一、为什么要有矢量数据类型
向量化并行是现代处理器提升性能的重要方法。X86架构的CPU中的SSE/AVX都是SIMD(SingleInstruction Multiple Data,单指令多数据)模式。而当前GPU架构则是采用SIMT(SignleInstructtion Multiple Thread,单指令多线程)模式。
对于当前GPU架构来说,向量化的方法是SIMT。一个指令,同时有多个工作项执行。工作项映射到GPU上的硬件单元(AMD GPU为stream processor,NVIDIA GPU为CUDA Core)执行。这样的硬件单元处理的是标量数据。这使得我们在编写内核代码时无须显式地编写向量化代码,降低了GPGPU程序开发难度。对于GPU这样的设备,我们在内核直接使用标量数据即可。
二、OPENCL向量类型
下表中,变量类型后面是一个n来定义矢量中的元素个数,对所有矢量数据类型,支持的n值包括2、3、4、8和16。另外,double类型的矢量数据也是需要设备支持双精度时才可用。
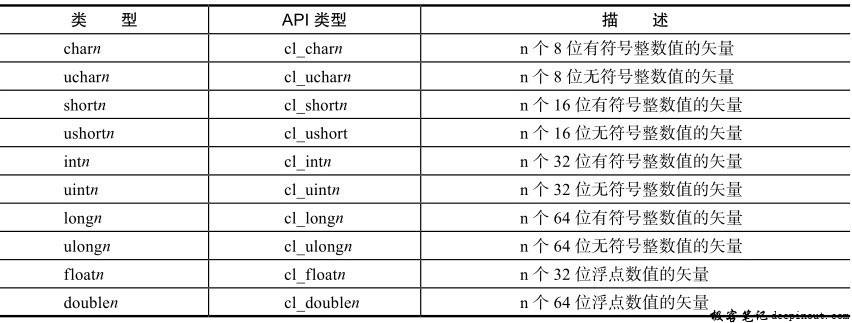
声明为一个标量或矢量数据类型的变量要按所用数据类型的大小(字节数)对齐。内置的数据类型大小按2的幂字节数对齐。如果一个内置数据类型的大小不是2的幂,则要按紧邻的下一个2的幂值对齐。例如,一个f loat4变量要按16字节边界对齐,char2变量要按2字节边界对齐。一个包含3个分量的矢量数据类型,这个数据类型的大小为
4*sizeof
(分量),这说明了包含3个分量的矢量数据类型要按
4*sizeof
(分量)边界对齐。
三、CUDA/HIP向量类型


四、OPENCL 与CUDA/HIP关于vec3内存地址对齐的区别
1、对于OPENCL,vec3地址对齐与同类型vec4一致,换言之,vec3对齐与同类型vec4对齐一致。
2、对于CUDA/HIP,vec3地址对齐与向量元素类型对齐一致(可以通过上面各个类型对齐表来加深理解)
五、实际应用
在将OpenCL-CTS中的test_conformance/vectors例子移植到CUDA/HIP平台上就会遇到OPENCL与CUDA/HIP关于vec3内存地址对齐的区别,需要根据CUDA/HIP的特性修改代码使得该例子可以在CUDA/HIP上测试通过。
参考文献:
2.CUDA_C_Programming_Guide(NVIDIA官网文档)