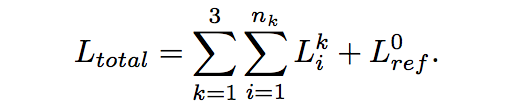可学习的多视图PatchMatchStereo
目录
前言
PatchMatch主要用于在两幅二维图像中搜索最近领域中相似度最高的patch。其主要基于随机采样(random sampling)思想,并根据图像区域相似性,提供一种在整个图像区域快速propagate以提高搜索与匹配效率的机制。
PatchMatchStereo是在PatchMatch思想基础上,由Microsoft Research 提出的一种三维立体匹配算法。二维图像扩展到视频匹配会带来更多的难点,由于包含每个像素有近似无限的三维平面,那么如何找到一个最优三维平面是面临的关键问题。文章贡献在于2点:(1)视图步进,按照立体匹配对从左视图至右视图的顺序完成平面步进;(2)时间步进,按照一段视频连续帧从前至后的顺序完成平面步进(目标移动很小的情况)。
PatchmatchNet:一种新颖的,可学习的patchmatch来实现高分辨率的MVS。具有高速度和低内存需求,相比于使用正则的3D cost volume,patchMatch可以处理高分辨率的图像,更适合资源有限的设备。在端对端训练结构中实现一个多尺度迭代,每次迭代中patchmatch的核心算法是通过一个新颖的,可学习的自适应传播和评估方案实现的。性能比现有的最好的mvs方案快至少2.5倍,内存占用少2倍。
1、介绍
MVS是利用已知位姿的图片,对观察到的场景进行几何重建。仍存在一些问题亟待解决:遮挡、亮度变化、弱纹理、非博朗基曲面。
目前,许多基于学习的MVS方法构建3D cost volume,用3D CNN对其进行正则化并回归深度。由于3D CNN通常耗费时间和内存,一些方法在特征提取过程中对输入进行下采样,并在低分辨率下计算cost volume和深度图。

从上图可以看出,低分辨率传递深度图会影响其精度。由于内存限制,这些方法无法有效利用图像原有的尺寸。显然,在一些应用上比如手机设备,头戴AR或者其它时间要求严苛的应用上,低内存和时间消耗是关键。最近,研究者们在试图减轻这种限制。比如,R-MVSNet从深度范围和序列化处理cost volume解耦内存消耗,但是代价是额外的时间消耗。包含级联的3D cost volume从粗到精地预测高分辨率深度图,在时间和内存上效率高。
几种传统的MVS方法都是基于原始的Patchmatch算法,而不是完全保持结构化的cost volume。Patchmatch采用随机迭代算法实现近似最近邻域计算。特别的,深度图的内在空间的相关性被用来快速找到好的方案,无需查找所有的可能性。对我们基于MVS的深度学习方法设置中,patch低内存要求独立于视差范围和隐式平滑效果使这个方法熠熠生辉。
在这项工作中,我们提出了PatchmatchNet,一种新的基于学习的Patchmatch的级联公式,其目的是减少高分辨率mvs的内存消耗和运行时间,同时也旨在提高深度学习的性能。
- 将Patchmatch的思想引入到一个基于MVS的端到端可训练的深度学习框架中。更进一步,将模型嵌入到一个由粗到精的框架中,以加快计算速度。
- 我们用可学习的、自适应的模块来增强Patchmatch的传统传播和代价计算来提高精度,并将其用于深层特征。在为sources views的代价聚合时建立可视化信息。此外,还提出了一种鲁棒性训练策略,将随机性引入到训练中,以提高可见性估计和泛化的鲁棒性。
- 在不同的MVS数据集上验证了该方法的有效性。
2、相关工作
A.传统的MVS
传统MVS方法可划分为四种:基于体素的,基于曲面估计的,基于patch的,基于深度图的。基于深度图的方法更简洁灵活。在这里我们讨论patchmatch 立体方法。Galliani 提出了Gipuma,一个大规模并行的Patchmatch stereo的多视图拓展。它在传播过程中使用红黑棋盘格去并行信息传递。Schonberger提出COLMAP,包括了pixel-wise 视图选择,深度图,曲面法线。ACMM采用自适应棋盘格采样,multi-hypothesis用于视图选择和多尺度几何一致性引导中。由Patchmatch的思想,本文提出了基于学习的Patchmatch,它继承了经典Patchmatch的效率,同时利用深度学习提高了性能。
B.基于学习的立体视觉
GCNet介绍了利用3D cost volume 正则化来实现三维重建,用soft argmin回归最终的视差图。PSMNet加了一个空间金字塔池化,并用3D沙漏网络来正则化。DeepPruner提出了一个没有可学习参数的可微分的Patch模块,丢弃大部分视差,然后建立一个轻量级的 cost volume ,并用3D CNN来正则化。相反,我们不适用任何 cost volume ,而是将原始的patch思想和深度学习结合在一起。xu 提出了基于稀疏点的尺度内代价聚合方法,使用了可变卷积。同样地,我们提出了一个自适应采样点的策略来进行空间代价聚合。
C.基于学习的MVS
基于体素的方法仅限于小规模的重建,这是由于体素表示的缺点。相反,基于平面扫描立体,最近有许多工作使用深度图来重建场景,他们通过warp多个视图的特征来构建 cost volume ,并用3D CNN正则化,回归出深度。因为3d cnn非常耗时和耗内存,对 cost volume 采取下采样。为了减少内存,R-MVSNet用GRU在运行时序列化正则2d代价,但是这牺牲了运行时间。目前研究的目标是提高效率同时建立高分辨率的深度图。CasMVSNet提出了基于特征金字塔的级联代价体,由粗到精构建深度图。UCS-Net提出了级联自适应thin volumes,为了自适应构建采用基于方差的不确定度估计。CVP-MVSNet 形成了一个图像金字塔,也构建了 cost volume 金字塔。为了加速Patch传播,我们同样采用了一个级联结构。除了级联 cost volume 之外,PVSNet 学习预测每个原图像的可见性。一个抗噪声训练策略被用于处理干扰的视图。我们还学习了一种自适应策略组合基于的多个视图的信息可见性信息。此外,我们提出了一种鲁棒的训练方法在训练中加入随机性的策略来提高可见性估计和泛化的鲁棒性。Fast-MVSNet 构建了一个稀疏代价体来学习一个稀疏的深度图然后用高分辨率RGB图像和2DCNN来稠密化它。我们构建的优化模块是基于MSG-Net,用RGB来引导depth上采样。验证了我们方法的有效性,比如DTU,Tanks&Temples,ETH3D。结果证明与大多数基于学习的方法相比,我们的方法在减少内存和时间上更具有竞争力。
3、PatchmatchNet
如下图,Patchmatch-Net的结构。它由多尺度特征提取、基于学习的Patchmatch(迭代地由粗到细的框架)和一个空间优化模块三部分组成。

A.多尺度特征提取
N张尺寸为 W x H 的输入图像,我们用I0表示参考图像,Ii表示源图像。在应用基于学习的Patchmatch算法之前,从输入图像中提取了像素级的特征,与特征金字塔网络(FPN)相似。特征在多分辨率图像上分层提取,可以加速我们的深度图由粗到细的计算。
B.基于学习的PatchMatch
继传统的Patch Match和自适应的深度图计算,我们的可学习的patchmatch包括以下三个步骤:
- 初始化:生成随机假设
- 传播:邻居间传播假设
- 评估:计算所有假设匹配成本并选择最佳解决方案
初始化后,该方法在传播和评估之间迭代,直至收敛。基于深度学习,我们提出了传播的自适应版本、评估模块和初始化调整。 Patchmatch流程的详细结构如下图所示。

简单地说,传播模块根据提取的深层特征自适应地对传播点进行采样。自适应评估学习估计可见性信息进行代价计算,并根据深度特征对空间邻域进行自适应采样以再次聚合代价。因为内存消耗很大,我们避免将每个像素的假设参数化为一个倾斜平面。相反,我们依靠基于学习的自适应评估来组织窗口内的空间模式,在该窗口内计算匹配成本。
a.初始化和局部扰动
在Patchmatch的第一次迭代中,以随机方式进行初始化以促进多样化。基于预定义的深度范围[dmin,dmax],在[1/dmax,1/dmin]范围内取Df个间隔初始化每个depth的像素值,实现在图像空间的均匀采样。使我们的模型能应用于复杂的大场景。
对于后k次迭代,对每个像素的每个假设值Nk附加波动值。波动值为归一化逆区间Rk乘一个因子,来执行局部扰动,并且对于更精细的阶段,Rk逐渐减小(因子随深度分辨率增加而减小)。为了确定Rk的中心,利用上一次迭代的估计,即对较粗阶段上采样。
b.自适应传播
深度值的空间相干性通常只适用于来自同一物理表面的像素。因此,与Gipuma和DeepPruner采用一个固定的邻域集合来传播深度不同,PatchmatchNet使用一种自适应传播方法聚合近似曲面。这有助于Patchmatch更快地收敛并提供更精确的深度图。如下图,
自适应传播
倾向于收集同一表面的像素——对于有纹理的物体和无纹理的区域使我们能够有效地找到期望的深度值。

在可变形卷积神经网络网络上实现。因为该方法在每个分辨率上都是相同的,我们就不再区分。为了获取参考图像中每个像素p的Kp个深度假设值,模型学习了一个附加的2D偏移量Δoi应用到用栅格组织的固定偏移量o上。在参考图的特征图F0上应用2D CNN来为每一个像素学习一个额外的2D偏移量。并通过双线性插值获得深度值Dp:
式中D是来自上一次迭代的深度值,可能是从较粗阶段(低分辨率深度)采样的。
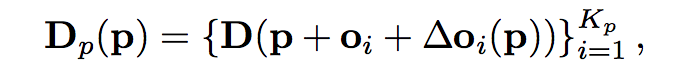
c.自适应评估
自适应评估包括:可微扭曲,匹配代价计算,自适应空间代价传播和深度回归。
可微扭曲
继平面扫描立体视觉之后,大多数基于学习的MVS方法在每个深度假设值上建立一个平行平面,并将源图像的特征映射扭曲到其中。通过参考帧和源图像的内参矩阵和位姿转换关系,我们在齐次坐标中为参考中的像素p计算源中相应的像素pij,深度假设dj:
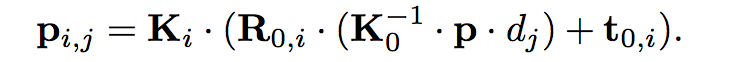
通过可微双线性插值得到扭曲源图像i的第j深度假设值的特征映射,Fi(pij)
匹配代价计算
对于多视立体视觉,这一步必须整合来自任意数量的源图像信息到单个像素p的单个深度值的代价值dj。为此我们通过group-wise(将特征的相关性通道降低至Group的个数,减少内存)相关性来计算每个像素的匹配代价,并使用像素视图权重对视图进行聚合。通过这种方式,我们可以在代价聚合过程使用可见性信息并获得鲁棒性。最后,通过一个小的网络,将每个group的代价预测成一个单一的数字,投影到参考帧的每个像素和深度假设。
设F0(p),Fi(pi,j)分别表示参考视图和源视图的特征。将特征通道平均划分为G组后,F0(p)g 和Fi(pi;j)g表示第g组的特征,它们的相似性Si(p,j)g计算如下:
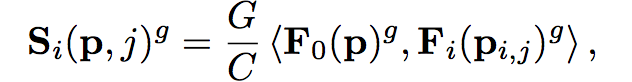
为了计算像素级的视图权重,利用我们在stage3的最初的深度假设集的多样性。我们用wi§表示图像Ii在像素p的可见性信息。权重被计算一次后被固定,上采样到更精细的stage。
一个简单的像素级视图权重网络,由具有1x1x1的3D卷积和非线性sigmoid组成,采用初始相似集Si输出每个像素0到1之间的数字,Pi ∈R[wxhxD]。像素p和源图像Ii的视图权重由下式给出:
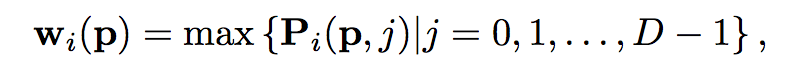
最后每个group的相似性由下式给出:
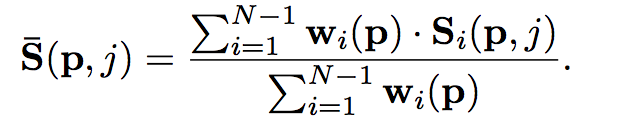
最终得到每个像素的每个group的相似性S∈R[WxHxDxG],用一个带有3D卷积(1x1x1)的小网络即可得到每个像素的每个深度假设值的一个单独的代价值。
自适应空间代价传播
传统的MVS匹配算法通常在一个空间域上聚合代价(我们使用的是平行平面)来提高匹配的鲁棒性和一个隐含的平滑效果。可以说,我们的多尺度特征提取已经从一个大的接受域中包含了邻域信息。不过,我们还是使用空间代价聚合。为了防止聚合穿过曲面边界的问题,提出了基于Patchmatch和AANet的自适应代价聚合。对于一个空间窗口Ke个像素p被划分成栅格,我们学习每个像素的附加偏移量Δp,聚合空间代价C(p,j)定义为
其中wk和dk基于特征和深度相似性加权成本C。
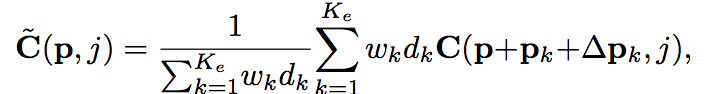
Δpkj通过在参考帧的特征图上做2D CNN得到的。如下图所示,被采样的位置都在边界内,采样的位置保持在对象内边界,而对于无纹理区域,采样点聚集在一个更大的空间环境中可以潜在地减少估计的不确定性。

(a) 深度预测的参考图像。
(b) 固定取样位置。
(c) 本方法的自适应采样位置。
(b)和(c)中的灰度图是置信深度图。
深度回归
使用softmax激活函数,我们将代价C转化为概率P,用于亚像素深度回归和ground truth估计。像素p处的累积深度值D(p)表示如下:
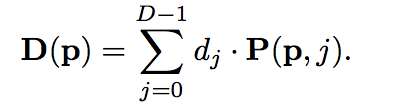
C.深度图优化
我们发现直接上采样(W/2 x H/2 to W x H) 和用RGB图像来优化估计是有效的。基于MSG-Net设计深度残差网络。为了避免对某个深度比例产生偏差,我们预先将深度归一化到[0,1],并在细化后再恢复。我们的网络输出了一个残差值被加到Patchmatch的(上采样)估计D中,得到细化的深度图Dref。该网络独立地从D和I0中提取特征映射FD和FI。应用Fd上的反卷积到上采样到图像尺寸。应用多个2D卷积层顶部连接的两个特征映射-深度映射和图像-传递深度残差。
D.损失函数
Ltotal表示所有的深度估计和在相同分辨率上的ground truth的所有loss的总和: