气象数据集
-
关于MapReduce
MapReduce是一种可用于数据处理的编程模型,它本质上是并行运行的,因此可以将大规模的数据分析任务分发给任何一个拥有足够多机器的数据中心。MapReduce的优势在于处理大规模数据集,这里我们先看一个数据集。
我们今天的目的是:在大批量的气象数据中,获取每年每月的最高气温。
-
数据格式
我们使用的数据来自于权威指南提供的美国国家气候数据中心,该数据按行为单位,每一行包含日期、气温、地点等等信息。比如下列数据为:1901年12月29日到31日的数据,相信细心的你会找到日期的,而温度是每一行的第87到92个字符(包含正负号)。0029227070999991901122913004+62167+030650FM-12+010299999V0200701N002119999999N0000001N9-01561+99999100271ADDGF104991999999999999999999 0029227070999991901122920004+62167+030650FM-12+010299999V0200701N002119999999N0000001N9-02001+99999100501ADDGF107991999999999999999999 0029227070999991901123006004+62167+030650FM-12+010299999V0200701N003119999999N0000001N9-01501+99999100791ADDGF108991999999999999999999 0029227070999991901123013004+62167+030650FM-12+010299999V0200901N003119999999N0000001N9-01331+99999100901ADDGF108991999999999999999999 0029227070999991901123020004+62167+030650FM-12+010299999V0200701N002119999999N0000001N9-01221+99999100831ADDGF108991999999999999999999 0029227070999991901123106004+62167+030650FM-12+010299999V0200701N004119999999N0000001N9-01391+99999100521ADDGF108991999999999999999999 0029227070999991901123113004+62167+030650FM-12+010299999V0200701N003119999999N0000001N9-01391+99999100321ADDGF108991999999999999999999 0029227070999991901123120004+62167+030650FM-12+010299999V0200701N004119999999N0000001N9-01391+99999100281ADDGF108991999999999999999999 -
测试数据下载
Hadoop测试数据–气象数据集
使用MapReduce来分析数据
为了充分利用Hadoop提供的并行处理优势,我们需要将查询表示成MapReduce作业,完成某种本地端的小规模测试之后,就可以把作业部署到集群上运行。
-
Map和Reduce
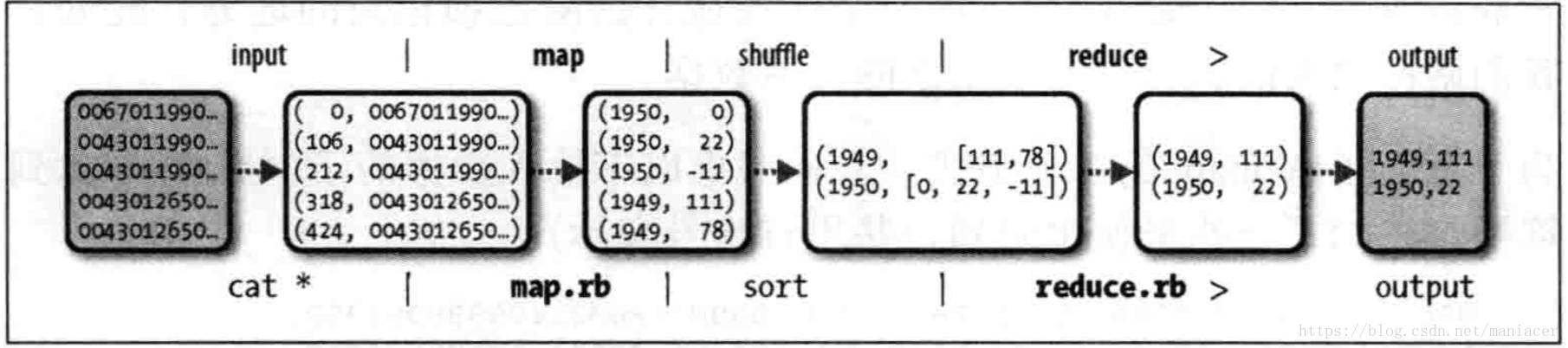
MapReduce任务过程分为两个处理阶段:Map阶段和Reduce阶段,每阶段都以 键-值 作为输入和输出,其类型又开发者根据实际情况自行决定。我们需要编写两个函数:Map函数和Reduce函数。
Map阶段的输入是你刚刚下载的气象数据集,每一行就是一条气象数据,Map的输入的值的格式就是文本格式(String),键就是每一行的起始位置相对于整片内容的偏移量,在这里无实际意义,给Long类型即可。Map函数实现的功能很简单,就是将每一行的数据进行截取,得到我们需要的年份、月份以及气温数据。
为了全面了解Map的工作方式,我们考虑以下输入数据的实例数据(将中间无用的数据省略了,并用省略号表示):
0029227070999991901123013004......N0000001N9-01391+99999100321A......
0029227070999991901123120004......N0000001N9-01391+99999100281A......
这些行以键值对的方式作为map输入
(0,0029227070999991901123013004......N0000001N9-01391+99999100321A......),
(106,0029227070999991901123120004......N0000001N9-01391+99999100281A......)key是文件中的行起始位置的偏移量,Map函数本身不需要这个,所以将其忽略掉,Map函数只需要提取年份月份、气温信息,并将他们作为以下格式输出给Reduce:
(190110, 12),
(190110, 15),
(190111, 22),
(190112, 11)...Map 函数的输出经由Map Reduce框架处理后,最后发送给reduce函数。这个过程基于键来对键值对进行排序和分组。因此,reduce函数接收到的是如下输入:
(190110, [12, 15]),
(190111, 22),
(190112, 11)...每个年份月份后跟着一个气温集合,reduce函数只需要从这个气温集合中找出最大的一个值,就能找到当前月份最高气温了:
(190110, 15),
(190111, 22),
(190112, 11)...
JAVA代码
MaxTemperatureMapper.javaimport java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class MaxTemperatureMapper
extends Mapper<LongWritable, Text, Text, IntWritable> {
private static final int MISSING = 9999;
@Override
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
System.out.println("--------------------->>>>>,key:"+key+",value:"+value+"");
String line = value.toString();
String year = line.substring(15, 19);
int airTemperature;
if (line.charAt(87) == '+') { // parseInt doesn't like leading plus signs
airTemperature = Integer.parseInt(line.substring(88, 92));
} else {
airTemperature = Integer.parseInt(line.substring(87, 92));
}
String quality = line.substring(92, 93);
if (airTemperature != MISSING && quality.matches("[01459]")) {
System.out.println("--------------------->>>>>write,key:"+year+",value:"+airTemperature+"");
context.write(new Text(year), new IntWritable(airTemperature));
}
}
}MaxTemperatureReducer.javaimport java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class MaxTemperatureReducer
extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
public void reduce(Text key, Iterable<IntWritable> values,
Context context)
throws IOException, InterruptedException {
System.out.println("--------reducer>> key:"+key+",values:"+values.toString());
int maxValue = Integer.MIN_VALUE;
for (IntWritable value : values) {
maxValue = Math.max(maxValue, value.get());
}
System.out.println("--------reducer>> maxValue:"+key+",maxValue:"+maxValue);
context.write(key, new IntWritable(maxValue));
}
}
打包成JAR文件
File->Project Structure
Build Artifacts-Build
对数据格式进行解释
数据来源于:NCDC 美国国家气候数据中心
| 位置 | 数据 | 含义 |
|---|---|---|
| 1-4 | 0029 | |
| 5-10 | 029070 | USAF weather station identifie |
| 11-15 | 99999 | WBAN weather station identifier |
| 16-23 | 19010108 | 观察日期 |
| 24-27 | 1300 | 观察时间 |
| 28 | 4 | |
| 29-34 | +64333 | 纬度(1000倍) |
| 35-41 | +023450 | 经度(1000倍) |
| 42-46 | FM-12 | |
| 47-51 | +0005 | 海拔 |
| 52-56 | 99999 | |
| 57-60 | V020 | |
| 61-63 | 230 | 风向 |
| 64 | 1 | 质量代码 |
| 65 | N | |
| 66-69 | 0118 | |
| 70 | 1 | 质量代码 |
| 71-75 | 99999 | 云高(米) |
| 76 | 9 | |
| 77 | 9 | |
| 78 | N | |
| 79-84 | 000000 | 能见距离(米) |
| 85 | 1 | 质量代码 |
| 86 | N | |
| 87 | 9 | |
| 88-92 | -0033 | 空气温度(摄氏度*10) |
| 93 | 1 | 质量代码 |
| 94-98 | +9999 | 露点温度(摄氏度*10) |
| 99 | 9 | 质量代码 |
| 100-104 | 10320 | 大气压(hectopascals x10) |
| 105 | 1 | 质量代码 |