比,发现只有photoId和pcursor其中的数据不同。经过我的仔细查找发现,这个photoId就是这个视频的id,那个网页地址上都有。不同的视频photold才不同。行了,photold解决了,那pucursor呢,
这个是个什么鬼?
我看了几个graphql的传输的数据,除了第一个graphql的pucursor是空的。其他的都全是数字。然后我打印了那返回不全的json的数据。
发现了一个惊人的秘密
。pucursor里面数据是上一个graphql返回的数据里面最后一个人的id。
解密了!!!
,他是动态渲染的,pucursor接收上一个发评论的人的id来发送下一个请求,从而请求数据。

4.最后来请求完整数据
先写好主程序,最后来个递归就解决一切,评论顺利到手!!!
import requests
import json
import sys
lists = []
def text(w):
ww =0
list = []
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.61 Safari/537.36 Edg/94.0.992.31',
'Cookie': 'kpf=PC_WEB; kpn=KUAISHOU_VISION; clientid=3; did=web_1e83306028e4691a0acb7f78ecfbf145; didv=1632459485000; client_key=65890b29; Hm_lvt_86a27b7db2c5c0ae37fee4a8a35033ee=1632459683; userId=153866369; kuaishou.server.web_st=ChZrdWFpc2hvdS5zZXJ2ZXIud2ViLnN0EqABSkrOjzdufZa4lBYXxddWpU-Da_CebI6GVHm2vvSBBxRUv9kJ_BKaJ3weX3FWf3acdLw2yy6uCM1MpHB8Pfi7EnJBlcRb0GqyXYMpPlaCdMqKlVo0PI-iY9zN0wdxA89wOXtml-fWR7CFTT54hsd3PZTsTwlWBA7vhJvwim07-A1RaTmwi66PbBkj7eCrkmJX0hdCln9MiFVyA_CL44TScBoSuDcrlwmr6APhXfdZrBO5uo0FIiA8xE-BzwPs3Wp_Q9mI4y5GcZxo1E-B0xr4CkR4zohqJigFMAE; kuaishou.server.web_ph=eeb2272fa742f8d8f79bd635c3e8044ac1f8'}
data = {
"operationName": "commentListQuery",
"variables": {
"photoId": "3xhcrvum26yz3vg",
"pcursor": str(w)
},
"query": "query commentListQuery($photoId: String, $pcursor: String) {\n visionCommentList(photoId: $photoId, pcursor: $pcursor) {\n commentCount\n pcursor\n rootComments {\n commentId\n authorId\n authorName\n content\n headurl\n timestamp\n likedCount\n realLikedCount\n liked\n status\n subCommentCount\n subCommentsPcursor\n subComments {\n commentId\n authorId\n authorName\n content\n headurl\n timestamp\n likedCount\n realLikedCount\n liked\n status\n replyToUserName\n replyTo\n __typename\n }\n __typename\n }\n __typename\n }\n}\n"
}
conment = requests.post('https://www.kuaishou.com/graphql', headers=headers, json=data)
conments = json.loads(conment.text)
#print(conments['data'])
s = len(conments['data']['visionCommentList']['rootComments']) - 1
#print(conments['data']['visionCommentList']['rootComments'][s]['commentId'])
for ii in range(0,s):
#print(len(conments['data']['visionCommentList']['rootComments']))
#print(conments['data']['visionCommentList']['rootComments'][s])
print(conments['data']['visionCommentList']['rootComments'][ii]['content'])
www = conments['data']['visionCommentList']['rootComments'][ii]['content']
w = conments['data']['visionCommentList']['rootComments'][ii]['commentId']
if len(lists)!=-1 :
lists.append(www)
print('111111')
if len(lists)!=1:
a = lists[-2]
if lists[-1] == a and len(lists) != 1:
print("评论已经爬完")
sys.exit()
for a in range(0,len(list)):
ww +=list[a]
print(ww)
return w
w = ''
while w!=1:
w = text(w)
兄弟们,今天就到这里了,剩余就靠你们自己发挥了,(偷偷告诉你们哦,这个不止可以对快手哦,好多网站都可以这样)。
但是还是遵守法律法规。
下次教兄弟们怎么用python群发消息,也是post请求哦!
